




You need tools that handle the trivial stuff and give you, your team, and your company space to think and act decisively.
The world is distracting, making it hard to focus on what's important. Many so-called “productivity” tools like to pester you with notifications. However, each 5-minute task or interruption adds up throughout the day, the week, and the year.
The disruptive power of workplace interruptions extends far beyond the moment itself. Research indicates it takes 23 minutes to reengage with a task following a disruption fully, and this "resumption lag" erodes productivity throughout the day. During this transition, our brains struggle to juggle multiple mental contexts simultaneously, clouding cognitive resources and compromising performance. These seemingly minor disruptions systematically undermine both efficiency and quality.
Contrary to what some people say, tool selection does matter. You need tools that handle the trivial stuff and give you, your team, and your company space to think and act decisively.
We recently did a Deep Dive with Lee Littlejohn from US Foods where he talked about how he used Dagster as a basis for his company’s data platform and made thoughtful design decisions to make sure that everyone who works in the data platform only needs to focus on what is important to them.
Individually
Operating in a fragmented data stack is a disjointed experience. You may need to log in to multiple platforms to understand what is happening, and each switch of tools creates an opportunity to get distracted.
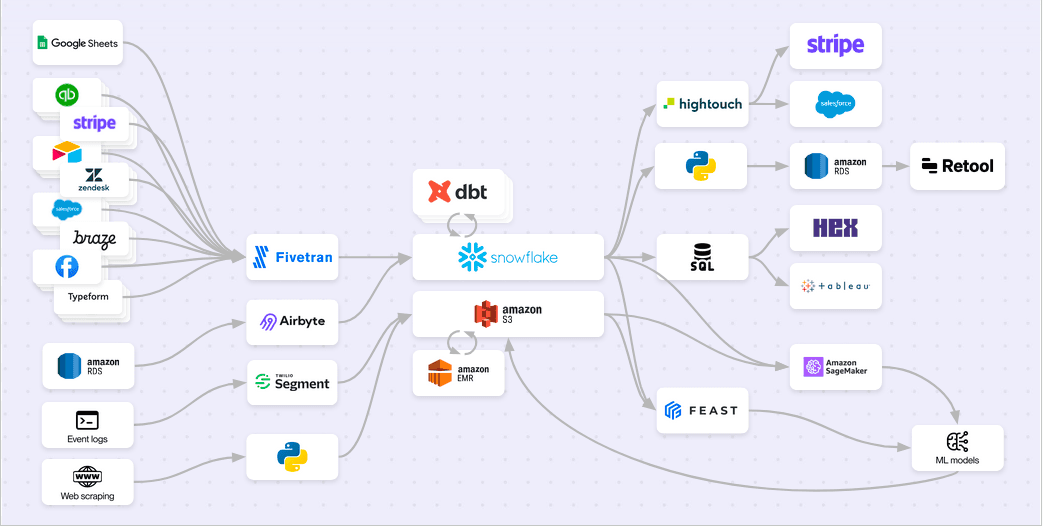
The Orchestrator is perfectly positioned to serve as the system of record for the data platform. It understands the state of your data assets and how they are connected to each other. This enables real-time alerting when an asset or check fails, a catalog so you can browse and make sense of your platform, and intelligent automation and retry policies that keep your pipelines flowing.
With Dagster, you get your entire data platform in one tool, from ingestion to dashboarding and everything in between. So, if a dashboard is broken, you will get an alert about which upstream asset failed and why. Then, you log into the Dagster UI, re-run the asset, and refresh the dashboard. Quickly resolve the issue and build confidence in your platform with your stakeholders.
As a team
Data Your tooling should support collaboration, testing, and embedding organizational context so there is no single point of failure and the platform can scale to meet the business needs. Dagster is code first by design to accommodate this need for flexibility and stability.
Code is the best form of documentation since it is the source of truth. Using code as the basis of your documentation also provides several benefits:
- Code is versioned
- Code is collaborative
- Simplifying Onboarding - just take a tour of the repo!
When you structure your data stack around software engineering best practices, you get the benefits of stacking automation with CI/CD and testing and encoding business logic to meet your needs. When your platform incorporates a thoughtful CI/CD process, you harden your system to catch breaking changes before they land in production. Layering data quality into your system further increases stability by boosting confidence in the data. Opening up new capabilities for customer-facing applications and more sophisticated internal use cases is foundational to scaling your data platform while keeping the team lean.
When your data platform is reliable, your team will spend less time putting out fires. The mental space created allows you to take advantage of strategic opportunities as they present themselves and do some proactive exploratory analysis to give stakeholders what they need before they think about it.
Organizational
At the organizational level, cognitive overload manifests as systemic confusion that affects business decisions and outcomes. Leaders commonly ask: - "Is this data correct and up-to-date?" - "What are our data platform's capabilities and limitations?" - "Are we ready to implement AI initiatives?" - "What happens when key team members are unavailable?"
These uncertainties lead to delayed decisions, lost opportunities, and inefficient allocation of resources. When data is misunderstood, isn't used—or worse, it's used incorrectly. Dagster addresses these organizational challenges by:
Building institutional knowledge - By encoding business logic into version-controlled code and providing comprehensive asset catalogs, Dagster creates a reliable system of record that persists beyond any individual team member.
Increasing stakeholder confidence - With end-to-end lineage and integrated data quality checks, executives and department heads can trust that the insights they're using for decisions are accurate and current.
Enabling strategic agility - When your data platform runs reliably with minimal maintenance overhead, your organization can quickly pivot to new initiatives and opportunities without being constrained by technical debt. Organizations using Dagster report significant improvements in their ability to make data-driven decisions, with stakeholders across departments increasingly relying on data products for daily operations and strategic planning.
Total Cost of Operations
Regarding data platform costs, it's common to focus on recurring operating expenses like cloud spending, data warehouse credits, and vendor subscriptions. But that obscures the total picture. Viewing your data operation from a Total Cost of Operations (TCO) approach makes you more strategic with your tool selection, team composition, and culture. Here are some ways that Dagster helps reduce TCO:
Uptime
If data orchestrators help with anything, it's ensuring all of your data is in the right place, at the right time, and correctly. If any of these are wrong, the data team needs to spend time fixing the issue. These incidents can range from the trivial number being off to SLA violations, which can be costly to the company.
Training & Onboarding
Documentation, standardization, and developer experience are the main pillars of effective collaboration and onboarding. Your data platform is complex and highly contextual to your organization. Ideally, new team members should be able to understand and contribute as part of their onboarding process. We recently launched components designed with this in mind; injecting context into your data platform lowers the skill curve necessary for new and less experienced team members to contribute to the platform. Platform owners can build abstractions specific to the work streams so everyone is as productive as the strongest team members.
import dagster as dg
from dagster_dbt import DagsterDbtTranslator, DbtCliResource, DbtProject, dbt_assets
class CustomDagsterDbtTranslator(DagsterDbtTranslator):
def get_asset_key(self, dbt_resource_props: dict) -> dg.AssetKey:
return super().get_asset_key(dbt_resource_props).with_prefix("snowflake")
dbt_project = DbtProject(project_dir="../../jaffle_shop")
dbt_project.prepare_if_dev()
@dbt_assets(
manifest=dbt_project.manifest_path,
dagster_dbt_translator=CustomDagsterDbtTranslator(),
)
def jaffle_shot_dbt_assets(context: dg.AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
defs = dg.Definitions(
assets=[jaffle_shot_dbt_assets],
resources={"dbt": dbt_project},
)type: dagster_dbt.DbtProjectComponent
attributes:
dbt:
project_dir: "../../jaffle_shop"
asset_attributes:
key: "snowflake/{{ node.name }}"Here’s an example on how you would integrate with a dbt project in vanilla Dagster:
This is the same logic with Components in Yaml:
Team Capacity
Historically, data teams were seen as essential overhead but data is becoming a more strategic part of the organization. Investing in this strategic resource takes time, skilled professionals, and infrastructure. With those two facts in mind, it’s essential to task data teams on projects that move the organization forward. If they can't focus on execution because they are chasing down errors and data discrepancies, you end up with a data team that is burnt out and stakeholders who are not getting what they need.
A recurring theme we hear from customers is that Dagster reduces confusion and reactive work for their data operations, allowing them to focus on more impactful work. We recently commissioned a Total Economic Impact report through Forrester Consulting. Check out the whole report here.

How Dagster Makes It Happen
Dagster's approach to data orchestration goes beyond scheduling jobs to provide true cognitive relief for your entire data operation.
What Dagster Does For You
End-to-end lineage gives you complete visibility into how data transforms from raw inputs to final outputs. This visibility doesn't just help with debugging—it fundamentally changes how you understand your data ecosystem, letting you make decisions with complete context rather than partial information.
Improved asset selection syntax means you can target precisely what you need without wading through unnecessary complexity. When you need to rerun part of your pipeline or investigate an issue, you'll spend seconds finding what you need, not hours.
Catalog and rich asset metadata transform documentation from an afterthought to an integrated part of your workflow. When team members need to understand what a table contains or its structure, that information is right there—no context switching is required.
Alerting works proactively rather than reactively. Instead of responding to panicked messages about broken dashboards, you'll address issues before they impact downstream consumers.
We've also built numerous quality-of-life improvements that add to meaningful cognitive relief. For example, Dagster automatically handles daylight savings time transitions—a small thing that prevents entire classes of time-based errors that plague other orchestrators.
Components
We recently unveiled low-code interface Components. This is a sea change in how teams build and share their data platforms. Low-code tools for data work generally fall short because they lack the flexibility and context necessary to deliver value. With Components, the data platform owner defines guardrails and abstracts away the complexity. So, the less technical users can build with a simplified YAML or Python interface. Speeding up data product velocity and accessibility across the team.
Our founder and Chief Technology Officer Nick Schrock will be hosting a webinar on April 16th where he will explain the vision behind components and show how this is the future of data platforms. Register today.





.jpg)
.png)



.png)

