




A structure for a reliable, maintainable data platform design.
In the ever-evolving landscape of data engineering and orchestration, managing complex workflows and ensuring seamless collaboration across teams can be challenging. This is where Dagster, a powerful data orchestration platform, comes into play. Dagster not only helps in defining, scheduling, and monitoring data pipelines but also introduces innovative architectural concepts that enhance the robustness and scalability of data workflows.
One such concept is the “code location” architecture. Code locations in Dagster play a crucial role in organizing, isolating, and managing the code that defines your data assets and pipelines. By understanding and leveraging code locations, you can achieve better dependency management, fault tolerance, and organizational clarity in your data projects.
In this blog post, we will dive into the intricacies of Dagster’s code location architecture. We will explore what code locations are, why they are important, and how they can be effectively utilized to improve your data orchestration workflows. Whether you are a seasoned data engineer or just getting started with Dagster, this post will provide valuable insights into making the most of this powerful feature.
In this article, we'll cover:
- What is a Code Location
- Benefits of Code Locations
- Practical use cases
- How to define and use Code Locations
- Real world examples
- Conclusion
What is a Code Location?
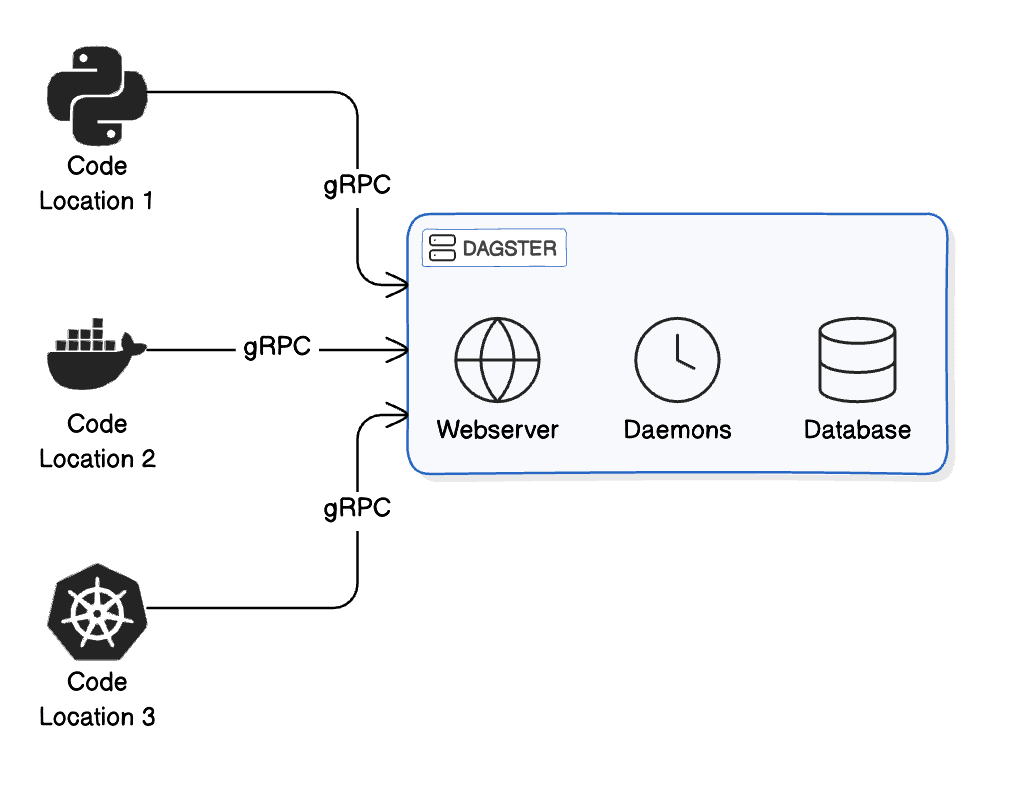
In Dagster, a code location is a fundamental concept that helps in organizing and managing the code that defines your data assets and pipelines. A code location serves as a reference to a specific Python module containing an instance of Definitions, which encapsulates your data assets, jobs, schedules, and sensors. Additionally, it includes the Python environment required to load and execute this module.
Components of a Code Location
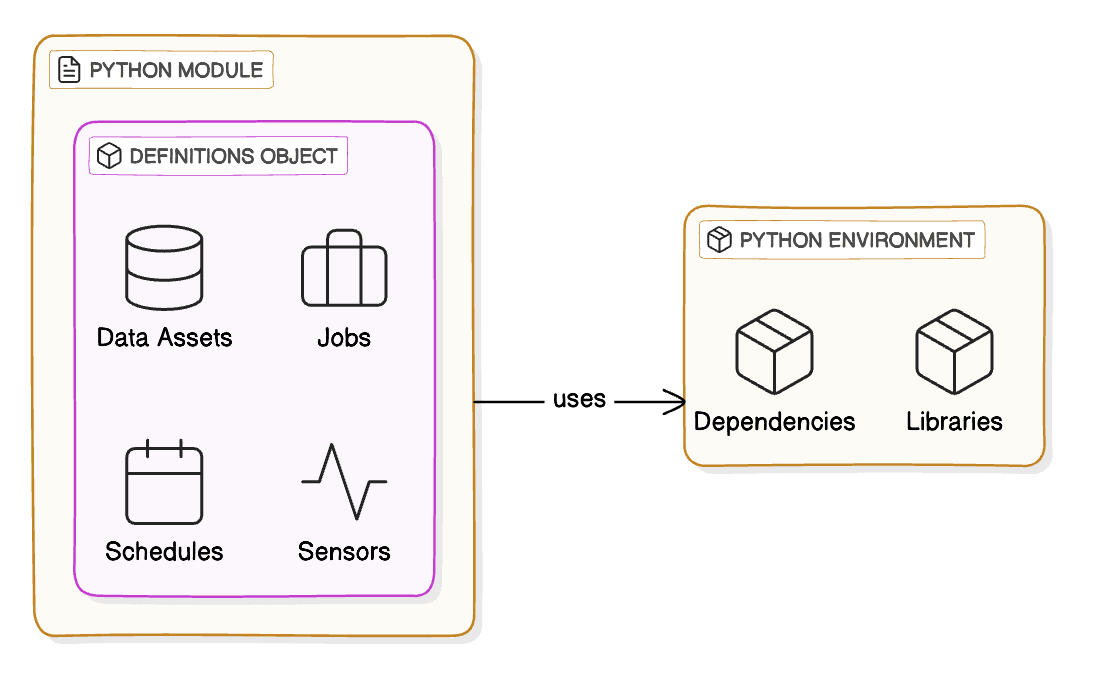
- Reference to a Python Module:
- A code location points to a Python module where your
Definitionsobject resides. This object is a central place where you define all your data assets, jobs, schedules, and sensors.
- A code location points to a Python module where your
Here is an example of a basic asset and a code location Definitions object:
from dagster import Definitions, asset
@asset
def my_asset():
return "Hello, Dagster!"
defs = Definitions(assets=[my_asset])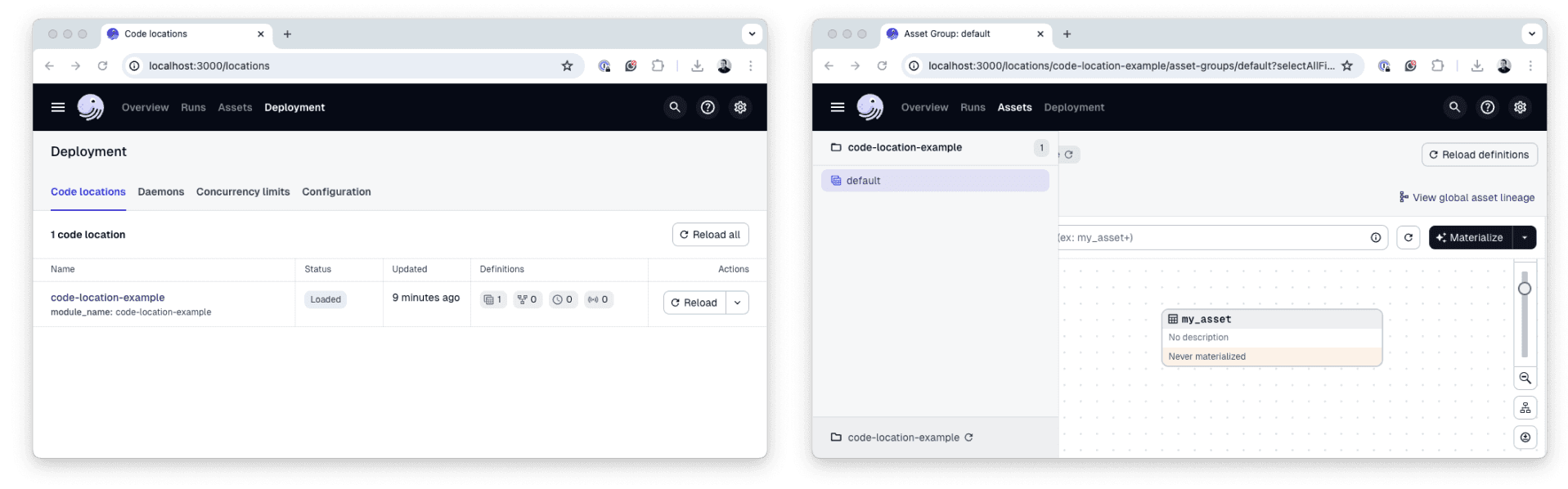
Screenshots of our simple Dagster Software-defined Asset as rendered in the Dagster UI.
- Python Environment:
- The code location also specifies the Python environment that can load and execute the module. This environment includes all the necessary dependencies and libraries required by your code.
- This separation allows different code locations to have different dependencies, making it easier to manage complex projects with varying requirements.
How Code Locations are Loaded
Dagster tools, such as the command-line interface (CLI) and the web-based user interface (UI), use code locations to load and access your definitions. When you start the Dagster UI or run a Dagster command, the system loads the specified code locations, making the defined assets, jobs, schedules, and sensors available for execution and monitoring.
By organizing your code into distinct locations, you can achieve several benefits, including better dependency management, fault tolerance, and organizational clarity. In the next section, we will explore these benefits in detail and discuss why code locations are essential for effective data orchestration.
More details on this can be found in the Dagster Docs here.
Benefits of Code Locations
Dagster’s code location architecture offers several key benefits that enhance the robustness, scalability, and manageability of your data orchestration workflows. Let’s explore these benefits in detail:
Isolation and Dependency Management
One of the primary advantages of using code locations is the ability to isolate and manage dependencies effectively. Each code location can have its own set of dependencies, allowing different teams or projects to use different versions of libraries without conflicts.
- Separate Library Dependencies:
- Different teams can work on separate code locations with their own dependencies, ensuring that changes in one team’s environment do not affect others.
- For example, Team A can use
pandas==1.2.0while Team B usespandas==1.3.0, without any interference.
- Version Management:
- Code locations enable you to manage different versions of Dagster and other libraries within the same project. This is particularly useful when migrating to new versions or testing new features.
Fault Tolerance and Reliability
Code locations contribute to the fault tolerance and reliability of your data orchestration system by isolating failures and ensuring independent evaluation of schedules and code loading.
- Defending Against Starvation and Coupled Failures:
- By isolating code into different locations, you can prevent a failure in one location from affecting the entire system. This isolation helps in maintaining the overall stability and reliability of your workflows.
- Independent Evaluation:
- Schedules and sensors are evaluated independently within their respective code locations. This means that a failure in one schedule or sensor does not impact others, ensuring continuous and reliable operation.
Organizational Clarity
Code locations provide a clear organizational structure for your data assets and pipelines, making it easier to manage and navigate complex projects.

- Grouping and Organizing Definitions:
- You can group related assets, jobs, schedules, and sensors within a single code location, providing a clear and logical structure to your project.
- For example, you might have separate code locations for different business domains, such as
sales,marketing, andfinance.
- Unique Namespaces:
- Each code location has its own unique namespace, preventing naming conflicts and ensuring that definitions are easily identifiable and manageable.
By leveraging these benefits, you can create a more robust, scalable, and manageable data orchestration system. In the next section, we will explore practical use cases that demonstrate how code locations can be effectively utilized in real-world scenarios.
Practical Use Cases
Understanding the theoretical benefits of code locations is essential, but seeing how they can be applied in real-world scenarios can provide a clearer picture of their practical value. Here are some use cases that demonstrate how code locations can be effectively utilized in various contexts:
Team Collaboration
In large organizations, multiple teams often work on different parts of a data pipeline. Code locations facilitate seamless collaboration by allowing each team to work independently without interfering with others.
- Scenario: Imagine a company with separate teams for data ingestion, data transformation, and data analytics. Each team can have its own code location, ensuring that changes in one team’s code do not affect the others.
- Data Ingestion Team: Uses a code location to manage all assets and jobs related to data ingestion.
- Data Transformation Team: Has a separate code location for transformation logic and dependencies.
- Data Analytics Team: Maintains its own code location for analytics and reporting tasks.
This separation allows each team to focus on their specific tasks while maintaining a clear boundary between different parts of the pipeline.
Environment Separation
Running the Dagster webserver/UI in a separate environment from user code can enhance security and stability. Code locations make it easy to achieve this separation.
- Scenario: A company wants to ensure that the Dagster webserver/UI is isolated from the environments where user code is executed. This can be particularly important for security-sensitive applications.
- Webserver Environment: Runs the Dagster webserver/UI with minimal dependencies, ensuring a lightweight and secure environment.
- User Code Environments: Each code location runs in its own environment with the necessary dependencies for executing user-defined assets and jobs.
This separation not only enhances security but also improves the stability of the Dagster webserver/UI by isolating it from potential issues in user code.
Version Testing and Migration
When migrating to new versions of libraries or testing new features, code locations provide a safe and isolated environment for experimentation.
- Scenario: A team wants to test a new version of a library without disrupting the production environment.
- Production Code Location: Uses the stable version of the library.
- Testing Code Location: Uses the new version of the library for testing and validation.
By isolating the testing environment, the team can thoroughly evaluate the new version without risking the stability of the production system.
Note that for Dagster+ users, Branch Deployments is a much preferable approach to version testing and migration.
Multi-Tenancy
For organizations that manage multiple clients or projects, code locations can help in maintaining clear boundaries and ensuring that each client’s data and workflows are isolated.
- Scenario: A data consultancy firm manages data pipelines for multiple clients. Each client has unique requirements and dependencies.
- Client A Code Location: Contains all assets, jobs, and dependencies specific to Client A.
- Client B Code Location: Maintains a separate code location for Client B’s workflows and dependencies.
This approach ensures that each client’s data and workflows are isolated, reducing the risk of cross-contamination and simplifying management.
These practical use cases illustrate how code locations can be leveraged to improve collaboration, enhance security, facilitate testing, and manage multi-tenancy. In the next section, we will provide a step-by-step guide on how to define and use code locations in Dagster.
How to Define and Use Code Locations
Now that we’ve explored the benefits and practical use cases of code locations, let’s dive into the steps for defining and using code locations in Dagster. This section will provide a step-by-step guide to creating a code location, along with example code snippets to illustrate the process.
Step 1: Create a Definitions Object
The first step in defining a code location is to create a Definitions object. This object will encapsulate your data assets, jobs, schedules, and sensors.
from dagster import Definitions, asset
@asset
def my_asset():
return "Hello, Dagster!"
defs = Definitions(assets=[my_asset])In this example, we define a simple asset my_asset and create a Definitions object that includes this asset.
Step 2: Define the Code Location in a Python Module
Next, you need to place your Definitions object in a Python module. This module will serve as the reference point for your code location.
# my_code_location.py
from dagster import Definitions, asset
@asset
def my_asset():
return "Hello, Dagster!"
defs = Definitions(assets=[my_asset])Save this code in a file named my_code_location.py.
Step 3: Configure the Code Location in Dagster
To make Dagster aware of your code location, you need to configure it in your Dagster instance. This can be done by specifying the code location in your workspace.yaml file.
load_from:
- python_file:
relative_path: "my_code_location.py"
attribute: "defs"In this configuration, relative_path points to the Python module containing your Definitions object, and attribute specifies the name of the Definitions object.
Step 4: Load and Access the Code Location
Once you have configured the code location, you can load and access it using Dagster tools such as the CLI and UI.
- Using the CLI:
- You can directly execute a Dagster job by calling a defined job within the code location:
dagster job launch -j my_job
See more details on the dagster job command in the docs here.
- Using the UI:
- Start the local Dagster webserver, specifying the code location as a module with the
-mflag`:
- Start the local Dagster webserver, specifying the code location as a module with the
dagster dev -m my_code_location
- Navigate to the Dagster UI in your web browser. You should see your code location and the defined assets, jobs, schedules, and sensors.
Step 5: Managing Dependencies
Ensure that the Python environment for your code location includes all necessary dependencies. You can use tools like virtualenv or conda to create isolated environments for each code location.
- Example:
# Create a virtual environment
python -m venv my_env
# Activate the virtual environment
source my_env/bin/activate
# Install dependencies
pip install dagster
pip install other_dependencies
- Once your separate code locations have dependencies managed inside their own virtual environment, you can activate the environments by adding the
executable_pathkey to the YAML for a location:
# workspace.yaml
load_from:
- python_file:
relative_path: path/to/my_code_location_1.py
location_name: arbitrary_code_location_name_1
executable_path: venvs/path/to/my_env_1/bin/python
- python_file:
relative_path: path/to/my_code_location_2.py
location_name: arbitrary_code_location_name_2
executable_path: venvs/path/to/my_env_2/bin/python
- See the Dagster Docs on loading multiple Python environments for details.
By following these steps, you can define and use code locations in Dagster effectively. This setup allows you to organize your data assets and workflows, manage dependencies, and ensure isolation and fault tolerance.
In the next section, we will look at real-world examples and case studies of organizations using code locations to enhance their data orchestration workflows.
Real-World Examples
To further illustrate the power and flexibility of Dagster’s code location architecture, let’s explore some real-world examples and case studies. These examples demonstrate how organizations have successfully implemented code locations to enhance their data orchestration workflows.
Example 1: A Data-Driven E-commerce Company
Scenario: An e-commerce company needs to manage various data pipelines for different departments, including sales, marketing, and inventory management. In this user's case, each department has unique requirements and dependencies. (Note that this is just one way to organize code locations, but you may prefer to organize code locations by technology focus, cross-functional process, or some other way).
- Sales Department:
- Code Location:
sales_code_location - Assets: Sales data ingestion, sales performance metrics
- Dependencies:
pandas,numpy - Example:
- Code Location:
# sales_code_location.py
from dagster import Definitions, asset
@asset
def sales_data():
# Logic to ingest sales data
pass
@asset
def sales_metrics(sales_data):
# Logic to calculate sales performance metrics
pass
sales_defs = Definitions(assets=[sales_data, sales_metrics])
- Marketing Department:
- Code Location:
marketing_code_location - Assets: Marketing campaign data, customer segmentation
- Dependencies:
scikit-learn,matplotlib - Example
- Code Location:
# marketing_code_location.py
from dagster import Definitions, asset
@asset
def campaign_data():
# Logic to ingest marketing campaign data
pass
@asset(deps=[campaign_data])
def customer_segments():
# Logic to perform customer segmentation
pass
marketing_defs = Definitions(assets=[campaign_data, customer_segments])
- Inventory Management Department:
- Code Location:
inventory_code_location - Assets: Inventory levels, reorder alerts
- Dependencies:
sqlalchemy,requests - Example
- Code Location:
# inventory_code_location.py
from dagster import Definitions, asset
@asset
def inventory_levels():
# Logic to fetch inventory levels
pass
@asset
def reorder_alerts(inventory_levels):
# Logic to generate reorder alerts
pass
inventory_defs = Definitions(assets=[inventory_levels, reorder_alerts])By using separate code locations for each department, the company ensures that each team can work independently with their own dependencies and workflows. This setup enhances collaboration, reduces the risk of conflicts, and improves overall efficiency.
Example 2: A Financial Services Firm
Scenario: A financial services firm needs to manage data pipelines for different clients, each with unique data processing requirements and regulatory constraints.
- Client A:
- Code Location:
client_a_code_location - Assets: Transaction data, risk assessment
- Dependencies:
pandas,scipy - Example:
- Code Location:
# client_a_code_location.py
from dagster import Definitions, asset
@asset
def transaction_data():
# Logic to ingest transaction data
pass
@asset
def risk_assessment(transaction_data):
# Logic to perform risk assessment
pass
client_a_defs = Definitions(assets=[transaction_data, risk_assessment])
- Client B:
- Code Location:
client_b_code_location - Assets: Portfolio data, performance analysis
- Dependencies:
numpy,matplotlib - Example
- Code Location:
# client_b_code_location.py
from dagster import Definitions, asset
@asset
def portfolio_data():
# Logic to ingest portfolio data
pass
@asset
def performance_analysis(portfolio_data):
# Logic to analyze portfolio performance
pass
client_b_defs = Definitions(assets=[portfolio_data, performance_analysis])
By isolating each client’s data and workflows into separate code locations, the firm ensures compliance with regulatory requirements and maintains data privacy. This approach also simplifies the management of client-specific dependencies and workflows.
Example 3: A Data Consultancy Firm
Scenario: A data consultancy firm manages data pipelines for multiple projects, each with different data sources and processing requirements.
- Project X:
- Code Location:
project_x_code_location - Assets: Data ingestion, data transformation
- Dependencies:
requests,pandas - Example
- Code Location:
# project_x_code_location.py
from dagster import Definitions, asset
@asset
def raw_data():
# Logic to ingest raw data
pass
@asset
def transformed_data(raw_data):
# Logic to transform raw data
pass
project_x_defs = Definitions(assets=[raw_data, transformed_data])- Project Y:
- Code Location:
project_y_code_location - Assets: Data extraction, data analysis
- Dependencies:
sqlalchemy,scikit-learn - Example:
- Code Location:
# project_y_code_location.py
from dagster import Definitions, asset
@asset
def extracted_data():
# Logic to extract data from a database
pass
@asset
def analyzed_data(extracted_data):
# Logic to analyze extracted data
pass
project_y_defs = Definitions(assets=[extracted_data, analyzed_data])- Project Z:
- Code Location:
project_z_code_location - Assets: Data collection, data visualization
- Dependencies:
beautifulsoup4,matplotlib - Example:
- Code Location:
# project_z_code_location.py
from dagster import Definitions, asset
@asset
def collected_data():
# Logic to collect data from web sources
pass
@asset
def visualized_data(collected_data):
# Logic to visualize collected data
pass
project_z_defs = Definitions(assets=[collected_data, visualized_data])By organizing each project into its own code location, the consultancy firm can manage project-specific dependencies and workflows efficiently. This modular approach allows the firm to scale its operations, onboard new projects quickly, and maintain a clear separation of concerns across different client engagements.
Conclusion
Dagster’s code location architecture is a powerful feature that brings numerous benefits to data orchestration workflows. By understanding and leveraging code locations, you can achieve better dependency management, fault tolerance, and organizational clarity. This architecture allows for seamless collaboration across teams, secure and stable environment separation, efficient version testing and migration, and effective multi-tenancy management.
To recap, we explored the following key points:
- What is a Code Location?: We defined code locations and discussed their components, including the reference to a Python module and the Python environment required to load the module.
- Benefits of Code Locations: We highlighted the advantages of using code locations, such as isolation and dependency management, fault tolerance and reliability, and organizational clarity.
- Practical Use Cases: We provided real-world scenarios where code locations enhance team collaboration, environment separation, version testing, and multi-tenancy.
- How to Define and Use Code Locations: We walked through the steps to create and configure code locations in Dagster, including creating a
Definitionsobject, defining the code location in a Python module, configuring the code location in Dagster, and managing dependencies.
By implementing code locations in your Dagster projects, you can create a more robust, scalable, and manageable data orchestration system. Whether you are working in a large organization with multiple teams or managing data pipelines for various clients, code locations provide the flexibility and isolation needed to ensure smooth and efficient workflows.
Next steps
We encourage you to explore and implement code locations in your Dagster projects. Start by defining your Definitions objects and configuring your code locations to see the benefits firsthand. For more detailed information and guidance, refer to the Dagster documentation, which provides comprehensive resources on code locations and other features.
If you have any questions or need further assistance, feel free to join the Dagster community forums and discussion boards. Our community is always ready to help and share insights on best practices and advanced use cases.
Happy orchestrating with Dagster!





.jpg)
.png)



.png)

