




Most teams build data platforms reactively when you should be architecting one that scales with your business, not against it.
If you have ever had the pleasure of building a data platform from zero, you likely started with a few Python scripts that moved CSV files into a database or maybe even a master spreadsheet. Which is fine when the team is less than 10 people. But then you get blessed with growth. As more sources are added, transformations become more complex, and scheduling is no longer as simple as running a single script. Now you have dozens of scripts, inconsistent error handling, no visibility into what's running, and every new data source feels like a special case.
You know you need a proper data platform, but where do you start?
Most teams build data platforms reactively, adding tools and patterns as needs arise. This leads to fragmentation, inconsistent standards, and maintenance burdens that slow down the entire organization. The orchestrator you choose (or don't) determines whether your platform becomes a competitive advantage or technical debt that slows everything down.
This post provides a framework for architecting a data platform that scales with your business, rather than against it.
The Fragmentation Problem
Modern data stacks involve a hodgepodge of specialized tools rather than a single monolithic system. While this unbundling provides flexibility, it can also lead to fragmentation and maintenance burdens.
smava, a German fintech, experienced this firsthand. Before adopting a unified platform, different engineers pushed scripts to various locations, monitored jobs through unique dashboards, and applied different standards for data quality. The result was constant "alert fatigue" and frequent outages.
By adopting a centralized control plane, they standardized scheduling, error handling, alerting, and lineage tracking. They ended up with a platform that works for them with Zero downtime, and developer onboarding was reduced from weeks to 15 minutes.
Core Platform Principles
Start with Orchestration
The orchestrator is the beating heart of your platform. Choose it first or early on, then build around it. Modern Orchestrators are a considerable point of leverage for data teams. Setting consistent standards across all pipelines, offering a single view of what's running and failing, and shared patterns that reduce onboarding time.
Adding orchestration as an afterthought can lead to inconsistent patterns and increased operational complexity. For a deeper look at what a modern orchestration platform provides, see our platform overview.
Design for Composability
A composable data platform utilizes loosely coupled, interchangeable components rather than rigid, tightly integrated solutions. New tools can be integrated without disrupting existing flows. These days, top data teams are utilizing metadata-driven pipelines, where templates or components are used to dynamically build complex pipelines using simple configurations.
Otto, one of Germany's largest e-commerce companies, learned this when unifying six different teams. Their composable approach with orchestration, storage, and cataloging separated by abstraction allowed them to transition by adjusting configuration rather than rebuilding pipelines.
Key principles include separating concerns through abstraction layers, utilizing standard interfaces, externalizing configuration, and avoiding tight coupling between tools.
The Payoff
The payoff for getting this right is substantial. Teams with well-architected platforms ship faster, onboard engineers in days instead of weeks, and spend their time building new capabilities rather than firefighting. Teams without them burn cycles on maintenance, struggle to hire because nobody wants to work on a mess, and watch as data quality issues erode trust across the organization.
Implementation: Building with Dagster
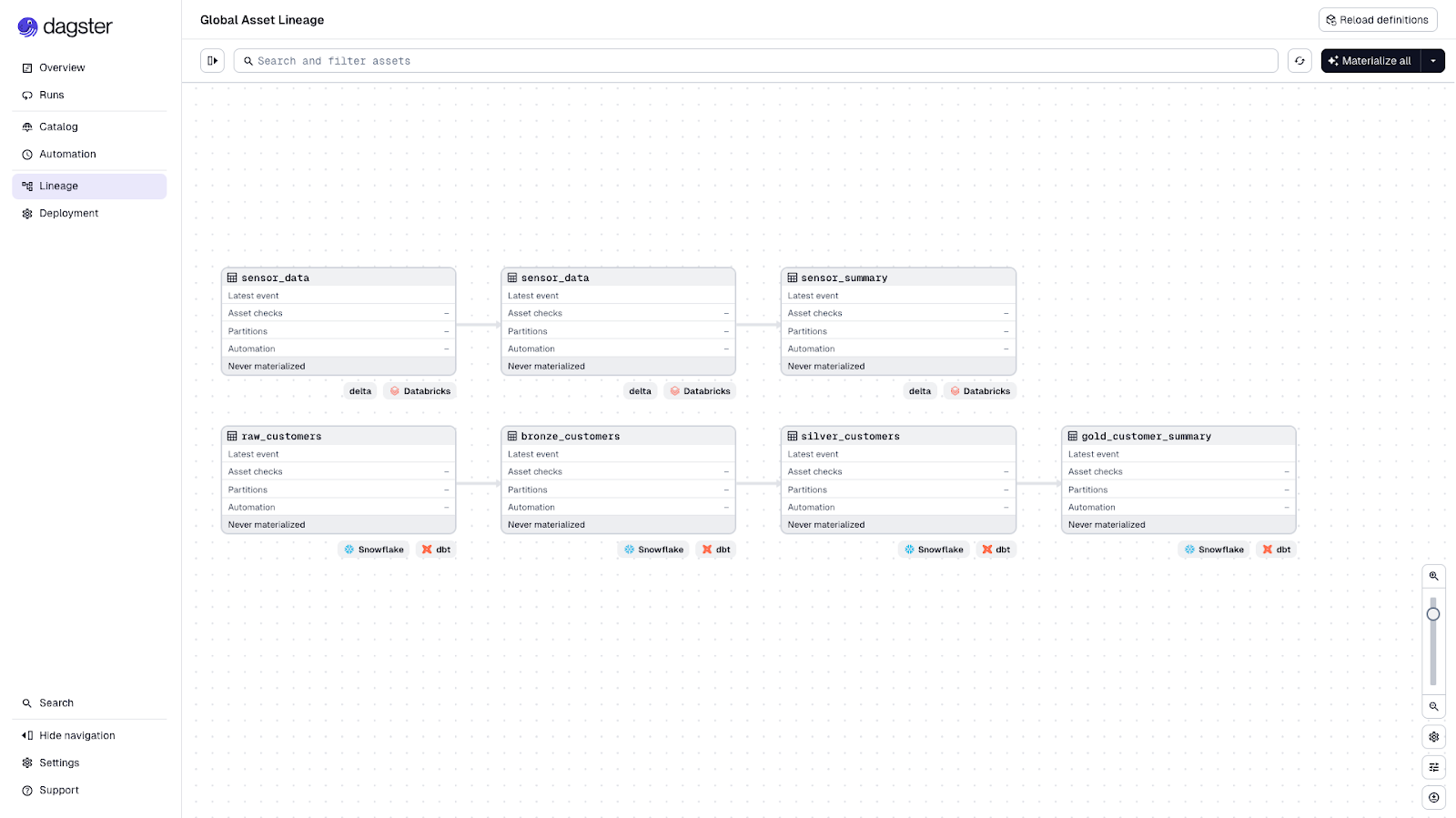
Real platforms often have multiple teams working with different architectures and tools. One team might use Databricks with Delta Lake while another uses Snowflake with dbt. The challenge is letting each team work independently while maintaining global visibility across everything.
Dagster addresses this by utilizing multiple code locations. Which are separate projects that deploy independently but are presented in a single, unified UI. Here's the structure from our multi-platform-data example:
project_databricks_and_snowflake/
├── dg.toml # Workspace configuration
├── dagster_cloud.yaml # Dagster+ deployment configuration
├── deployments/
│ └── local/
│ └── pyproject.toml # Local environment for dg commands
├── projects/
│ ├── databricks-delta/ # Code location 1
│ │ ├── pyproject.toml
│ │ ├── tests/
│ │ └── src/databricks_delta/
│ │ ├── definitions.py
│ │ └── defs/
│ │ ├── components/lakehouse/
│ │ └── resources.py
│ └── snowflake-medallion/ # Code location 2
│ ├── pyproject.toml
│ ├── tests/
│ └── src/snowflake_medallion/
│ ├── definitions.py
│ ├── dbt_project/
│ └── defs/
│ ├── components/medallion/
│ └── resources.py
├── .env.example
├── pyproject.toml
└── README.mdEach team owns its code location with its own dependencies, deployment schedule, and toolchain. But platform teams and stakeholders see everything in one place: unified lineage, cataloging, and observability across both Databricks and Snowflake assets.
The dg.toml workspace config ties it together:
directory_type = "workspace"
[workspace]
[[workspace.projects]]
path = "projects/databricks-delta"
[[workspace.projects]]
path = "projects/snowflake-medallion"Run dg dev, and both code locations load into a single Dagster instance. Teams iterate independently; leadership gets the full picture.
Choosing Your Architecture Pattern
Your architecture choice depends on your constraints:
- ETL suits stable, well-defined pipelines where you don't need raw data
- ELT works when you want flexibility and can afford warehouse compute
- Lakehouse fits high-volume scenarios where you need to separate storage from compute
Most production platforms combine all three. The key is using consistent orchestration and data quality patterns across them.
What Success Looks Like
Big Cartel: One Engineer, Enterprise-Grade Platform
Big Cartel had data scattered across multiple systems with no visibility. Business metrics varied "depending on the day you asked." Patrick, their solo data engineer, built a platform with Airbyte, Dagster, dbt, and Snowflake. He went from "waiting for dashboards to break" to proactive monitoring with a custom Slack-integrated alerting system—all with zero excessive configuration. Data quality checks built into the pipeline caught issues before stakeholders did.
smava: Zero Downtime in Regulated FinTech
smava was drowning in alert fatigue with frequent outages undermining trust. After rebuilding around Dagster, they achieved zero downtime starting in July 2025, reduced onboarding from weeks to 15 minutes, and automated the generation of 1,000+ dbt models. Their observability investment paid off immediately—"Alerts directly went to zero."
Otto: Escaping "YAML Hell" at Enterprise Scale
Otto had six teams using different tools. Some were trapped in "YAML Hell" with Argo Workflows. Airflow users couldn't test locally without production environments. After unifying on Dagster, they eliminated configuration sprawl with Python-native development, enabled data scientists to contribute directly to pipelines, and built reusable "asset factories" for common patterns. The result: "better community feeling and collaborative energy between teams."
The Alternative
The alternative is familiar to most data teams: constant firefighting, metrics nobody trusts, onboarding that takes months, and talented engineers leaving because they're tired of maintaining brittle systems. The platform patterns in this post exist because teams got tired of that reality and built something better.
Scaling Your Team Alongside Your Platform
Platform architecture is only half the equation. As your platform grows, you'll face questions beyond technology: How should responsibilities be divided? Who owns the data catalog? How do you onboard engineers without creating bottlenecks?
We've compiled lessons from dozens of data teams on building systems that scale with clarity, reliability, and confidence. Download our free guide: How to Scale Data Teams.
Get Started
Three things to do this week:
- Audit your current platform: Map existing tools and patterns. Identify fragmentation.
- Choose your orchestrator: If you don't have one, pick one. If you have one, ensure it's the right one (Dagster).
- Standardize one pattern: Select a common use case (e.g., daily batch ingestion) and use it as the template for future pipelines.
Resources
- Multi-platform-data example — Simple Dagster project with Databricks and Snowflake patterns under separate code locations.
- Dagster Documentation
- How to Scale Data Teams — Free ebook on team and platform scaling
- Customer Stories — More case studies from Big Cartel, smava, Otto, easyJet, US Foods, and others





.jpg)
.png)



.png)

