




Navigate complex data environments more effectively, and ensure that valuable data assets are easily discoverable and usable.
The rate at which we generate data far outpaces our ability to effectively index it. As a result, data indexing technology is constantly playing catch-up, evolving in response to our growing need to discover and share information efficiently.
Data practitioners, especially those using modern tools, often find themselves limited by the current technologies' inability to fully leverage available data. This is where data catalogs come into play.
The frustration intensifies when crucial information is:
- Scattered across different tools
- Out of sync
- Hidden beneath multiple layers of abstraction

Maintaining data assets at scale isn’t just about volume. It’s about context, lineage, and reliability.
Without a clear and trusted view of your data in your organization, you’re often left with:
- Time wasted tracking down datasets, reaching out to colleagues, or verifying stale metadata.
- Duplicated work because different teams don’t know that a dataset or analysis already exists
- Uncertainty about data reliability leads to hesitancy, delayed decisions, and potentially wrong decisions—assuming any decision is made at all
- A fragmented toolset that forces you to switch between multiple platforms that don’t play well with each other
That’s where built-in and operational data catalogs come in.
A catalog directly integrated into the orchestration platform gives data platform engineers a serious advantage. Instead of relying on yet another standalone tool, they can get real-time and reliable views of all of their production data assets with a built-in catalog. This would give data platform teams and pipeline builders the operational context they need without the burden of tool switching.
What is a Data Catalog?
A data catalog is the home base for your data platform. Think of it like a guidebook or map for your organization’s data. It gives you a searchable and centralized view of your data assets, putting metadata, definitions, and lineage at your fingertips and directly within your orchestration environment. From it, you can understand your data at the granular level (what your data means, where it came from, and how it can be used) while also being able to instantly access and manage said data however you need to maximize reliability and accuracy.
For data platform engineers, this means:
- Quickly searching and locating datasets environment-wide without leaving the orchestration tool
- Easily accessing definitions, transformations, and lineage with real-time metadata so that you’re always working with trusted and updated information
- Reducing tool fatigue by keeping everything in one place, removing the need to jump between different platforms for operational data management
Why Data Platform Engineers Need a Built-In Catalog
Save Time and Focus on Engineering
Every minute spent searching for datasets or verifying data accuracy is time not spent building scalable pipelines. A built-in catalog gives you immediate access to trusted metadata so that you can focus on what matters most—delivering value through data engineering.
With a built-in catalog, the orchestration layer becomes your single source of truth, giving you reliable information at a moment’s notice.
Get Rid of Tool Fatigue
Managing a complex toolchain is tedious, especially when the tools don't work well together. Pretty much every solution needs additional configuration to fulfill your business requirements. That added overhead taxes engineers and takes them away from their core function. Embedding a catalog directly within your orchestration platform streamlines operations, reducing the need for a separate catalog for operational use cases.
The more reliable your metadata is, the less reliant you become on third-party tools, deferring the need for additional catalog tools until your organization grows into them.
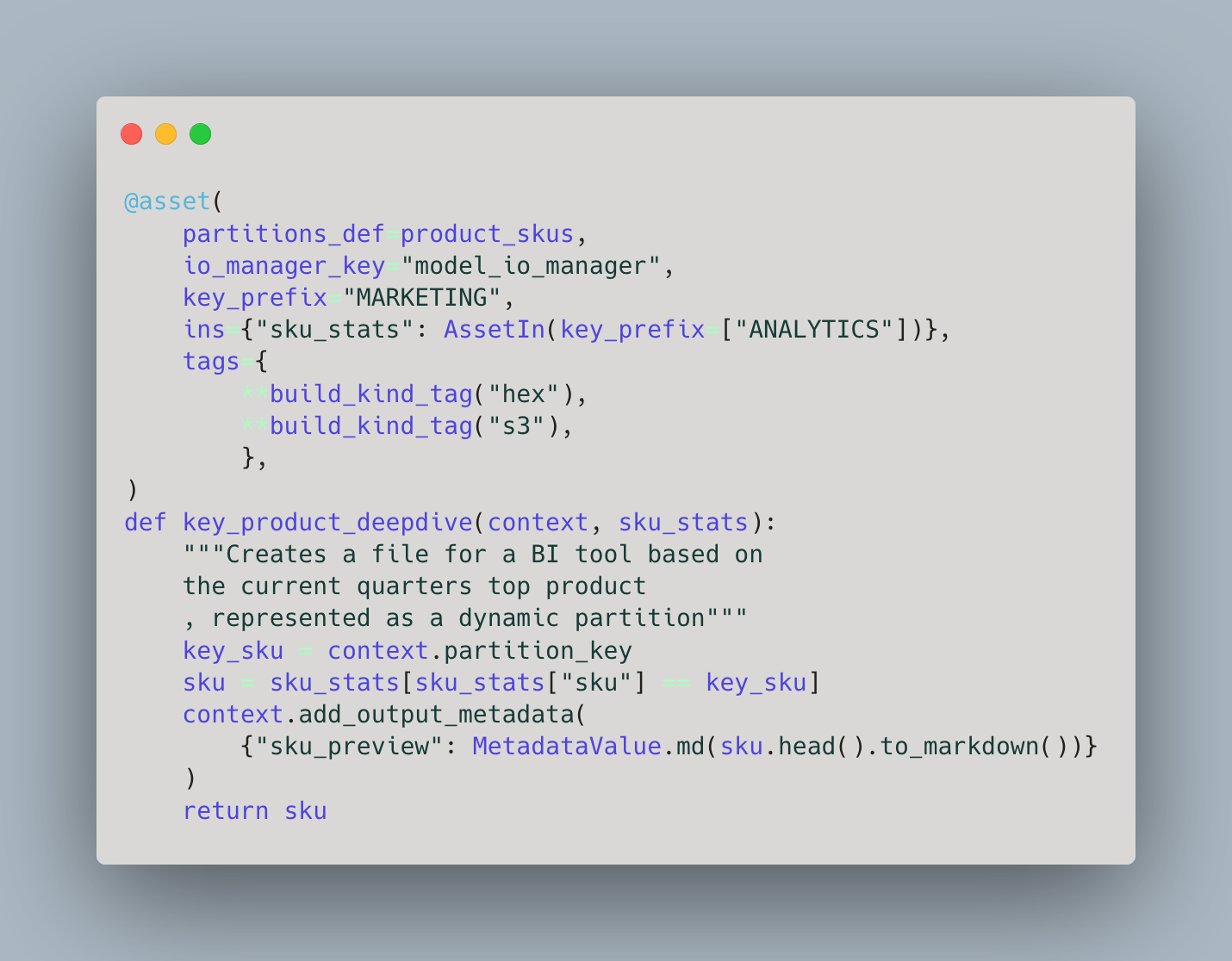
Software Defined Assets as the Source of Truth
The metadata your catalog contains ultimately determines its effectiveness. Using Software-defined Assets as the basis for your catalog ensures that the content of your catalog is always up to date and reflects the intention of the data platform engineer.
Using code as a source of truth is a key way to bring software engineering best practices to data platform engineers:
- Versioned and Collaborative
- Code is versioned so it’s simple to identify breaking changes
- Collaborate with pull requests to see implementation details.
- Supports Automation
- Automated Testing
- Continuous integrations/Continuous Deployment
- Flexibility
- Avoids vendor lock-in since you own the code
- Highly Customized to meet your requirements
Avoid Redundant Work
Stop wasting time recreating datasets and duplicating analyses. A built-in catalog would ensure that all your teams have visibility into the existing datasets and analyses. That means saved time, optimized resource use, and less frustration.
With a centralized catalog, teams can collaborate more effectively while reducing their blind spots and ensuring that no efforts are wasted.
Onboard New Team Members Faster
New data engineers can ramp up quickly through a catalog's clear and comprehensive data overviews.
With full visibility into the definitions, transformations, and usage of datasets, your new hires can start contributing faster, minimizing the learning curve and eliminating reliance on outdated documentation.
Foster Collaboration and Break Silos
It’s easy as a data platform engineer to find yourself working in a silo where different teams use disconnected tools and datasets. The problem with this is that it often leads to miscommunications and inefficiency.
A built-in catalog helps break down these silos with a unified view of your data, making sure that everyone—from engineers to analysts—has access to the same reliable data and metadata. A single operational catalog also means that teams no longer have to rely on ad-hoc communication or manually shared datasets. Instead, everyone can easily locate, understand, and use the same information, ultimately fostering better collaboration and leveraging your data fully.
Beating Data Fragmentation
Overcoming scattered, unreliable data and building a reliable and streamlined data management process requires a few things.
Make Dagster Your Home Base
Dagster is designed to serve as the home base for data platform engineers and pipeline builders. Our asset-oriented orchestration simplifies data management with a built-in catalog for production data. By giving engineers a single source of truth and view of their data, Dagster removes the need to juggle multiple tools and provides more reliable metadata for operational use cases.
Cataloging Data With Dagster+
Dagster+ offers an enhanced cataloging experience purpose-built for technical teams that need reliable and detailed metadata about their production data assets. For enterprises and data engineers looking for advanced cataloging capabilities, Dagster+ delivers:
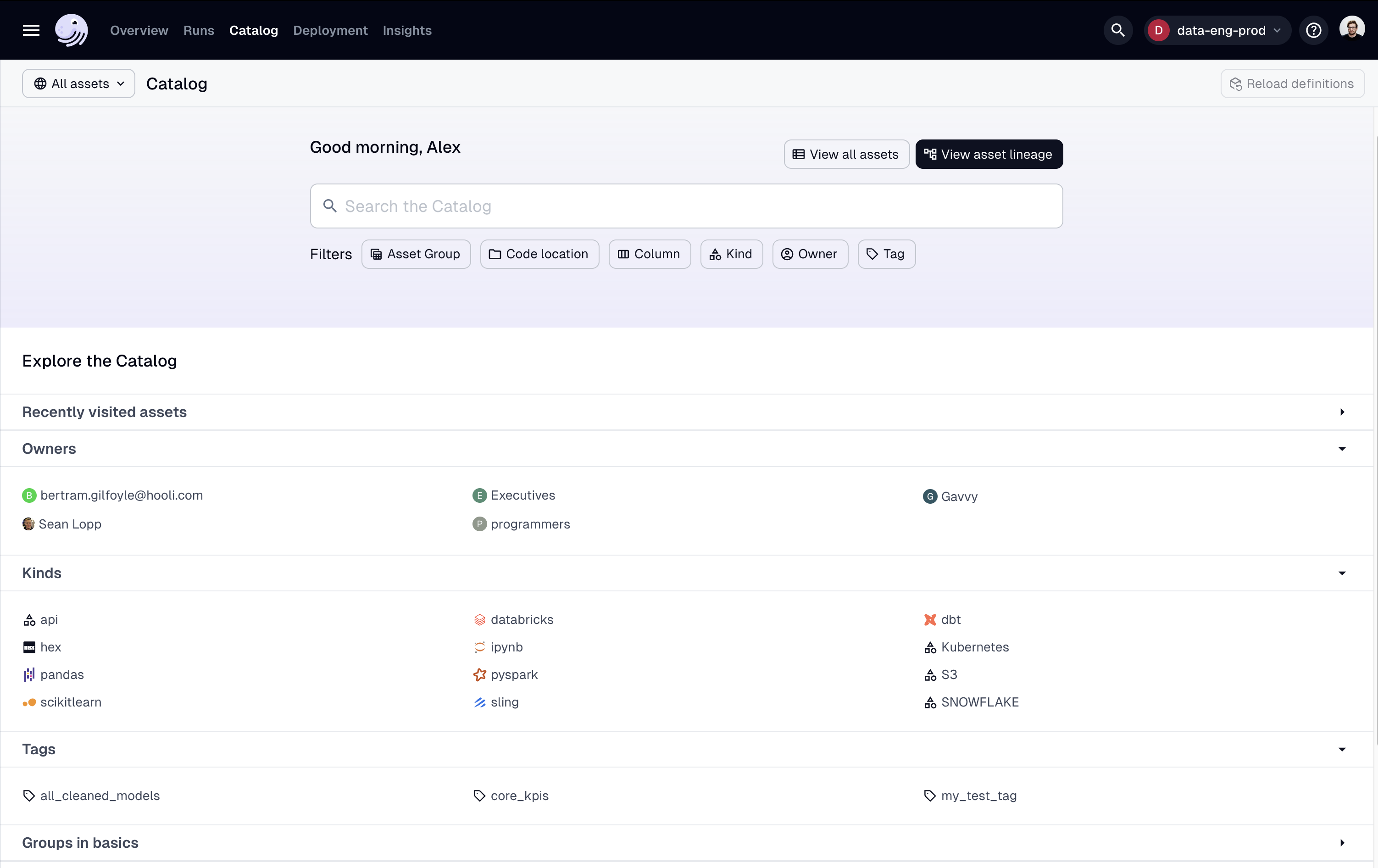
- Data Platform System of Record
- Column-level lineage to track transformations and understand how individual data points are being used
- Holistic view of assets by who owns them, the code location, kind, group, and tags you assign.
- External asset integration brings data from external sources into one view.
- No additional work is required. The catalog is generated from your Software-defined Assets and reflects your intention as a data platform engineer.
- Democratized data access so that every member of your data platform team can access the data they need without unnecessary bottlenecks.
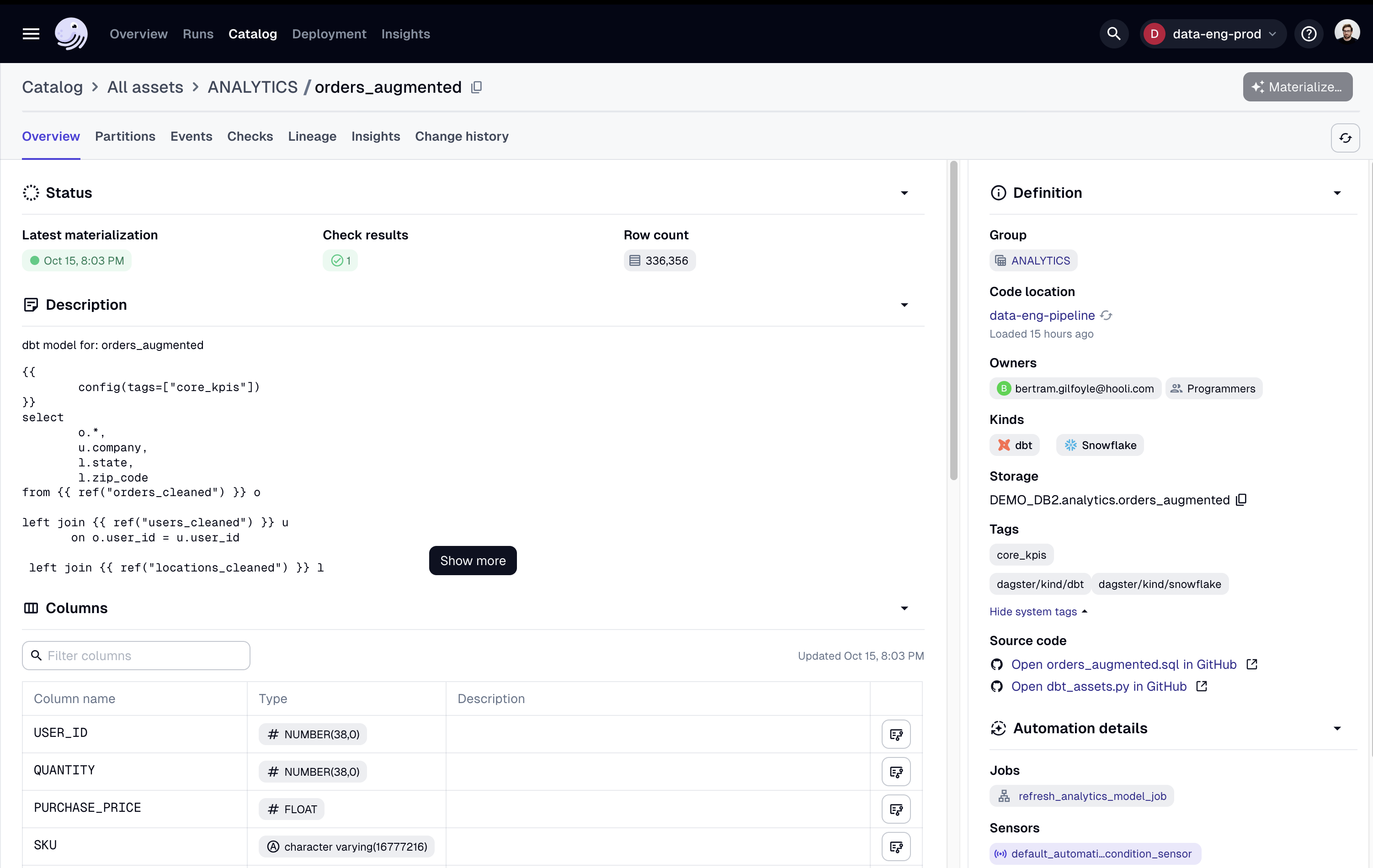
With Dagster+ and your data catalog embedded into your orchestration layer, you get the tools that your data platform teams need to manage data more efficiently and reliably—all in one place.
Conclusion
As data assets and pipelines are complex, managing them becomes increasingly challenging. A reliable data catalog is essential for understanding and leveraging your data effectively.Dagster simplifies this process by integrating data catalog functionality directly into its platform, eliminating the need for standalone tools. This integration offers several benefits:
- Real-time accuracy: Your team can rely on up-to-date data information without additional engineering effort.
- Streamlined management: As your data environment expands, Dagster+ helps you efficiently manage your growing data asset library.
- Enhanced visibility: The built-in catalog improves data discovery and understanding across your entire data platform.
- Reduced overhead: Dagster eliminates the need to maintain separate catalog tools by consolidating functionality. By providing these features, Dagster enables teams to navigate complex data environments more effectively, ensuring that valuable data assets are easily discoverable and usable.
Go to our platform page for more info or start a free trial of Dagster+ to put together your first project.





.jpg)
.png)



.png)

