



smava achieved zero downtime and automated the generation of over 1,000 dbt models by migrating to Dagster's, eliminating maintenance overhead and reducing developer onboarding from weeks to 15 minutes.
KEY RESULTS:
- Zero downtime achievement unlocked: Zero downtime in July 2025 and since then
- Eliminated failure alerts: "Almost down to zero" maintenance overhead
- 1000+ models: Automated generation of 1000+ DBT models
- Team satisfaction: Improved developer experience, reduced alert fatigue, boosted the productivity
- Scalability confidence: Assurance on providing required scalability for the growth targets
smava is a Berlin-based fintech pioneer (founded in 2007) that has built one of Germany’s leading online credit-comparison and brokerage platforms.
The company enables consumers to compare personal-loan offers from more than 20 banking and credit-partner institutions through a single, streamlined digital interface.
Especially by leveraging digitized workflows,tailored loan recommendations, and a broad marketplace of lenders, smava empowers borrowers to secure significantly better and fairer loan terms, making loans transparent, fair, and affordable.
In short, smava is helping to digitize and disrupt Germany’s traditionally paper-heavy and bank-centric credit market by offering transparency, choice, and speed in personal-loan origination.
.png)
Alex Naumov is Principal Data Architect at smava, where he leads the Data Engineering & Architecture function and manages data and analytics engineers. He is driven by a great passion for data and transforming organizations to become data-driven and the best in what they do. Fascinated by coding/computers since his early teens, Alex has spent around 16 years in the data domain, first as a consultant, mostly having the role of data or solution Architect, for ten years, and since 2019 based in Berlin with smava. His experience spans 8 countries, 10+ sectors and roughly 30 projects/customers, and a wide variety of technologies.
The challenge
As smava’s data ecosystem evolved alongside rapid business growth, its original data infrastructure began reaching the limits of scalability and maintainability. The system relied on a combination of legacy tools, including a custom Java application for Data Vault code generation and orchestration paired with a low-code ETL platform, that had served the company well in earlier stages. However, as data volumes and complexity increased, this setup made it difficult to maintain transparency, consistency, and agility.
Key pain points included limited version control, limited CI/CD workflows, and limited visibility into operational issues, all of which slowed down development and troubleshooting. When failures occurred, the team had little autonomy in resolving them quickly due to dependency on external vendor support.
Over time, the maintenance load began to outweigh innovation. The data team faced an ever-growing queue of alerts and manual interventions, while the broader organization’s data demands continued to rise in line with smava’s growth targets and business requirements.
To continue supporting smava’s mission of making loans transparent, fair, and affordable, the company set out to modernize its data platform further. It sought a scalable orchestration solution that could enhance reliability, introduce professional development workflows, and allow engineers to focus on building value instead of firefighting.
The solution
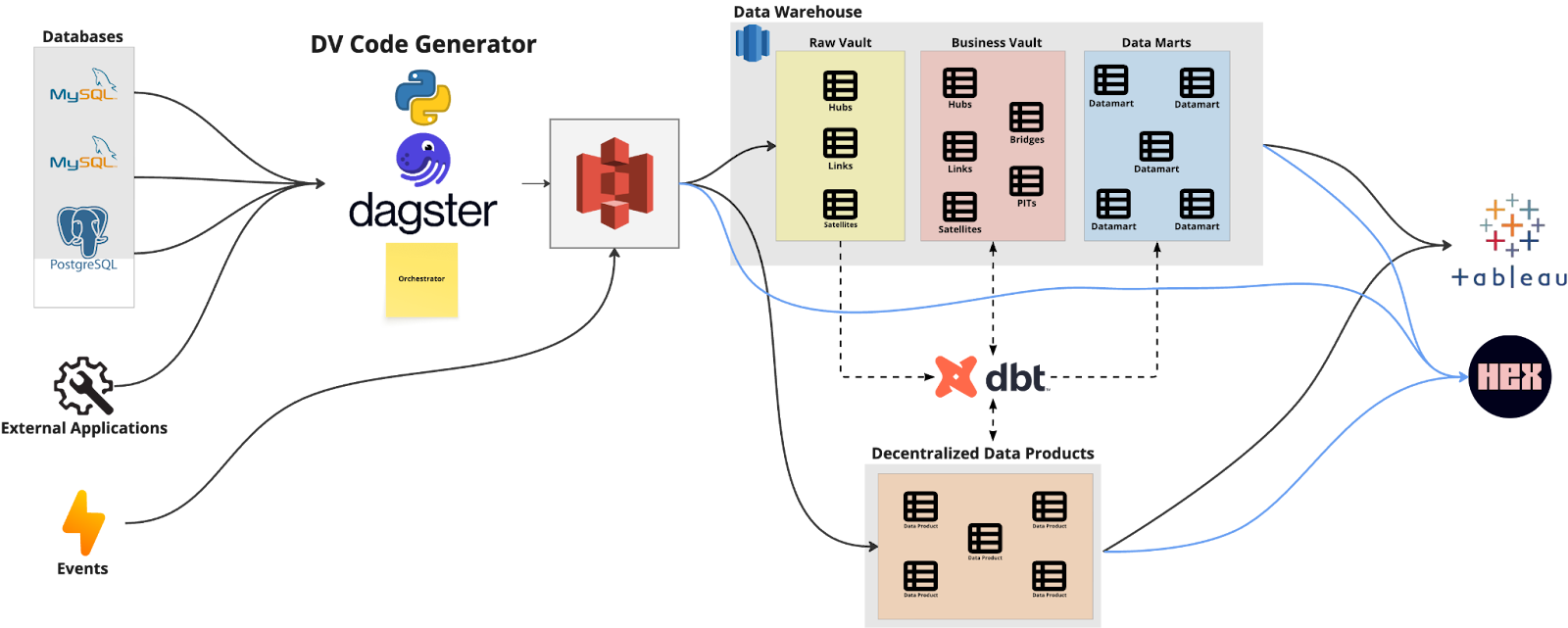
The team faced a practical challenge: they needed to replace their aging Java-based code generator, and wanted to modernize the platform further while keeping the benefits of automated Data Vault code generation. Initially, they looked at Airflow, but during their research, Alex discovered Dagster and reached out for a POC. The results were immediately compelling. "The mindset shift, organizing work around actual data assets rather than tasks, was definitely like a game changer for us," Alex explains. Dagster’s asset-centric architecture and superior CI/CD capabilities addressed smava’s data development challenges that, he says, “would have been quite a big pain with Airflow."
The implementation strategy was pragmatic and phased. smava started by migrating their legacy workloads to Dagster to establish a stable foundation, then built their crown jewel: a custom dbt code generator that creates Data Vault models from simple YAML configurations. This system generates over 1,000 dbt models automatically, eliminating manual coding while maintaining enterprise-grade quality checks and tests. The result is generated code that integrates seamlessly with Dagster's asset catalog, providing full lineage visibility and orchestration capabilities.
Example YAML Configuration for data exports:
1source_sysytem: some_system
2source_type: mysql
3import_asset: source_table
4description: source table import from database
5schema: source_db
6table_name: source_table
7export_format: csv
8export_chunk_size: 10000
9columns:
10 - expression: source_table.record_id
11 alias: record_id
12 type: int
13 - expression: related_table.reference_id
14 alias: reference_id
15 type: int
16 - expression: source_table.status
17 alias: status
18 type: varchar(255)
19 - expression: source_table.category
20 alias: category
21 type: varchar(255)
22 - expression: source_table.created_at
23 alias: created_at
24 type: timestamp
25 - expression: source_table.updated_at
26 alias: updated_at
27 type: timestamp
28incremental_columns:
29 - source_table.updated_at
30query_overrides: >
31 select $columns
32 from schema_name.table_name as source_table
33 left join schema_name.related_table as related_table
34 on source_table.reference_key = related_table.id
35
Example YAML Configuration for DV objects:
1hub_name: some_hub
2description: Some hub
3staging_materialization: view # optional
4incremental_strategy: append # optional
5merge_update_columns: "[list of columns]" # optional
6merge_exclude_columns: "[list of columns]" # optional
7enforce_contracts: true
8tests_filter: some filter # optional
9business_key_definitions:
10 - bk_id: bk1
11 order: 1
12 columns:
13 - column_name: hub_1_bk_col_1
14 column_type: int
15 - column_name: hub_1_bk_col_2
16 column_type: int
17 imports:
18 - import_name: import_1
19 source_system: source_system_1
20 columns:
21 - expression: hub_1_bk_col_1_expr
22 - expression: hub_1_bk_col_2_expr
23 - import_name: another_import
24 source_system: some_source_system
25 columns:
26 - expression: expr_1
27 - expression: expr_2
28 - bk_id: bk2
29 order: 2
30 columns:
31 - column_name: hub_1_bk_col_3
32 column_type: varchar(50)
33 imports:
34 - import_name: import_name
35 source_system: some_source_system
36 columns:
37 - expression: some_expression
38Today, smava’s technical architecture runs on AWS Fargate with a hybrid setup connecting multiple source systems, with different technologies, through Dagster and Python. The platform integrates dbt Cloud and dbt Core, with all generated models and their intensive contracts imported as Dagster asset checks. It combines the speed and reliability of automated code generation with the observability, CI/CD workflows, version control, and collaborative development practices that now enable smava’s data team to focus on building value, accelerating innovation, and scaling confidently alongside the business.
The results
Rebuilding around Dagster’s data-centric orchestration fundamentally changed how smava's data team works. Most striking was the complete elimination of the alert fatigue that had been crushing team morale: with Dagster’s real-time visibility into pipeline health, Alex says, "Alerts directly went to zero.” In fact, he notes, the platform achieved zero downtime in July 2025 — a stark contrast to their previous frequent outages.
The developer experience improvements were equally transformative. New team members can now get up and running in just 15 minutes with proper local development environments, compared to the several days of training required for their previous tools. "You just spend maybe 15 minutes to set up your Dagster, your other dependencies and plugins, to VS Code, and now they're actually liking it," Alex explains.
Professional development practices like CI/CD, pull requests, code reviews, and branch deployments became standard, replacing the black-box debugging of their legacy systems. The end-to-end lineage and column-level lineage capabilities have proven essential for their Data Vault architecture, allowing analysts, analytics engineers, data scientists, etc. to trace data origins and transformations across multiple layers. The unified data catalog provides read-only access to stakeholders who can now see "what's happening, what's running, what's failed" without requiring technical expertise.
In addition to operational improvements, the platform reduced infrastructure overhead by consolidating legacy instances and ECS clusters. Alex highlights an even greater benefit: eliminating manual maintenance tasks saved significant “invisible costs,” freeing the team to focus on delivering business value. Most importantly, smava can now confidently assure executives that their infrastructure can scale with growth targets, providing a stable foundation to support continued innovation.
Looking ahead
The success of the data platform team with Dagster has attracted attention across smava, highlighting the potential to extend its use to other teams. We are exploring how we can benefit from Dagster further for groups such as the data science team, as well as teams with existing Airflow implementations. Alex notes, “We are aware that Dagster is actually a perfect fit for machine learning workflows too,” and this awareness is guiding how the team evaluates opportunities to expand Dagster’s use across other complex data pipelines.
smava is now ready to scale in every sense of the word. Their automated code generation system can easily accommodate new data sources and evolving business requirements without manual coding effort, while Dagster’s asset-centric approach provides the flexibility to adapt their Data Vault architecture as needs grow. With zero maintenance overhead and executive confidence in the platform’s scalability, Alex says they now have a system that can confidently handle “x%, y%, whatever growth we are talking about, we are ready.”
Key takeaways
Zero downtime achievement smava went from frequent system outages to zero downtime in July 2025 and since then, demonstrating how modern data orchestration can deliver enterprise-grade reliability in regulated financial services.
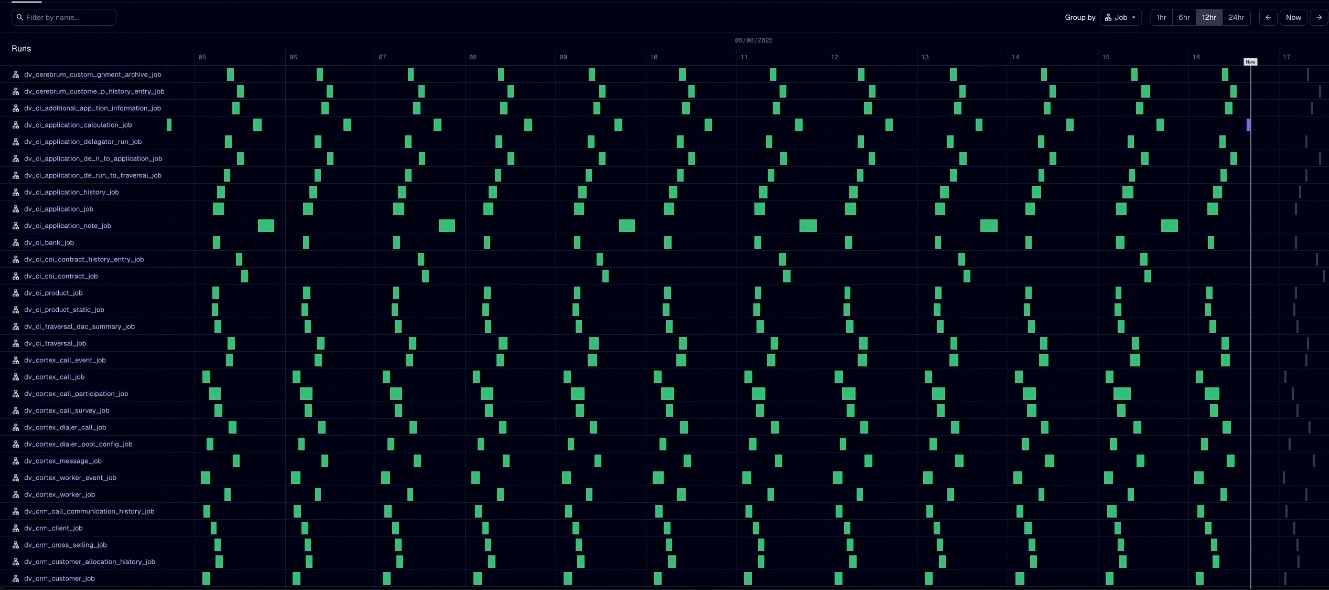
Maintenance overhead elimination The team reduced maintenance work to "almost zero" by eliminating daily alert fatigue and reactive firefighting, freeing engineers to focus on strategic data initiatives instead of operational fixes.
Massive Scale Through Automation Their YAML-driven code generation system now produces over 1,000 dbt models automatically, ensuring enterprise-grade data quality without manual coding, model automation at a sophistication level that would be difficult to achieve manually.
15-minute developer onboarding New team members can set up complete local development environments in just 15 minutes, compared to weeks of training with legacy tools, dramatically boosting productivity and knowledge transfer.
Executive confidence achieved The platform transformation allowed Alex and his team to confidently assure smava’s C-level leaders that their data infrastructure can support ambitious growth targets, turning data capabilities from a potential constraint into a strategic advantage for the business.





.jpg)
.png)



.png)

