



Zippi successfully navigated a common growth milestone, future-proofing data operations on Dagster.
By their very nature, startup companies innovate and iterate on a core idea, fine-tuning their business model, positioning, and pricing. They also iterate and innovate when it comes to their data operations.
Brazilian fintech firm Zippi provides a great example of how Dagster helps engineering teams incrementally adopt and innovate while also building a reliable and adaptable data platform.
We met up with Renan Veras, Data Engineer on the Zippi data team, to discuss the business and the evolution of the data platform.
"Dagster+ helped us deliver faster insights with less downtime, all while reducing our maintenance costs. We have greater visibility of our data assets and our pipelines are easier to troubleshoot and understand."
About Zippi: Microfinance for Micro-Entrepreneurs
Access to credit is extremely scarce for the 40 million gig economy workers in Brazil and many other emerging economies across Latin America.
Volatile earnings and a difficult-to-access work history mean that these individuals cannot even apply for loans at most financial institutions. When faced with emergencies or financial difficulties, micro-entrepreneurs struggle to secure short-term funding.
Zippi solves that by building financial products tailored to micro-entrepreneurs and small businesses, providing the critical cash flow needed to keep the business going. Zippi issues working capital lines with a streamlined application process. Zippi has tens of thousands of active loans, each averaging 1,000 Brazilian real (~$180 USD).
Zippi was a YC Combinator graduate of 2019.
From Pipelines to Platforms
Like most startups, Zippi began by implementing the critical pipelines needed to run the business.
Renan breaks these down as:
- Loan underwriting (the primary pipeline based on a proprietary Machine Learning model). This includes fraud analysis and identity verification (a.k.a “KYC procedures”).
- Business Analytics
- Customer behavior analysis
To achieve this, the team built out a first set of pipelines primarily focused on data movement:
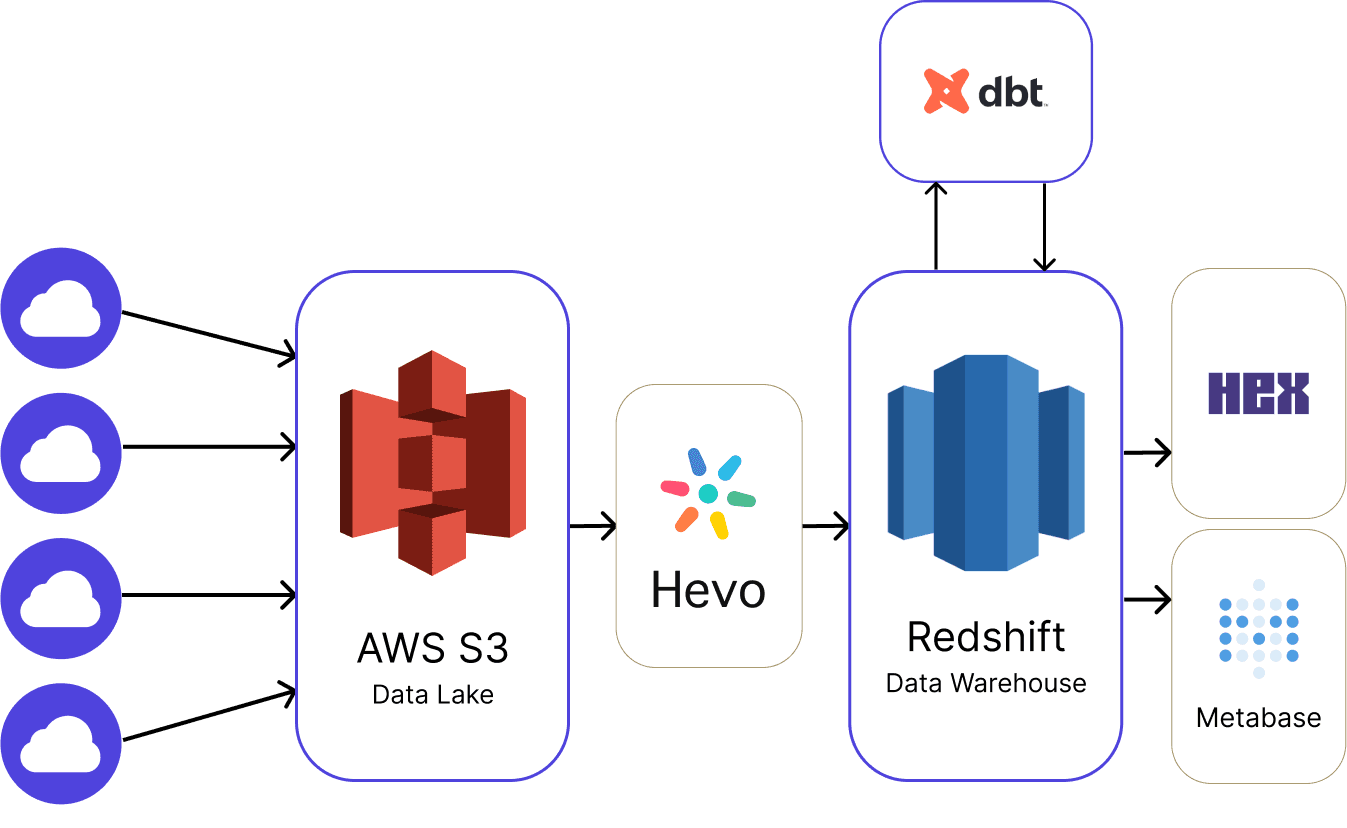
In this pipeline, data is ingested from SaaS applications into an S3 data lake, ported to Redshift using Hevo, transformed using dbt, and analyzed using HEX or Metabase.
In addition to the above, the team implemented Metaplane for data observability and the automation of data quality checks.
For the main credit analysis pipeline, the team ingests data from the Brazilian government and OpenFinance, a new service for financial institutions. Data volumes rapidly grew from small datasets to many terabytes.
ML models for loan approval
Like most lending companies, Zippi is developing its own ML models for creditworthiness, identity verification, and risk assessment. Ultimately, the ML model decides who should get approved for the loans. Such ML models are often the ‘secret sauce’ for a fintech company as they are based on—and fine-tuned with—the proprietary datasets the company accumulates.
Operationalizing such ML models with the basic ELT pipeline was challenging, says Renan:
“We moved to this ML-driven model, to rate the creditworthiness of loan applicants. We needed to assign a score to each applicant to support the Credit team. The challenge was to integrate the model to make predictions within the same pipeline that makes the model transformations. We had no way to integrate the model as it would both write tables and then dynamically read back from those same tables. Our pipelines were very linear and did not permit that kind of dynamic operation.”
Emerging data silos
Already at this small scale, long-term issues related to data discovery and collaboration started to emerge.
“We need all data practitioners at Zippi to be working closely together.” says Renan, “ As we were organized previously, people had different contexts about the company. Analysts on the business team were not aware of what was happening on the risk team or the growth team, and had no visibility into the data they were using.”
Moving to a centralized platform and a “single pane of glass,” Zippi could foster collaboration and autonomy among data practitioners and stakeholders. This would also free up the data engineering team to work on infrastructure and other critical parts of the growing data systems.
Moving to Dagster
The team adopted Dagster incrementally, initially focusing on operationalizing the ML model.
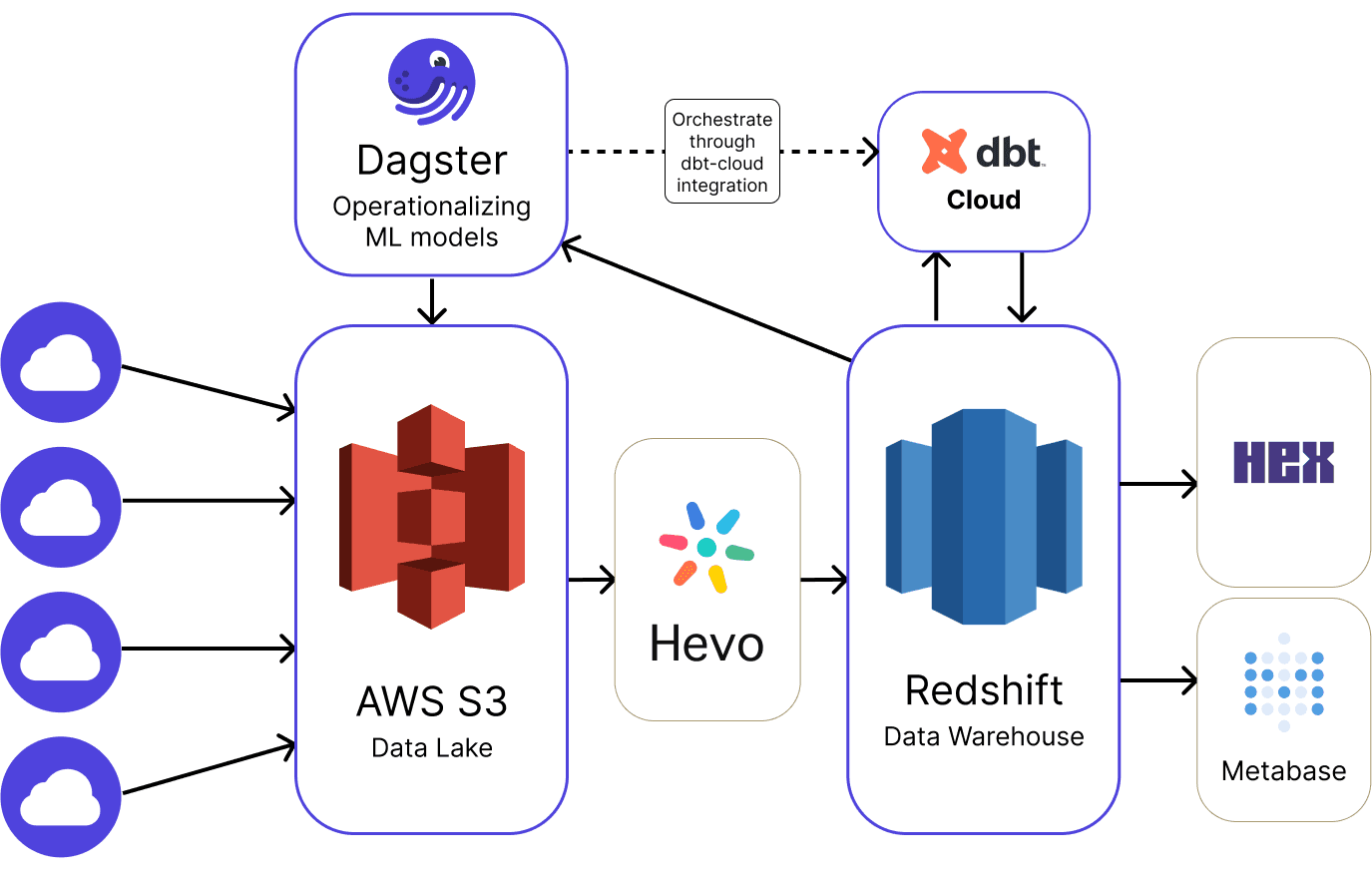
The pipeline now became:
- ETL as a service -> S3 data lake -> Redshift data warehouse
- Transformations run on dbt Cloud orchestrated through the
dagster-dbt-cloudintegration - Dagster runs the ML logic for the loan underwriting analysis returning the score per customer, creating a data asset for the credit team back in S3
- Analysis and visualization by the analytics engineers in Metabase and Hex
- Data observability and quality checks still ran on Metaplane.
The ML model, built on sklearn, would run directly in the Dagster instance.
The team could now continue to innovate and test out the ML model while supporting the critical operations of the business.
Next step: orchestrating the pipelines end-to-end
It rapidly became apparent that Dagster could provide a lot more value to the engineering team than simply running the ML models. The next step was to orchestrate the dbt transformations through Dagster, using the dbt integration.
To track the entire lineage of their data, the team used Dagster's dbt integration.
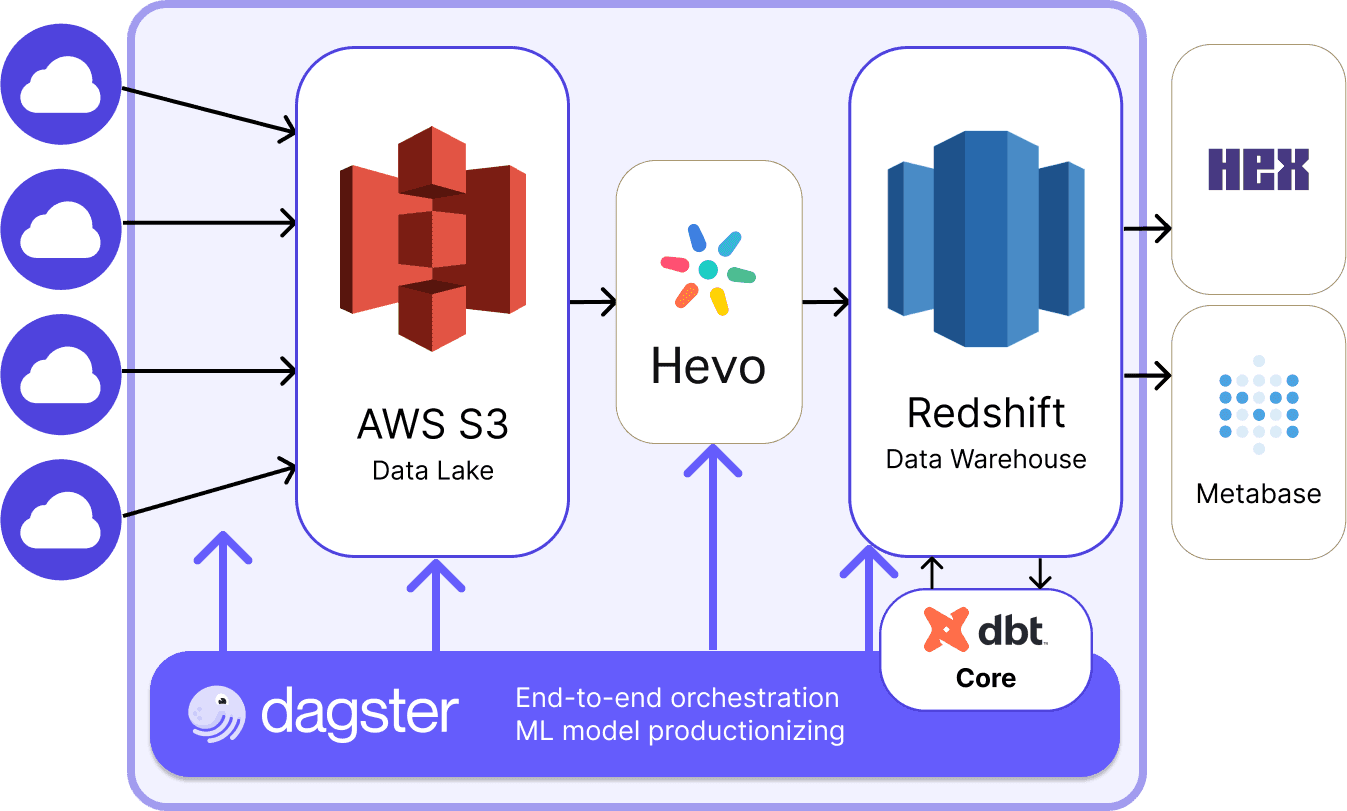
“The ETL service did ingestion automatically, but we developed another process using an external Python script running in a HEX Notebook that would check the success of the ETL process from S3 to Redshift. Then we asked, ‘Why are we doing this? We have Dagster to orchestrate everything.’” explained Renan.
The team set about connecting the entire data stack within a single platform, eliminating the many local scheduling tasks and one-off Python scripts. The data platform was starting to unify.
Running on a Platform.
Today the team has full observability across the data platform, monitoring, and alerting in Slack.
It became a lot easier to diagnose and troubleshoot.
“We had issues with dbt execution monitoring.” says Renan. “dbt Cloud alerts were very limited, with no context on the error. The team would spend many cycles searching through dbt logs to identify the source of an error. In Dagster, we could parse out the error from the execution, and we had more information to troubleshoot quickly.”
Now the state of each data asset is immediately visible, and key assets are easy to locate in the Dagster catalog.
While the team used Dagster+ and dbt Cloud side by side for a while, they eventually concluded that most of the workload could be run directly on Dagster using dbt Core.
Building for the future
With the data platform foundation in place, Renan sees the team building out more integrations, and automating more steps of the process.
Another focus is remodeling the current pipelines following a reorganization at Zippi and a change in the data team structure. This will allow the Zippi centralized data team to better serve internal stakeholders.
Eventually the team would like to take Metaplane out of the equation, running all data observability and data quality checks on Dagster+, further simplifying the stack.
Next, the team will focus on improving analysts' ability to work independently with data, implementing a semantic layer, and supporting the modeling work. Again, Dagster’s self-service features, such as catalog mode, will support the effort.
Additionally, the team is excited to explore more machine learning challenges in the future. Leveraging Dagster, they are confident in their ability to build a robust MLOps stack to streamline the development, deployment, and monitoring of their machine learning models. This will not only enhance their predictive capabilities but also ensure that they can scale their ML efforts efficiently.
A common roadmap for incremental adoption
Zippi’s incremental adoption of Dagster is typical of startups that need to iterate rapidly and illustrates a typical incremental roadmap to moving towards a centralized data platform, reducing data silos while fostering autonomy and collaboration among data practitioners.
Organizations can adopt Dagster at their own pace and model their data architecture around the asset-centric framework, accelerating the development lifecycle, fostering collaboration, safe in the knowledge the solution can grow with their own data needs.





.jpg)
.png)



.png)

