


What Are Data Orchestration Tools?
Data orchestration tools manage data workflows, automating the movement and transformation of data across different systems. These tools simplify processes, ensuring data flows in an organized manner. They enable synchronization between various data processes, offering mechanisms to schedule, manage, and monitor data workflows. This ensures that data is available at the right time and place, supporting real-time analytics and business operations.
Organizations rely on data orchestration tools to handle intricate data pipelines, reduce manual intervention, and increase operational efficiency. They minimize errors by defining clear dependencies between tasks. These tools provide an overarching view of data processes, allowing systems to adapt to changes and scale operations without compromising data integrity.
This is part of a series of articles about data platforms.
Key Features of Data Orchestrators
1. Workflow Scheduling
Workflow scheduling enables the automation of data pipelines to run at specified times or in response to particular events. This ensures that workflows can be executed without manual intervention, reducing operational overhead.
Orchestration tools offer various scheduling options, from simple time-based scheduling (such as daily or hourly triggers) to more complex event-driven triggers. Advanced tools may support dynamic scheduling, adjusting based on workload or data availability, ensuring efficient resource usage and timely data processing across the organization.
2. Task Dependency Management
Dependencies between tasks can be defined using data orchestrators, ensuring that each task begins only when its predecessor has completed successfully. This avoids situations where tasks execute prematurely, which can lead to incomplete or inaccurate data processing.
Additionally, orchestration tools often allow for conditional task execution, where a task might only run if previous tasks meet certain criteria, further enhancing the flexibility and reliability of data pipelines.
3. Data Lineage
Data lineage provides a detailed record of the data's journey through various workflows, tracking where the data originates, how it transforms, and where it ends up. This capability is crucial for auditing, troubleshooting, and ensuring the accuracy of analytical results. By visualizing the flow of data through pipelines, organizations can trace specific data points, understand dependencies between tasks, and quickly identify the source of errors or anomalies.
Advanced data orchestration tools allow users to inspect and audit data transformations at each step of the pipeline, ensuring compliance with data governance standards. This visibility helps organizations maintain trust in their data by providing a clear path of how data was processed and what changes were made along the way, simplifying root-cause analysis in the event of data issues.
4. Metadata Management
Metadata management in data orchestration involves organizing, storing, and maintaining information about the data being processed. Effective metadata management enables users to track key details about datasets—such as schema definitions, file formats, and version history—ensuring consistency and discoverability across various workflows.
Data orchestration tools often integrate metadata management features to improve the discoverability and traceability of datasets. These tools can automatically capture metadata during the execution of data workflows, facilitating easier debugging, optimizing resource allocation, and supporting regulatory compliance by keeping a record of how data is used, accessed, and modified throughout its lifecycle.
5. Error Handling and Retry Mechanisms
Data pipelines are prone to errors, whether due to system failures, network issues, or incorrect configurations. Data orchestration tools are equipped with sophisticated error handling and retry mechanisms to mitigate these challenges.
When a task fails, the orchestrator can automatically retry it based on customizable retry logic, such as a set number of attempts or waiting intervals between retries. If the retries fail, the tool typically raises alerts, logs the error, and can trigger alternative workflows or compensating actions to handle failures gracefully, ensuring minimal disruption to business operations.
6. Monitoring and Logging
Orchestration tools offer real-time tracking of task execution, allowing users to monitor the status of workflows, identify performance bottlenecks, and detect failed tasks quickly. Logs provide detailed information about each task's execution, including success and failure messages, duration, and resource consumption.
This visibility helps in diagnosing problems and in optimizing performance and resource allocation, leading to more efficient data processing and faster problem resolution.
7. Integrations with Other Data Sources
Data orchestration tools can connect to databases, cloud storage systems, SaaS applications, data lakes, and big data processing platforms like Apache Spark, Hadoop, or ETL frameworks. This allows them to seamlessly move and transform data across disparate environments, support complex data workflows that may span on-premises and cloud infrastructures.
By supporting native integrations with popular services, data orchestration tools can serve as the unified control plane for heterogeneous and disparate workflows across the data platform.
8. Security and Access Control
Security is a top concern for any data-related operation. These tools often support role-based access control, ensuring that only authorized personnel can access or modify workflows and sensitive data.
Many tools also integrate with existing authentication systems such as LDAP or OAuth, allowing for single sign-on (SSO) and enforcing strict access policies. Additionally, data orchestrators may include encryption for data at rest and in transit, ensuring that sensitive information is handled securely throughout the workflow.
9. Visualization and UI
Data orchestration tools provide intuitive user interfaces and visualization capabilities that simplify the management of complex workflows. Many offer drag-and-drop interfaces for designing workflows visually, making it easier for users to build, configure, and manage pipelines without needing extensive coding skills.
The visualization features also extend to monitoring, where users can observe the flow of data in real time, quickly identifying bottlenecks or issues. This allows both technical and non-technical users to interact with data pipelines, fostering collaboration and reducing the learning curve associated with more technical data management tools.
10. Data Quality Checks
Ensuring data quality is critical to maintaining accurate analytics and operations, and data orchestration tools support this through automated data quality checks. These checks can be implemented at various stages in the workflow to validate data for correctness, completeness, and consistency.
For example, tools can flag missing values, detect outliers, or verify that data meets predefined formatting rules. When issues are detected, the workflow can either halt, alert users, or trigger remediation processes, ensuring that only high-quality, reliable data is processed and used for downstream tasks like analytics or machine learning models.
Notable Data Orchestration Tools
1. Dagster

Dagster is an open-source data orchestration platform for the development, production, and observation of data assets across their development lifecycle. It features a declarative programming model, integrated lineage and observability, data validation checks, and best-in-class testability.
- License: Apache-2.0
- Repo: https://github.com/dagster-io/dagster/
- GitHub stars: 11K+
- Contributors: 400+
Key features of Dagster:
- Data asset-centric: Focuses on representing data pipelines in terms of the data assets that they generate, yielding an intuitive, declarative mechanism for building data pipelines.
- Observability and monitoring: Aims to be the “single pane of glass” for your data team, with a robust logging system, built-in data catalog, asset lineage, and quality checks.
- Cloud-native and cloud-ready: Provides a managed offering with robust, managed infrastructure, elegant CI/CD capability, and support for custom infrastructure.
- Integrations: Extensive library of integrations with the most popular data tools, including the leading cloud providers (AWS, GCP, Azure), ETL tools (Fivetran, Airbyte, dlt, Sling), and BI tools (Tableau, Power BI, Looker, and Sigma).
- Flexible: Supports any Python workflow and lets you execute arbitrary code in other programming languages and on external environments using Dagster Pipes.
- Declarative Automation: Lets you go beyond cron-based scheduling and intelligently orchestrate your pipelines using event-driven conditions that consider the overall state of your pipeline and upstream data assets.

2. Apache Airflow

Apache Airflow is an open-source platform to develop, schedule, and monitor batch-oriented workflows. It allows users to build and manage complex workflows using Python code. With Airflow’s web interface, users can track the state of their workflows and adjust as necessary.
- License: Apache 2.0
- Repo: https://github.com/apache/airflow
- GitHub stars: 36k+
- Contributors: 3k+
Features of Apache Airflow:
- Workflows as code: Lets users define workflows entirely using Python, enabling dynamic, customizable pipeline creation.
- Extensible framework: Integrates with different technologies and lets users extend functionalities as needed.
- User interface: Provides visibility into pipeline status, logs, and task management.
- Scheduling and execution: Offers scheduling capabilities with rich semantics for defining workflows that run at regular intervals.
- Version control and collaboration: Workflows can be stored in version control, allowing rollbacks and multi-developer collaboration.

3. Prefect

Prefect is a data orchestration tool that enables users to build, manage, and monitor data workflows with enhanced security, scalability, and observability. It allows users to automate workflows across different infrastructure while maintaining control and collaboration features.
- License: Apache 2.0
- Repo: https://github.com/PrefectHQ/prefect
- GitHub stars: 17k+
- Contributors: 300+
Features of Prefect:
- Dynamic workflows: Supports the orchestration of any Python-based workflow.
- Enterprise-grade scalability: Scales orchestration with features like scheduling, retries, concurrency management, and automation.
- Fine-grained access control: Enables teams to collaborate securely with role-based access, sharing, and permissions management.
- Centralized monitoring and observability: Offers a unified dashboard for tracking, deploying, and managing workflows, ensuring visibility into system metrics and logs.
- Resilient pipelines: Automates workflows with built-in retries and transactional semantics to ensure reliability in the face of failures.
4. Databricks Workflows

Databricks Workflows is a fully managed orchestration service integrated with the Databricks Data Intelligence Platform. It allows users to create, manage, and monitor multitask workflows for ETL, analytics, and machine learning pipelines.
- License: Commercial
Features of Databricks Workflows:
- Platform integration: Fully integrated with Databricks, allowing automation of notebooks, Delta Live Tables, and SQL queries without external orchestration tools.
- Reliability: Offers guaranteed 99.95% uptime.
- Monitoring and observability: Provides insights into every workflow run, with notifications for failures via email, Slack, PagerDuty, or custom webhooks.
- Batch and streaming orchestration: Supports both scheduled batch jobs and real-time pipelines with triggers based on data availability.
- Compute management: Optimizes resource usage with automated job clusters that only run when scheduled, ensuring cost-effective performance for production workloads.

5. Google Cloud Composer

Google Cloud Composer is a fully managed workflow orchestration service built on Apache Airflow and is used to automate and manage complex data workflows across cloud and on-premise environments. Cloud Composer simplifies the creation, scheduling, and monitoring of workflows using Airflow’s capabilities, without the burden of infrastructure management.
- License: Commercial
Features of Google Cloud Composer:
- Managed Airflow environment: Fully managed Airflow service, eliminating the need to handle infrastructure setup or maintenance.
- Cross-cloud orchestration: Orchestrates workflows that span multiple cloud platforms and on-premises systems.
- DAG-based workflows: Offers Python-based DAGs to define and schedule complex data pipelines with clear task dependencies.
- Google Cloud integration: Provides built-in connectors for Google Cloud services like BigQuery, Cloud Storage, and Pub/Sub, simplifying data movement and processing.
- Scalable Kubernetes architecture: Supports Airflow components, such as schedulers and workers, which run on Google Kubernetes Engine for scalable execution.

6. Azure Data Factory

Azure Data Factory (ADF) is a fully managed cloud service for data orchestration and integration across hybrid environments. It enables the creation, scheduling, and monitoring of data-driven workflows, allowing organizations to transform raw data from various sources.
- License: Commercial
Features of Azure Data Factory:
- Data connectivity: Connects to a range of data sources, including relational, non-relational, and on-premises systems.
- ETL and ELT pipelines: Supports data workflows for transforming and integrating data using mapping data flows or compute services like Azure Databricks and Azure HDInsight.
- Custom triggers: Automates pipeline execution with event-driven triggers, enabling workflows to run based on events such as file uploads or schedule-based triggers.
- Scalable data transformation: Leverages Spark clusters for scaling data transformation tasks, ensuring that large datasets are processed efficiently without managing infrastructure.
- Security and monitoring: Features role-based access control (RBAC), integrated security with Entra ID, and monitoring through Azure Monitor to ensure data protection and pipeline visibility.

7. Metaflow

Metaflow is an open-source data orchestration framework to simplify the development and management of machine learning, AI, and data science workflows. Built originally by Netflix, Metaflow provides an environment to develop, scale, and deploy data-driven projects, while automatically handling aspects such as versioning, orchestration, and scaling to the cloud.
- License: Apache 2.0
- Repo: https://github.com/Netflix/metaflow
- GitHub stars: 8k+
- Contributors: \~100
Features of Metaflow:
- Python-based workflows: Allows users to write and manage workflows in plain Python, making it easy to orchestrate complex data and ML processes.
- Scalable compute: Leverages cloud resources, including GPUs and multi-core instances, to scale workflows as needed, enabling parallel processing and large-scale computations.
- Automatic versioning: Tracks and stores variables and data versions throughout the workflow, providing a complete history for easy experiment tracking and debugging.
- Cloud integration: Scales from local development to cloud deployments on AWS, Azure, Google Cloud, or Kubernetes without users modifying the codebase.
- Simplified deployment: Deploys workflows to production with a single command, integrating with existing systems and automatically handling updates in data.

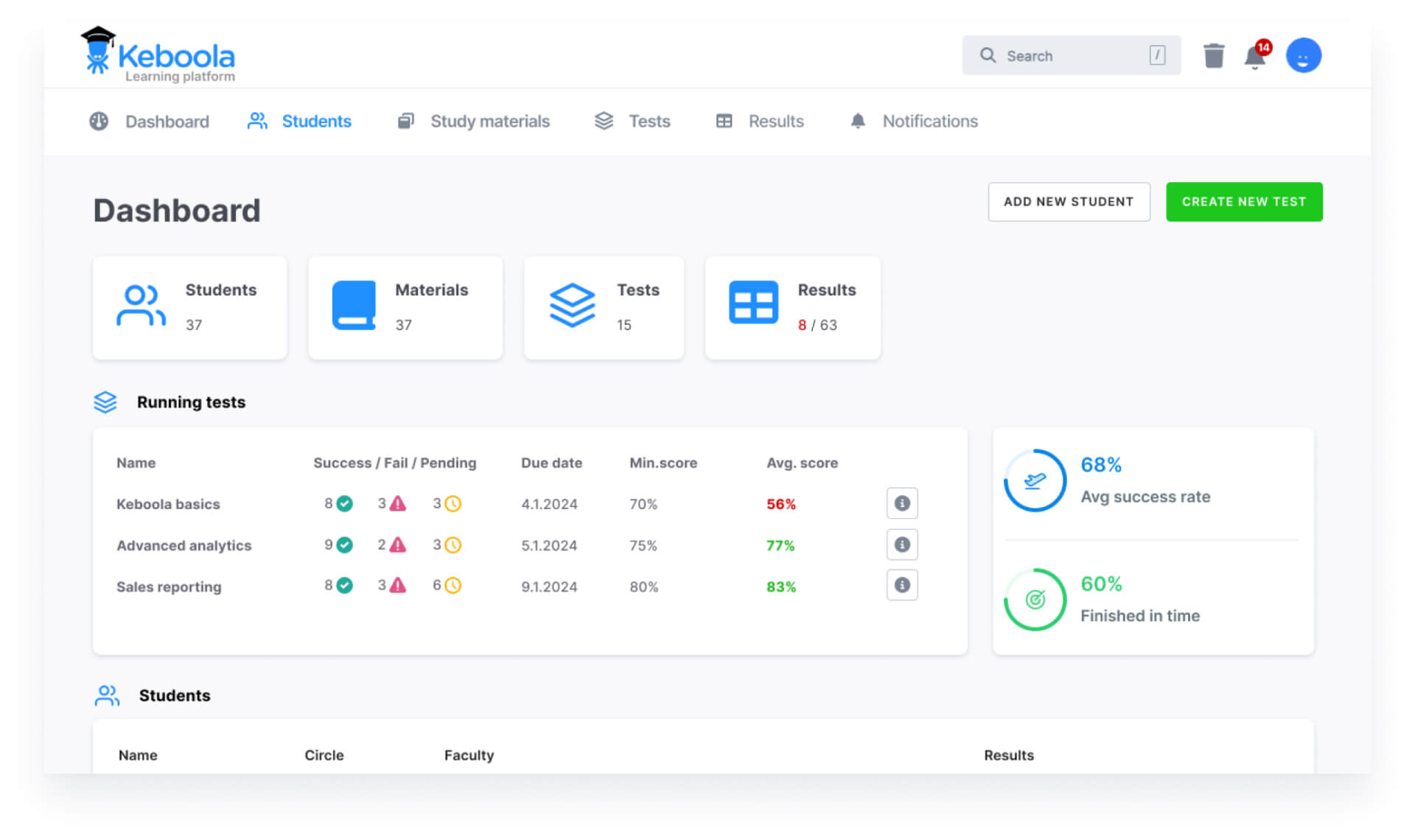
8. Keboola

Keboola is a data orchestration platform to simplify data integration, automation, and governance. By offering self-service capabilities, Keboola allows users to build, deploy, and manage data solutions without relying on IT departments.
- License: Commercial
Features of Keboola:
- Self-service data integration: Simplifies the process of integrating data from multiple sources, empowering users to manage their own data workflows without IT involvement.
- Automation and orchestration: Automates data workflows and applications, enabling faster execution of business processes with minimal manual intervention.
- Pre-built solutions: Offers a library of pre-built components and templates, allowing users to deploy data workflows, AI solutions, and automations with a single click.
- Data governance and security: Built with security and governance in mind, ensuring compliance with data regulations and providing control over data access and usage.
- AI integration: Provides an easy onramp to AI, enabling companies to augment datasets and build AI-powered applications and automations without complex infrastructure.
9. Mage

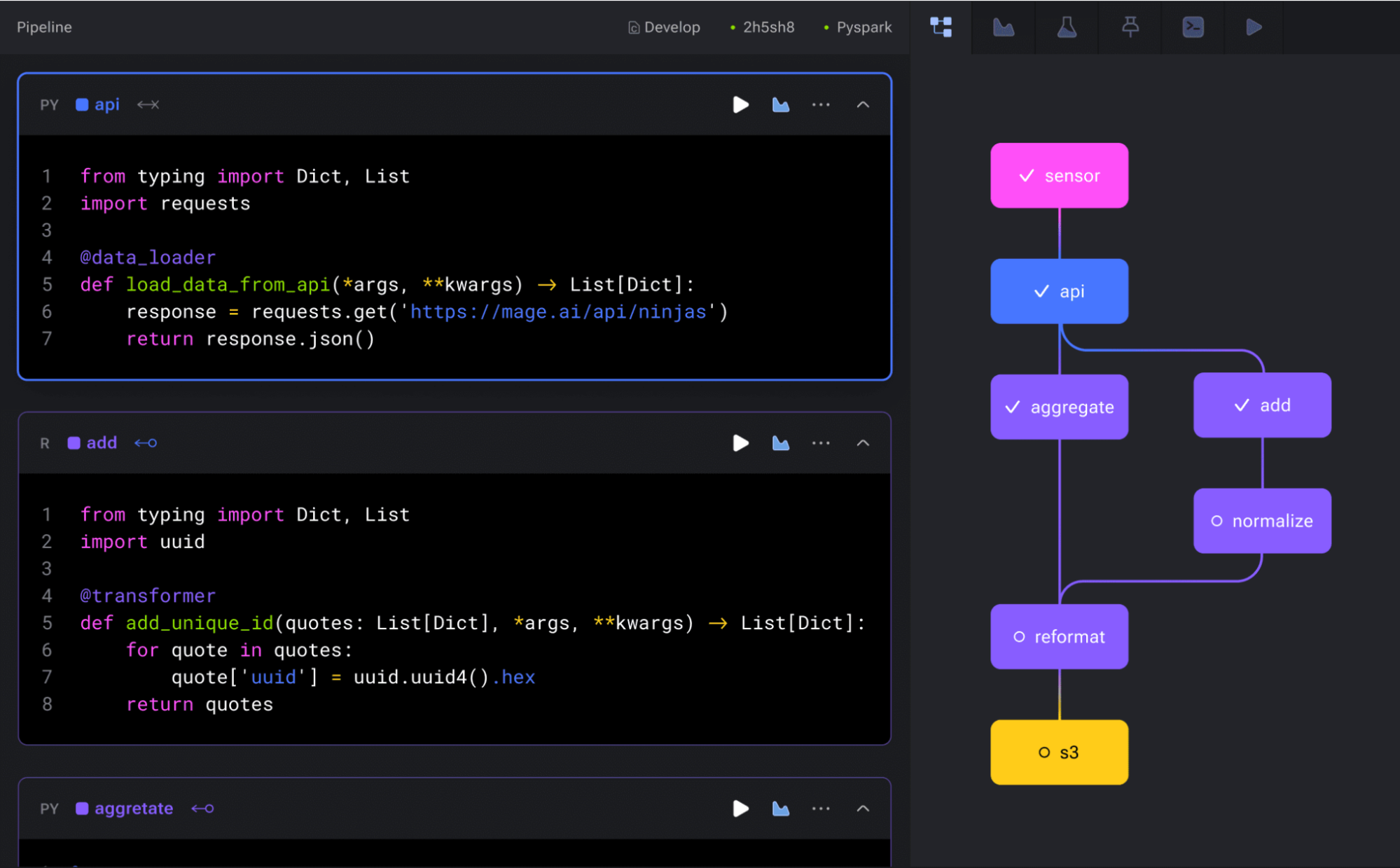
Mage is an open-source data orchestration framework to simplify and improve the process of building, transforming, and managing data pipelines. Combining the flexibility of notebooks with modular, testable code, Mage enables developers to extract, transform, and load data.
- License: Apache 2.0
- Repo:https://github.com/mage-ai/mage-ai
- GitHub stars: 7k+
- Contributors: 100+
Features of Mage:
- Hybrid data orchestration: Users can schedule and manage data pipelines with interactive notebooks and reusable, modular code.
- Multi-language support: Users can write pipelines in Python, SQL, or R.
- Built-in observability: Monitors and tracks pipelines with UI tools for observability, including real-time alerts and logs.
- Data integration: Synchronizes data from third-party sources to internal destinations with pre-built connectors.
- Interactive development: Offers a notebook editor to run code interactively and preview results instantly, improving the developer experience.
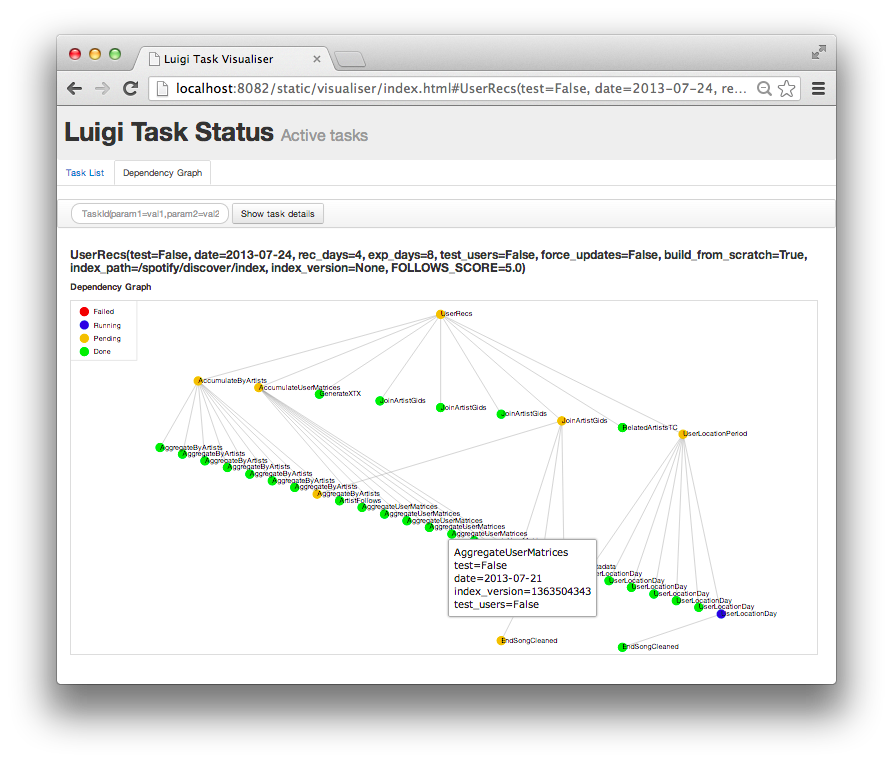
10. Luigi

Luigi is a Python-based data orchestration tool for building and managing complex pipelines of batch jobs. It handles tasks such as dependency resolution, workflow management, and failure handling, allowing users to automate and monitor long-running processes.
- License: Apache 2.0
- Repo: https://github.com/spotify/luigi
- GitHub stars: 17k+
- Contributors: 500+
Features of Luigi:
- Dependency resolution: Automatically manages dependencies between tasks, ensuring workflows execute in the correct order.
- Workflow management: Handles the orchestration of thousands of long-running tasks, making it suitable for complex batch jobs.
- Extensible integration: Supports a variety of tools and frameworks like Hadoop, Spark, and Hive, while also allowing custom Python tasks.
- Atomic file operations: Guarantees that file system operations (e.g., in HDFS or local files) are atomic, preventing pipeline crashes due to partial data.
- Visualization: Provides a web interface with a visualizer that displays the dependency graph, helping users track task completion and identify bottlenecks.
Key Considerations for Choosing a Data Orchestration Tool
Here are some of the factors that organizations should consider when evaluating data orchestration solutions.
Ease of Use and Developer Productivity
Tools with intuitive user interfaces, low-code or no-code options, and clear documentation allow developers to quickly build, manage, and troubleshoot data workflows. Visual pipeline editors, drag-and-drop components, and predefined templates further enhance usability by simplifying workflow creation without requiring extensive coding knowledge.
In addition, tools that support popular programming languages like Python, SQL, or R can significantly improve productivity by allowing developers to work with familiar environments. The availability of debugging tools, real-time logging, and version control features also enables teams to iterate faster, manage changes effectively, and maintain reliable workflows.
Scalability and Performance
Data orchestration tools must be able to scale as the volume, variety, and velocity of data increase. This includes handling more tasks in parallel and orchestrating workflows across distributed environments like cloud platforms or on-premises systems. The chosen tool should support horizontal scaling, dynamic workload distribution, and efficient resource utilization.
Performance optimization features such as job prioritization, resource throttling, and adaptive scheduling help maintain high throughput and responsiveness, even under heavy workloads. Tools that leverage cloud-native architectures or support distributed computing frameworks like Kubernetes often provide greater scalability for large-scale data operations.
Error Handling and Reliability
Unexpected failures in workflows can disrupt operations. A suitable tool should provide comprehensive error management features, including automatic retries, failure notifications, and fallback mechanisms. These features ensure that the workflow can recover from failures with minimal downtime or manual intervention.
Tools that allow users to define custom retry logic, such as setting retry intervals or the number of attempts, improve flexibility in managing errors. Built-in support for checkpointing and transactional tasks ensures that workflows can resume from the last successful state, improving overall reliability and reducing the risk of data loss or corruption during failures.
Integration Capabilities
Integration capabilities determine how well the tool connects to existing systems and data sources. A wide range of connectors ensures seamless data flow across different platforms, enhancing data accessibility and processing capabilities.
The tool should integrate smoothly with existing data pipelines, databases, and analytical tools, supporting diverse data processing environments. Integration flexibility reduces the need for extensive custom solutions and ensures quick deployment into existing workflows.
Observability and Monitoring
The data orchestration tool should provide real-time insights into the status of workflows, helping teams identify and resolve issues quickly. Monitoring capabilities such as health checks, performance metrics, and detailed logs enable proactive detection of bottlenecks, delays, or failures.
Comprehensive alerting features, including integration with notification systems like Slack, PagerDuty, or email, allow teams to respond to issues promptly. The tool should also offer dashboards or visualizations that display key metrics, such as task durations, resource utilization, and success/failure rates.
Modularity and Reusability
A modular architecture enables the reuse of components across different workflows. Modularity allows users to break down workflows into smaller, reusable tasks or components, promoting efficiency and consistency. Reusable components reduce the time needed to build new workflows, as developers can easily leverage existing modules without rewriting code or logic.
In addition, tools that support the creation of templates, reusable functions, or workflow libraries help maintain standardization across different projects. Modular designs accelerate development and simplify maintenance, as individual components can be updated or replaced without affecting the entire pipeline.
Security and Compliance
The data orchestration tool must support encryption for data at rest and in transit to protect sensitive information. Role-based access control (RBAC), audit logging, and multi-factor authentication (MFA) are key features that ensure only authorized personnel can access or modify workflows.
Compliance with standards such as GDPR, HIPAA, or SOC 2 is another critical factor to consider. Tools that offer built-in compliance features, such as data masking, logging of sensitive operations, and automated audits, help organizations meet regulatory requirements more easily.
Extensibility and Customization
A tool that offers APIs, SDKs, or plugin support allows developers to extend its functionality by integrating custom logic, third-party services, or bespoke components. This flexibility is crucial for organizations with unique requirements that may not be fully addressed by out-of-the-box features.
Customization options, such as user-defined workflows, custom operators, or specialized connectors, also allow teams to adapt the tool to their specific infrastructure or business processes. Tools with open-source components or active developer communities often offer better support for extensibility, as users can contribute or use community-built plugins.
Community Support
An active community and support system are Access to a vibrant community fosters collaboration and problem resolution, providing broader insights into effective tool use. Additionally, professional support and documentation are useful for training users and resolving complex problems.
Why Choose Dagster?
Unlike other orchestrators, Dagster aims to be the unified control plane for your data platform. It not only orchestrates your data processes but also provides a flexible, programmable platform allowing multifunctional data teams to run any tool on any infrastructure at scale, while serving as the single pane of glass to orchestrate and monitor these processes.
It features native integrations with the most popular data tooling and cloud platforms, a best-in-class developer experience, and built-in support for complex event-driven triggers, data quality checks, and a rich data catalog.
Learn more about the Dagster platform






.jpg)
.png)



.png)

