




Standardizing on Databricks is a smart strategic move, but consolidation alone does not create a working operating model across teams, tools, and downstream systems. By pairing Databricks and Unity Catalog with Dagster, enterprises can add the coordination layer needed for dependency visibility, end-to-end lineage, and faster, more confident delivery at scale.
Enterprises consolidating on Databricks are making a smart strategic bet. Databricks is exceptional at what it was designed to do: unify data and AI workloads on a common lakehouse foundation, with Unity Catalog providing centralized governance across data and AI assets.
But consolidation solves a different problem than coordination.
Once multiple teams, workspaces, and downstream systems depend on that shared platform, the hard part is no longer choosing where workloads run. It is understanding dependencies, ownership, freshness, and impact across the full system.
That is where Dagster fits: not as a replacement for Databricks or Unity Catalog, but as a complementary layer that helps enterprises operate their Databricks strategy at scale. We’ll explore that architecture in more detail in our upcoming webinar.
The coordination gap
A Databricks consolidation strategy usually starts with platform standardization: fewer tools, shared conventions, better governance, and less duplicated infrastructure. That part works. The harder problems emerge afterward, once multiple business units, workspaces, and downstream consumers are involved.
The first is dependency visibility. One team’s transformation may feed another team’s training workflow, which in turn powers a customer-facing application. When something changes upstream, the downstream impact is often invisible until something breaks.
The second is end-to-end lineage. Unity Catalog excels at governing and tracing Databricks-native assets, but enterprise systems do not begin or end within Databricks. Data moves through ingestion tools, transformation layers, Databricks, and downstream applications. Without a way to connect those layers, teams lack a coherent view of the full data supply chain.
The third is operational governance. At enterprise scale, governance is not only about access policies. It also means knowing who owns an asset, whether it is fresh, what depends on it, and who needs to be notified when something changes.
These are not signs that consolidation failed. They are signs that consolidation succeeded and that the organization now needs a coordination layer to operate that shared platform effectively.
How Dagster complements Databricks
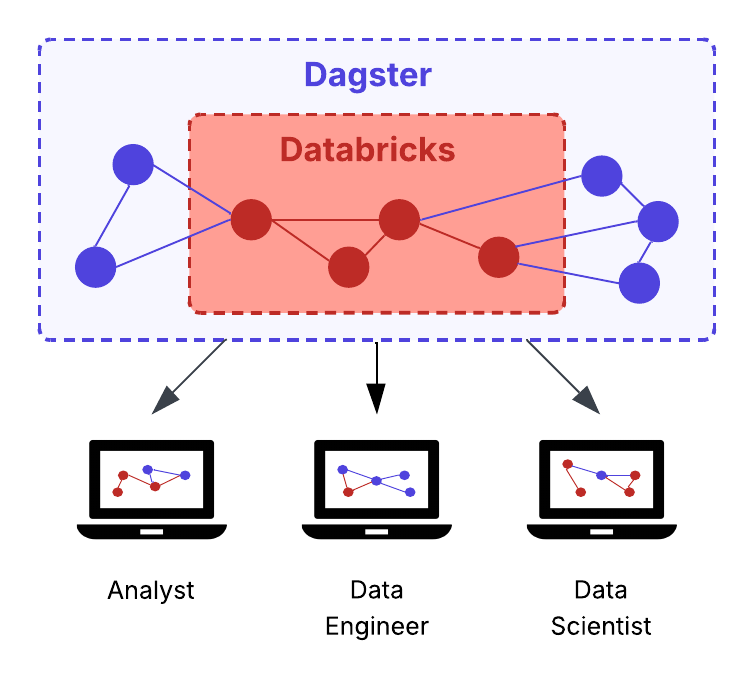
The right framing here is layering, not replacement. Unity Catalog remains the governance authority for Databricks assets. Dagster operates at a different level: providing a shared operational view across the full stack.
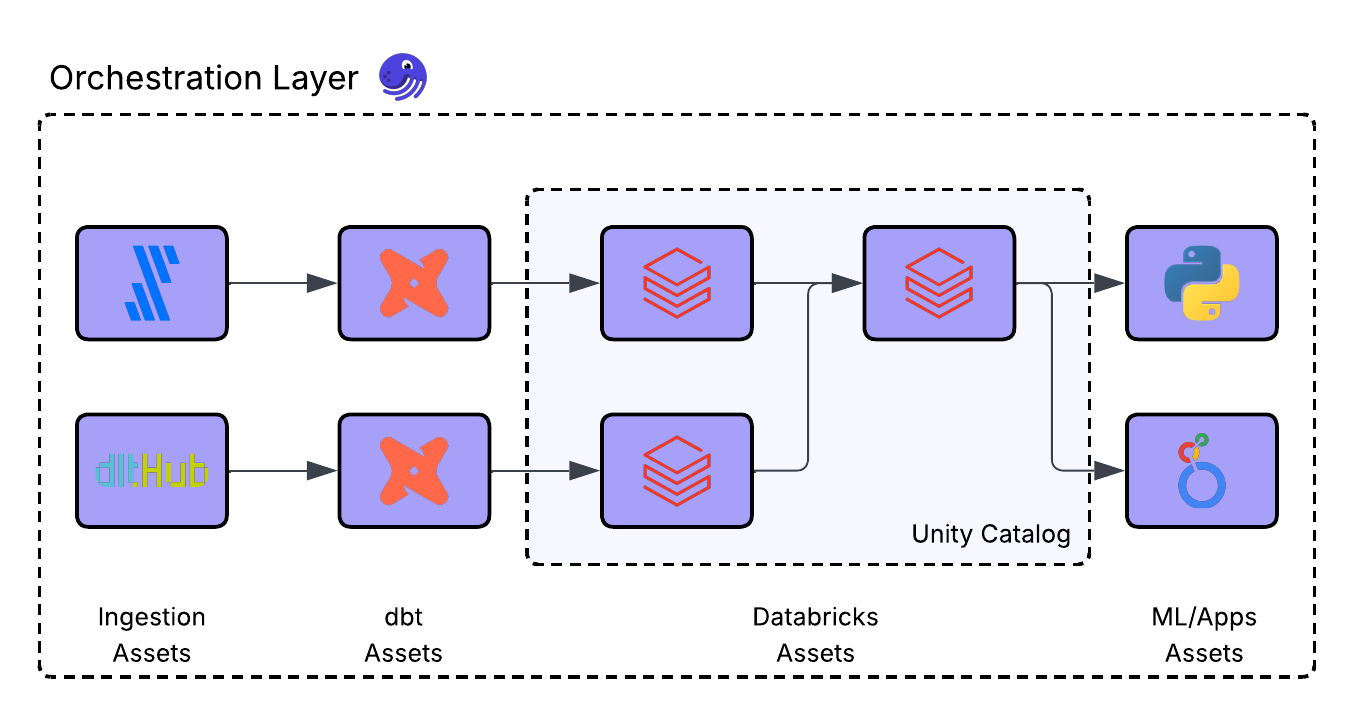
Dagster’s asset catalog is built to represent assets, lineage, freshness, and health across systems. That means a Fivetran sync, a dbt model, a Databricks table, and a downstream application can all appear in the same asset graph, with dependencies tracked across them.
Just as importantly, this is not a migration. Dagster can read Unity Catalog metadata through a read-only connection and represent Databricks assets in its broader operational graph, while Unity Catalog remains the source of truth for governance.
That makes the relationship complementary by design. Unity Catalog governs Databricks-native assets. Dagster makes those assets operationally visible within the wider platform, so teams can coordinate work, understand impact, and manage dependencies across tools and business units.
Full stack as an operating model
In many enterprise environments, the stack already spans multiple systems. Fivetran or Airbyte ingest from source systems. dbt transforms raw data into curated models. Databricks executes large-scale processing and hosts governed data and AI assets. Downstream dashboards, applications, and ML systems consume the results.
What is usually missing is a shared operational view of that end-to-end system.
Without it, each team sees only part of the flow. When something breaks upstream, downstream teams often discover it only after dashboards fail, features drift, or customer-facing systems degrade. Impact analysis is slow, ownership is fuzzy, and cross-team dependencies become bottlenecks.
That lack of visibility also slows delivery. Teams get more cautious when they cannot confidently see the downstream impact. Changes take longer to review, handoffs create friction, and shipping new data products or models carries more risk than it should.
With Dagster sitting across that stack, the operating model changes. Databricks assets can be represented alongside ingestion jobs, transformation models, and downstream consumers in a single operational graph. That gives teams a clearer picture of how work moves through the system, what depends on what, and where ownership sits.
The value is practical. When an upstream change fails, the blast radius is already mapped. When a critical asset goes stale, teams can see it before downstream consumers notice. And when dependencies are visible and ownership is clear, teams can move faster with fewer hidden bottlenecks and more confidence in change.
That is the difference between platform consolidation and an operating model. Consolidation gets workloads onto Databricks. An operating model makes that decision reliable as the system grows more interconnected.
The case for coordination
For large enterprises, the challenge is rarely deciding whether Databricks is the right foundation. The challenge is making that foundation workable across complex teams, regulated workflows, and high-stakes downstream use cases.
That is what a coordination layer provides. It turns a strong platform decision into an operating model that supports accountability for freshness, quality, ownership, and cross-team dependencies.
In regulated or high-impact environments, that matters even more. It is not enough to know that assets are governed inside Databricks. Teams also need confidence in how work moves across the broader stack, which upstream changes affect downstream systems, and who is responsible when something breaks or drifts.
That is why the most successful Databricks consolidations do not stop at standardization. They invest in making that standardization operationally usable. Databricks provides the foundation. Dagster helps teams operate it with more visibility, less risk, and greater confidence.
The right architecture for enterprise scale
The strongest Databricks consolidations do not stop at standardizing where workloads run. They go one step further and make that decision workable across business units, toolchains, and downstream consumers.
That does not require more platform sprawl or a migration away from Unity Catalog. It requires a complementary architecture: Databricks as the lakehouse foundation, Unity Catalog as the governance authority for Databricks assets, and Dagster as the coordination layer that brings orchestration, observability, and end-to-end operational visibility to the full stack.
Each layer does what it was designed to do. Databricks provides the platform. Unity Catalog governs the assets that live there. Dagster makes those assets visible and actionable within the broader system, so teams can move faster with more confidence and fewer bottlenecks.
That is how enterprises unlock the full value of Databricks consolidation: not just by consolidating infrastructure, but by building the operating model that makes that consolidation work at scale.
Join our upcoming webinar for a deeper look at how this architecture works across teams and systems.





.jpg)
.png)



.png)

