




Some of the most interesting Dagster projects come from the community. This post highlights creative community-built applications.
Some of our favorite Dagster use cases are the ones we never could have predicted.
People in the community are using Dagster to explore public datasets, monitor infrastructure, automate research workflows, build internal tools, and experiment with entirely new kinds of data applications. Some projects are deeply technical, some are wonderfully niche, and all of them reflect the creativity of the people building with Dagster.
This post highlights a few community-built projects that caught our attention along with the stories behind them, why their creators picked Dagster, and what the experience of building them was like.
Working on something fun with Dagster? We’d love to hear about it.
Christian Casazza

Tell us a little about yourself and what you work on
I taught myself data engineering on the job because I began to see it as a force multiplier for data value creation. Investing in the data engineering foundation of a system makes everything else downstream easier. I first began working with developers when we needed to create pipelines for e-commerce operational analytics. I enjoyed building the pipeline logic, and then just kept asking the developers questions on how everything worked. With LLMs getting “good enough” beginning with GPT4, I started teaching myself agentic engineering with open source data primitives.
Today, I’m building data value creation systems. My main focus has been to learn by doing, and just building as many end-to-end pipelines as possible. NYC and NY State have among the best curated open government data in the world, and so it's been my initial “Avatar” as I’ve built pipelines across domains like budget, transportation, real estate, legislation, and more. Modern open data primitives combined with coding agents really allow me to go deeper into the pipelines, on both the data enhancement and the analytics side, without investing a ton of capital upfront. In addition to my main NY pipelines, I’ve also created data products around sports with great providers like NFLverse and prediction markets like Polymarket.
How did you first discover Dagster?
I first came across Dagster through social channels and noticed that “high signal” people in the data space seemed to like it, so once my pipelines reached suitable complexity I gave Dagster a shot. What stood out was that Dagster handled many of the generic, “logistics” of data engineering (orchestration, scheduling, asset checks, factory creation, etc) while still feeling natively Pythonic. I liked how I could develop locally fast without infrastructure, so the activation energy to start a new pipeline is low, and the developer cycle is fast.
What project have you been building with Dagster?
I have been building a vertical data stack using open source data primitives. You can explore my public curated datasets at QueryStation.app. Dagster allows me to build detailed ingestion, cleaning, joining, and analytics pipelines.
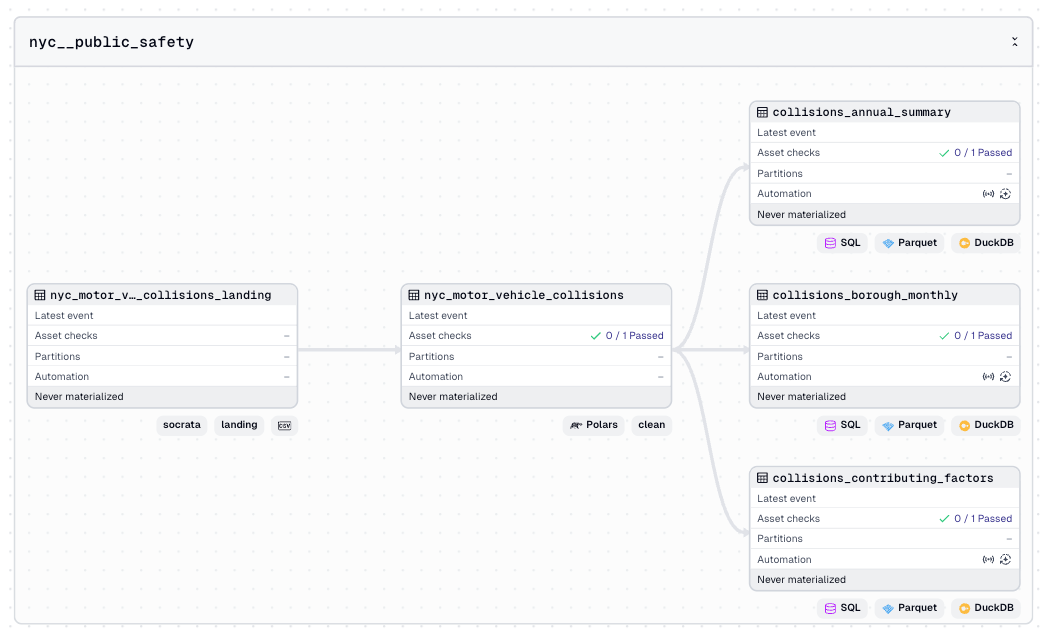
My data pipelines are mainly built around Arrow, Parquet, DuckDB, Polars, and DuckLake. All raw data is initially standardized at the Parquet level, where the Polars Lazyframe engine typically handles the majority of my data wrangling. DuckDB is my engine for writing clean intermediate parquet files to DuckLake and running downstream SQL analytics pipelines. DuckLake is my open table provider, which makes it so much simpler to update tables over time, and for the data application layer to consume the tables. Apache Arrow ensures all layers can speak with each other, such as passing a dataframe to DuckDB or the typescript data app layer querying a DuckLake table and receiving Arrow IPC. Arrow makes it easy to build a SQL based API. For users that want to query my already curated datasets, like NYC 311 or its various budget datasets, they can just query QueryStation directly with SQL and get back Arrow, which can be read into a dataframe and analyzed by agents.
Dagster is the foundation of the data engineering system. It acts as the bridge that turns a collection of scripts using primitives into a linked, coherent system. It standardizes the data pipeline lifecycle by automatically handling DAG management, scheduling, asset checks, metadata storage, and more. Dagster is designed to embed trust into data pipelines so consumers actually use the outputs. The design of the repo is intentionally opinionated around Dagster. The opinionated setup is so agents can focus on context specific data engineering instead of the implementation of the underlying data software. One core idea is reducing the marginal cost of building and expanding new sources. I’ve been developing factory-style patterns where you can provide an AI agent with a URL or API documentation that can then be analyzed to generate formal Dagster assets from templates that will scrape the docs site to create organized markdown files. The “Dagster expert” skill has been helpful for grounding my Dagster development around the core Python best practices.
What was the hardest or most interesting problem you solved?
The most interesting challenge was getting the factory functions online and designing assets in a scalable way. Rather than designing every asset individually, I wanted shared patterns where assets could inherit common behavior like checks, metadata, and documentation. I built toward an asset registry concept: a way to automatically register assets, generate documentation, and allow agents to encode knowledge across work.
def create_socrata_pipeline(
name: str,
socrata_config: SocrataIngestConfig,
schema: SchemaContract,
*,
# Organization (NEW)
domain: str | None = None,
geographic_scope: str | None = None,
group: str | None = None,
# Partitioning
partitions_def: PartitionsDefinition | None = None,
clean_partitions_def: PartitionsDefinition | None = None,
partition_mapping: PartitionMapping | None = None,
# Logic
post_transform_fn: Callable[[pl.LazyFrame], pl.LazyFrame] | None = None,
enrichments: StandardEnrichments | None = None,
# ... more parameters
) -> PipelineResult:
"""Create a 2-stage Socrata pipeline: Landing (CSV) → Clean (Parquet)."""
# Normalize schema: accept 2-tuple or 3-tuple, extract contract
schema_contract, is_3tuple = normalize_schema(schema)
# ... compose landing asset, clean asset, checks
return PipelineResult(
landing=landing_asset,
clean=clean_asset,
checks=checks,
)The hardest part was the front-loaded setup. Some of the work predated the dg CLI, so more of the structure had to be assembled manually. There are often multiple ways to solve the same problem in Dagster, so finding the mental model that makes the most sense takes some trial and error.
I also am figuring the best way to handle open table maintenance jobs, such as those needed for the DuckLake table, within Dagsters. One idea was a maintenance asset that bundles checkpoint or table-maintenance behavior into the graph, while allowing for setting DuckLake configurations at the Python level. However, DuckLake is still fairly new, so some of these best practices will only be possible to know with time.
Why was Dagster a good fit for this project?
Dagster was a strong fit because the project involves many data pipelines that are completely unrelated domain wise, but need consistent patterns around asset code, checks, tests, metadata, scheduling, etc. The AssetFactory pattern makes it easy to design stable, reusable code APIs for the pure logistics aspects of data engineering.
Using a Dagster asset factory also makes it much easier to encode best practices and prevent agentic-based code drift across pipelines. For example, Polars is significantly more performant for data wrangling when leveraging the LazyFrame API with scan and sink_parquet vs using the traditional Eager API with .collect, read, and write_parquet. I’ve found that agents when given leeway are more prone to slipping in manual .collect calls into pipelines that create premature materializations and turn lazy pipelines eager. The factory functions provide strong guardwails to keep transformations end-to-end lazy automatically, so the agent can focus on the actual data wrangling logic it wants to happen instead of the implementation details.
Another really cool aspect of Dagster is it’s a natural fit for building an agent-friendly data pipeline with a contextual domain knowledge system. Dagster stores all of its various metadata(runs, asset info, etc) in SQL tables, which can be done with Postgres and queried through API. Dagster also lets users create custom metadata they can attach to assets which then show up in the Dagster UI. By building into these existing primitives, I’ve been able to add arbitrary types of different domain knowledge to assets. Key info like sources, analyst discovery facts, data quality/quarks caveats, etc. that agents discover as they work can be encoded into the pipeline with Dagster. Encoding the info into the pipeline makes it much easier to carry context across agent sessions and providers. It also makes it easier to build on previous work and build data pipelines that can go deeper and build layered analysis.
What advice would you give someone starting with Dagster?
One of Dagster’s strongest traits, how composable it is, can also be one of its pitfalls for early users. With Dagster, there are often multiple “correct” ways to implement a data pipeline in terms of how you design your code and where the logic lives. This can lead to refactor paralysis to find the “best” way that uses “all” the features.
It's best to start with one complete end-to-end pipeline, ideally something separate from your main work code. Build it, change things, break things, and learn how the pieces fit together. Then slowly layer in the complexity. Add more advanced features like scheduling, asset checks, and custom metadata later. See what breaks and what changes with edits until you have a shape you like. I would also recommend running agents periodically through your repo using the curated Dagster-Expert and Dignified Pipeline skills from the Dagster team. They help to ground your code with best practices that help to avoid agentic drift.
However, once you get past the initial learning curve, don’t be afraid to start being ambitious with Dagster. The composability it gives lets you build some really powerful workflows as a code native workflow builder. The key is to start simple, build something that works, then see what breaks when you try to add sophistication gradually.
Using my repo is personally my recommended way to get started with Dagster. The opinionated setup has many of the core infrastructure and design patterns in place already. Anyone working with an agent can use the repo to build their own end to end data pipeline, using the existing code as an example base for I believe a very wide range of data pipelines someone may want to build.





.jpg)
.png)



.png)

