October 1, 2020 • 3 minute read • ![]()
Case Study: Good Data at Good Eggs - Data Infrastructure Correctness and Reliability



- Name
- David Wallace
- Handle
- @davidjwallace
This is the second in a series of posts about putting Dagster into production at Good Eggs. Read the introduction for an overview of our experience transforming our data platform with Dagster.
Where does data come from? At Good Eggs, some of our most important data comes from the field. Our warehouse managers use Google Sheets, for instance, to report on our various staffing partner labor metrics. The data from these Google Sheets feeds the downstream modeling that powers our logistics operations, and it’s crucial that it be correct. Since all data entry is prone to error, we’d like to catch those errors as quickly as possible, and definitely before bad data makes its way into our decision support.
Checking data quality on ingest with custom types

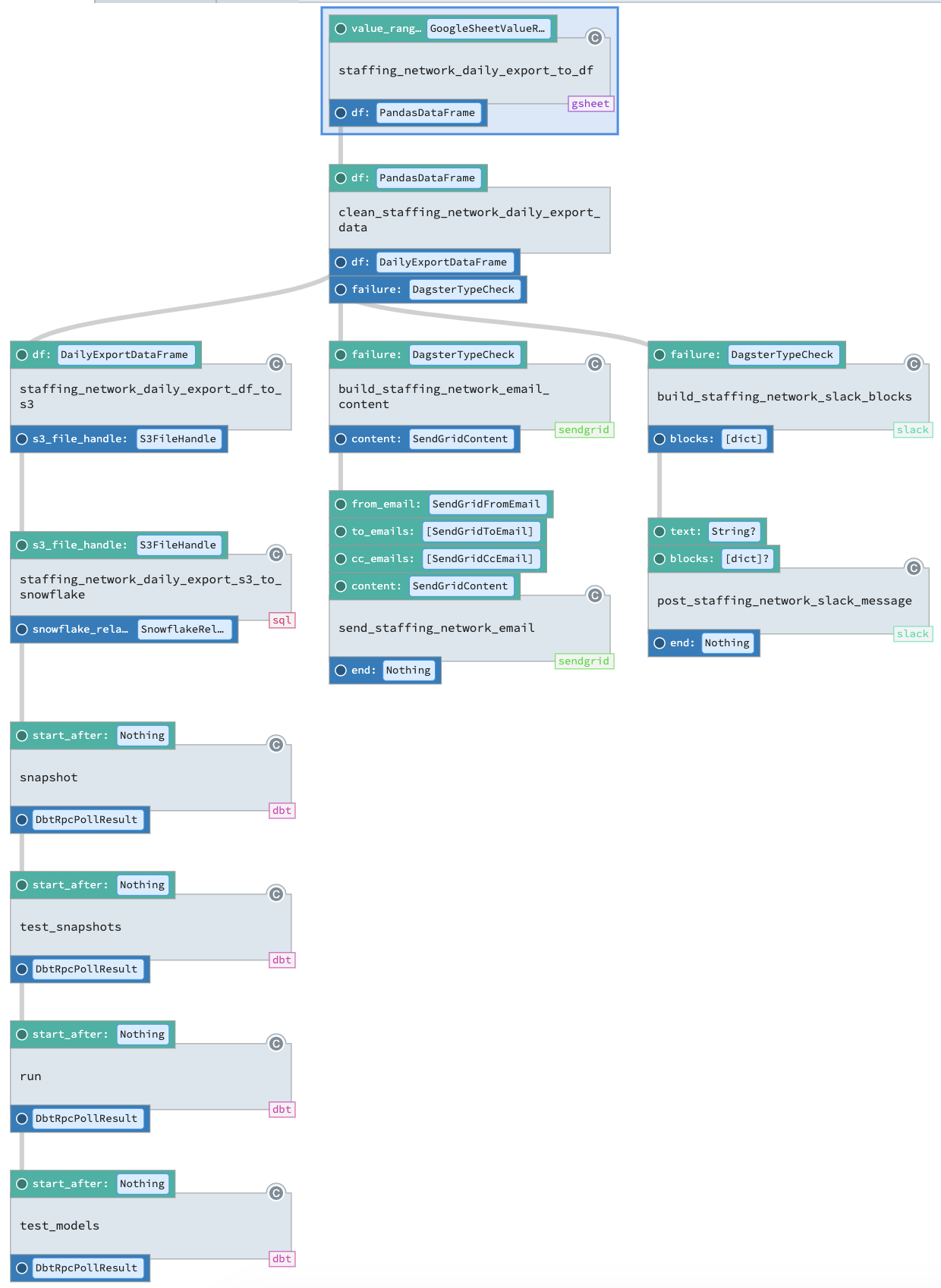
Let’s look at how we manage our data ingest from Google Sheets using Dagster.
Each node in the pipeline here is what Dagster calls a solid, a functional unit of computation that produces and consumes data assets.
In our pipeline, a solid reads a range of values from a Google Sheet, and then reshapes it as a Pandas DataFrame with given column types.
We then type check the data against a custom data frame type as a way of running quality checks on the data. In Dagster, type checks can run arbitrary code and associate their results with structured metadata. Here, we use a type factory from the dagster_pandas library to construct a custom data frame, which runs a set of checks on the data frame and its column. This process guarantees invariants, like that values for certain columns are non-null or belong to certain sets of categorical values. We also inject structured metadata (generated by our own compute_dataframe_summary_statistics function) so that summary statistics about the data appear in Dagit and in longitudinal views.
def compute_dataframe_summary_statistics(dataframe):
return [
EventMetadataEntry.text(
str(len(dataframe)), "n_rows", "Number of rows seen in the dataframe"
),
EventMetadataEntry.md(
dataframe.head().to_markdown(),
"head",
"A markdown preview of the first 5 rows."
),
...
]
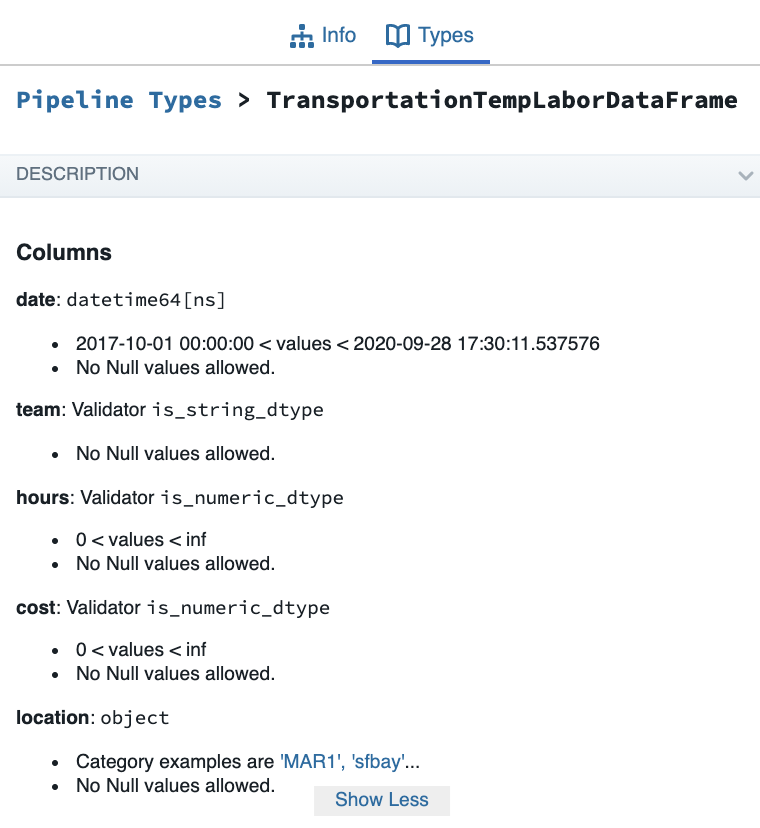
TransportationTempLaborDataFrame = create_dagster_pandas_dataframe_type(
name="TransportationTempLaborDataFrame",
columns=[
PandasColumn.datetime_column(
name="date",
min_datetime=START_DATE,
max_datetime=datetime.utcnow(),
non_nullable=True,
),
PandasColumn.string_column(name="team", non_nullable=True),
PandasColumn.numeric_column(name="hours", min_value=0, non_nullable=True),
PandasColumn.categorical_column(
name="location", categories={"sfbay", "MAR1"}, non_nullable=True
),
...,
],`
dataframe_constraints=[UniqueColumnsConstraint(columns=["date", "location"])],
event_metadata_fn=compute_dataframe_summary_statistics,
)
Like all other Dagster objects, custom types are self-documenting, so we get a nice view of the custom type in Dagit. This helps with discoverability for our analysts and anyone coming to the system fresh.

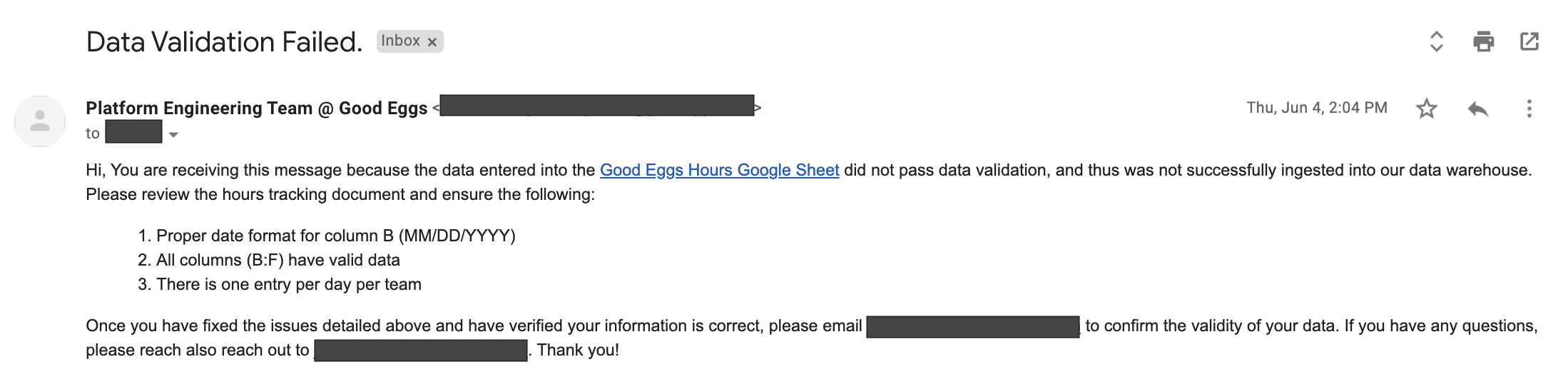
If our type checks fail, we conditionally execute solids that notify us in Slack and via email of the ingest failures, so we can take corrective action quickly. Emails are sent to select users, e.g., the operations team.

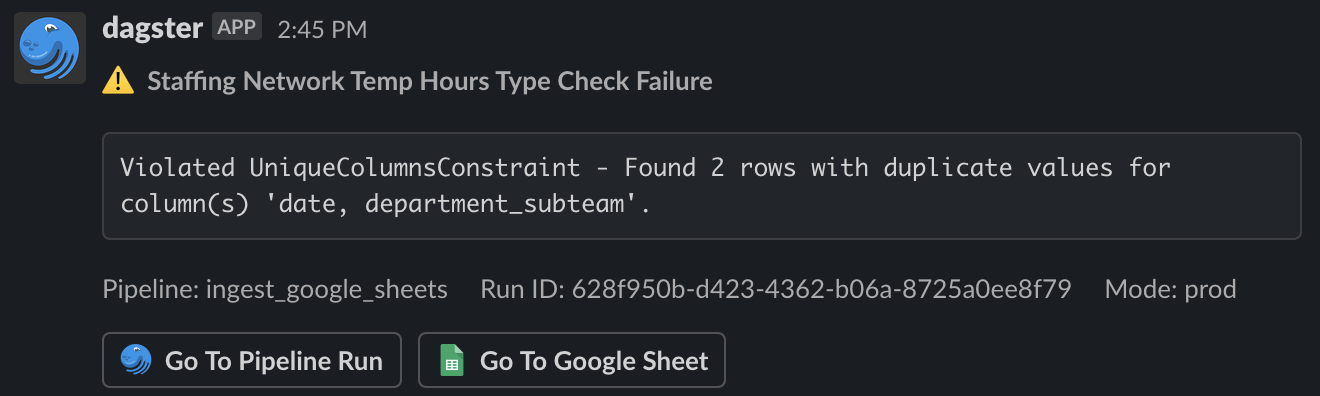
Slack messages surface operational failures to everyone quickly, and include links to the pipeline run and the source data to help debug.

If our type checks succeed, we know we can move ahead with data ingest. We conditionally execute solids that write the data to S3, then to Snowflake. Then, we trigger downstream dbt models, dbt tests, and Jupyter notebooks.
For us, failing before bad data is ingested to the warehouse is a big win. It’s a little bit like the value provided by database schema constraints, but in a system (Google Sheets) with no concept of schema or typing. You can’t commit strings to an integer column in a database, and you shouldn’t be able to load a form with values of the wrong type either.
We recognized the value of being able to impose strong typing at will on any of our inputs or outputs when we first started to evaluate data orchestrators, and this was one of the factors in our choice of Dagster over Airflow.
We’ve introduced several dozen of these custom data frame types into our data ingest process. Thanks to automated data quality tests, we’ve been able to make a process that used to take days immediate — our max latency is now about an hour. And there’s no chance of polluting downstream data artifacts because when our data isn’t clean, computation now just halts.
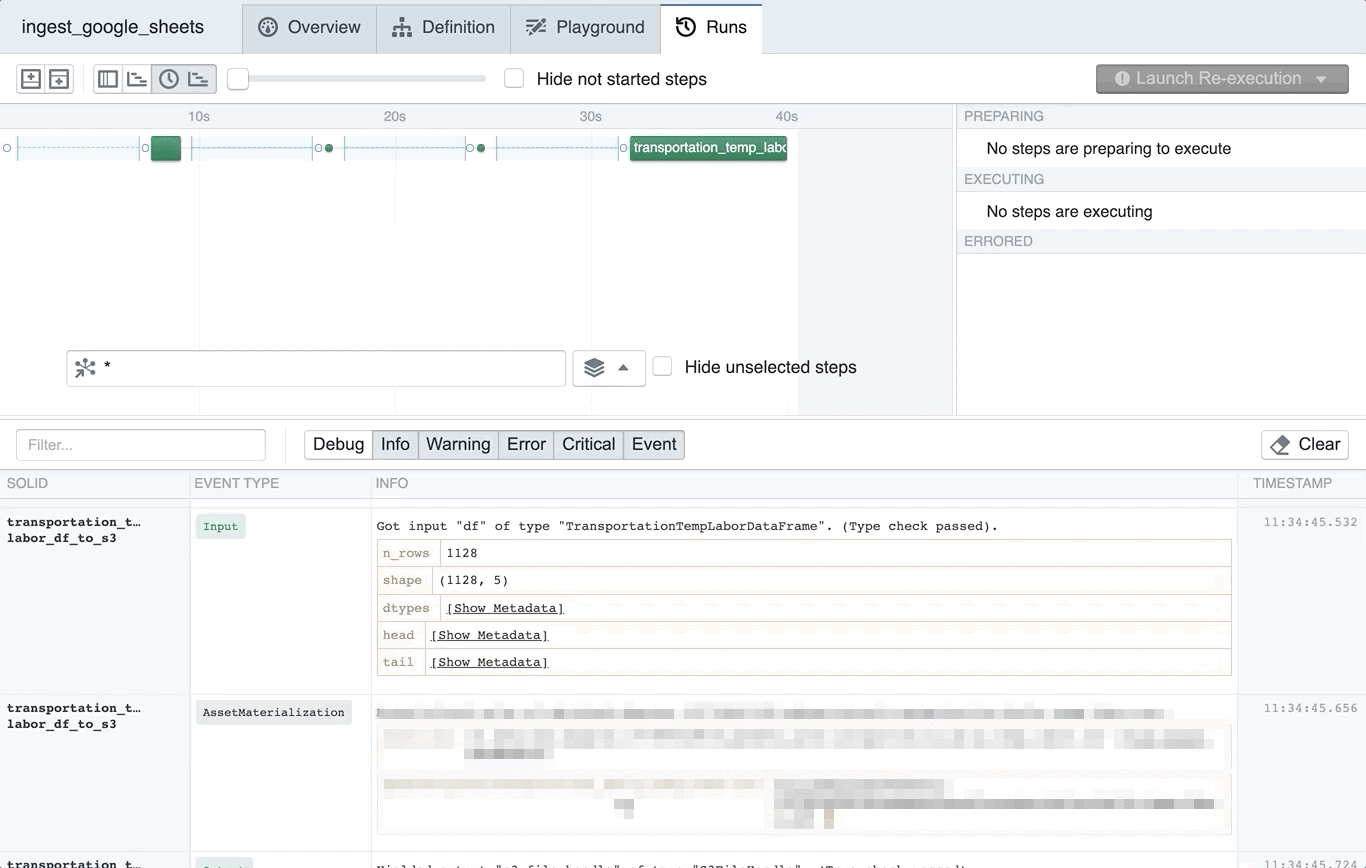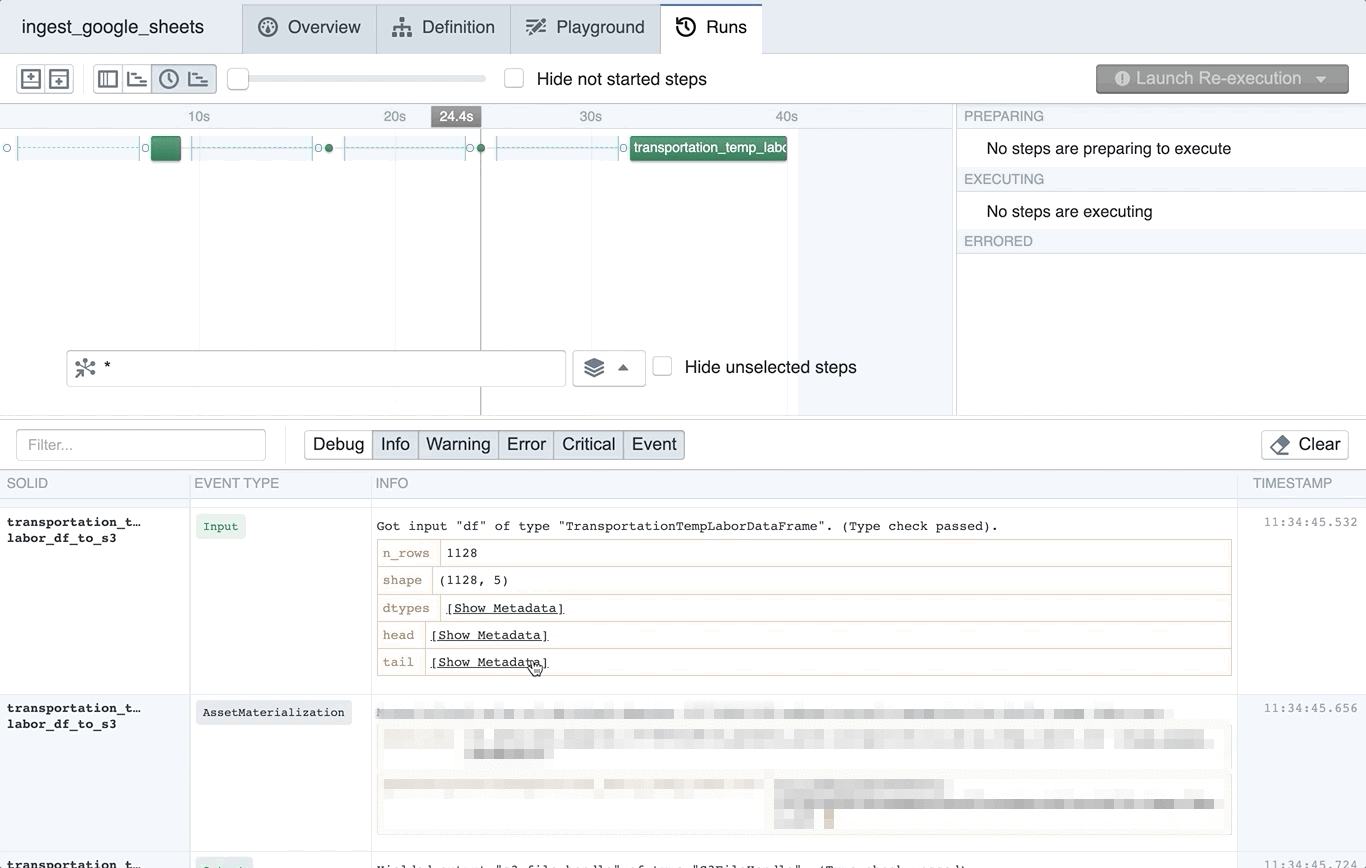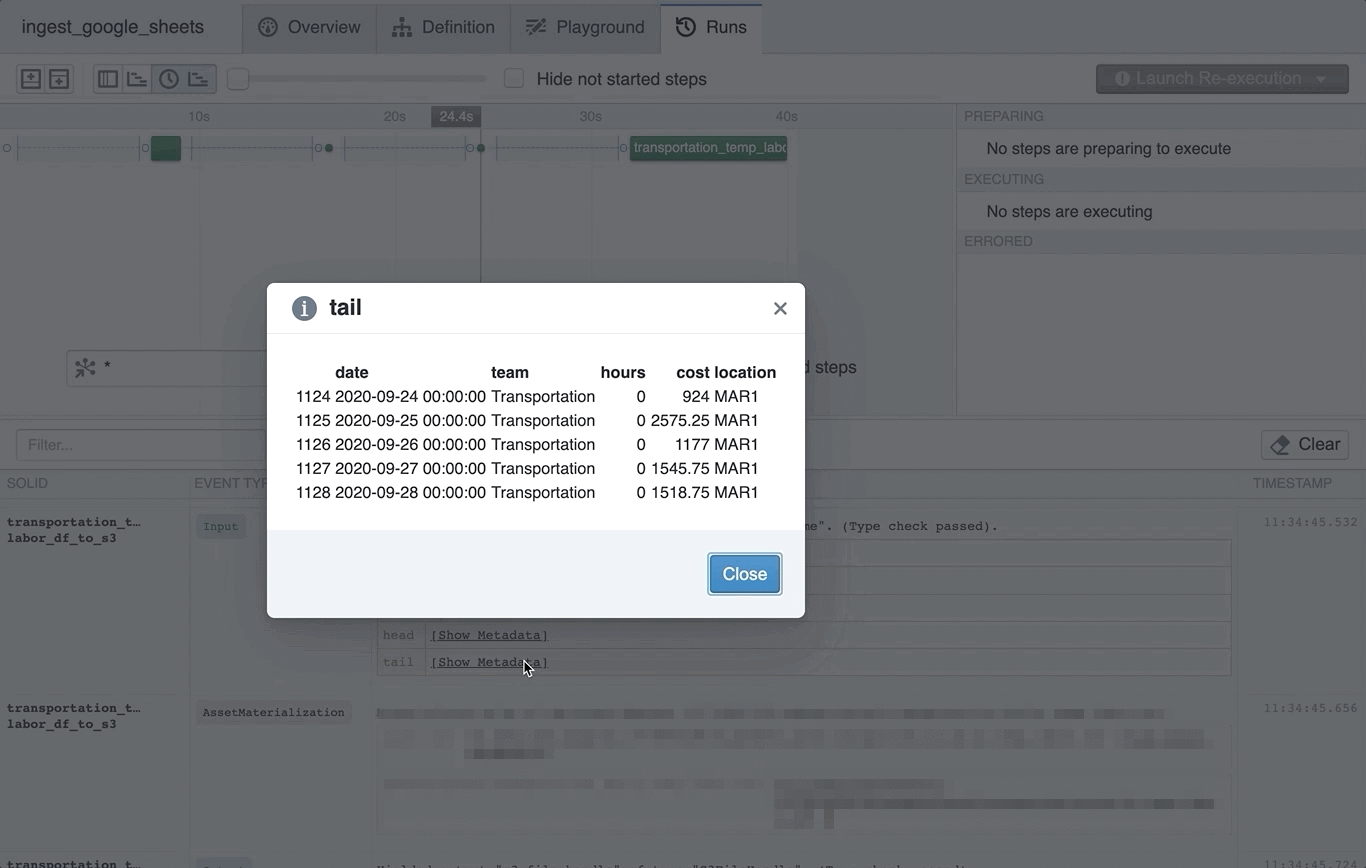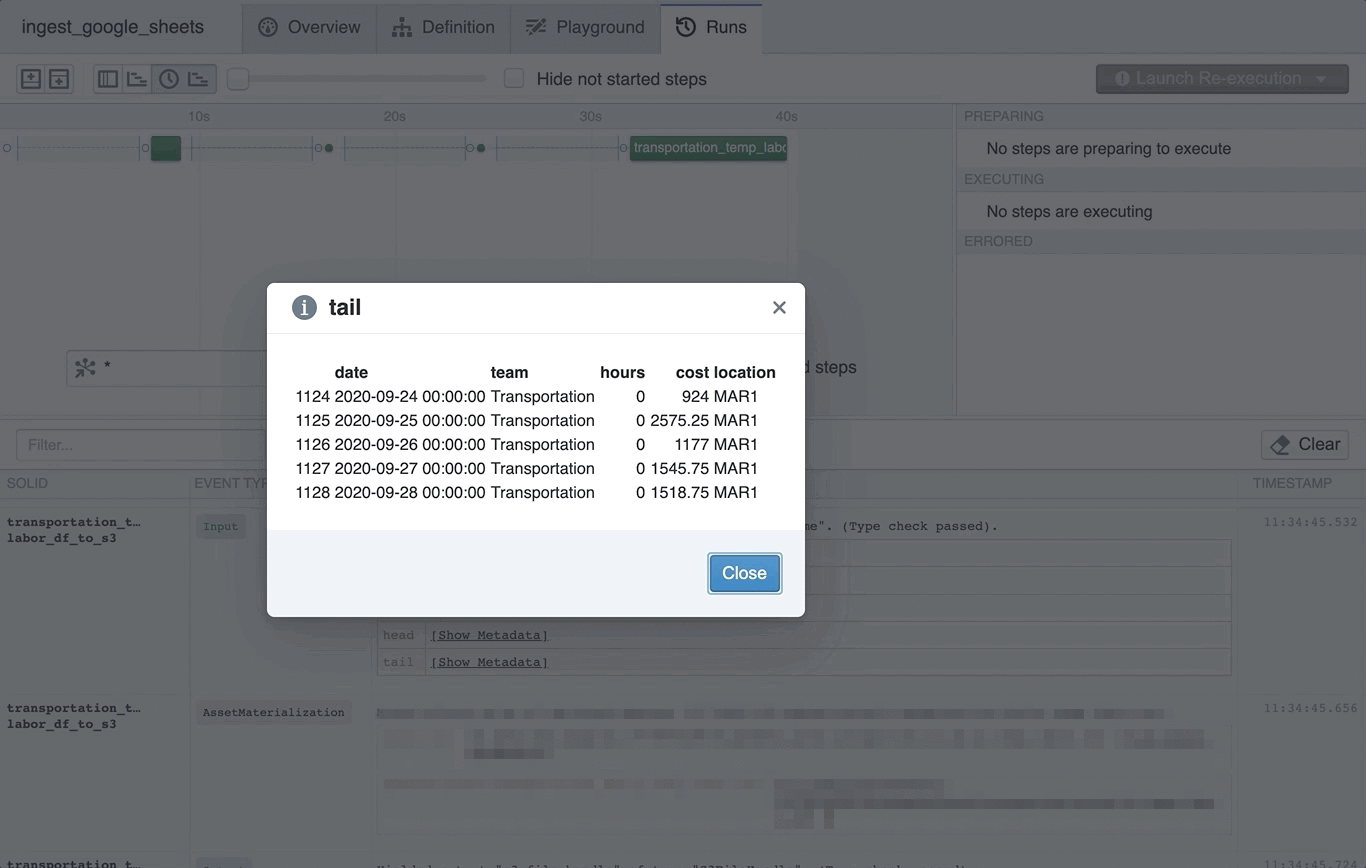
We also yield structured metadata as part of our type check process. Being able to view this metadata in the Dagster logs before ingestion has real benefits for the human in the loop. For example, we yield structured metadata with the head and tail of the data in a Google Sheet. This is viewable directly in Dagit and is often enough for a human to diagnose a data quality problem.

Dagster’s support for custom data types, and ability to surface structured metadata in Dagit, means less downstream breakage on data ingest and better recovery when bad data makes it through.
We hope you’ve enjoyed reading about our experience with Dagster so far. Check out the next post in the series to learn about how we've enabled self-service observability with Dagster's asset catalog.


We're always happy to hear your feedback, so please reach out to us! If you have any questions, ask them in the Dagster community Slack (join here!) or start a Github discussion. If you run into any bugs, let us know with a Github issue. And if you're interested in working with us, check out our open roles!
Follow us:


Case Study: KIPP - Building a Resilient Data Platform with Dagster


- Name
- Fraser Marlow
- Handle
- @frasermarlow

Case Study: Mejuri - Building an eCommerce Data Platform
- Name
- Fraser Marlow
- Handle
- @frasermarlow

Case Study: The Lean and Efficient One-Person Data Team of Erewhon

- Name
- Colton Padden
- Handle
- @colton
