




Ecosystem and integration improvements, data catalog improvements, new asset checks, new declarative automation, and more.
The Dagster 1.8 release introduces changes that provide better integration with other tools, simplify asset management, enhance automation capabilities, and improve data quality.
Here's an overview of the updates.
Ecosystem and Integration Improvements
Un-experimentalizing Pipes
Dagster Pipes is our toolkit designed for building integrations between Dagster and external execution environments, ultimately enabling the separation of orchestration and business logic in the Dagster ecosystem.
As of today, the Pipes API and its integrations with Lambda, Kubernetes, and Databricks are now stable and no longer experimental. Try incorporating it into your pipelines and see their extended integration capabilities for yourself.
Get the latest info on Dagster Pipes in our documentation.
DbtProject
Improvements to the DbtProject integration make it easier to define dbt assets for both development and production by eliminating boilerplate for local development and assisting with pulling dependencies and generating the manifest at build time.
Learn more about the DbtProject class in the documentation.
SDF Integration
The new integration with SDF expands Dagster’s orchestration capabilities, allowing for more comprehensive and versatile data pipelines by leveraging SDF’s developer experience, model validation framework, hybrid execution engine, and metadata system.

For more information on the SDF integration, stay tuned for our upcoming blog post on how SDF and Dagster can help you achieve transparent and scalable data pipelines while relying less on cloud compute.
Looker Integration
The Dagster Looker package lets users define Dagster assets from a Looker project defined in LookML and backed by git directly into their data pipelines.
More details can be found in the GitHub discussion.
Data Catalog Improvements
Enhanced Asset Metadata

The Asset Details page now prominently displays row count and relation identifiers (table name, schema, database) when corresponding asset metadata values are provided. These additions make tracking and identifying assets easier, improving data traceability and management.
See our documentation on metadata and tags for more information
Code Reference Metadata

We’ve added code reference metadata that allows opening local files in your editor or source control files in your browser. Linking assets to specific code references enhances traceability and documentation, making understanding the data lineage and code dependencies easier.
See more on code reference metadata in our documentation.
Data Quality and Reliability Improvements
Metadata Bound Checks
The new build_metadata_bounds_checks API allows users to define asset checks that fail if a numeric asset metadata value falls outside specified bounds. This enhancement improves data reliability and quality control by ensuring asset values remain within acceptable ranges.
Read up on asset checks in our documentation.
Freshness Checks from dbt Config
Freshness checks can now be set directly on dbt assets using dbt configuration. This feature streamlines data freshness and reliability processes while integrating seamlessly with existing dbt pipelines.
Check out the API docs to learn more about building freshness checks from dbt assets.
Core Definition APIs
Stable Support: External Assets
Dagster now offers stable APIs for specifying assets that can’t be materialized from Dagster, but which are still part of the lineage graph. For example, this enables Dagster to know about a dashboard in a business intelligence tool that’s downstream of Dagster-orchestrated assets. You can specify a non-materializable asset by constructing an AssetSpec and passing it to a Definitions object.
This functionality replaces the experimental external_assets_from_specs API and deprecates SourceAssets, which offered similar capabilities but in a more limited way.
See the documentation for more info.
Merging Definitions
The Definitions.merge API allows users to merge multiple Definitions objects into a single object, simplifying the structuring of large Dagster projects and making it easier to manage complex projects by combining sub-domain definitions into a cohesive whole.
See the documentation on definitions for more info.
Deduplication in Asset Definitions
AssetDefinitions provided to a Definitions object will now be deduplicated by reference equality, meaning that the below code will now work.
from dagster import asset, Definitions
@asset
def my_asset():
pass
defs = Definitions(assets=[my_asset, my_asset])
### This will now dedupe to a single AssetsDefinition.
Refer to the asset definitions documentation for more info.
Partitions and Backfills
Wiping Materializations
It’s now possible to wipe materializations for individual asset partitions, providing more granular control over data. This allows you to keep Dagster's view of your data up-to-date when you need to manually delete data in your storage system.
Asset Job Backfill Policies
Asset jobs now use backfill policies derived from their underlying assets, utilizing the policy with the minimum max_partitions_per_run. This improvement enhances backfill efficiency and control, ensuring that backfill processes are more aligned with each asset's specific needs.
Learn more about launching backfills for partitioned assets in our documentation.
Automation
Declarative Automation
Auto-materialize has been transformed into “Declarative Automation”, which centers on new AutomationCondition APIs that replace the AutoMaterializePolicy system (now deprecated). AutomationConditions address a number of long-standing issues with the prior system by making it more customizable – e.g. it now supports composing arbitrary boolean expressions – and easier to operate at scale.
@asset(automation_condition=AutomationCondition.eager())
def a(): ...
@asset(
automation_condition=(
AutomationCondition.on_cron("@daily") |
AutomationCondition.code_version_changed()
)
)
def b(): ...
Check out our GitHub discussion on Declarative Automation for a recap on the challenges that inspired these changes.
Jobless Automation
The experimental target parameter allows schedules and sensors to directly target assets, automatically including them in the assets list of the containing Definitions object. This change simplifies automation setups, reducing the need for explicit job definitions and making automation more straightforward.
Timeline Page Grouping
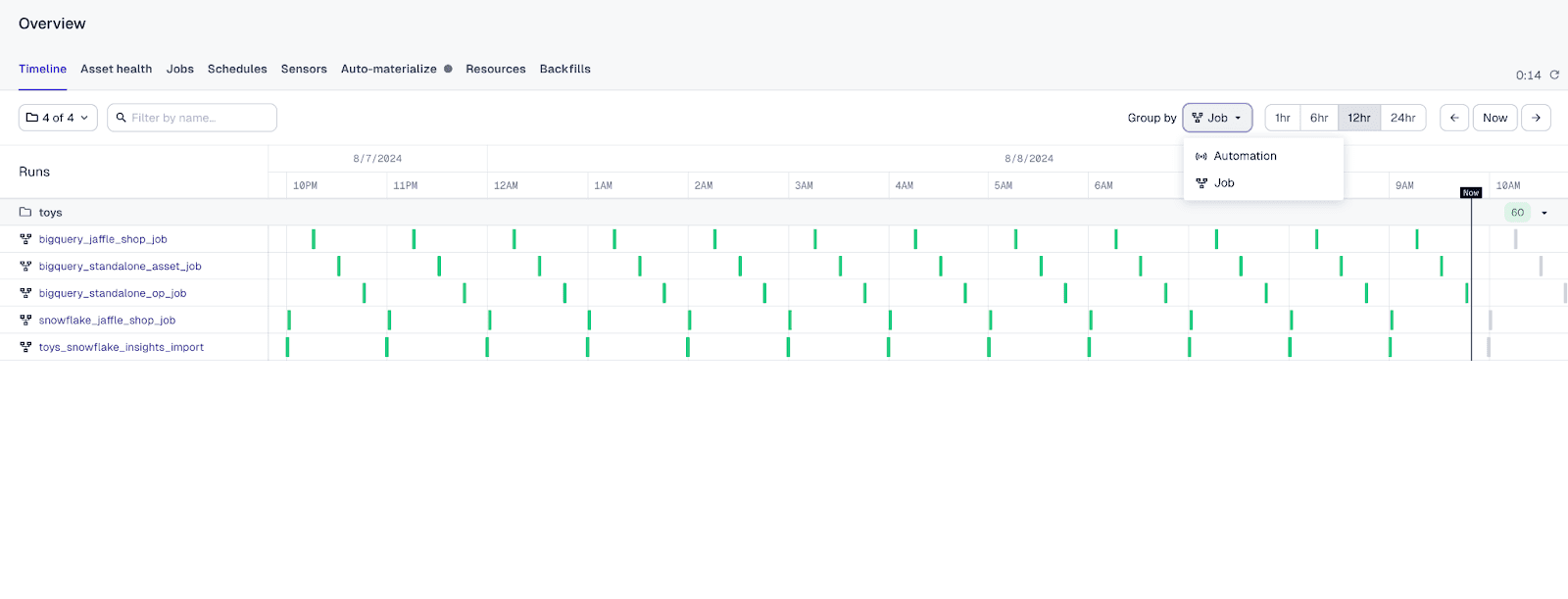
The Timeline page can now be grouped by job or automation, allowing users to visualize and manage their pipelines better. Grouping by automation ensures that runs launched by sensors are appropriately categorized, improving the timeline's clarity and organization. You can enable this feature by selecting the experimental navigation feature flag in user settings.
Acknowledgments

We want to thank all community contributors for their efforts and innovations in making this release possible.
Chris Histe | Ali Ebrahim | Daniel Gafni | Søren Schwartz | Mathieu Larose | Daniel Bartley | James Lewis | David Griffiths | Arseny Egorov | yuvalgimmunai | the4thamigo-uk | Neil Fulwiler | Dimitar Vanguelov | Marijn Valk | Gabor Ratky | SanjaySiddharth | lautaro79 | Edson Nogueira | Cooper Ellidge | Aksel Stokseth | Tomas Gajarsky | Alex Launi | Thomas Baumann | gibsondan | Thomas Weit | Brian Malehorn | Ivan Tsarev | jobicarter | Egor Dmitriev | Chris Roth | Federico Caselli | Joe Percivall | jlloyd-widen | Niko | Jonathan Lai | Shane Zarechian | Alexander Bogdanowicz | Gareth Brickman | Jake White | abhinavDhulipala | Vinnie | Piotr Marczydło | Tim Nordenfur | drjlin | Stian Thaulow |
Stay tuned for more updates and enhancements in future releases.
Enjoy orchestrating with Dagster 1.8.





.jpg)
.png)



.png)

