




Guide to the some common AI Architectures patterns with Dagster
You likely have an AI application you want to get off the ground. Given how quickly the space is evolving it can be difficult to know where to get started. Below are some common patterns that can help get you started.These are a potential toolbox for ways to solve AI problems. They will be helpful in different situations, and you may use some more often (you may never pre-train a model from scratch yourself). They can also be combined; you can combine RAG with a fine-tuned model.
Prompt Engineering
Overview
Prompt engineering is the practice of designing input prompts to guide the behavior of an LLM. Users can get more accurate and task-specific outputs by structuring prompts for specific use cases without knowing anything about the underlying model.
Benefits
- Development Speed. Prompt engineering requires the least amount of engineering. As a result, it is very easy to iterate and experiment at low cost.
- Minimal Infrastructure. Unlike RAG, which requires an external storage layer, or pretraining, which requires extensive GPUs for compute, prompt engineering is self-contained.
Architecture
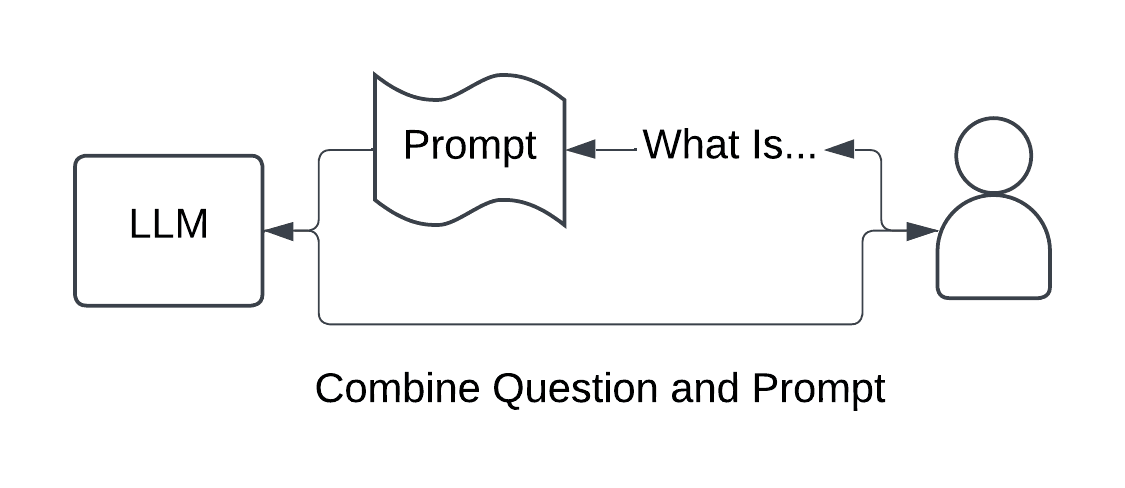
A user asks a question. The information from the question is parsed and injected into a predefined prompt. The prompt adds context or specific rules to help craft a more detailed response from the model.
When the prompt has been constructed, the full prompt is sent to the LLM, which then provides an answer.
Example Prompt Engineering with Dagster
Imagine you are designing an application to help users answer questions about Pandas. You want the answers to be grounded in the context of Pandas and to supply useful supplemental information.
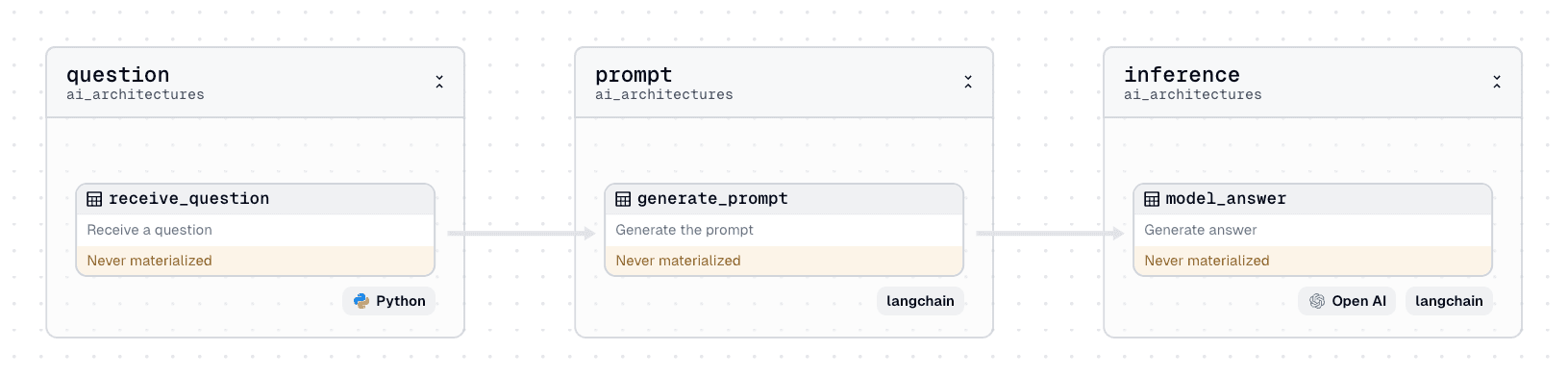
- Question. A user inputs a question. With Dagster, these can be set at execution time with run configurations so you can reuse the same DAG to answer multiple questions.In this case, the user asks the ambiguous question, “What is a series?” but we know they are interested in Pandas.
- Prompt. A prompt is needed to generate a helpful answer grounded in Pandas. We will use Langchain to help with the prompt engineering processing. Langchain makes it easy to develop and use prompt templates. We may iterate on the prompt template as we calibrate an appropriate response from the LLM. Our template may look like this:
system_template = f"""
In the context of the python framework Pandas. Answer the questions in 1 or 2 sentences.
Also include two links for further relevant information.
Question: {question}
"""
- Inference. The prompt and input can now be combined and passed to the LLM. Again, we will use Langchain but also need an underlying model such as OpenAI’s
gpt-4o-minito answer the question.Now, we can see that even a somewhat unclear question will return a relevant answer in the format we feel is most instructive for the user.
In Pandas, a Series is a one-dimensional labeled array capable of holding any data type, similar to a column in a spreadsheet or a database table. Each element in a Series is associated with an index, which allows for efficient data access and manipulation.\n\nFor further information, you can check the following links:\n- Pandas Series Documentation\n- Introduction to Pandas Series
RAG
Overview
Retrieval augmented generation (RAG) enhances performance by integrating external knowledge. With this approach, a retrieval system fetches relevant data from an external storage layer (often a vector database). The retrieved data is then used as context for the LLM, which can provide more accurate and informed responses.
Benefits
- Dynamic. Allows data to be updated separately without the need to retrain the model.
- Domain-specific contextualization. Provide traceable sources and citations for responses and reduce hallucinations.
- Cost efficiency. Requires less parameter storage for the LLM as storage is pushed to the external storage layer.
Architecture

Source data is converted into high-dimension vectors (embeddings) that represent the semantics of the content. These embeddings are added to an index within a vector database. Vector databases function like traditional databases but allow queries based on similarity measures, which is ideal for content retrieval.
After the vector database is populated, relevant information can be combined with an LLM to answer a prompt. The answer generated will be grounded in the domain-specific context of the data contained within the vector database.
Example RAG with Dagster
Imagine you want to provide answers specific to your organization. These answers should be grounded in the constantly occurring discussions in Slack and GitHub.
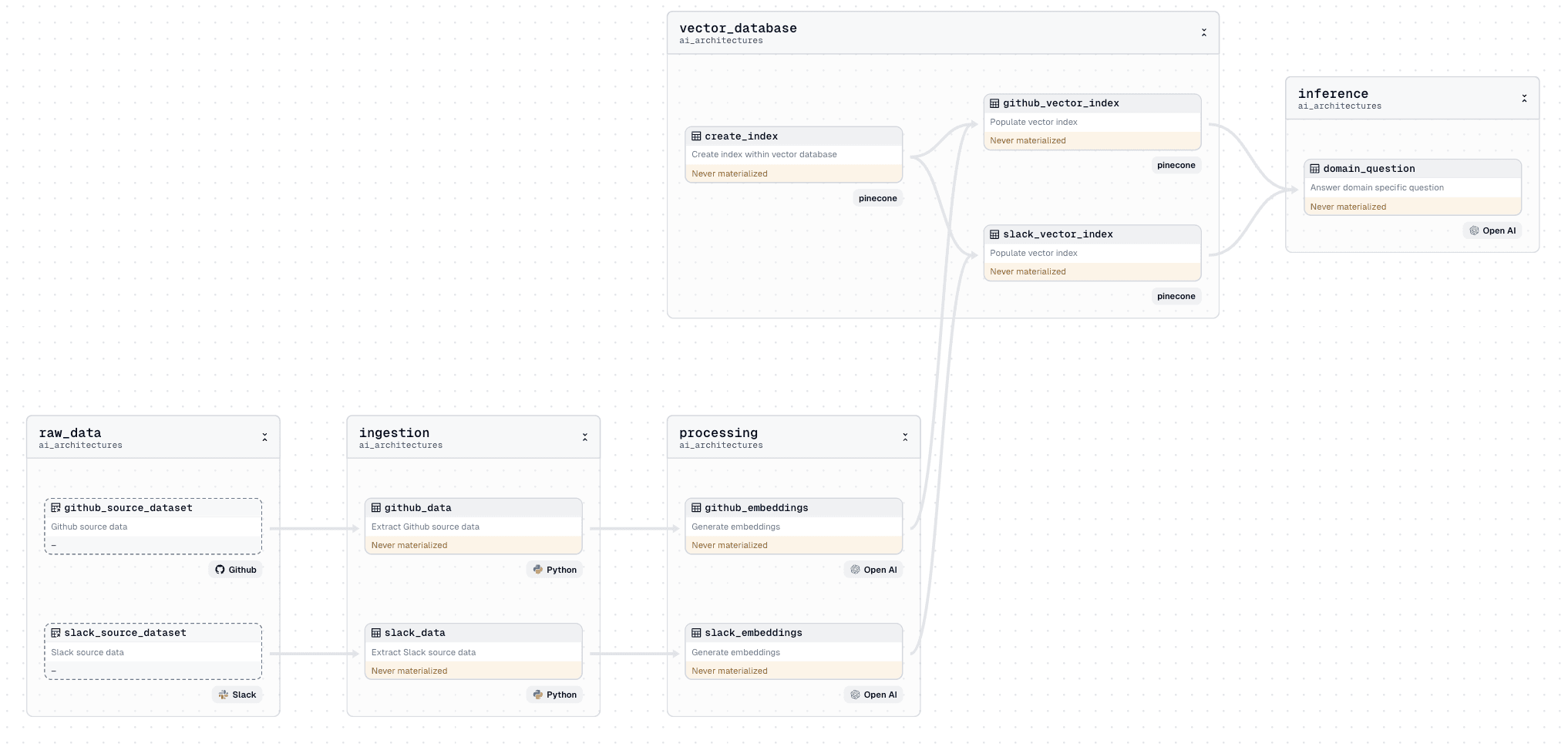
- Ingestion. Data from Slack and GitHub is extracted by either writing your own code or leveraging frameworks such as dlt and Dagster embedded ETL. The cadence of extraction can be based on a traditional schedule or event-based, such as new GitHub issues being created using sensors.
- Processing. After the data has been extracted, embeddings can be created. Dagster integrates easily with AI tools such as LangChain and offers native support for the OpenAI Python client. Using these tools, data can be split appropriately, and embeddings can be generated.
- Vector Database. Once the embeddings are created, data is uploaded to the vector index. Dagster can manage the index creation and orchestrate the addition of new embeddings. As the application scales, Dagster can run processes concurrently.
- Inference. With the vector database populated with Slack and GitHub information. One or more AI applications can now rely on that database as it is continuously refreshed.
Fine-Tuning
Overview
Fine-tuning is the processing of using an existing pre-trained LLM and adapting it based on a small dataset for a specific task. When a model is fine-tuned, only a few weights are changed.
Benefits
- Customization. Tailors the model's behavior to align with specific goals, voice, or application requirements.
- Cost efficiency. Allows for token savings due to shorter prompts. Fine-tuning also allows for less computationally expensive models to be used while still offering the performance of more expensive alternatives.
- Output control. Have total control of the format and style of a model’s output.
Architecture
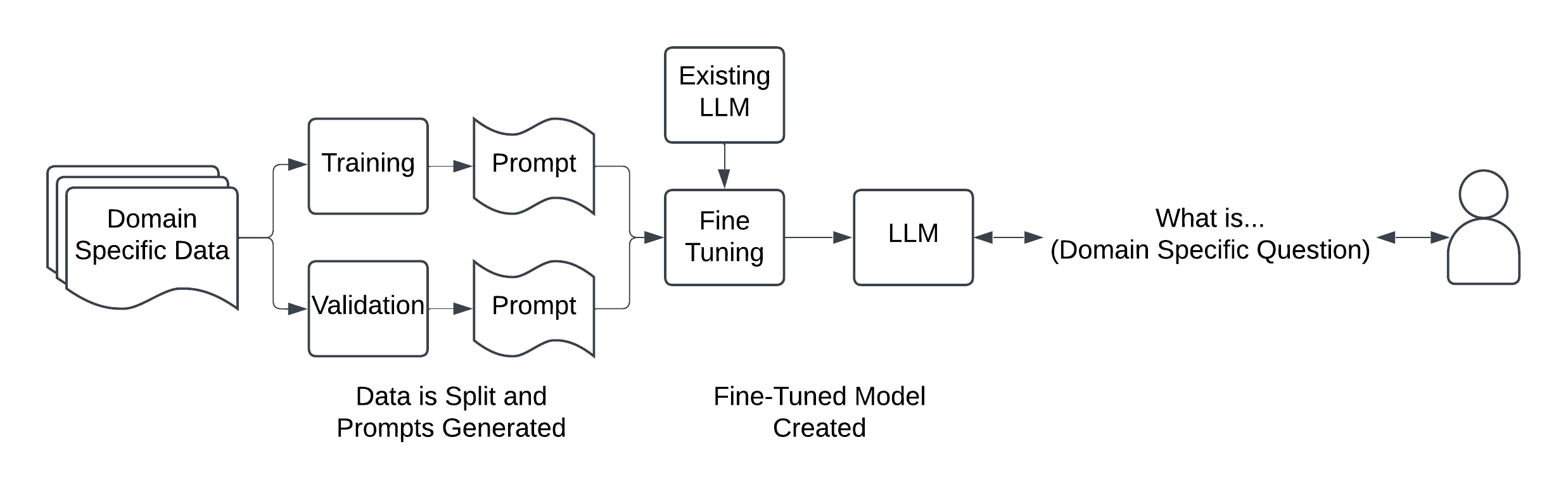
Data is collected and split into two samples, one for training the final model and one for validation. These samples do not have to be large; a few dozen examples are usually enough.
Next, each sample is converted into prompts that mimic the desired interaction with the model. These prompts can be grounded in specific knowledge, conversation style (such as answering cheerfully), or both.
After creating the sample prompts, they can be provided as inputs for a fine-tuning job. This may take a while, depending on the number of samples and the underlying model used to train. After the fine-tuning job is completed, a new model will be produced that can be queried.
Example Fine-Tuning with Dagster
Imagine you want to provide answers to questions asked in your GitHub repository. You want these answers to match the tone of the answers already in the repo and be consistent with the style users are familiar with.

- Ingestion. Data from GitHub can be extracted using several tools you are already familiar with. This data can also be categorized into discrete periods using partitions, which might help understand how answers have changed over time.
- Processing. The data can then be sampled and split across a training and validation set. Using this data, we can craft the prompts. This might involve combining the data from Github with some additional prompt engineering.The format of the prompts will depend on what is used to fine-tune the models. If using OpenAI, the conversations might look like this:
{"messages": [{"role": "system", "content": "You answer Github issues in an upbeat and helpful way to ensure user success."}, {"role": "user", "content": data["github_question"]}, {"role": "assistant", "content": data["github_answer"], "weight": 1}]}
- Fine-Tuning. After the prompts are generated, they can be uploaded to the storage layer in OpenAI. The Dagster OpenAI resource makes this easy and can pass the file IDs to the fine-tuning job endpoint, generating a model specific to this use case. A Dagster asset check can also be tied to the new model to ensure it performs as expected.
- Inference. The new model is ready to be used. If it ever needs to be retrained the assets can be re-executed to pull in additional Github issues to generate additional prompts.
Pretraining
Overview
Pretraining a model involves training it on a large volume of data without using any prior weights from an existing model. This results in a model that can be used or further fine-tuned.
This is generally the most intensive AI pattern regarding data, work, and computational resources. It is less common for organizations to need to retrain their own model and instead rely more on some combination of prompt engineering, RAG, and pretraining.
Benefits
- Avoid biases. Starting from scratch can ensure that your model has no unintended biases from existing models.
- Unique data. If your data is unique and specific to your use case and is unlikely to be included as part of the knowledge base for open and more generalized LLMs.
- Different Languages. Models for languages not well represented by general models may benefit from pretraining. For example, if a model is trained only on English text, even with fine-tuning or RAG, it may struggle to give correct answers in other languages.
Architecture
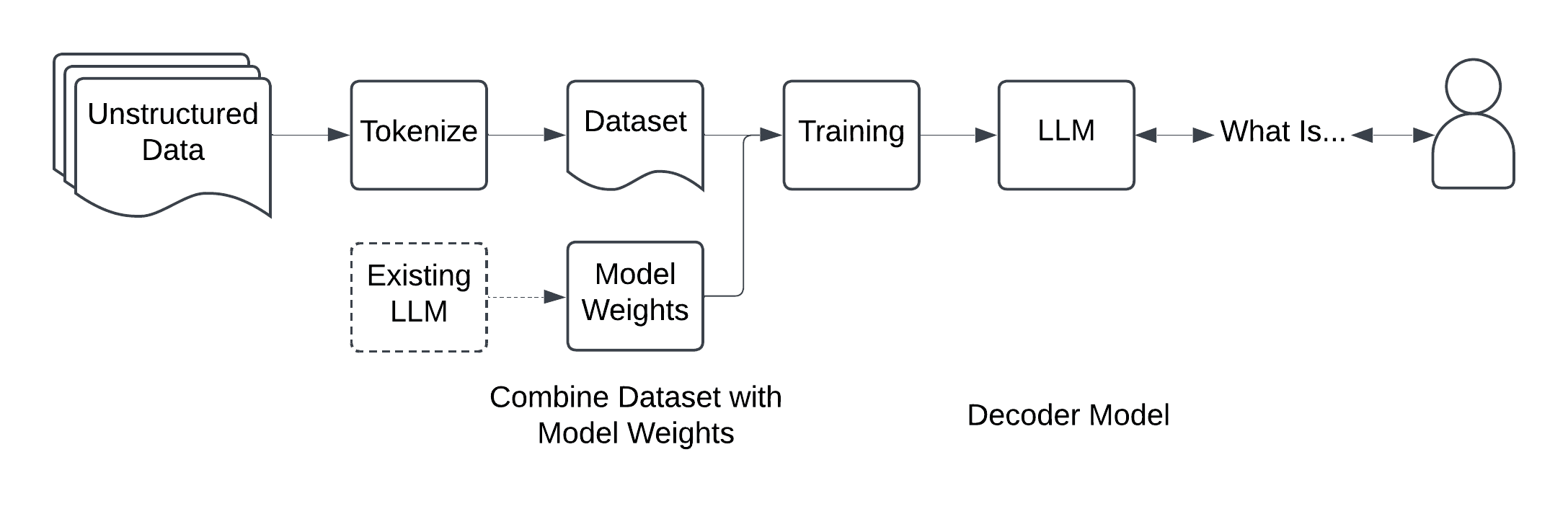
There is no single way to pre-train a model, and many tradeoffs to be made between cost and performance. Training smaller models generally starts with a large amount of unstructured text. This might be books, articles, wikis, or anything with extended text examples.
Next, you will need to turn the text into tokens. The tokens represent the individual fragments of the overall text. These tokens then need to be converted into their corresponding IDs, which will be used for training.

This data will then be combined with model weights. There are several ways to handle weights, such as using random weights, which is the most expensive or more commonly, using the weights of an existing model.
Data and weights can now be combined in training. Depending on the number of parameters, this can take several weeks or more, potentially costing hundreds of thousands of dollars. Training uses much more memory than inference and requires expensive GPUs. This will produce a decoder-only model that can generate the next token (word) in a sequence.
Example Pretraining with Dagster
Imagine you have written a new programming language and would like to create a model that can assist users in developing with it.
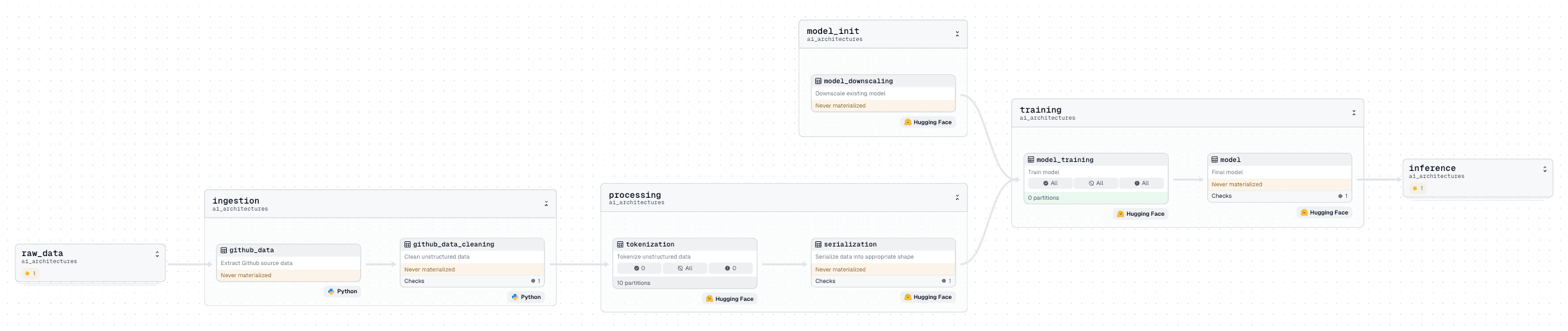
- Ingestion. A large amount of data needs to be collected. We can imagine ingesting the entirety of the GitHub repo (though that may not be enough). After the data is collected, it needs to be cleaned. This includes deduplication, removing typos, filtering out languages unrelated to the language you wish to train your model on, and other steps that may bias the data. Assets checks can be included to help ensure data quality.
- Processing. The unstructured data needs to be split into tokens and IDs. To help speed up the process, this work can be partitioned over several concurrent assets. After the unstructured data has been mapped to IDs, it can be shaped and converted to a format such as a Hugging Face DataFrame for training.
- Model Init. In addition to our own data, we may use the weights of an existing model. This will be much more cost-effective than generating random weights. We will have to determine an appropriate existing model and whether we want to use its existing number of layers, upscale a smaller existing model (add the layers), or downscale (remove the layers) a larger model.
- Training. The most expensive step is training a model. Depending on the number of parameters, this step may take considerable time. We can use HuggingFace to execute our training job and partition the checkpoints of our model within Dagster. This will produce a model that can generate the next token in our custom programming language, which will most likely be the next. We will want to include some model evaluations or asset checks to ensure it behaves as expected.
- Inference. The model can now be used, though it may need to be fine-tuned or combined with RAG to give more context-aware answers.





.jpg)
.png)



.png)

