




Software-Defined Assets are a new abstraction that allows data teams to focus on the end products, not just the individual tasks, in their data pipeline.
Why data needs declarative design
Software engineering has grown increasingly declarative. Front-end development has shifted from imperative libraries like jQuery to frameworks like React, allowing developers to describe what UI they want rather than how to render it. Similarly, DevOps has moved from shell scripts to Infrastructure as Code tools like Terraform and Pulumi, enabling teams to declare infrastructure states without detailing each provisioning step.
Declarative approaches are attractive because they simplify building and maintaining systems. Rather than defining how work is done, you describe the desired end state, and the framework handles execution.

While declarative methods are common in software engineering, data workflows often remain stubbornly imperative. This is partly because many data stacks are cobbled together from disparate scripts and cron jobs. Figuring out which process updates a particular database table or ML model can feel like a heroic act. And even after you find the relevant code, changes feel risky with uncertain externalities lurking in every refactor.
As data platforms scale, the need for a declarative approach grows more urgent. You can’t afford to treat data work as isolated jobs anymore; you need a higher-level abstraction. In DevOps, we manage infrastructure via resource definitions. In data, we should do the same and manage the assets (database tables, ML models, dashboards) as persistent objects that capture and encode some slice of the world. Assets may serve multiple teams and use cases, but they remain the fundamental units of a data platform.
From pipelines to assets
Declarative data engineering begins with defining assets in code, describing not just what the asset is but also how it’s generated and where it fits within the platform.
Each asset definition in Dagster includes:
- An asset key, serving as a global identifier
- An op, the function that produces the asset
- A set of upstream asset keys, defining dependencies
Combining these elements creates a powerful model for building data applications. By tracking dependencies alongside each node, Dagster can automatically infer the asset graph, eliminating the need to manually define explicit DAGs that often become outdated or misaligned with actual dependencies. This approach makes it much easier to scale a data platform, especially as even modest organizations can have hundreds or thousands of assets.
Below is a simple asset definition using Dagster’s Python API. It defines an asset called “logins”, which is derived from an upstream asset called “website_events”.
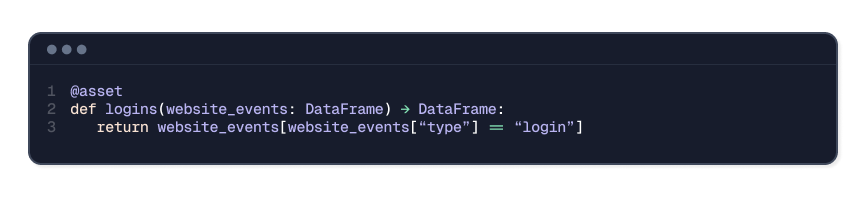
The asset key is `logins`, derived from the name of the decorated function. The function itself is the “op” and used to compute the asset. The upstream asset, `website_events`, is inferred from the function’s argument.
The `logins` asset is defined as a pure function. While Dagster supports defining assets in pure Python, assets can represent many other entities. For example, a dbt model can be represented as an asset, and Dagster can load entire dbt projects to generate individual assets for each model. The same applies to tables in a Postgres database managed by Fivetran or dashboards in Looker. Any object can be represented as an asset.
Beyond operational definitions, software-defined assets are also a natural hub for metadata. Below is an example of an asset definition with additional metadata.
@dg.asset(
metadata={
"owner": "sandy@elementl.com",
"domain": "core-site",
"priority": 3
},
partitions_def=DailyPartitionsDefinition(start_date="2020-10-05"),
kinds={"pandas"},
)
def logins(website_events: DataFrame, users: DataFrame) -> LoginsSchema:
"""
The logins table contains an entry for each login to the site.
“””Understanding the asset graph
A collection of software-defined assets forms an asset graph, which is essential for understanding and working with data. For developers, the asset graph provides a holistic view of the data platform and a clear way to navigate dependencies across processes and systems. For consumers, it reveals the status of the assets they rely on.
Taking this approach to the data platform means no single team is burdened with maintaining a monolithic DAG to capture all dependencies. Instead, each team owns a subset of the overall asset graph, managing only the assets relevant to their domain.
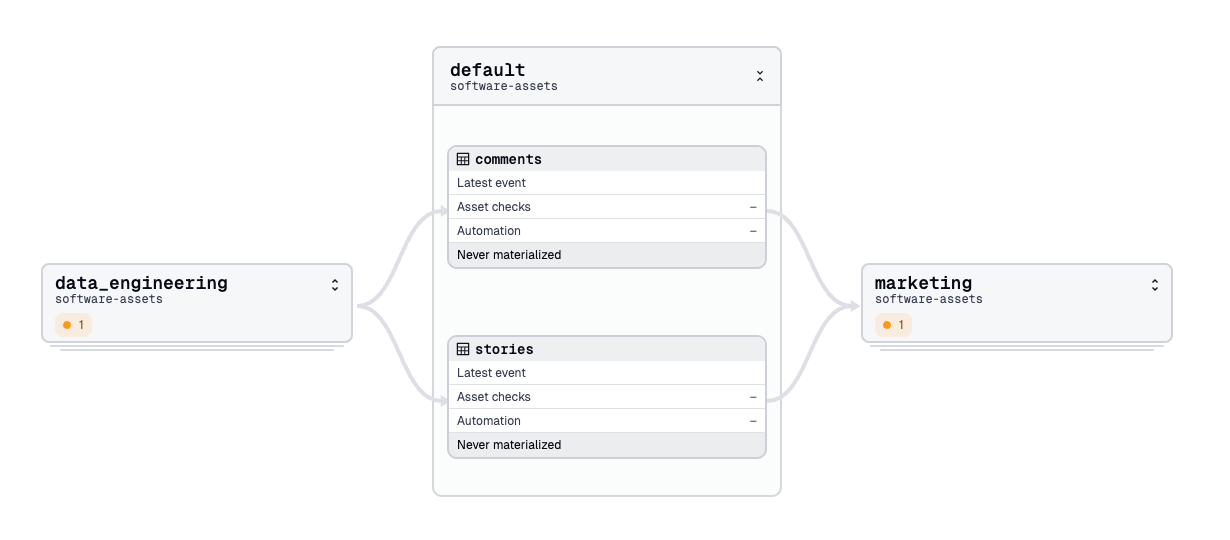
This approach allows teams or individual users to build on existing assets and take dependencies without duplicating work. It also eliminates the need to understand the internals of upstream assets, letting teams focus on the interfaces between them. By defining asset lineage declaratively, much of the chaos typically found in data platforms is naturally brought under control.
Orchestrating change in assets
Keeping assets in sync and up to date is typically the job of an orchestrator. Since orchestrators are the source of truth for scheduling, dependencies, and triggering computations, they hold the key to critical questions:
- Is this asset up to date?
- What do I need to run to refresh this asset?
- When will this asset be updated again?
- What code generated this asset?
These are the questions that matter when maintaining a data platform. Unfortunately, traditional orchestrators are poorly equipped to answer them because most operate at the task level, not the asset level. As a result, they provide insight into pipeline status but not the state of the underlying assets we actually care about.

An orchestrator that centers on assets reduces the friction of translating between pipelines and the data products that matter. This approach makes it much easier to identify where errors occur and understand what might be impacted.
Reconciling assets
Asset-based orchestration isn’t just about making it easier to translate between assets and computation, it also enables a more principled approach to managing change through reconciliation. Like other declarative systems, reconciliation focuses on the difference between how things are and how they should be. The orchestrator is responsible for identifying these discrepancies and materializing assets as needed.
Compared to simple schedule-based materialization, this approach is far more efficient. Instead of reprocessing data shared across multiple workflows, only the assets required to reach the desired state are recomputed.
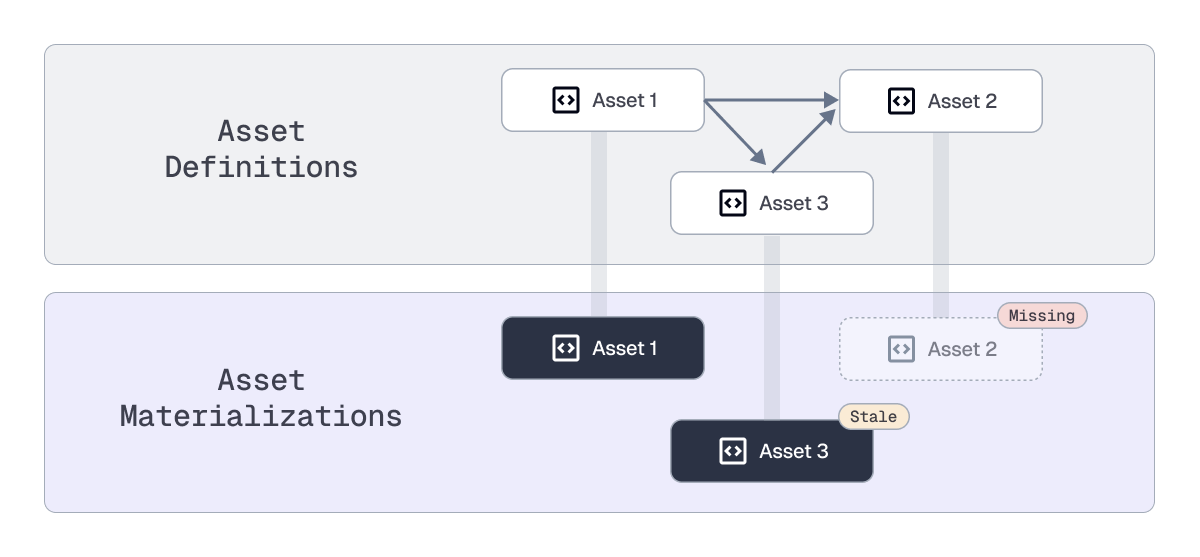
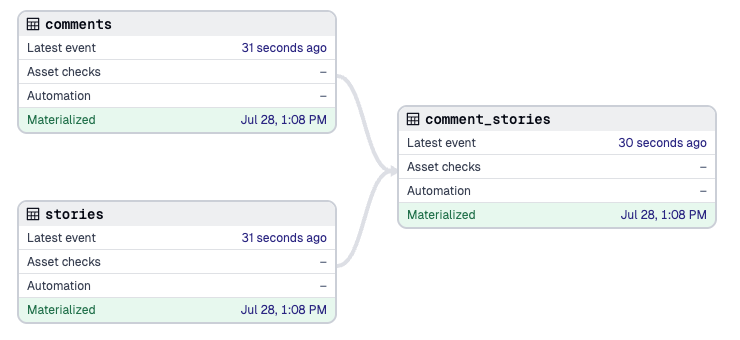
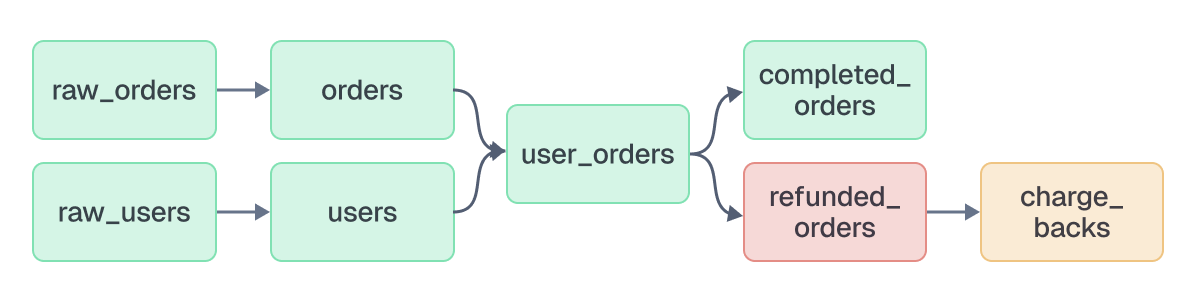
The most basic form of reconciliation occurs when a software-defined asset has no existing materialization. For example, here’s an asset graph that includes an unmaterialized asset, `comment_stories`.

Materializing `comment_stories` resolves this discrepancy.
Another discrepancy is when the contents of an asset do not reflect the assets it depends on. By default, assets with upstream dependencies should be based on the most recent contents of those upstream assets. If the most recent materialization of the asset occurs earlier than the most recent materialization of its upstream assets, it is likely stale and will indicate which of its dependencies are unsynced.

Approaching orchestration in this declarative way prevents many of the pain points associated with traditional orchestrators. Instead of needing to specify schedules at specific intervals or coordinating competing triggers, multiple users and teams can take dependencies on the same asset with the awkwardness of waster computation and poor observability.
Software-defined assets and the Modern Data Stack
The Modern Data Stack refers to a collection of tools and practices that have significantly simplified common data workflows. For example:
- Instead of writing custom tasks to chain SQL statements, dbt models directly express business logic within the database.
- Instead of coding pipelines to replicate tables into your data warehouse, tools like Fivetran or dlt handle that out of the box.
These tools have been a massive quality-of-life improvement for data practitioners but notable gaps remain. Many of these tools operate in isolation, with no effective way to unify them. Without a shared orchestration layer, teams are forced into brittle, error-prone workflows like manually coordinating schedules across disparate systems.
Another gap is in supporting Python and non-SQL workflows, which are often unique to each organization. Integrating tools like Pandas or PySpark into these pipelines adds complexity that the Modern Data Stack doesn’t easily address.
An asset-based orchestrator fills these gaps by combining polyglot compute with a declarative, asset-centric approach. Dagster makes Python a first-class citizen in the Modern Data Stack and enables asset graphs that span multiple systems and frameworks.
To make this even easier, Dagster supports Components. Components act as an abstraction layer over software-defined assets, allowing you to scaffold common integrations.
type: dagster_dbt.DbtProjectComponent
attributes:
project: '{{ project_root }}/dbt'This uses the `DbtProjectComponent` to read the dbt project located in the root of our Dagster project and generate all of the necessary assets.
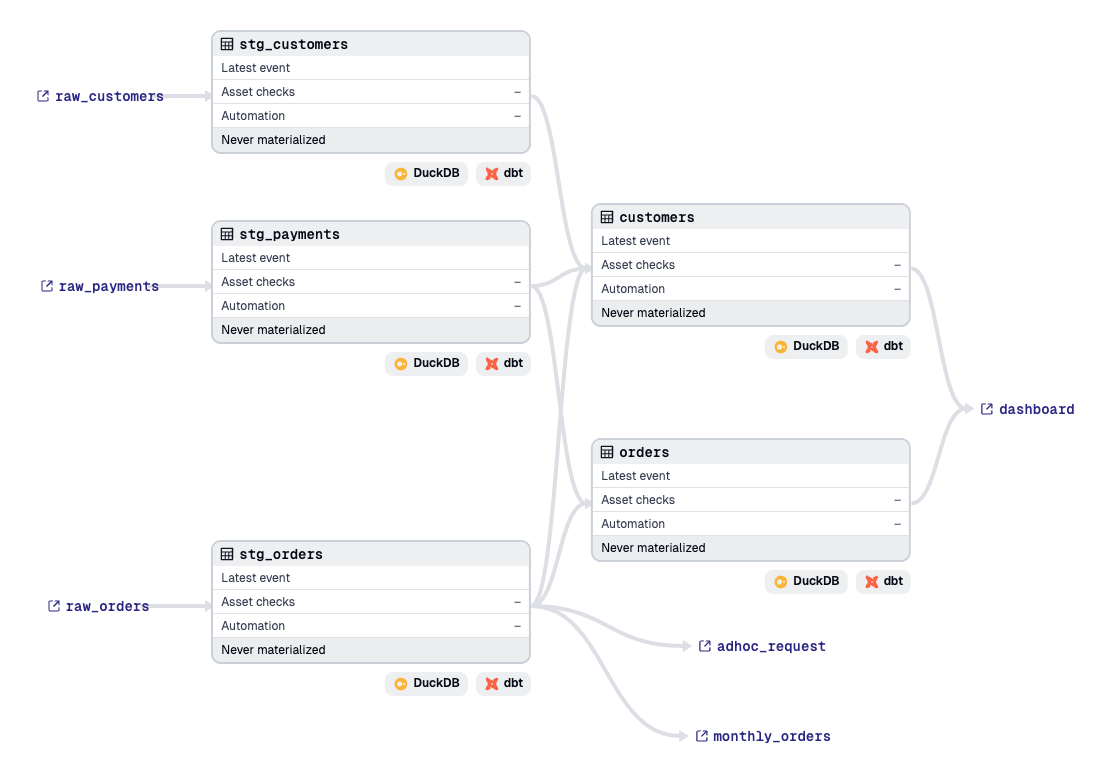
This gives us the Pythonic interface for our dbt models. We can now associate them with other tools in our data platform with other components, or add our own custom assets into the asset graph giving us a full lineage of our data platform.
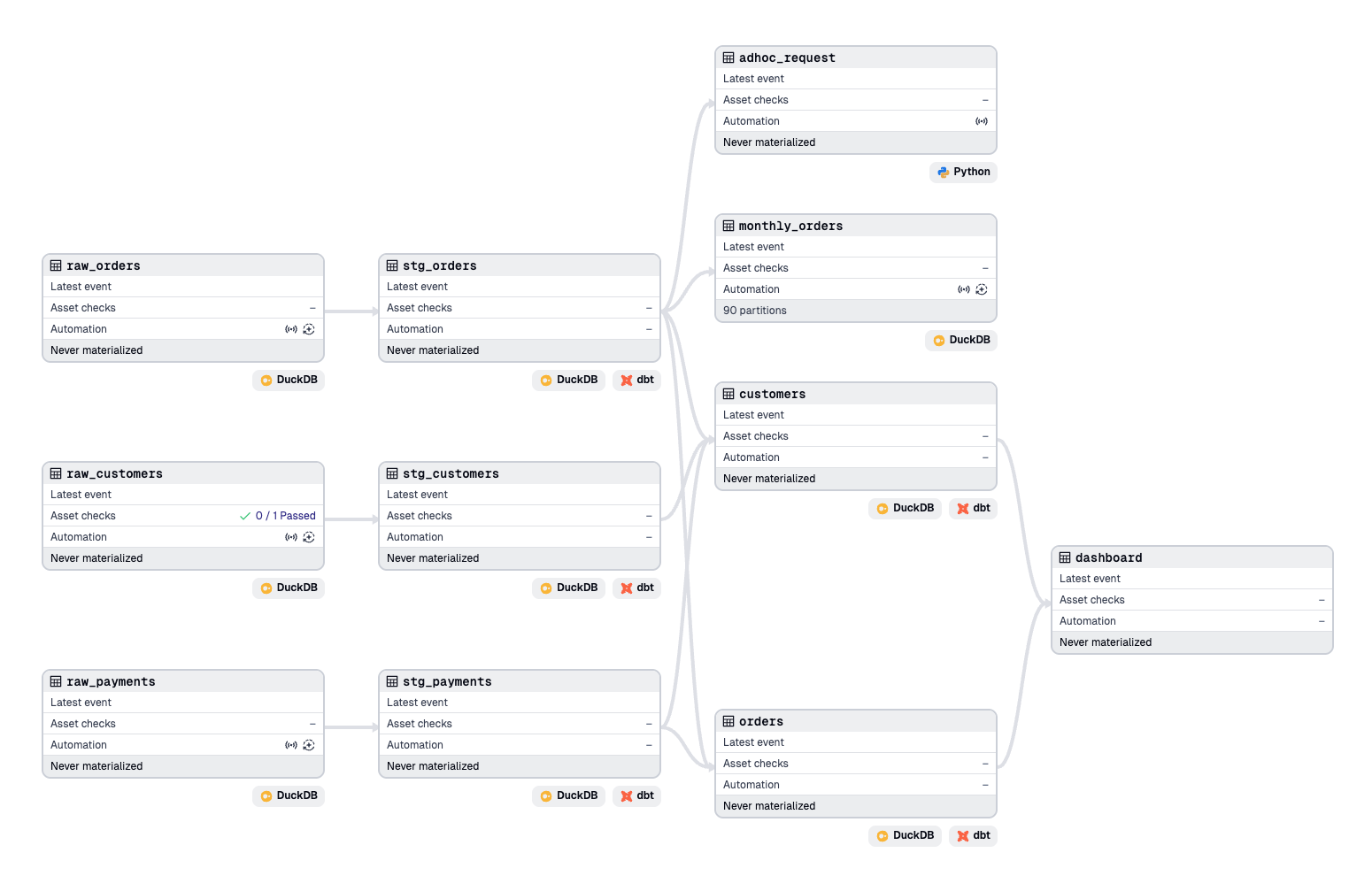
Conclusion
Approaching data with software-defined assets creates a more powerful foundation for building platforms with built-in lineage and observability. This lets teams focus on what their data should produce and the value it delivers, while the orchestrator handles reconciliation and ensures assets are kept in their desired state.
The Modern Data Stack is already moving toward declarative, asset-based principles. By defining dependencies and scheduling policies at the asset level rather than the task level, an asset-based orchestrator becomes the natural fit for this paradigm. Dagster enables this shift by supporting heterogeneous compute and providing a unified control plane, without forcing practitioners back into task-centric, imperative programming.





.jpg)
.png)



.png)

