




Dagster 1.3 officially inducts Pythonic Config and Resources and brings new enhancements to Software-Defined Assets, integrations, documentation, and guides.
Dagster 1.3: Smooth Operator
We are proud to make Dagster 1.3 available on Dagster Cloud and in Open Source.
This release:
- officially inducts Pythonic Config and Resources as a permanent part of the system. It was introduced as an experimental feature in 1.2.
- brings a number of enhancements to Software-Defined Assets related to tracking changes, auto-materialization, partitions, and the ergonomics of the powerful backfill functionality.
- includes new enhancements to integrations, documentation, and guides.
Pythonic Config and Resources: Experimental no more

After several weeks of review and fine-tuning, we are taking the “experimental” badge off the new Pythonic Config and Resources. The lead engineers on this effort (Nick Schrock and Ben Pankow) explored this topic in a recent Community Memo and discussed it live on our Community call on April 11th. We would like to thank all the members of the community who helped to road-test this new feature and provided valuable feedback.
The related documentation has been updated, including:
Examples, integrations, and documentation have largely ported to the new APIs.
Note that the old Resources and Config APIs will continue to be supported for the foreseeable future. Check out [migration guide](https://docs.dagster.io/guides/dagster/migrating-to-pythonic-resources-and-config) to learn how to incrementally adopt the new APIs.
What's new in Software-Defined Assets
Dagster's asset-first approach to designing pipelines continue to resonate strongly with a growing community of data engineers. Based on the positive feedback from the community we continue to build out this core abstraction with more powerful features.
Here is what has been released for Software-Defined Assets in Dagster 1.3:
Auto-Materializing Assets
- Auto-materialize policies replace the asset reconciliation sensor - We've made substantial improvements to the APIs used for specifying which assets are scheduled declaratively. Compared to
build_asset_reconciliation_sensors introduced in Dagster 1.2,AutoMaterializePolicys work across code locations, and allow you to customize the conditions under which each asset is auto-materialized. [docs] - Auto-materialize policies and data versions - We've made it possible to auto-materialize stale assets that are downstream of an observable source asset. They now use the source asset observations to determine whether upstream data has changed and assets need to be materialized. [docs]
UI Improvements
- Asset backfill page - A new page in the UI for monitoring asset backfills shows the progress of each asset in the backfill. [docs]
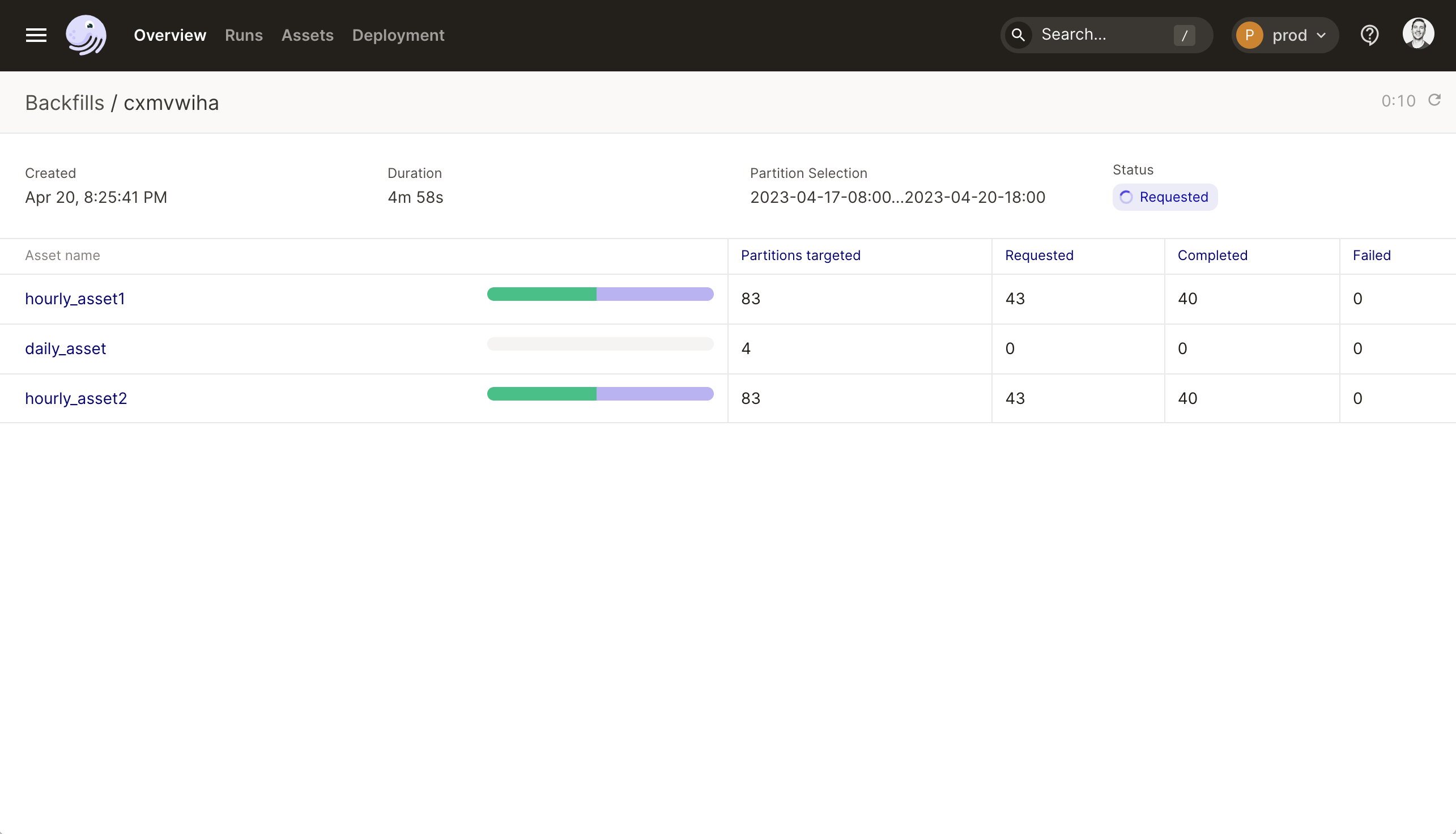
- Clearer labels for tracking changes to data and code - Instead of the opaque “stale” indicator, Dagster’s UI now indicates whether code, upstream data, or dependencies have changed. When assets are in violation of their
FreshnessPolicys, Dagster’s UI now marks them as “overdue” instead of “late”. [docs]
Docs Enhancements
We continue to invest in the Dagster docs to make them more accessible, complete, and up-to-date.
- Improved run concurrency docs - The new "Limiting concurrency in data pipelines" guide is a one-stop-shop for understanding and implementing run concurrency, whether you’re on Dagster Cloud or deploying to your own infrastructure.
- Additions to the Intro to Assets tutorial - We’ve added two new sections to the assets tutorial, focused on scheduling and I/O.
- New best-practice guide to building machine learning pipelines - Many Dagster users learn best by example - this guide walks you through building a simple machine learning pipeline using Dagster. You can explore more best practice guides here.
- Re-organized Dagster Cloud docs - We overhauled how the Dagster Cloud docs are organized, bringing them more in line with the UI.
1.3 Contributors
We are very grateful to community contributors to the Dagster project, who provide precious input by suggesting new features, submitting PRs, and helping identify and document bugs.
Here is a shout-out to all contributors to 1.3 - Dagster would not be what it is without your help.
nhuray |{' '} tghankenelben10 | ldnicolasmay | Abbe98 | mikekutzma | fridiculous | mpicard | NicolasPA | AndyBys | charliermarsh | Taadas | planvin





.jpg)
.png)



.png)

