

.jpeg)


Get the tale of the tape between the two orchestration giants and see why Dagster stands tall as the superior choice.
When it comes to data orchestration there are two names that are almost always in the conversation: Apache Airflow and Dagster.
We often get asked why data engineering teams should choose Dagster over Airflow. It boils down to a few key differences:
- Asset orientation: Dagster focuses on data assets (software defined assets) not just tasks, giving you better visibility into data lineage and dependencies.
- Principled architecture: Designed from the ground up for modern data workflows, Dagster has better local development, testing and debugging.
- Full data engineering lifecycle management: Dagster supports the entire data lifecycle from development to production with built in support for CI/CD.
In this post we’ll go over how Dagster handles Airflow’s limitations and why it’s the better choice for data teams looking for more efficient data orchestration.
We’ll also cover how to adopt Dagster when you have a heavyweight Airflow installation that isn’t going anywhere anytime soon.
The Birth of Apache Airflow
Apache Airflow was one of the first data orchestration tools, a Python-based orchestrator with a web interface. It was born in 2014 from the need for an efficient, programmable and user-friendly way to schedule and execute complex data tasks, Airflow solved the problems of that time by providing a way to manage and schedule tasks.
Airflow is a big step forward from the old manual and error-prone ways of managing data pipelines. Its Python based design makes it accessible to a wide range of users, as Python was and is still a popular language in data science and engineering.
Airflow is still popular today because of its mature ecosystem and wide adoption.
Apache Airflow Pros and Cons
Airflow’s initial design changed data task management, but it was designed in a different era of data engineering— one where the full data lifecycle wasn’t as complex as it is today.
Airflow works well within its scope, which is:
- Managing and executing task based workflows
- Connecting to various data sources and services through its plugins and integrations
- Simple pipelines without complex data dependencies or asset management
But Airflow falls short in many areas needed for efficient data operations today:
Local Development and Testing
Local development and testing helps find and fix issues early in the development process. Airflow’s architecture makes this harder because tasks are often tightly coupled to the production environment, so it’s hard to replicate the exact conditions locally. On top of that, Airflow’s dependency management can cause conflicts and make local setup harder. So issues are sometimes not found until staging or production environments. By then fixes are usually more expensive and time consuming.
Debugging
Debugging is a big part of data engineering to make sure transformations work as expected and issues are found and fixed quickly. But Airflow’s workflow debugging is hard because of its task focused approach. Logs are unstructured and scattered across different tasks, so it’s hard to find the root cause of an issue. The UI doesn’t give a complete view of the data flow either, so debugging is tedious and delays error identification and resolution, meaning longer downtimes.
Data Lineage and Asset Management
Understanding data lineage and dependencies helps you manage complex data flows and see the impact of your changes. Airflow’s focus on the execution of tasks rather than the data assets those tasks produce means less visibility in this area, so it’s hard to track data lineage and understand dependencies between different data assets. Lack of visibility means low data quality and consistency and potential data integrity issues.
Scalability and Isolation
Scalability is important because it lets your environment handle increased loads as it grows. Isolation prevents tasks from interfering with each other. Airflow’s monolithic architecture can cause scalability issues because all tasks share the same environment, which can cause performance bottlenecks. An error in one task can affect others. In large environments, this can mean performance degradation, increased risk of failures, and harder-to-isolate tasks to prevent interference.
Containerization
Containerization provides portability, efficiency and consistency across environments. Airflow was not designed with containerization in mind. While it’s possible to run Airflow in containers, it’s a lot of work and custom configurations. Lack of native support for containerized environments means users miss out on the benefits of portability and consistency. This makes it harder to have a consistent development and deployment environment, so potential discrepancies between different stages of the data pipeline.
CI/CD
Continuous Integration and Continuous Deployment (CI/CD) practices enable more efficient and reliable software development through automated testing and deployment. Airflow’s architecture is not designed for these practices. Automated testing and deployment is harder to implement in Airflow because tasks are tightly coupled to the environment they run in. So creating isolated, repeatable test environments is hard. This slows down the development cycle and increases the risk of introducing bugs into production, making it harder to maintain high quality software.
Airflow has let data engineers get stuff done – but often with a lot of pain. As data environments get more complex and continue evolving, its limitations become more apparent. Teams are finding themselves with late-stage error detection in production, outdated data, inflexible environments and dependency management that slow down development.
Closing the Gap
Unfortunately, these aren’t issues that can be fixed with a few new features. Airflow’s architecture, abstractions and assumptions are just not suited for data orchestration and the modern data stack.
We need to move towards more advanced tools that not only fix these issues but have stronger foundations than Airflow for data orchestration.
To close these gaps, organizations need an orchestration solution that goes beyond task execution, managing and optimizing data assets – tables, files and machine learning models – across the entire lifecycle. It also needs to integrate seamlessly with modern development practices, from local testing to production deployments, all backed by cloud-native capabilities.
This is part of the reality that Dagster offers: agile and transparent operations while controlling and shipping data fast and efficiently.
Enter Dagster
Dagster is a new paradigm in data orchestration– taking a radically different approach to data orchestration than other tools. Dagster was designed for the evolving needs of data engineers. Unlike its predecessors, Dagster was built from the ground up with data assets and the full development lifecycle in mind, for a more complete and integrated approach to data pipelines.
Dagster's asset-oriented nature allows it to easily answer questions such as: - Is this asset up-to-date?- What do I need to run to refresh this asset? - When will this asset be updated next?- What code and data were used to generate this asset?- After pushing a change, what assets need to be updated?
With this approach, we give data teams a more straightforward experience, so they can define, test and run their pipelines locally with ease. We also focus on developer productivity with rich, structured logging and a web based interface to give visibility and control over data pipelines.
Data engineers love Dagster’s approach and feature set. It’s the preferred choice for data teams looking to get more productive and manage their data pipelines better.
Dagster vs. Airflow
Dagster easily addresses the areas where Airflow falls short. Here’s how:
Local Development and Testing
Dagster is built with local development and testing in mind. For example, you can run your entire pipeline locally with the dagster dev command. This command starts a local Dagster instance where you can define, test and run your workflows without any external dependencies. This local development environment speeds up iteration and helps catch errors early, so development is faster, more efficient and less error prone.
Debugging
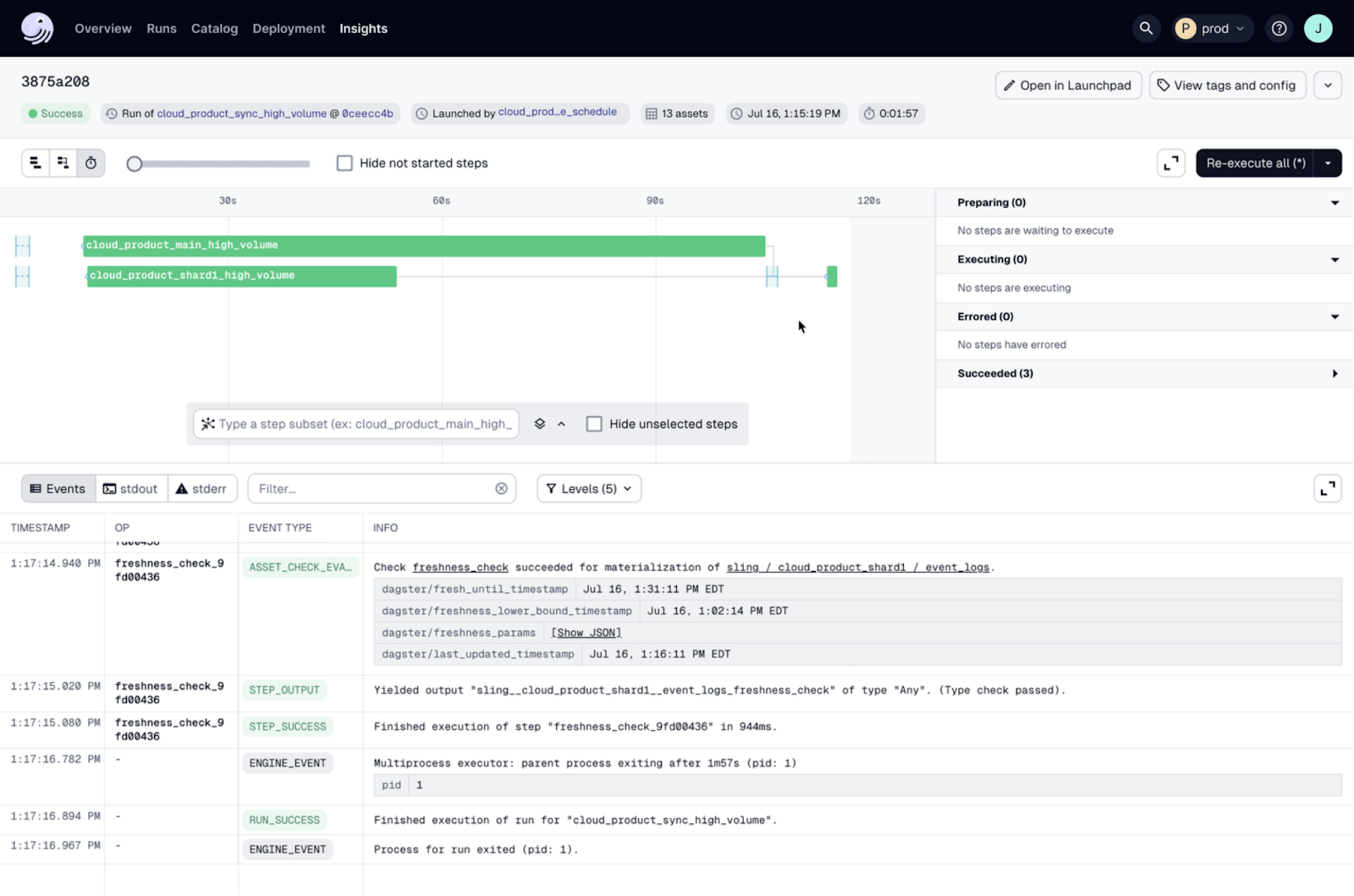
Dagster gives you rich, structured logs and a local development environment to debug pipelines through its UI. If a pipeline fails you can navigate through the logs with Dagster’s UI to find the exact step and error. The structured logs include metadata so you can understand the context of each log entry.
Data Lineage and Asset Management
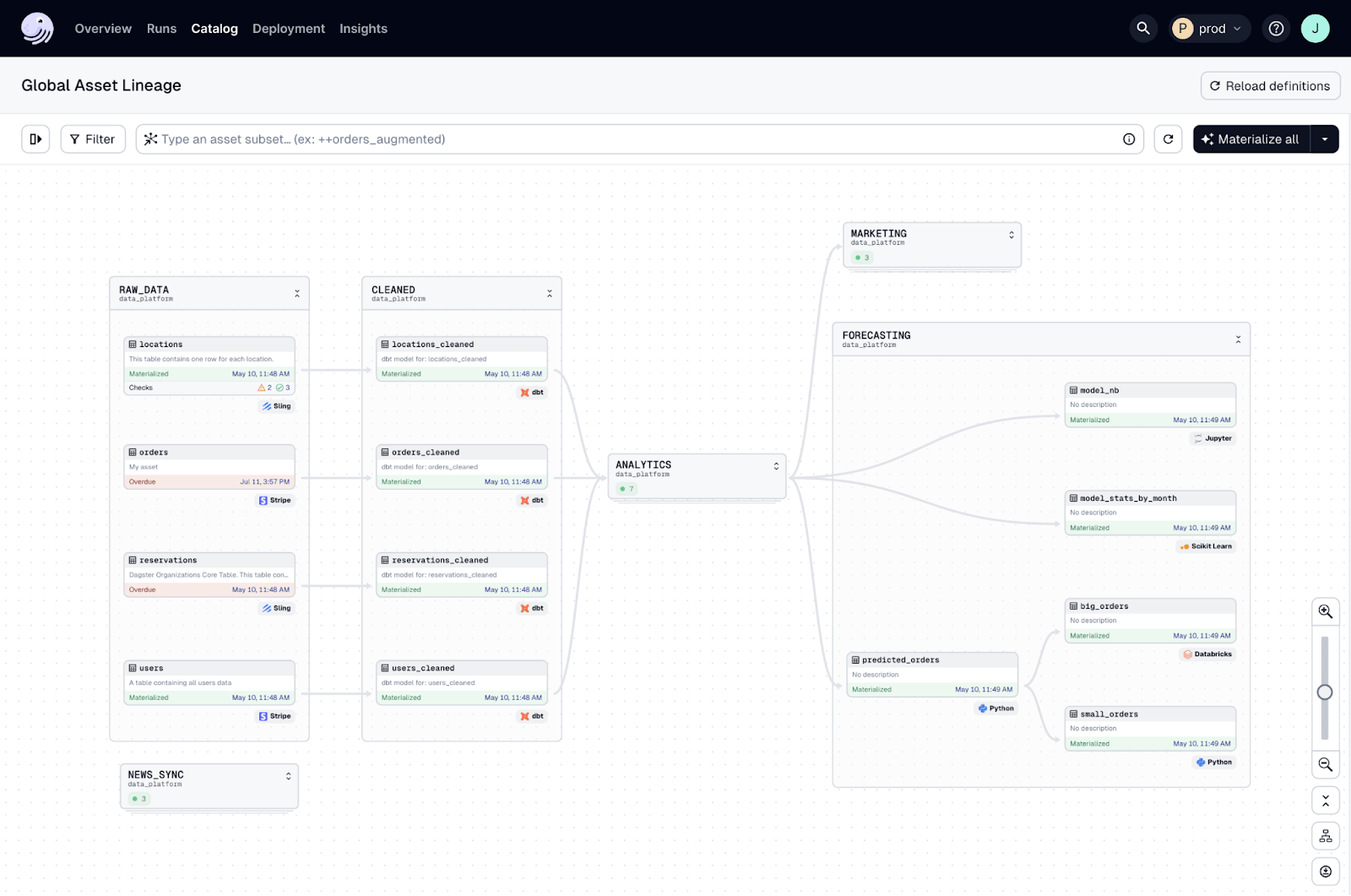
Dagster takes a data first approach to workflows, giving you full visibility into data lineage and dependencies. This asset based approach lets you define data assets and their dependencies explicitly. For example if you have a data pipeline that processes raw data into cleaned data and then into a report, Dagster can show you the entire lineage from raw data to the report. This visibility helps you manage complex data flows and understand the impact of changes.
Scalability and Isolation
Dagster is designed to be highly scalable and handle large and complex data workflows. Additionally Dagster’s architecture supports scalable execution environments like Kubernetes. You can define resource requirements for each job or step so tasks run in isolated environments.
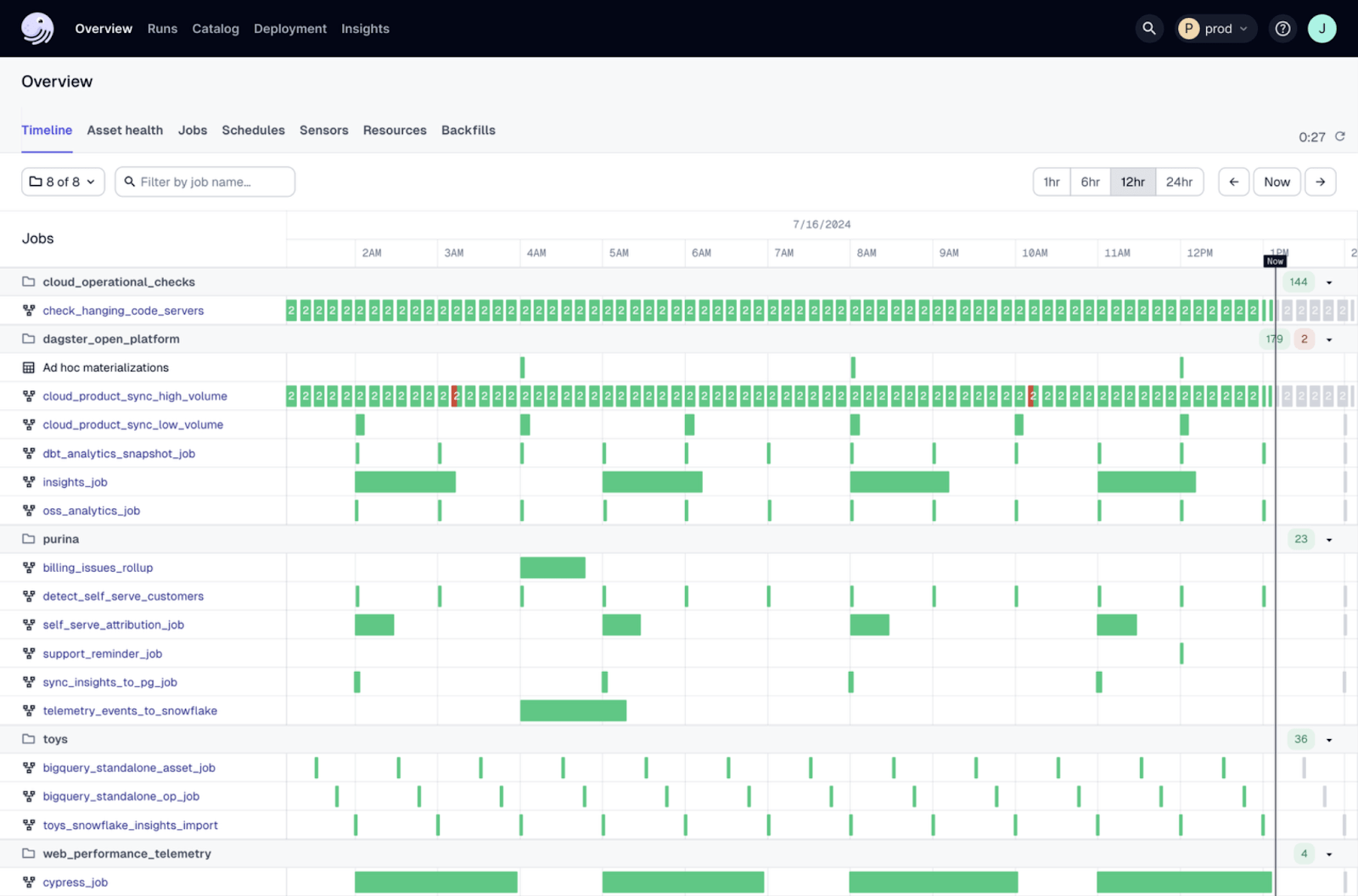
For example a CPU bound task can be scheduled on a node with high CPU availability and an I/O bound task can be scheduled on a node optimized for I/O.
Containerization
Dagster is designed for modern cloud and container environments. For example Dagster integrates with container orchestration platforms like Kubernetes. You can define your pipelines to run in Docker containers so your pipelines are consistent across environments. For example, you can develop and test your pipeline in a local Docker container and then deploy the same container to a production Kubernetes cluster.
CI/CD
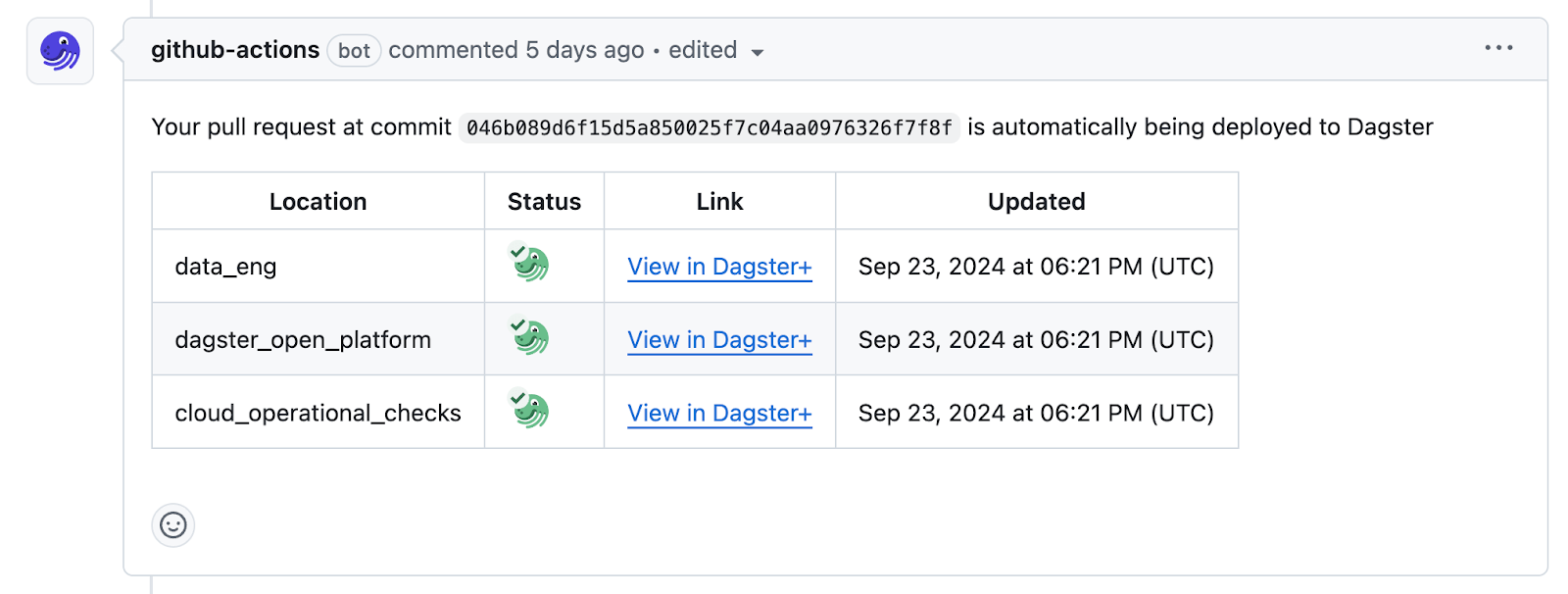
Dagster has built in CI/CD so you can implement these best practices and automate testing and deployment. For example Dagster+ has built in GitHub Actions to automate packaging and deployment of your code. You can set up a CI/CD pipeline that runs tests on your Dagster pipelines every time you push to your GitHub repository. So your code is always tested and deployed consistently.
Dagster+
In addition to Dagster’s core features Dagster+ adds a lot to Dagster to compete with the best in DataOps. It builds on top of Dagster’s foundation and adds more features for enterprise scale data operations:
Data Asset Management
Dagster+ has a built in data catalog that captures and curates metadata for your data assets. This catalog gives you a real time, actionable view of your data ecosystem, showing column-level lineage, usage stats and operational history. This makes it easier to discover and understand data assets.
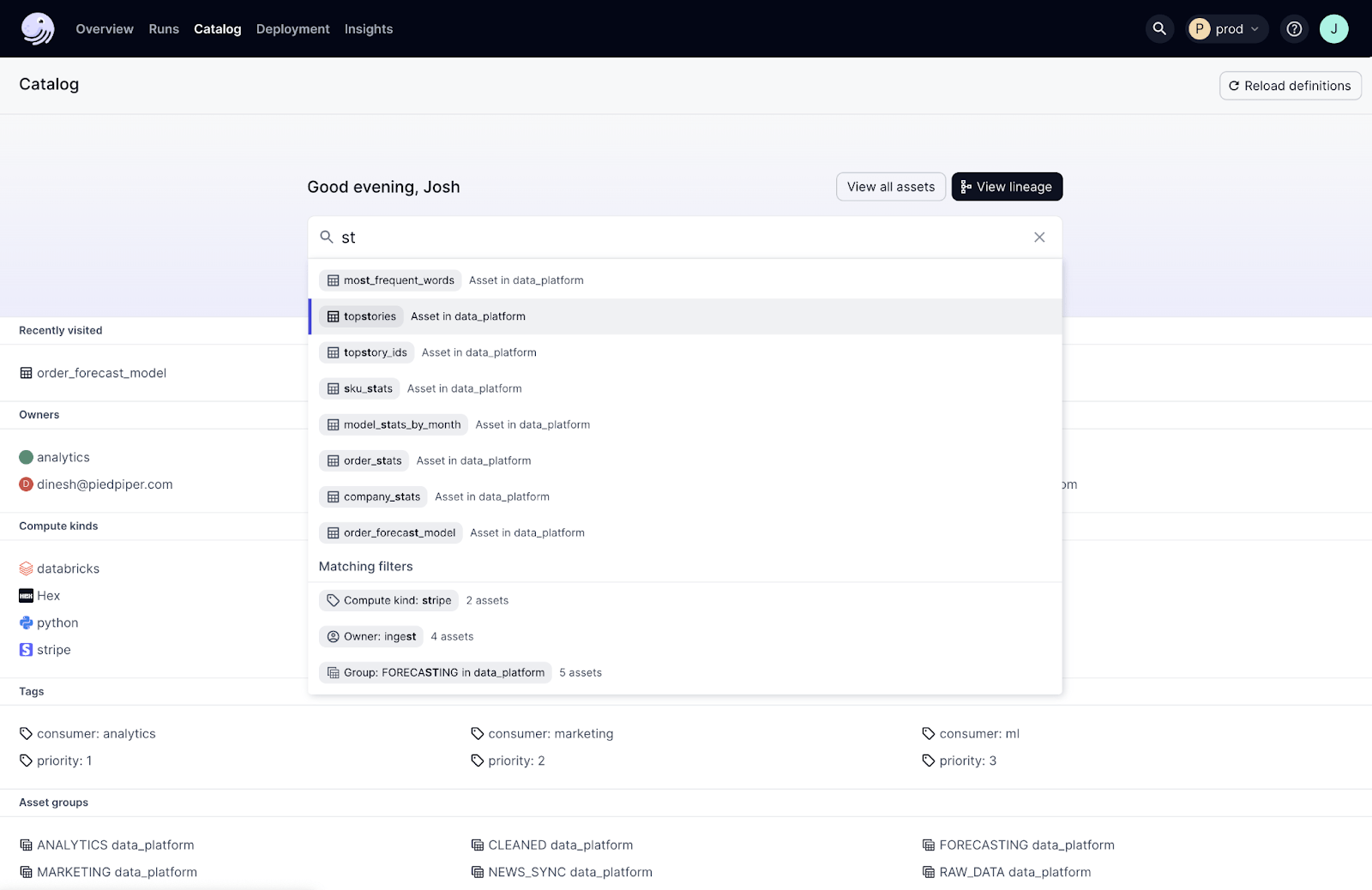
Operational Workflows
Dagster+ has advanced operational workflows that streamline the entire data orchestration lifecycle. These workflows introduce automated data quality checks, alerting and incident management. For example, if a data quality check fails, Dagster+ can automatically send an alert and create an incident ticket so you can get attention to issues immediately.
Security and Compliance
Data governance and compliance is vital in Dagster+. Features like role based access control (RBAC), audit logs and data encryption ensure data protection and compliance. You can also define fine-grained access controls to limit who can view or modify specific data assets.
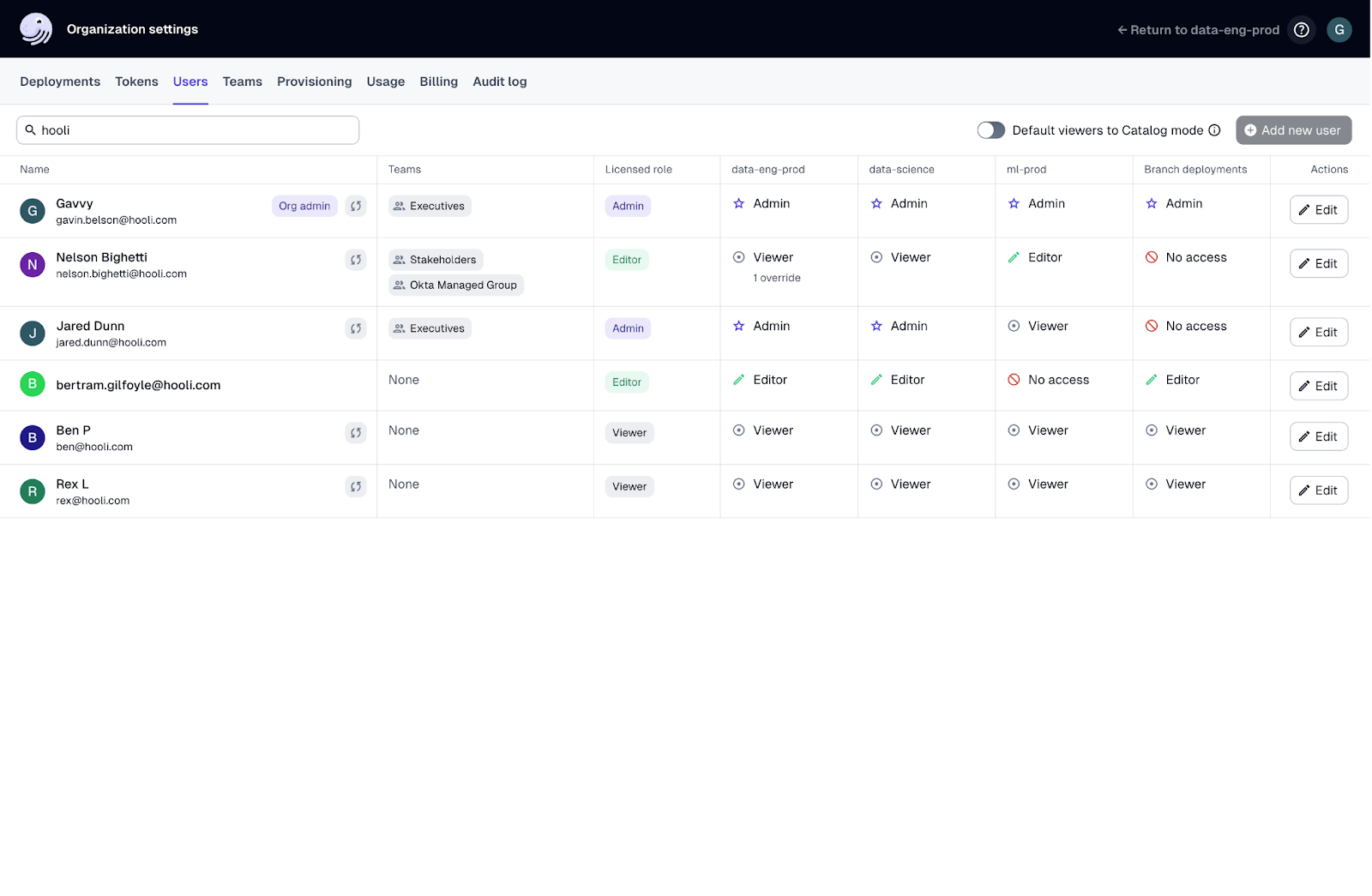
Priority Support
Dagster+ subscribers get priority support so issues get resolved quickly and data pipelines run smoothly. For example, if you have a critical issue in production you can reach out to the Dagster support team and get expedited help.
Context Rich View of Assets
Dagster+ gives you a full context rich view of data assets, including metadata about asset generation, usage, dependencies and status changes. You can see the full history of an asset, including last updated, who updated it, and any changes to the schema.
Platform Integration with External Assets
Dagster+ extends its cataloging to external assets so all your key assets and metadata are in one place. For example if you have data assets managed by external systems like Snowflake or BigQuery, Dagster+ can integrate with those systems to give you a unified view of all your data assets.
Searchability and Discoverability
Dagster+ makes data assets more searchable and discoverable so teams can find what they need. This improves data operations and your overall data management strategy.
Use Dagster for Better Data Operations
With these features, Dagster takes the baton from Airflow and easily runs ahead.
Some of Dagster’s biggest users are organizations that also have large Airflow installations. You might have a large Airflow installation in your organization that’s not going away anytime soon.
That being said, it doesn’t mean you can’t use Dagster. In some cases Dagster and Airflow sit side by side, independently of each other.
Check out our migration guide to get started with Dagster from Airflow.
Using Airflow with Dagster
You might have a large Airflow installation in your organization that’s not going away anytime soon.
In some cases, Dagster and Airflow sit side by side and independently of each other. Instead of going through a lengthy migration process, you can get day one value with Airlift.
Final Thoughts
Apache Airflow is used to build and run data pipelines but wasn’t designed with a holistic view of what it takes to do so. Dagster was designed to help data teams build and run data pipelines: to develop data assets and keep them up to date. The impact on development velocity and production reliability is huge.
Most Dagster users were Airflow users and nearly every Dagster user was an Airflow user at the time they chose Dagster.
So give it a try. We'd love for you to join them.





.jpg)
.png)



.png)

