



How KIPP’s solo data engineer radically improved KIPP’s ability to leverage data across the organization.
A Platform Approach for Faster Development
The KIPP NJ & Miami schools are part of the nationally recognized “Knowledge Is Power Program” network of free, open-enrollment, college-preparatory public schools. The network, known as KIPP Team & Family, comprises of 19 schools serving over 10,000 students across Newark, Camden, and Miami, FL.
The network faced a challenge familiar to many growing organizations: managing a complex and fragmented data stack. Data is vital at KIPP, informing everything from student progress and attendance to operational finance and HR. However, with different systems spread across multiple regions, scaling data management became a considerable task.
As the sole data engineer for KIPP's Newark, Camden, and Miami regions, Charlie Bini had to find a solution that could support growth, streamline data operations, and provide much-needed visibility into the data stack.

This is the story of how KIPP Team & Family Schools moved from a disparate collection of tools to a unified data platform powered by Dagster.
In doing so, Charlie changed how the entire data team works, providing better observability and alerting, a faster development cycle, and easier self-service for team members. Processes that took ”two weeks to a month to develop” can now be done “in a couple of days," says Charlie.
People love the idea of what we're doing, and the vision of a cohesive data platform is something that resonates with everyone.
The Problem: A Patchwork of Tools
Back in 2017, KIPP's data infrastructure was a tangle of multiple technologies—Python scripts, cron jobs, stored procedures, Fivetran, and even browser automation with Selenium. These tools were stitched together to extract data from various systems, including SFTP folders, APIs, and databases. Fivetran acted as the hub, ingesting data and moving it into a SQL Server for reporting. While it worked, the setup was brittle. If one step took longer than expected, the whole process would fail, and the data quality issues would be a constant challenge.
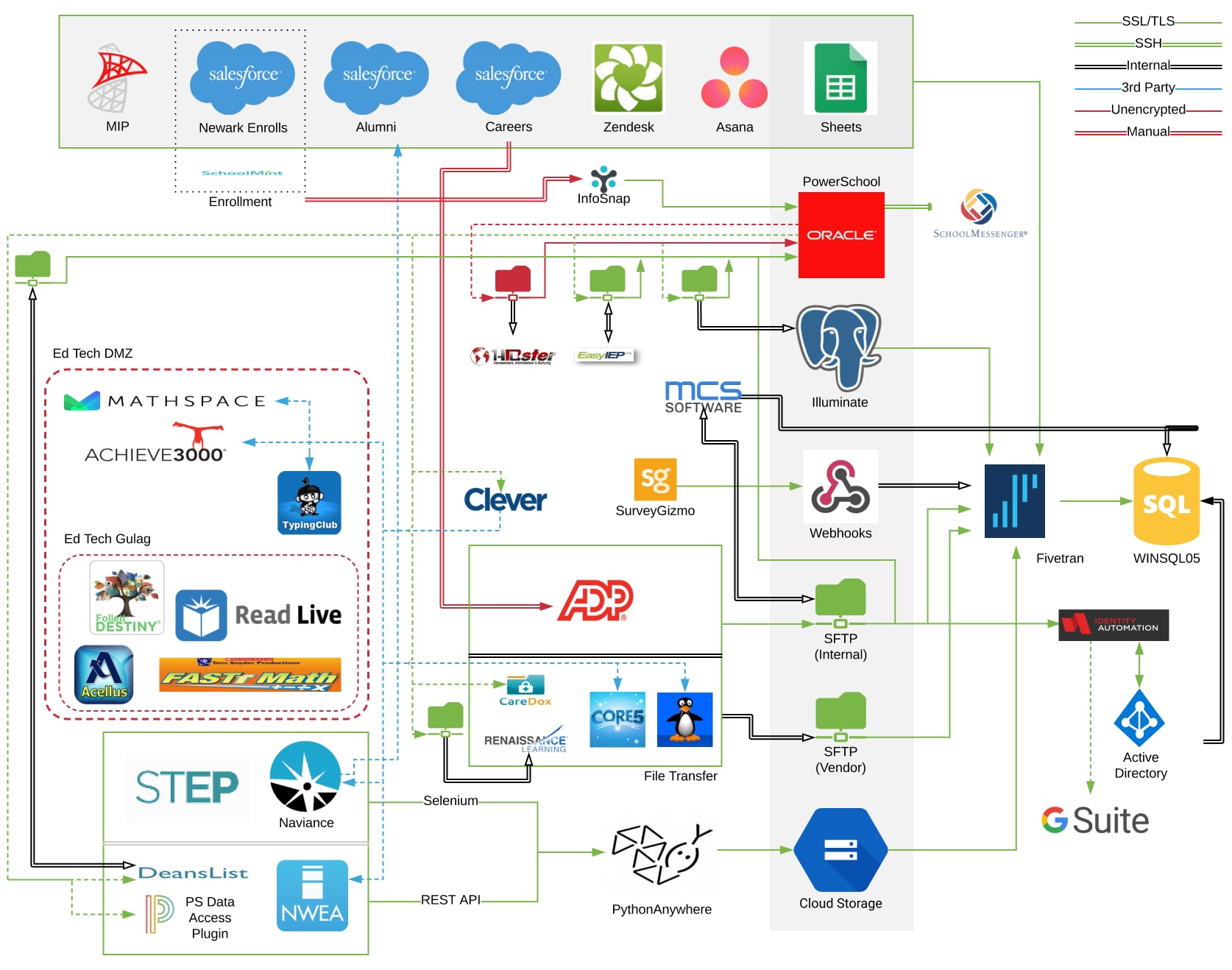
"Everything was very synchronous," said Charlie. "If our pull from a student information system took too long, the next process would miss its tick, and we'd end up waiting until the next scheduled run." This lack of resilience not only affected data reliability but also consumed Charlie's time in debugging and firefighting.
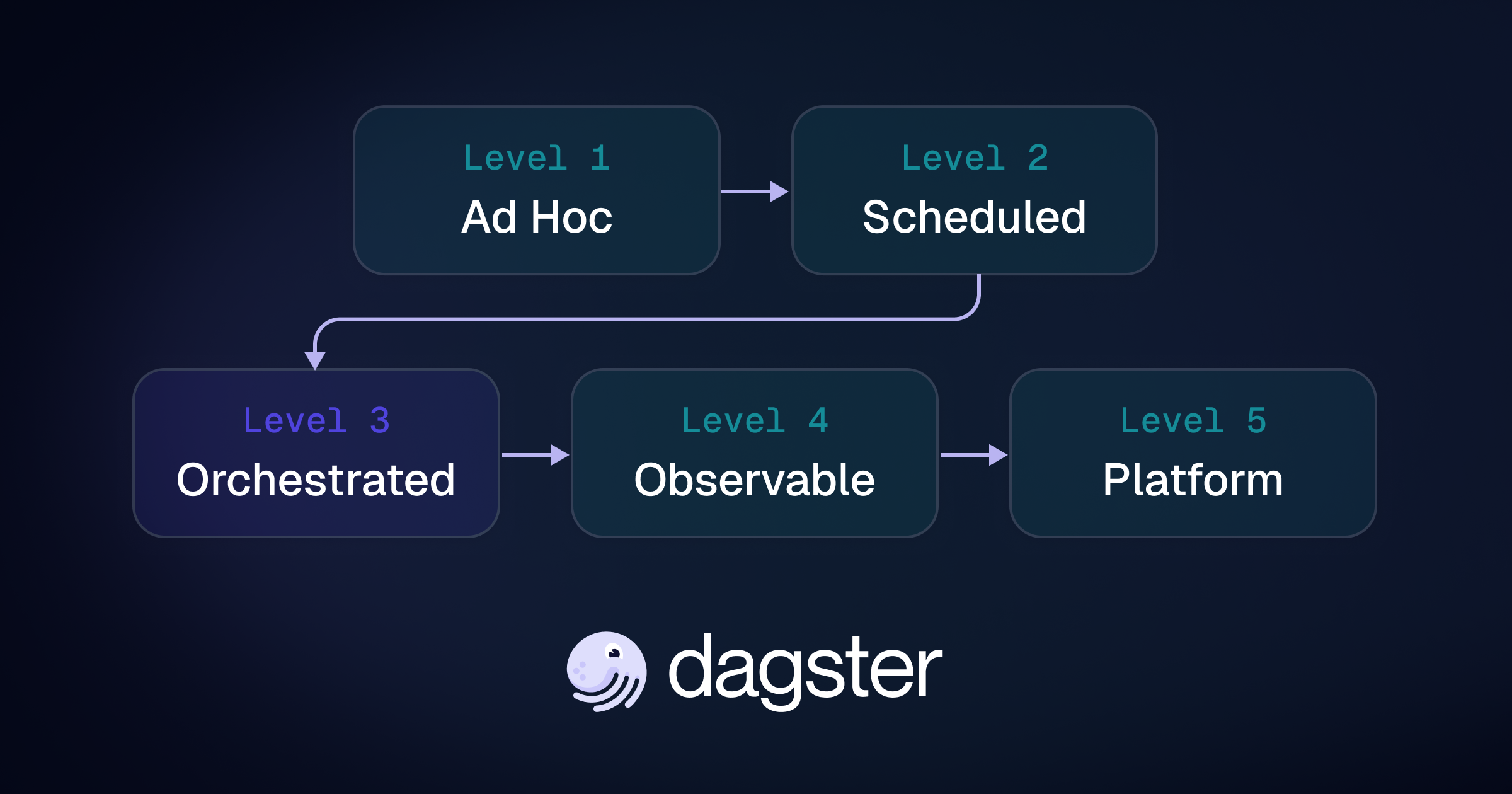
It was clear to Charlie and the rest of the team that in order to scale and free up time to take on new challenges, they would first need to overhaul the foundation of their data processes, moving from a patchwork of systems that had evolved organically, to a fully featured data platform where key capabilities such as orchestration, metadata management, end-to-end observability, and data quality could be centralized and unified.
Selecting the Right Orchestration Solution
KIPP experimented briefly with Airflow to improve orchestration, but it didn't provide the experience they were looking for. The complexity and the cost of running Airflow in Google Cloud Composer also made it unsustainable. Charlie knew that to scale, KIPP needed a new approach—one that would bring together all these disparate data processes in a cohesive and manageable way.
In 2021, Charlie began experimenting with Dagster, an emerging orchestrator that promised more visibility and control over data pipelines. With Dagster, KIPP could centralize all its data processes, bringing data extraction, transformation, and orchestration into a unified platform. One of the key benefits was the real-time visibility Dagster provided into pipeline health.
"The visibility into the pipelines is a game changer," Charlie noted. "We know as soon as something fails and why, and it's pretty easy to remedy it." This was a major shift from the old setup, where issues often remained undetected until downstream effects were noticed, such as outdated reports or missing data in dashboards.
Building the Data Platform
The new data stack brought all of KIPP's data operations under a single, cohesive framework:
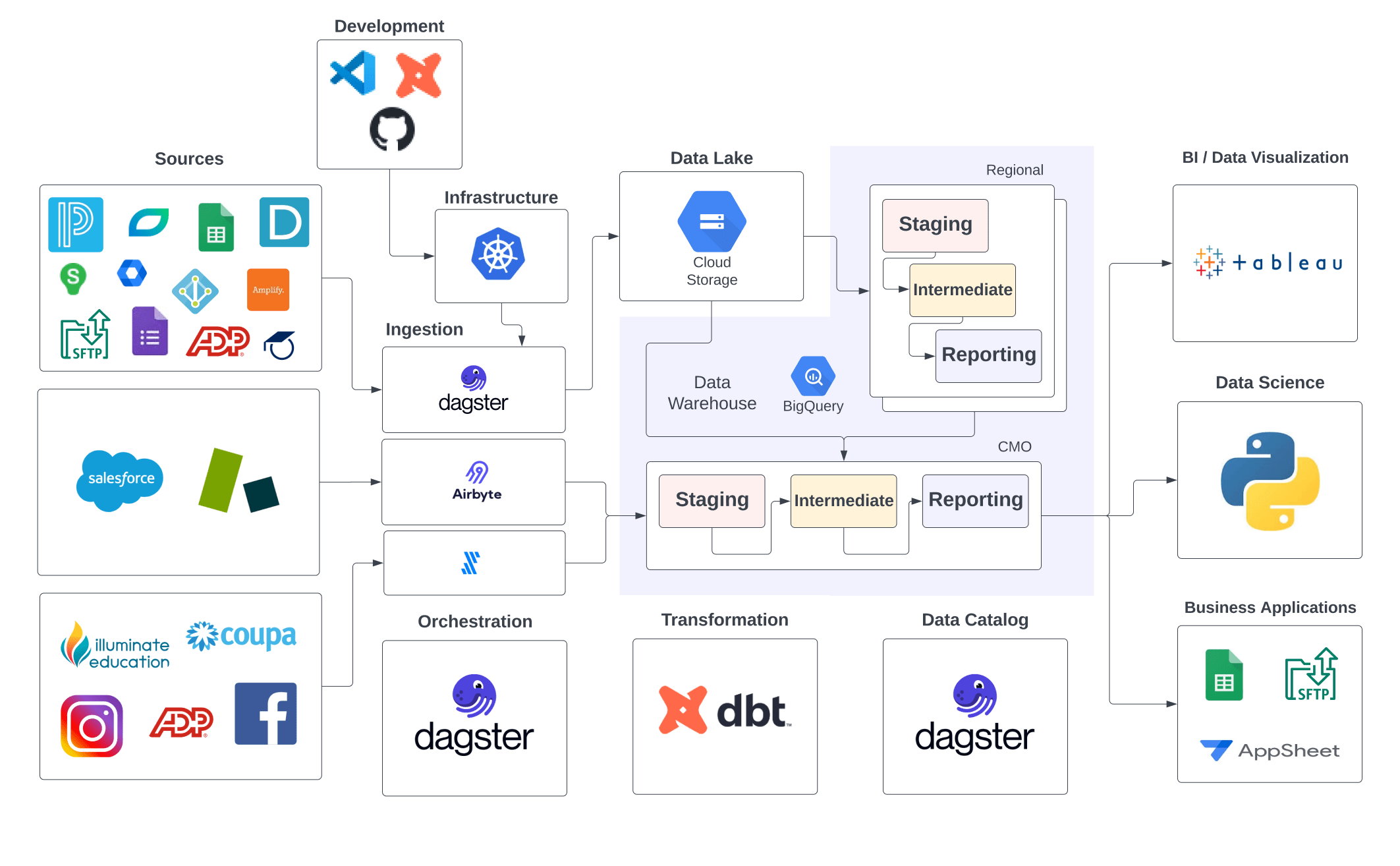
- Dagster for Orchestration and Cataloging: The core of the new data platform was Dagster. Dagster orchestrated everything—from data extraction from third-party systems to transformations and data loading into the warehouse. The platform also provided clear lineage graphs, which allowed the team to easily track the flow of data from source to report.
- BigQuery as the Data Warehouse: KIPP centralized its data storage in Google BigQuery, providing a scalable and performant environment for storing and querying data.
- dbt for Transformations: dbt was introduced to handle transformations within BigQuery, making the entire ELT process transparent and manageable with version control.
- Containerized Ingestion with Kubernetes: Data ingestion scripts were containerized and run on Kubernetes, making the system more scalable and resilient.
In this new setup, Dagster also manages data quality checks, leveraging asset checks to ensure incoming data conforms to expected schemas. This setup drastically reduced the number of data quality issues, and tickets related to data problems dropped by 30% year over year.
The Impact: Faster Development, Fewer Issues
The shift to Dagster wasn't just about technology—it changed how the entire data team worked. Data pipeline development, which previously took weeks, was reduced to just days. "It used to take two weeks to a month to develop a new integration. Now, with Dagster, we can get a proof of concept done in a couple of days," Charlie explained.
The time savings weren't just in development but also in maintaining data quality. Thanks to Dagster's real-time alerts and lineage tracking, Charlie and the team could respond to issues immediately. Slack alerts provided instant notifications when a job failed, allowing quick triage and resolution, often before downstream users even noticed a problem.
Empowering the Team
Another significant benefit of adopting Dagster was the growth in the team's capabilities. With everything centralized in a Git repository and using pull requests for changes, the analysts at KIPP were able to participate more directly in the data engineering process. This shift brought software engineering best practices—like code reviews and DevOps concepts—to the data team, raising everyone's technical skills.
"Our team has grown skill-wise," Charlie said. "Analysts are now more proficient in SQL, Git, and understanding how the entire data stack works together."
The introduction of Dagster's data catalog feature also provided the team with a single source of truth for data assets. Analysts could trace the lineage of data, understand dependencies, and find documentation, all within Dagster. This made onboarding new team members easier and increased overall productivity.
Conclusion: A Unified, Scalable Data Platform
By adopting Dagster, KIPP transformed its data platform from a fragmented set of ad-hoc tools into a unified, resilient, and scalable solution. The result was a data stack that not only met the organization's growing demands but also empowered the data team to work more efficiently and collaboratively.
Charlie hopes that other KIPP regions will eventually adopt a similar setup, allowing them to standardize data operations across the entire network and reduce redundancy. "People love the idea of what we're doing," he said, "and the vision of a cohesive data platform is something that resonates with everyone."
For other data teams facing similar challenges, KIPP's story serves as an inspiring example of how the right orchestrator can simplify operations, improve data quality, and ultimately help scale data capabilities to support meaningful organizational growth.




.jpg)
.png)
.jpg)


.png)

