




A major release with Declarative Scheduling, multi-asset scheduling, and SDA partitioning. Plus Secrets management, Dagit enhancements, Integrations updates and more...
We are thrilled to release version Dagster 1.1: Thank U, Next.
This is a big one. It includes support for declarative, asset-based scheduling, big improvements to our Fivetran, Airbyte, and dbt Cloud integrations, and more. We shared many of these enhancements during our Community Day update on Dec 7th, so feel free to watch the highlights here.
What’s new with Software-defined Assets?
Declarative Scheduling for Data Assets
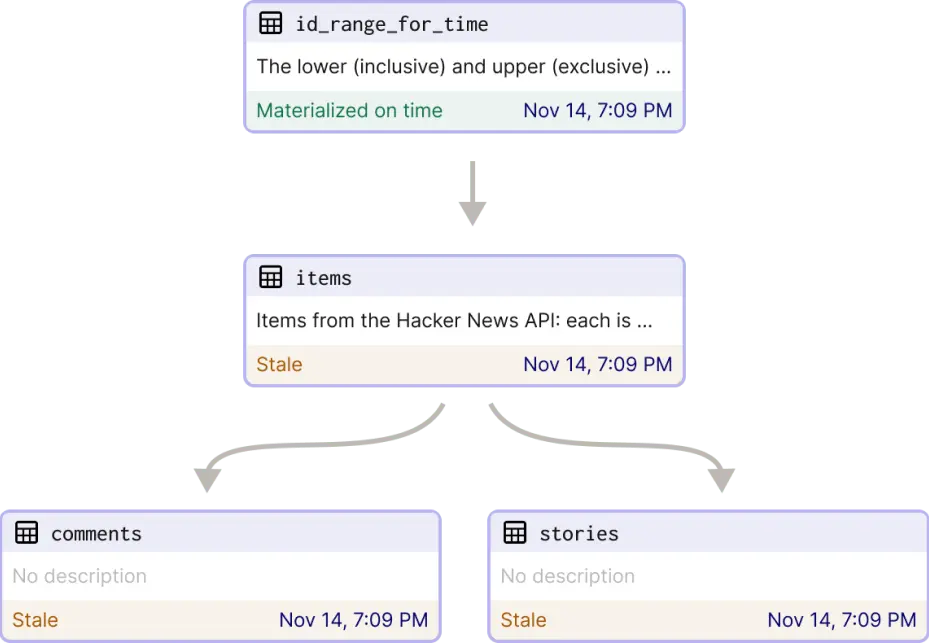
Declarative, asset-based scheduling is a principled way of managing change that models each data asset as a function of its predecessors, and schedules work based on how up-to-date you want your data to be.
Declarative Scheduling is detailed in its own blog post, and a hands-on guide on using declarative scheduling with software-defined assets is available, but here are some highlights:
Declarative scheduling will make working with assets much more efficient. You just declare at the asset level how frequently the asset should be updated (known as the “freshness policy”), and Dagster works backward from there.
As source code and upstream data change, the updates ripple through the asset graph, eagerly or lazily, depending on the requirements of the data products they support.
- The new asset reconciliation sensor automatically materializes assets that have never been materialized or whose upstream assets have changed since the last time they were materialized. It works with partitioned assets too. You can construct it using
build_asset_reconciliation_sensor. - You add a
FreshnessPolicyto any of your software-defined assets, to specify how up-to-date you expect that asset to be. You can view the freshness status of each asset in Dagit, alert when assets are missing their targets using the@freshness_policy_sensor, and use thebuild_asset_reconciliation_sensorto make a sensor that automatically kick off runs to materialize assets based on their freshness policies. - You can now version your asset ops and source assets to help you track which of your assets are stale. You can do this by assigning
op_versions to software-defined assets orobservation_fns toSourceAssets. When a set of assets is versioned in this way, their “Upstream Changed” status will be based on whether upstream versions have changed rather than on whether upstream assets have been re-materialized. You can launch runs that materialize only stale assets.
DIY scheduling: going multi-asset
- A much-requested feature was a sensor that can monitor the state of more than one asset. Now, with the new
@multi_asset_sensordecorator, you can define custom sensors that trigger based on the materializations of multiple assets. Similarly, with the newasset_selectionparameter on@sensorandSensorDefinition, you can now define a sensor that directly targets a selection of assets instead of targeting a job.
… and other SDA improvements:
- SDAs can be partitioned, allowing you to launch materializations of individual partitions and view the materialization history by partition in Dagit. With this new release, you can create multi-dimensional partitions for Software-defined Assets. In Dagit, you can filter and materialize certain partitions by providing ranges per-dimension, and view your materializations by dimension.
- By loading assets as Python objects, we have made it easier to do exploratory data analysis on notebooks. This is achieved through
RepositoryDefinitionand theload_asset_valuemethod.
Environment Variables for local development:
- Easily use environment variables during local development: With this latest release, environment variables included in a
.envfile will be automatically included in the environment of any Dagster code that runs. - As a side note, Dagster Cloud Serverless also released a new feature for managing secrets and other environmental variables straight in the Dagster Cloud UI. We explain the feature in our Community Day recap here.
Dagit (Dagster UI) enhancements
Overview Page
The Overview page is the new home for the live run timeline and helps you understand the status of all the jobs, schedules, sensors, and backfills across your entire deployment. The timeline is now grouped by code location and shows a run status rollup for each group. You can also look ahead to see when scheduled jobs will run in the future.
Your browser does not support the video tag. Dagit - the Dagster interface - showing the new Overview page
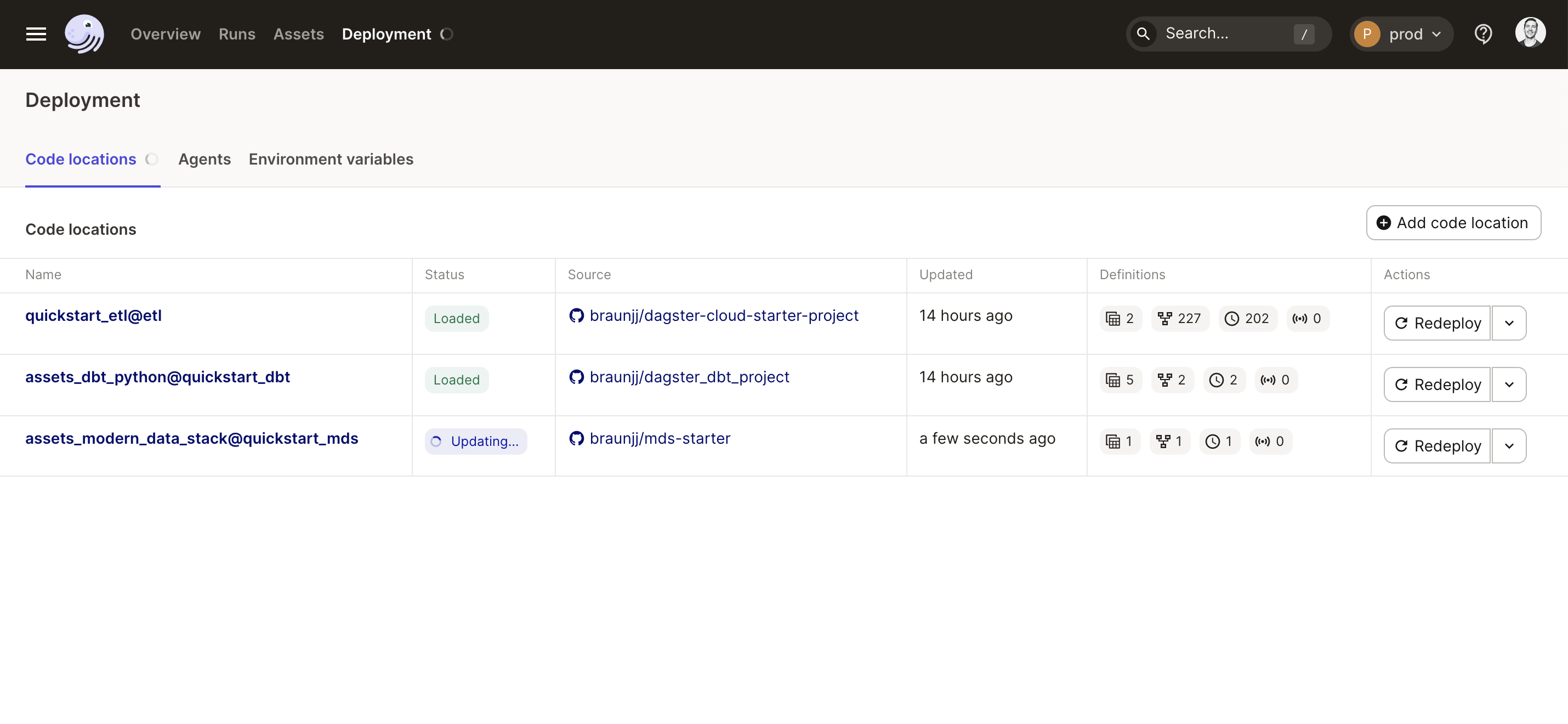
Deployment Page
The new Deployment page helps you quickly manage your Dagster instance and all its code locations. Here you can monitor the status of each code location, view its source, and browse all definitions within it. Definition views have been re-architected to load significantly faster when you have thousands of them.
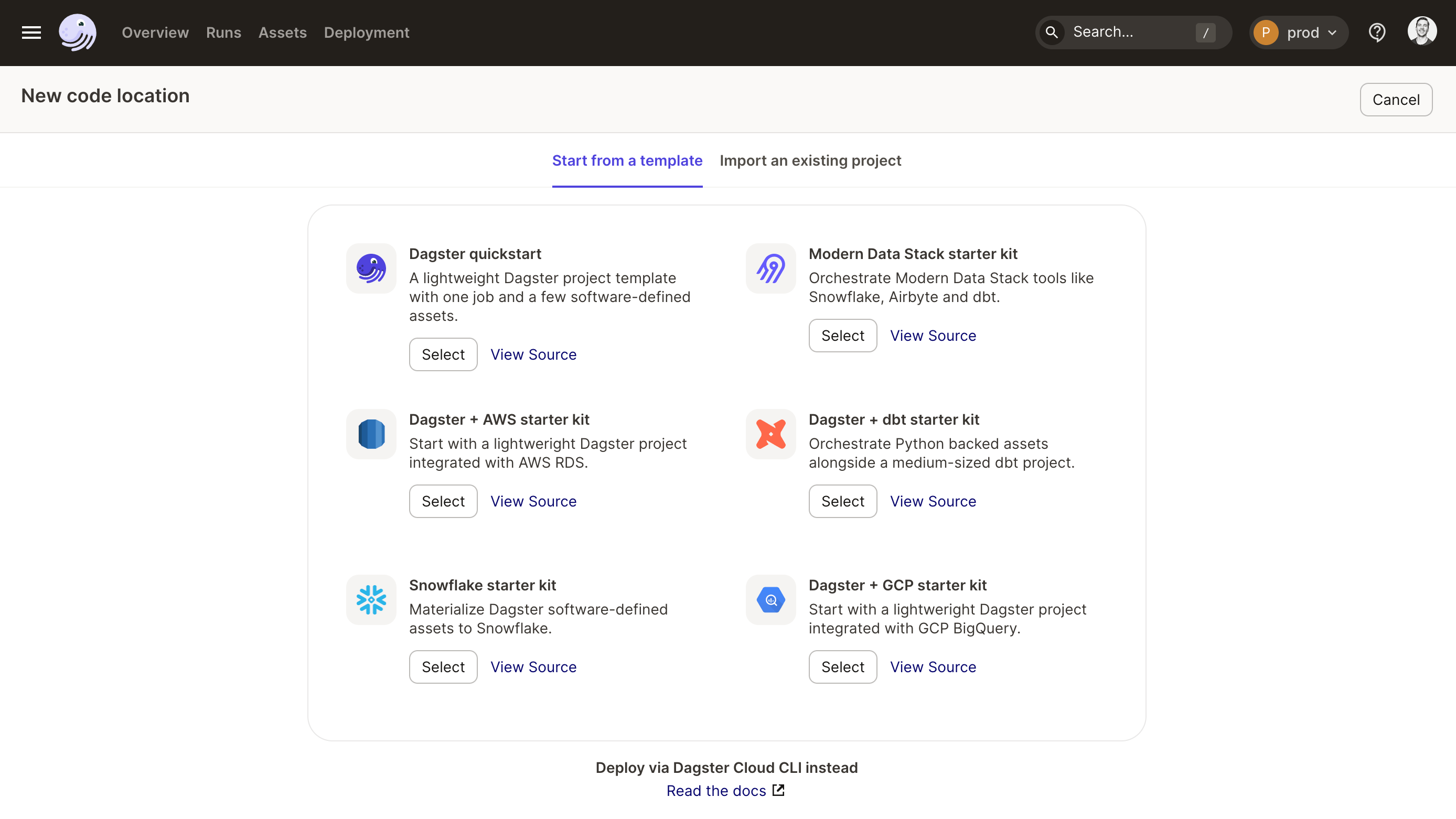
In Dagster Cloud you can now add a new Code Location to your Deployment using one of the new starter templates right from the UI. Creating a new Dagster project is as simple as selecting a template, connecting to Github, and clicking “Deploy”. You can also manage and set environment variables right from the Deployment page too.
Asset Graph
The Asset Graph has been redesigned to make better use of color to communicate asset health. New status indicators make it easy to spot missing and stale assets (even on large graphs!) and the UI updates in real-time as displayed assets are materialized.
Your browser does not support the video tag. Dagit - the Dagster interface - showing the redesigned Asset Graph.
Asset Details page
The Asset Details page has been redesigned and features a new side-by-side UI that makes it easier to inspect event metadata. A color-coded timeline on the partitions view allows you to drag-select a time range and inspect the metadata and status quickly. The new view also supports assets that have been partitioned across multiple dimensions.

Integrations updates

dagster-dbt now supports generating software-defined assets from your dbt Cloud jobs.

dagster-airbyte and dagster-fivetran now support automatically generating assets from your ETL connections using `load_assets_from_airbyte_instance` and `load_assets_from_fivetran_instance`.

New dagster-duckdb >integration: build_duckdb_io_manager >allows you to build an I/O manager that stores and loads Pandas and PySpark DataFrames in DuckDB.
A final word...
For more details on this release, check out the changelog, release notes, and migration guide.
A special thanks to everyone in the community who contributed to this release:

Adam Bloom

Akan72

Binhnefits

C0DK

Daniel Gafni

Nick Vazz

ReidAb

Roeij

zyd14





.jpg)
.png)


.png)

