October 29, 2020 • 4 minute read • ![]()
Dagster and dbt: Better Together



- Name
- AJ Nadel
- Handle
- @AJ_Nadel

- Name
- Bob Chen
- Handle
We are proud to announce the dagster-dbt library, a new first-class integration between Dagster and dbt (data build tool).
People sometimes ask us — should I use Dagster, or should I use dbt? We view Dagster and dbt as complementary technologies, not competing technologies. Data teams use dbt to define interdependent tables within a data warehouse, and Dagster to orchestrate dbt projects with other technologies, monitor their execution, and track the tables they produce.
What is dbt?
dbt enables data analysts to build well-defined data transformations in an intuitive, testable, and versioned environment.
Users build transformations (called models) defined in templated SQL. Models defined in dbt can refer to other models, forming a dependency graph between the transformations (and the tables or views they produce). Models are self-documenting, easy to test, and easy to run. And the dbt tooling can use the graph defined by models’ dependencies to determine the ancestors and descendants of any individual model, so it’s easy to know what to recompute when something changes.
For users who already speak SQL, dbt’s tooling is unparalleled.
We love dbt because of the values it embodies. Individual transformations are SQL SELECT statements, without side effects. Transformations are explicitly connected into a graph. And support for testing is first-class. dbt is hugely enabling for an important class of users, adapting software engineering principles to a slightly different domain with great ergonomics. For users who already speak SQL, dbt’s tooling is unparalleled.
What does Dagster bring to the table?
Dagster orchestrates dbt alongside other technologies and provides built-in operational and data observability capabilities. No matter the size of your dbt projects, you probably need it to interoperate with processes built in other tools.
Maybe your dbt models depend on source data tables that are populated by Stitch ingest, or by heavy transform jobs running in Spark. Maybe the tables your models build are depended on by analysts building reports in Mode, or ML engineers running experiments using Jupyter notebooks. Whether you’re a full-stack practitioner or a specialized platform team, you’ve probably felt the pain of trying to track dependencies across technologies and concerns. You need an orchestrator.
Dagster lets you embed dbt into a wider orchestration graph.
That’s where Dagster comes in. Where dbt defines a graph of SQL transformation, Dagster lets you embed dbt into a wider orchestration graph, clearly defining data dependencies that cut across technologies and teams and providing a single, unified operational view.
Support for observability is built into the system. Whether the nodes in your orchestration graph (what Dagster calls solids) run dbt models or reports in Mode, instigate Spark jobs or perform pure Python computations, they yield a stream of structured metadata back to the framework as they execute. This metadata makes deep integrations with other technologies possible.
In the case of dbt, rather than executing dbt models as black boxes, the framework can accumulate information about dbt runs over time, making that information available for longitudinal views and connecting it back to individual runs of your pipelines with no marginal setup effort.
Engineers can monitor dbt model execution in the same tool they use to monitor other technologies on the data platform.
Observability boils down to a couple of simple capabilities that we think everyone operating with data needs. With Dagster, individual dbt users can self-serve questions like “Which dbt models are at risk of becoming bottlenecks in our reporting pipeline?” And engineers can monitor dbt model execution in the same tool they use to monitor other technologies on the data platform.
Orchestrating dbt models with other computations
To see how this works in practice, let’s look at a simple Dagster pipeline that orchestrates dbt models together with other, heterogeneous processes operating on your data.

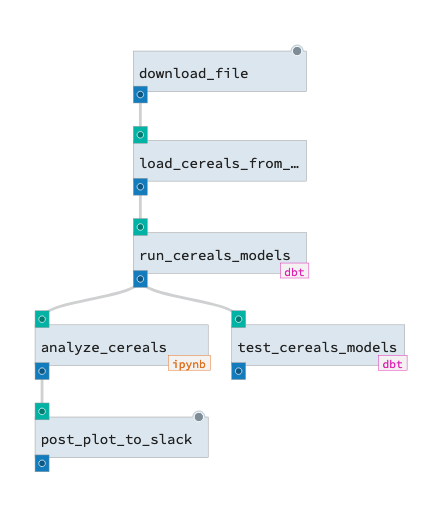
In this pipeline, we’ll download a raw .csv dataset from the public internet, then load it into a database using Pandas. We’ll run a series of dbt models to transform the data, run our dbt tests on the resulting database artifacts, and produce some plots using the transformed data. Finally, we’ll upload those plots to Slack for visibility.
While contrived, this example illustrates how dbt is often embedded into a larger context. Before dbt can operate on data, it has to be ingested from somewhere, using tools that lie outside of its purview. And after dbt has transformed data, that data is consumed by downstream users, who may use a wide range of technologies to do their work.
The dbt solids execute alongside the other components of the pipeline. You can see below that logs emitted by the running dbt models are streamed back to a central view, along with logs produced by solids making use of other technologies.

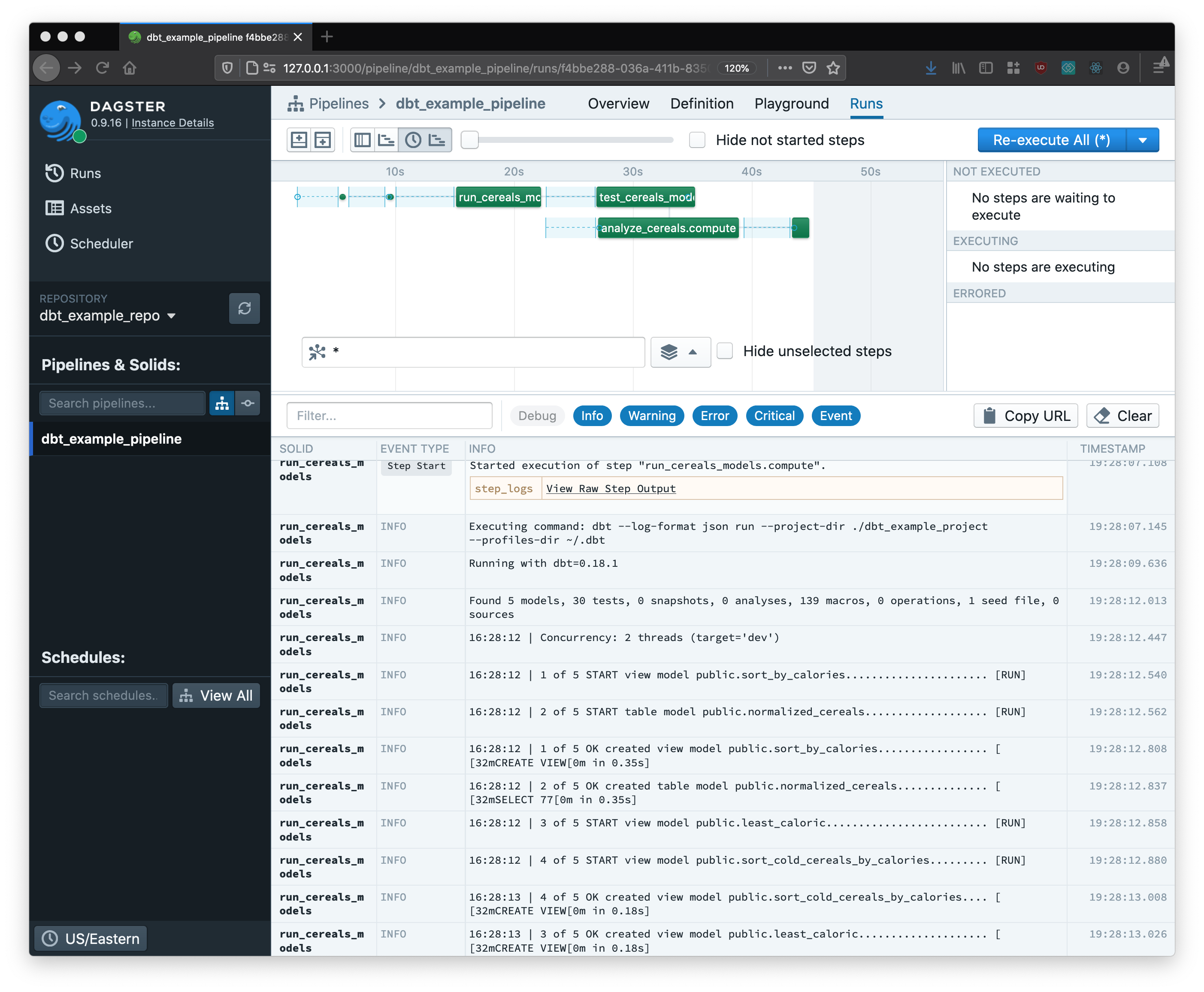
What’s more, Dagster is able to consume detailed metadata produced by the execution of the dbt models, and display it natively within a shared single portal.
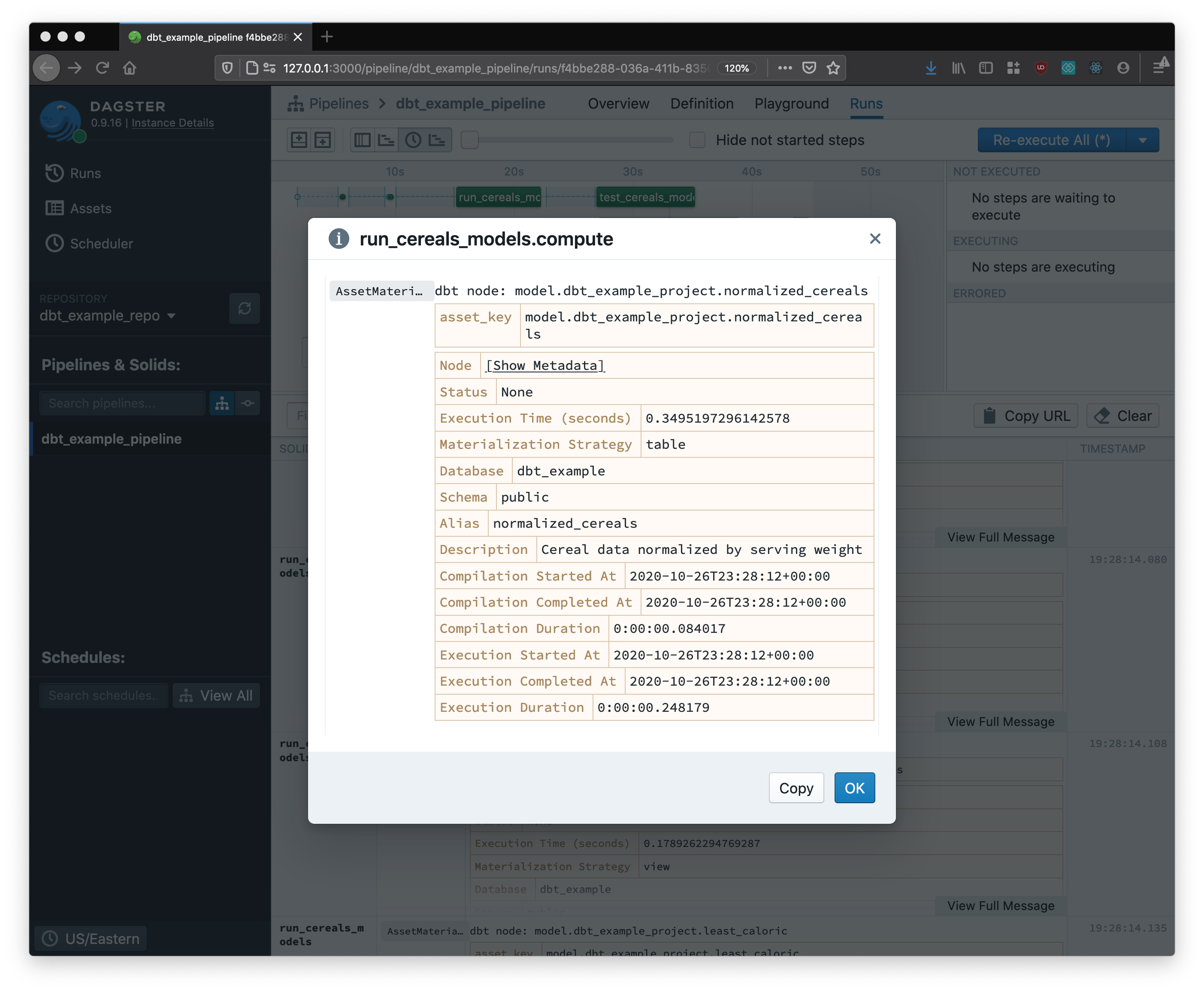
This makes monitoring a breeze. Once metadata is recorded, it can viewed longitudinally. So, for example, you can track the execution time of dbt models over many runs, and find developing bottlenecks before they become problems.

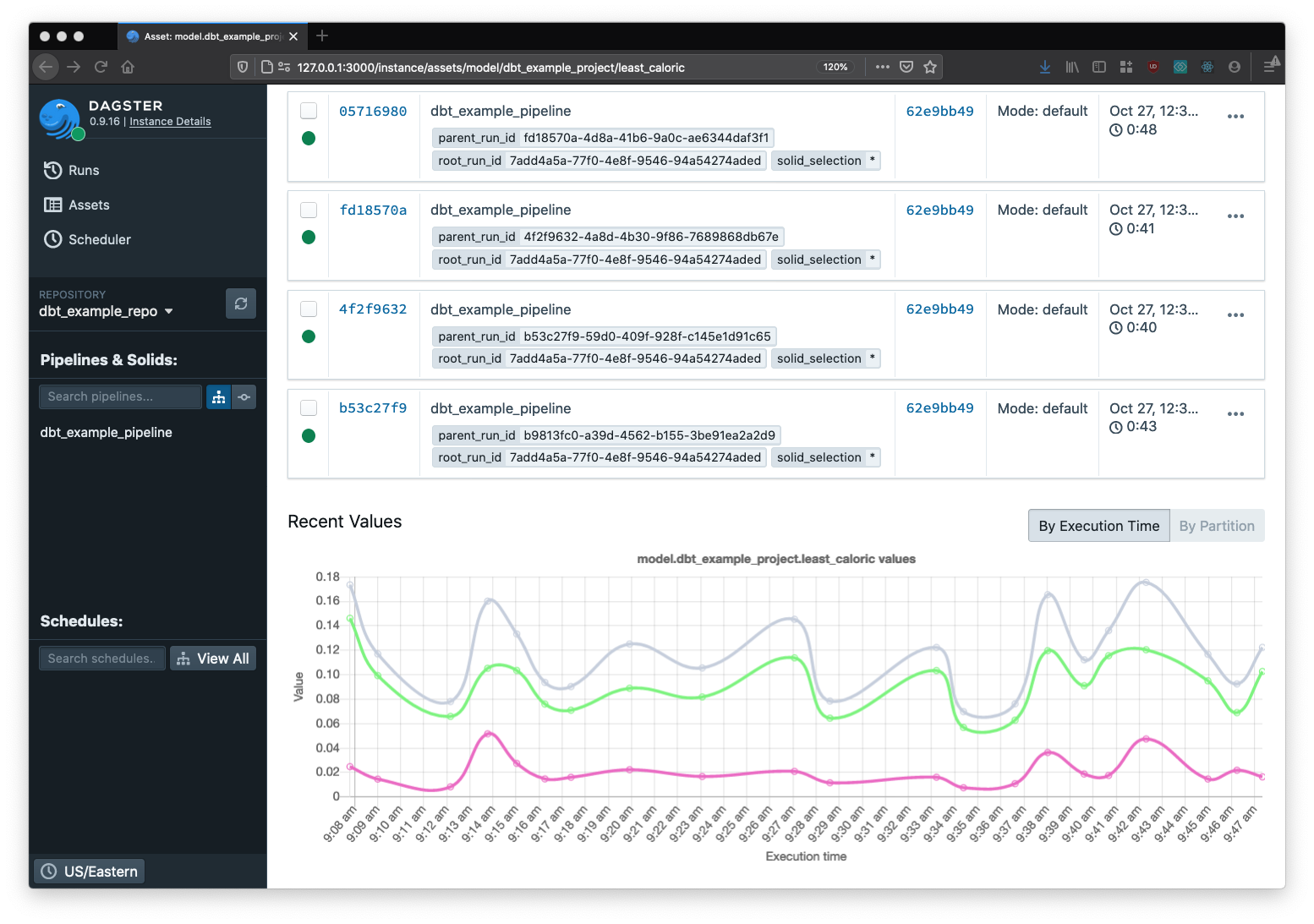
From this view, you can easily jump to any pipeline run that executed this model. So, for instance, if something was off about an asset created by that model at a particular time, you can inspect the logs of that specific run to figure out what happened. Or if the data in one of your tables seems stale, you can quickly check when it was last touched by a dbt run.
In short, with Dagster and dbt, you can:
Explicitly model the dependencies between your dbt models and processes that use other technologies;
Schedule and execute pipelines that include both dbt and other technologies;
Monitor your dbt models in the same tool you use to monitor your other processes, with historical and longitudinal views of your operations.
Learn more
You can find comprehensive guides in the dbt docs and the dagster-dbt integration documentation(https://docs.dagster.io/integrations/dbt).
Huge thanks to David Wallace at Good Eggs, whose community contributions laid the groundwork for this package.
If you’ve been working on an integration between Dagster and another ecosystem tool that you might want to contribute back to open source, please get in touch. The core team is happy to help support you in contributing integrations back upstream.


We're always happy to hear your feedback, so please reach out to us! If you have any questions, ask them in the Dagster community Slack (join here!) or start a Github discussion. If you run into any bugs, let us know with a Github issue. And if you're interested in working with us, check out our open roles!
Follow us:


Orchestrate Unstructured Data Pipelines with Dagster and dlt


- Name
- Zaeem Athar
- Handle
- @zaeem

Parallel Computing on Dagster with Dask

- Name
- Odette Harary
- Handle
- @odette

Orchestrating dbt™ with Dagster

- Name
- Rex Ledesma
- Handle
- @_rexledesma

- Name
- Sandy Ryza
- Handle
- @s_ryz