




Making Python package management simple and how Dagster leverages uv.
We’re big fans of Python — it’s intuitive, beginner-friendly, and remarkably versatile. Its flexibility makes it an ideal foundation for a wide range of data-centric roles. And the love for Python extends far beyond data teams; it has held the top spot in the TIOBE index of preferred programming languages for the last few years.
However if you ask people what they don’t love about Python, you will get an almost universal answer: package management. Python is great once you get going but its setup and installation can lead to headaches, especially when you work on large collaborative projects with complex dependencies.
There have been improvements over the years and several tools have tried to fill the gap but many feel like a bandaid on a structural problem. That is why we have been so excited about the rise of uv. Rather than attempting to patch existing tooling, uv reimagines what an ideal package manager should be — and then applies that vision to Python. This is similar to Dagster which reenvisioned data orchestration from the ground up and built an orchestration system around assets.
Because uv shares this philosophy of thoughtful software engineering, we have found that uv pairs particularly well with Dagster and what we are building. But before going into how uv and Dagster compliment each other, it might be worth talking about Python’s history with package management.
Python Package History
2008 - pip
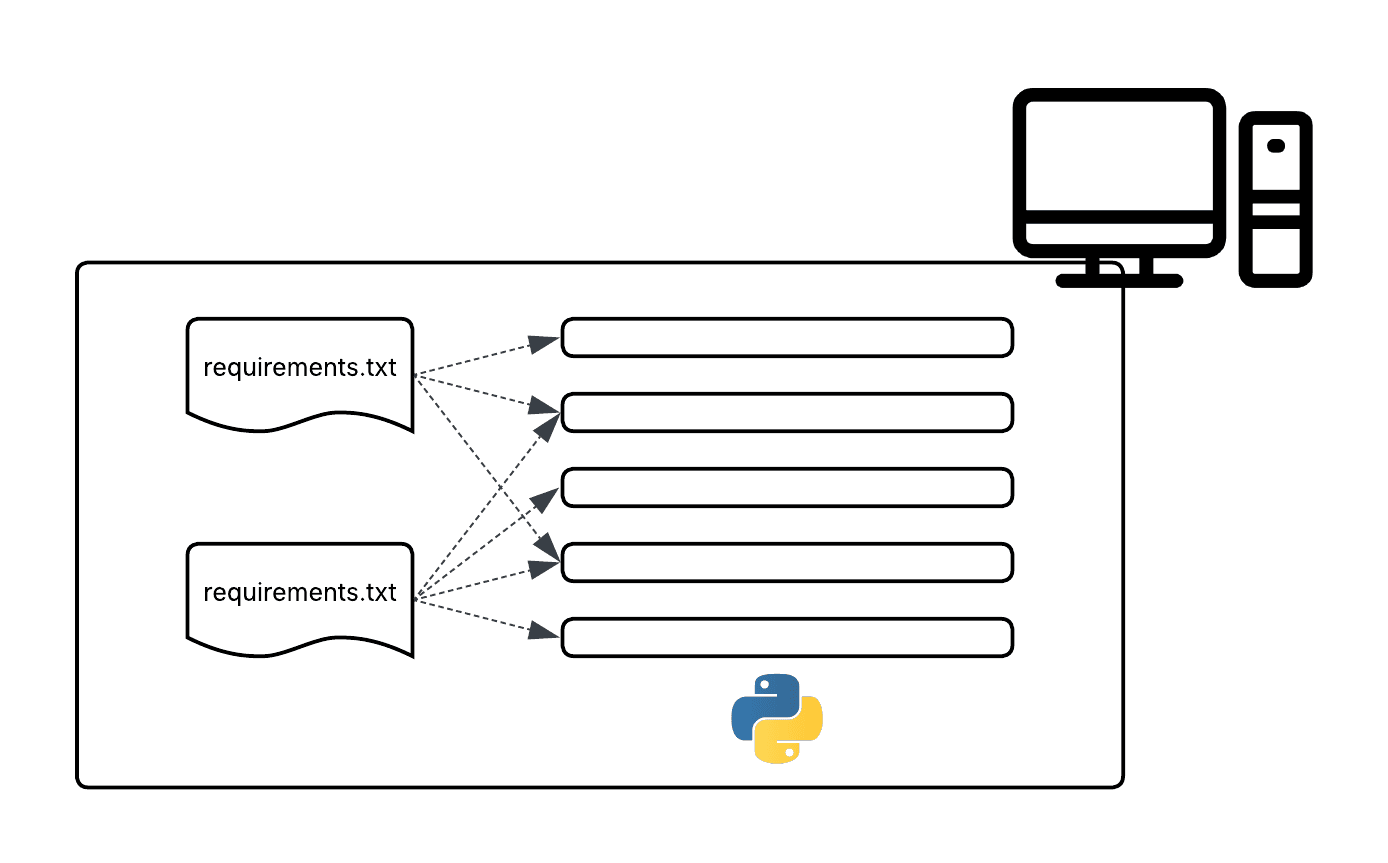
It may surprise Python users to know that the language existed for almost 20 years before pip was introduced. pip gave Python users a much smoother way to add and uninstall packages as needed. However, while helpful, pip alone was never the safest or most reliable tool for managing packages in complex environments.
There are several limitations to using pip by itself. Most notable is the lack of any built-in-environment management. Without isolated environments, all packages are installed into a shared global space, which can quickly lead to dependency conflicts. There are tools like virtualenv, venv, or conda that can help manage environments but layering them in can add complexity and additional coordination, especially in team settings.
Another persistent challenge with pip is dependency resolution — particularly due to Python’s lack of native support for multiple versions of the same package. For instance, installing a package like requests with a simple pip install requests may work at first, but your project can easily break later — either locally or when shared — due to unexpected version mismatches. By default, pip installs the latest available version of a package system-wide, without enforcing version consistency across environments. While version pinning (pip install requests==2.0.0) offers some control, it introduces its own limitations — namely, every project on your machine must now conform to that specific version, increasing the risk of conflicts. The problem compounds with sub-dependencies — the packages that your installed packages depend on. As your project grows, these transitive dependencies can introduce subtle incompatibilities that are hard to track down. Tools like pip freeze try to mitigate this by capturing the exact environment state, but the resulting dependency tree often becomes brittle, overly restrictive, and challenging to maintain.
2018 - poetry
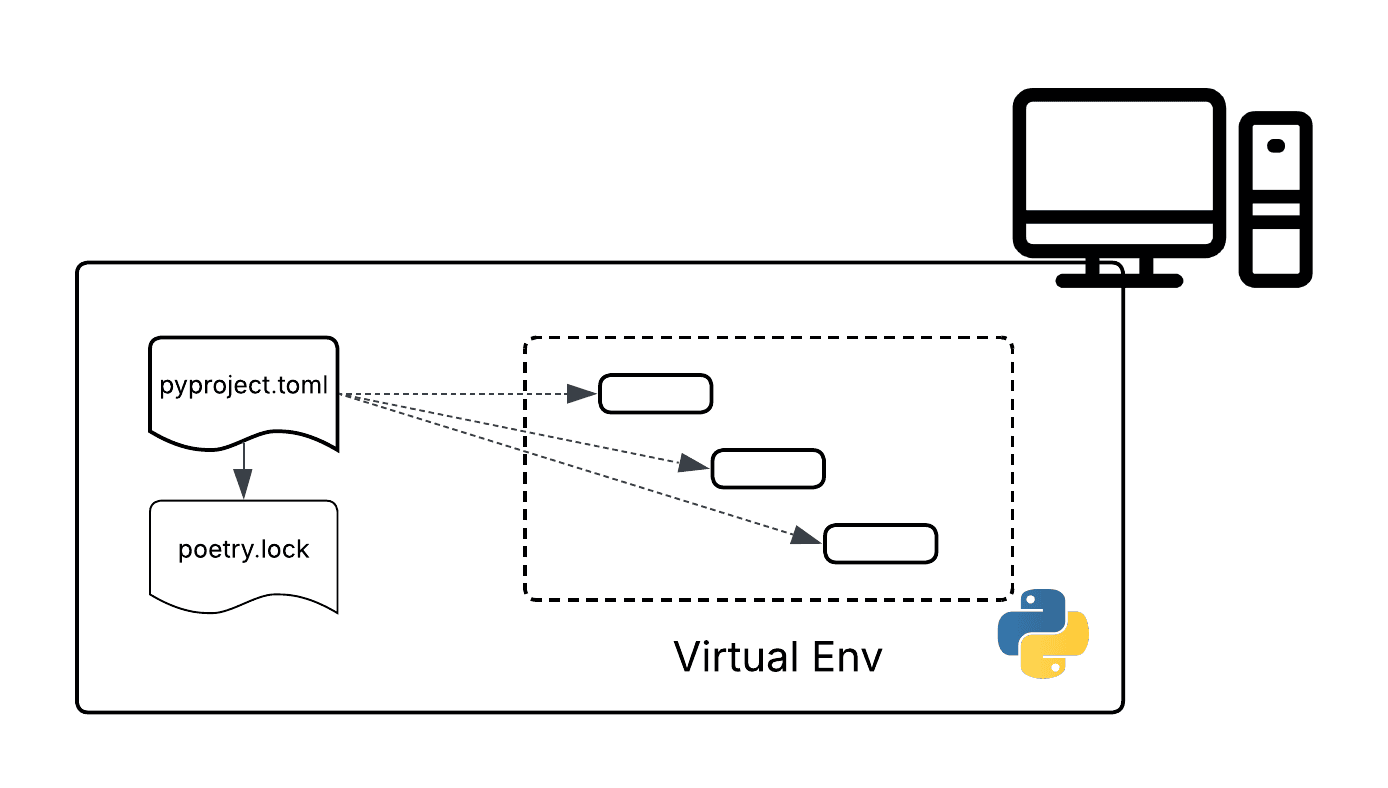
The shortcomings of pip left an opening for other tools to try and fix package management in Python. One popular tool is poetry which has several advantages over pip. First it handles both package dependencies and the virtual environment within the same tool. It also handles some of the conflict resolution issues by maintaining a separate lock file. This file is generated from an initial list of required dependencies and locks in specific versions of each dependency to avoid conflicts.
While a big improvement over pip, poetry still has issues. The most notable being performance. Python is not the most efficient language and installing the necessary packages, even for a small project, can take minutes. This is because all dependencies and sub-dependencies need to be checked for conflicts. Doing this once is not an issue but it can add up across automated builds and deployments in CI/CD pipelines. Additionally, while the lock file improves determinism, it’s not foolproof. Dependency conflicts or mismatches can still arise. Partially this is because the lock file is generated sequentially, where every package and its dependencies are checked against the dependencies already set. This can result in subtle issues that are difficult to debug — particularly in larger projects with complex dependency trees.
2023 - uv
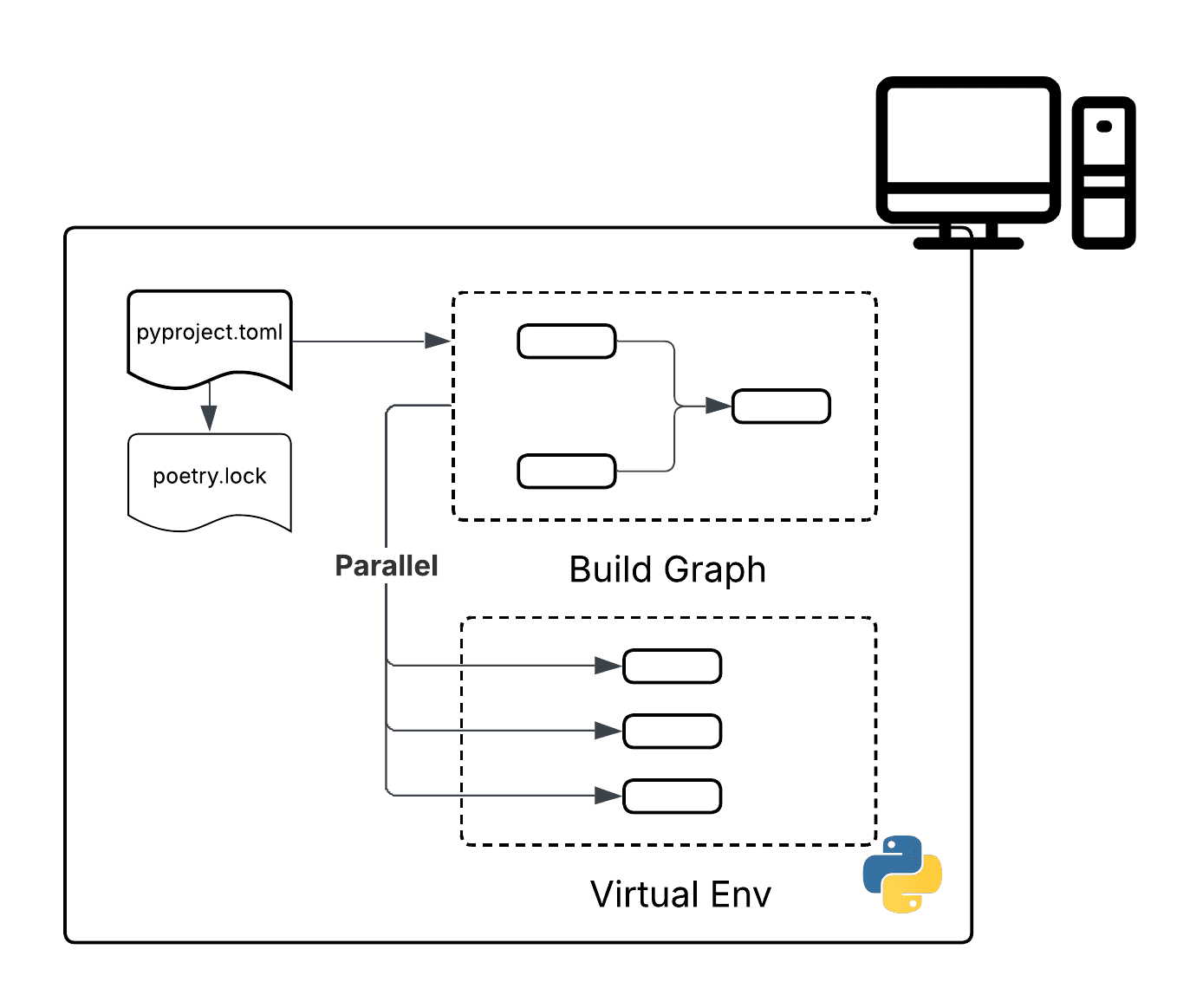
uv is the latest and most promising effort to address Python’s long-standing package management challenges. While it builds on the lessons of earlier tools, much of its inspiration comes from the Rust ecosystem — specifically Cargo, Rust’s powerful package manager and build system. In fact, uv is written in Rust, giving it a substantial performance advantage over tools built in Python.
This performance boost isn’t just due to the language it's written in. uv also takes a more efficient approach to dependency resolution. By computing the entire dependency graph upfront, it enables parallel installation of packages. This makes the lock much safer and much more efficient to install.
How Dagster and uv work together
So why is Dagster so excited about uv? Recently we have been working to make our own scaffolding and build process more efficient. Our users love the ability to spin up multiple code locations for their data platforms. This allows them to cater their dependencies to the specific code location while still connecting everything together under Dagster.
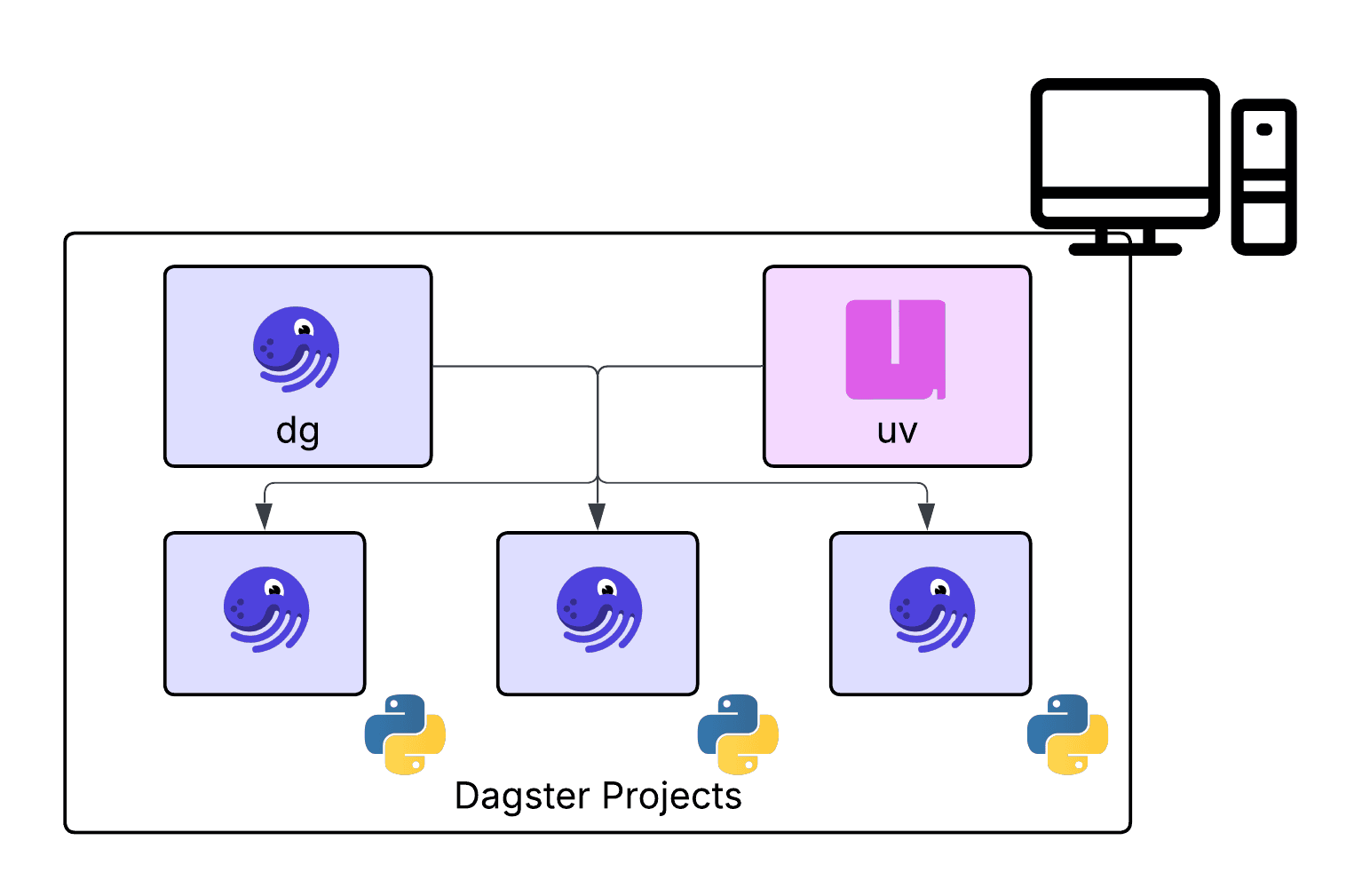
As a Python user, each code space is its own virtual environment. So we wanted to build tooling that matched that development workflow. That is where our CLI tool (dg) comes in.
dg provides opinionated scaffolding that works with uv to quickly spin up Python environments for Dagster. This means that with a single dg command you can jumpstart your Dagster code and the environment to run it in.
To get started we recommend installing dg and uv (instructions). Both can be viewed as system level tools that are not associated with a particular Dagster project. Instead they will help you create Dagster projects anywhere on your machine.
There is a lot more you can do with dg (full documentation). But we are most excited to make the developer process as seamless as possible.
And while Dagster dg and uv work wonderfully together, that does not mean you have to embrace both at the same time. dg is compatible with various Python package managers. However, if you have not tried out uv yet, you may find that it has been the tool missing from your Python stack.





.jpg)
.png)



.png)

