




dbt docs slow? See how we dropped page load time and memory usage for a large dbt project by 20x using React Server Components.
Over half of Dagster users use dbt™. For this reason, we’ve recently invested heavily in our integration. A huge part of this investment is talking to our customers and understanding their pain points.
One thing we heard over and over again was that dbt struggled with large-scale projects. In particular, dbt docs was very slow.
With a few days of work, we were able to drop the page load time for a large open-source dbt project (GitLab’s data platform) from over 4.5s to under 220ms, a 20x performance improvement. We also dropped memory usage from 350mb to 16mb, another 20x improvement. We used React Server Components, a relatively new and controversial technology, to get these results. While we got a great end result, it wasn’t entirely smooth sailing. Read on for the gory details.
Want to skip right to the code? It’s all on GitHub
Setting the table: what is dbt docs?
dbt (data build tool) is an open source command line tool that enables data analysts and engineers to transform data in their warehouses more effectively. dbt docs is a feature of dbt that allows users to generate documentation for their dbt projects. This documentation provides information about the models, sources, and macros that are present in the project, as well as their relationships and dependencies.
dbt docs can be incredibly valuable to dbt developers. It can help them to better understand the relationships between different components in their data pipelines, and can make it easier to identify potential issues or areas for improvement. Additionally, dbt docs can be used to generate documentation that is more easily shared with other members of a team or organization, making it easier for everyone to stay on the same page when it comes to data modeling and transformation.
The performance problems with dbt docs
Let’s take a look at a real-world, publicly available large dbt project. GitLab famously develops in the open, and their data platform is no different. Let’s load up their dbt docs into Chrome’s Lighthouse auditing tool to assess where we stand with respect to performance.
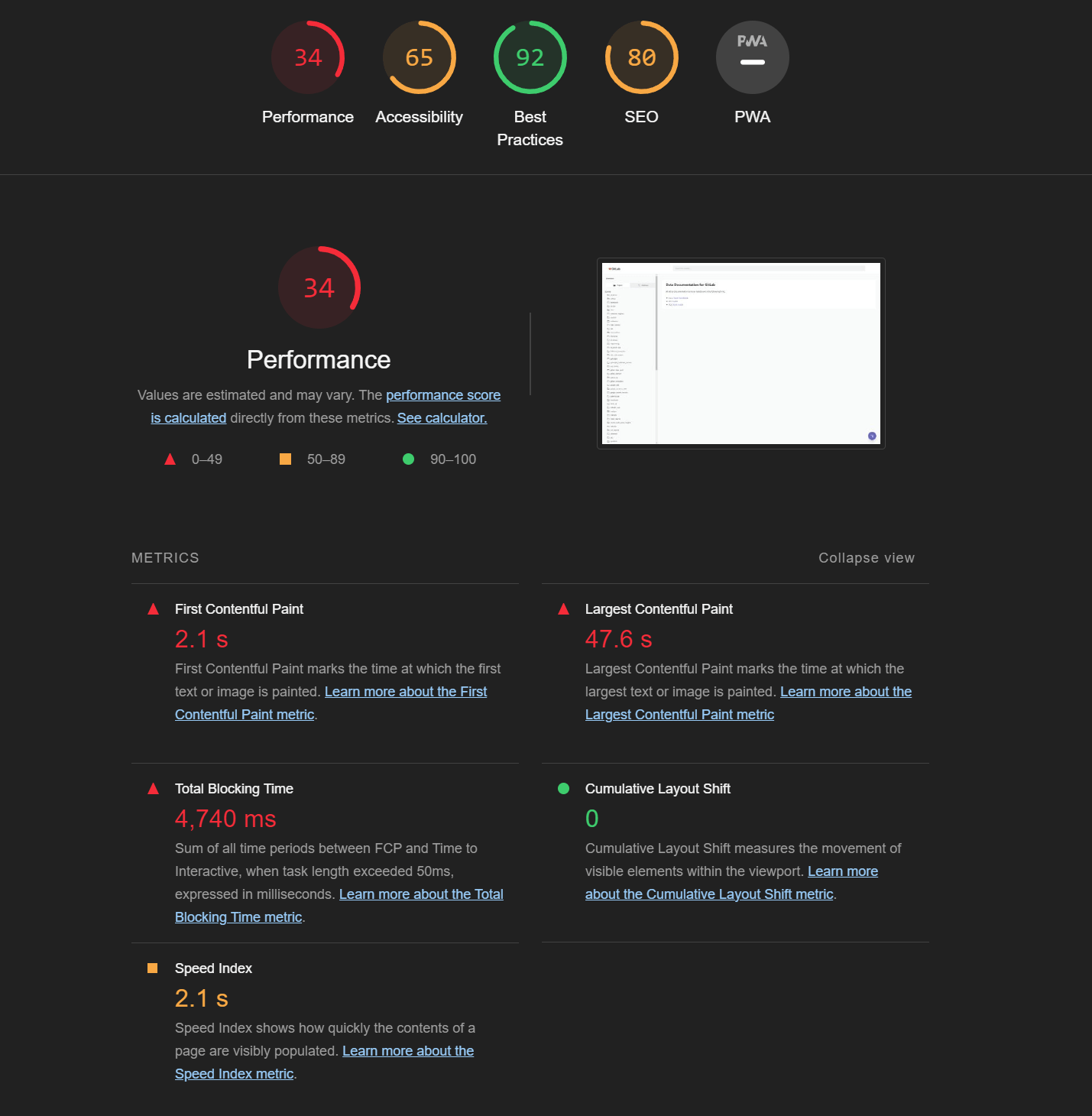
If we drill down we can see that this page downloads a mammoth 58mb JSON payload and parses it on the main thread before rendering. The biggest headline is the “largest contentful paint” number. This means that the docs took ~48s to load on my MacBook Pro M1 and fiber optic broadband connection!
How dbt docs was implemented
When we dug into the implementation of dbt docs, we identified a number of issues:
- They are built using Angular.js 1.0, which was released in 2010 and reached end of life over a year ago.
- They are rendered fully client-side, making them difficult for internal search crawlers to index.
- They require downloading the entire dbt
manifest.jsonandcatalog.jsonfiles, which contain all metadata and source code for the project. Each of these files can easily be dozens of megabytes, all of which must be downloaded and parsed serially before docs can be rendered.
While this architecture may work for small dbt projects, larger, production projects tended to hit these bottlenecks quickly.
Solution constraints
Our ideal solution would have the following constraints:
- This project should take less than a week. This likely means reusing as much existing CSS and JS as possible.
- Performance must be improved by an order of magnitude.
- It must support all commonly used features of the dbt docs.
- It must compile down to a static website just like dbt docs. It cannot require any dynamic behavior on the server.
The plan to fix it
Our plan to fix this problem was simple. We’ll generate static HTML pages instead of using client rendering. We’re a React shop already, so we decided to port the app from Angular to Next.js, a React framework, while reusing as much of the existing CSS and JS as possible. Once this was done, we could use Server Components with Next.js’s static export feature to create a static site. Simple.
However, the real world is not that simple. When we took a look at the actual page functionality, we had to make some trade-offs.
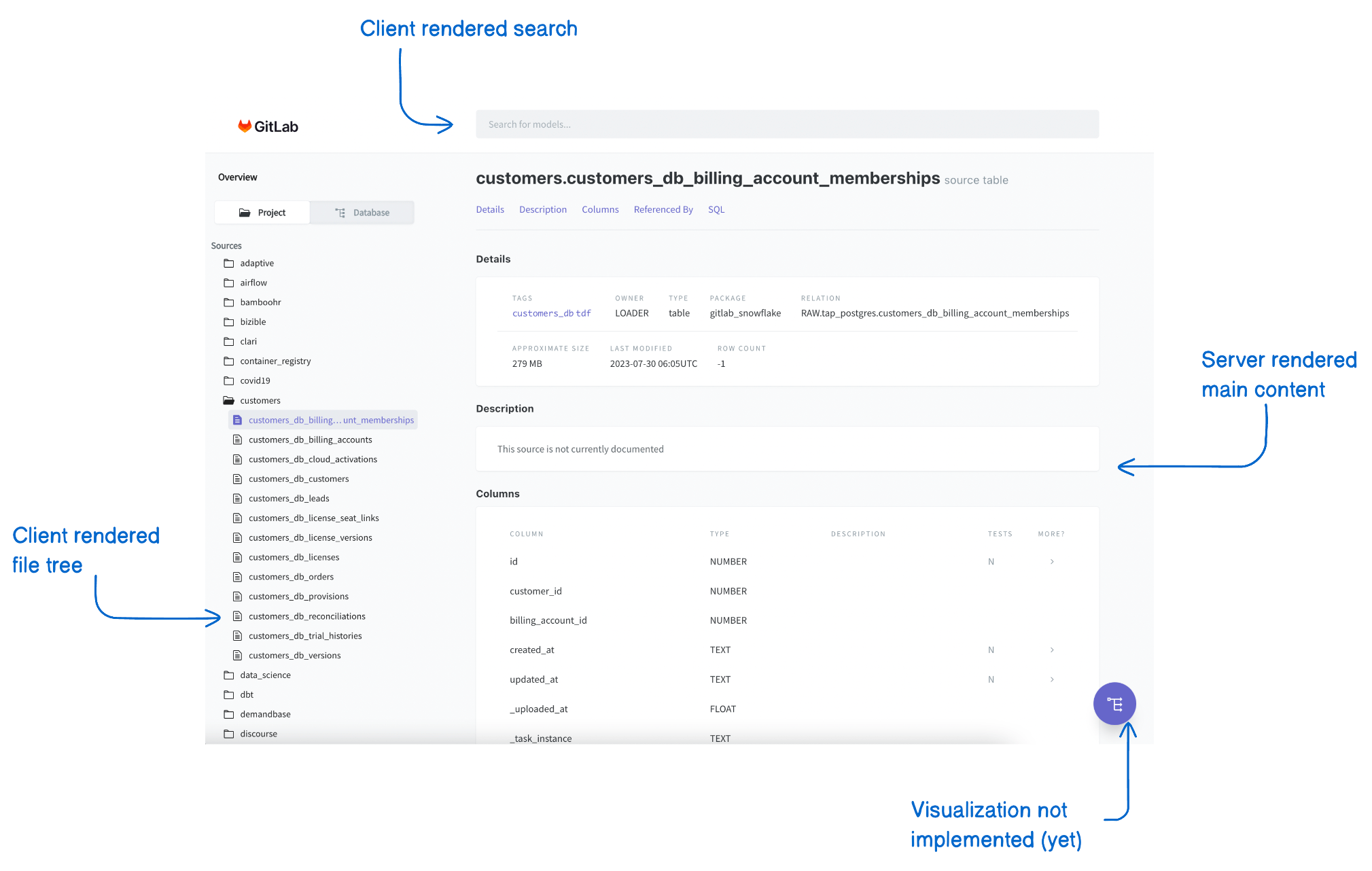
- The main content would be fully server rendered with React Server Components.
- The file tree was interactive so it had to be rendered client-side. Unfortunately, this meant that we had to download a big JSON blob containing the project structure.
dbt docsneeds to work without a server, so we needed to implement search fully client-side, which also necessitated downloading a big JSON blob containing the search index.- There was a visualization of the lineage graph that crashed on large projects. We decided to avoid solving that problem for now.
Why React Server Components?
With React Server Components, we can use React to generate static HTML that does not need to be hydrated. That is, we don't actually download any of the React needed to hydrate the server components. With traditional React server-side rendering you would still need to download the React components for the purposes of hydration.
Porting the main content
First, we created a new Next.js 13 project using TypeScript. This was as simple as running npx create-next-app@latest.
After that, we enabled Next.js’s new App Router feature, which gave us access to React Server Components. From there, it was a fairly straightforward process:
- Copy/paste some HTML from the Angular template into a React component.
- Clean up the HTML to make it valid JSX (adding closing tags, renaming
classtoclassName, etc). - Port the Angular event handlers like
ng-clickto React’s version (onClick).
This was a lot of manual work, but we had a basic port of this working in about a day. What was great about this was that we just wrote React the way we normally would. The one exception was our page.jsx App Router route. We used React Server Components to leverage Node.js’s built-in fs/promises module to read the large catalog.json and manifest.json files server-side, so no large JSON payloads needed to be transferred to be parsed by the client.
This immediately resulted in a huge performance gain. We had replicated a major chunk of the dbt docs functionality in about a day, and we already had a Lighthouse score of 100!
One Next.js gotcha: don’t load large JSON files with import().
One mistake we made early on was using import() to load the large catalog.json and manifest.json files. While Next.js does support JSON imports, we found that loading these files via import() caused major performance issues with Next.js. When we switched to using fs/promises and using JSON.parse() all of these performance issues went away.
Implementing the file tree
Up next, we had to implement a collapsible file explorer along the left hand side of the docs. Because the user can toggle which folder is open, we need to use React’s state feature for this component. And since Server Components can’t use React state, we must implement this as a client component.
Implementing the file tree as a client component introduced an additional performance challenge. Because the user can now toggle which folder is active, the client needs to know the entire file tree in the project. This information is stored inside of the manifest.json file, which, as we know, can be dozens of megabytes.
Rather than ship the entire manifest.json to the client, we opted for an alternative.
- We created a
GETroute in Next.js which returned a JSON object describing the file tree. This is about 30x smaller than the entiremanifest.jsonfile and can be loaded relatively quickly (when gzipped it’s 93kb) - We used the SWR library to load this endpoint asynchronously, so it didn’t block the page.
This structure should be familiar to anyone who has worked on single-page applications before. However, Next.js will generate static files for all GET endpoints as part of its static export feature. This means we’re able to develop in the style of a traditional web app while getting the benefits of a static site.
Implementing search
dbt docs includes a powerful search feature that searches over the names, descriptions, columns, and source code of every database table or view in the project. In a traditional web app, we’d implement the search server-side, either with an API route or using a Server Component. However, because we want the docs to work as a simple static site, we cannot leverage any dynamic server-side logic and must do the search entirely client side.
The first thing we did was reuse the same trick we used for the left nav. Rather than ship down the entire manifest.json file, we created a GET endpoint containing only the searchable data and lazily fetched it with SWR when the search box was focused.
We also made the call to remove the ability to search source code. This would have substantially increased the payload size, and after talking to users we realized that searching source code was a very rarely used feature. Even without the source code, the search index for our example project is quite big (8mb of JSON, 1.4mb gzipped).
Finally, we had to deal with the case of rendering a large number of search results. The original search result page would render a row for every search result - even if there were thousands of matches. This could easily overwhelm the browser for large result sets. We changed this to use a virtual scroller.
Building a static site
The last step was to generate a static site from our Next.js project. In theory, this is quite simple: just enable static exports, add a generateStaticParams() method to your pages and run next build. While this initially appeared to “just work” (!), it actually introduced a few problems.
Problem 1: that pesky .html extension
When building an app with Next.js, you’re usually deploying to a Node.js backend rather than static files. For that reason, your URLs usually don’t have a .html extension. When we migrated to static exports, however, we were generating a static .html file per page and had to add that extension. This meant that all of the links on our app were broken since they were missing the .html extension.
Fortunately, Next.js has a solution: simply set the trailingSlash parameter in your config. This will create one directory per page with an index.html in each, eliminating the requirement to add the extension to every link.
Problem 2: trailingSlash is confusing, or buggy, or both
One advantage of React Server Components and Next.js is that you can get the fast initial page load characteristic of server rendered apps, while also having fast page transitions that are characteristic of client-rendered apps. However, when we built our static site with trailingSlash enabled, we noticed that our client-side route transitions stopped working, and our app fell back to full-page reloads. Not only was this slower, it also led to a jarring user experience where, for example, the file tree’s state was reset on every click rather than staying persistent as the user would expect.
When we opened the web inspector, we found that the client-side router was requesting files as if trailingSlash was not enabled. This led to a 404 error which forced the full page reload. Once we tracked this down, we made a quick patch to Next.js using the incredibly useful and underrated patch-package package:
Now, our app was running nice and snappy!
styfle {' '} found an alternative approach to patching next.js that avoids the{' '} underlying issue (trailing slashes don't work correctly for paths that contain a ".") and graciously{' '} implemented it for us.
The results
We've uploaded the original version to S3, as well as the new version built with React Server Components so you can compare for yourself.
We compared results with gzip enabled and disabled. The benchmark data below only refers to gzip-enabled tests, as this is more favorable to the existing implementation. However, one should keep in mind that static sites are often deployed to services like S3, where it can be easy to forget to enable gzip compression.
Lighthouse scores
Here’s the Lighthouse score for the original dbt docs project when run in our test environment. Note the improvement from the original Lighthouse score due to gzip compression being enabled in our test environment and not in the deployed documentation:

As you can see, many megabytes of gzipped JSON were downloaded, tons of DOM nodes were created, and it burned over 4 seconds of CPU simply rendering the page!
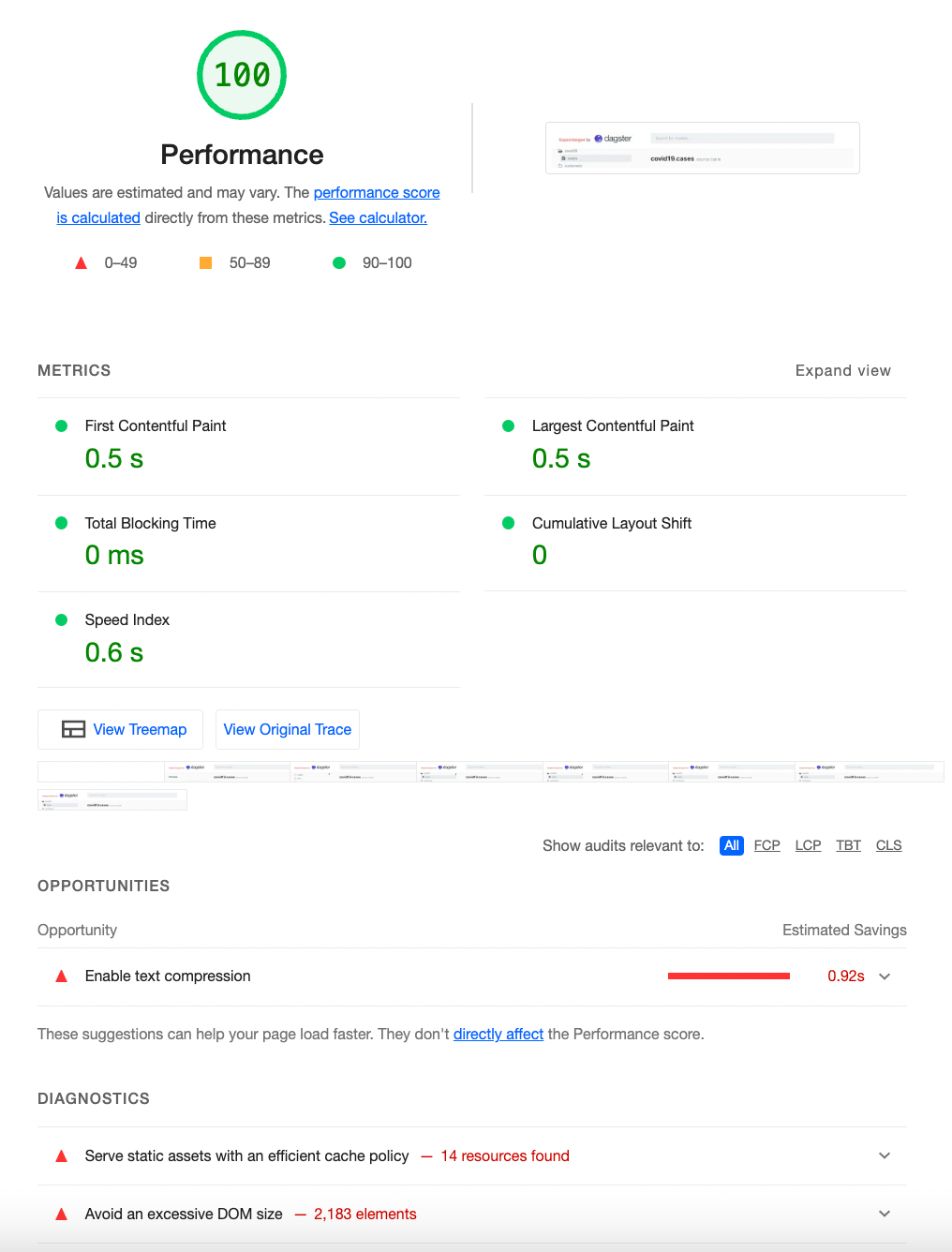
Our version with React Server Components is… much better.
Profiler
Let’s dig into the profiler to get an even better idea as to the user experience differences between the two.
Here’s the profiler trace of the original project’s initial page load:
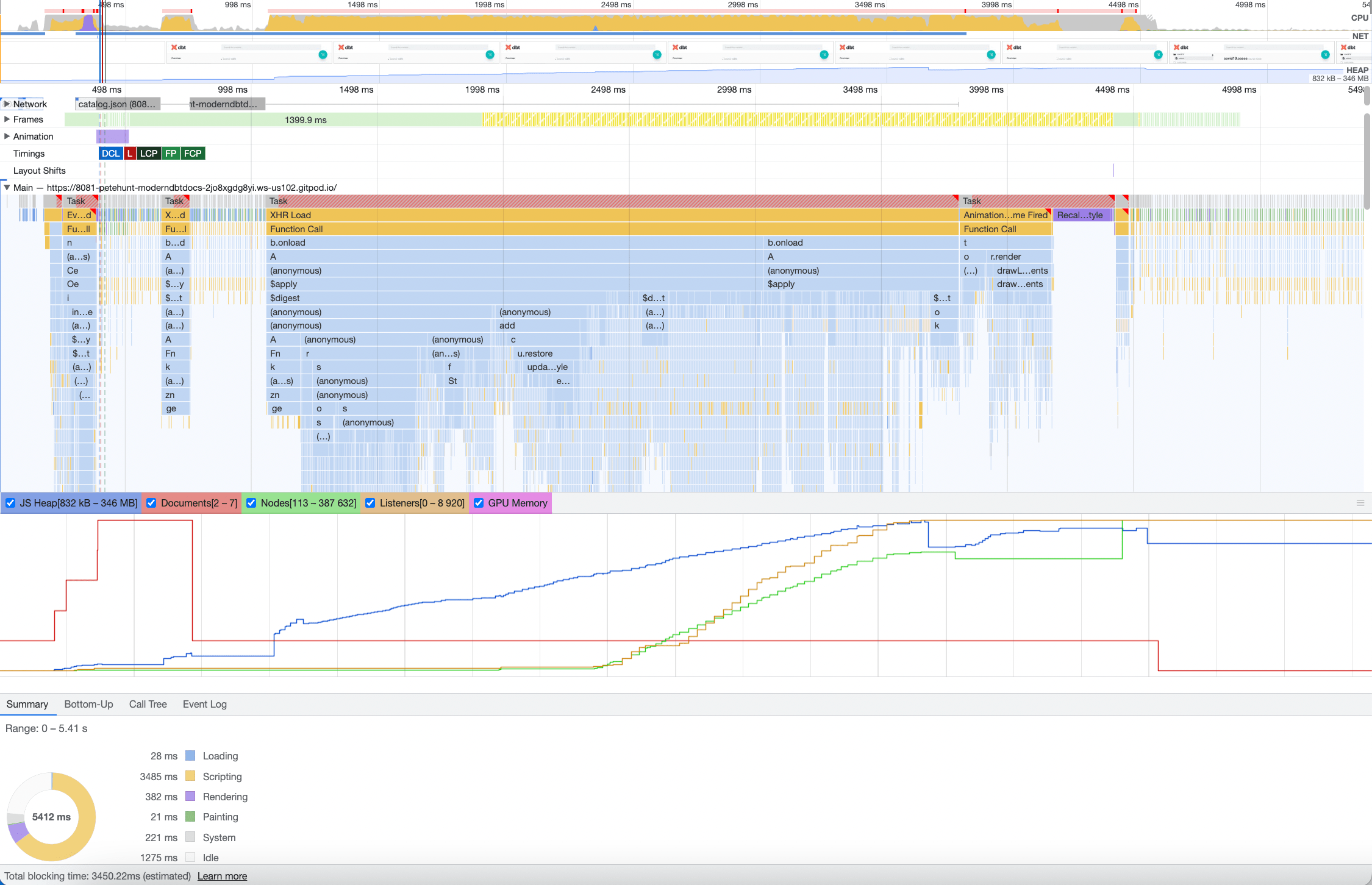
If you take a look at the timeline, you can see that the docs are only usable after about 4.5s. Additionally, there is about 3.5s of “blocking time”, which means that the browser is effectively locked up and unresponsive. Finally, there is enormous time spent running JS, which burns valuable CPU cycles.
Let’s take a look at the React Server Components version:
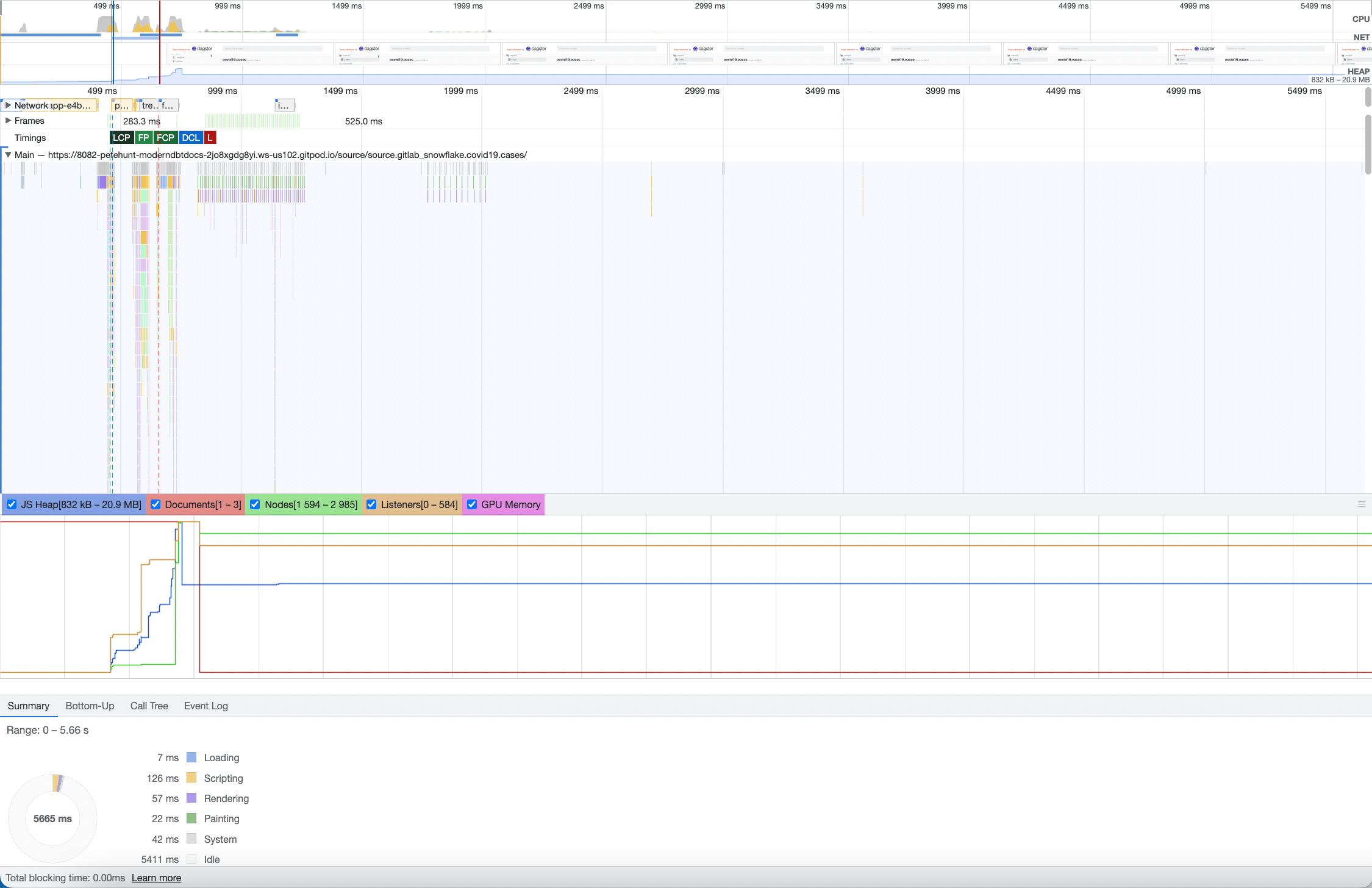
The docs are visible in under half a second, which is 10x faster than the original version.Additionally, there’s no blocking time, and very little CPU burned on scripting.
When we ran this test with gzip disabled (as is the case in most deployments of dbt docs we see), the difference was much larger: about 20x.
Memory utilization
Perhaps most striking was the difference in memory utilization. In order to measure this, we waited for a documentation page to load entirely, then opened up the heap profiler, hit the "force garbage collection" button, and took a heap snapshot.

The original implementation of dbt docs required approximately 350mb of memory per tab! This is perhaps the biggest scalability issue we found. Developers tend to have multiple tabs open to their docs, and if each tab is consuming 350mb of memory, this can quickly add up and evict other processes or browser tabs, making your entire system feel sluggish. Additionally, we found that the dbt docs tended to crash Safari on our iPhones during testing; this is likely due to out-of-memory errors (but we didn't dig in on this issue).
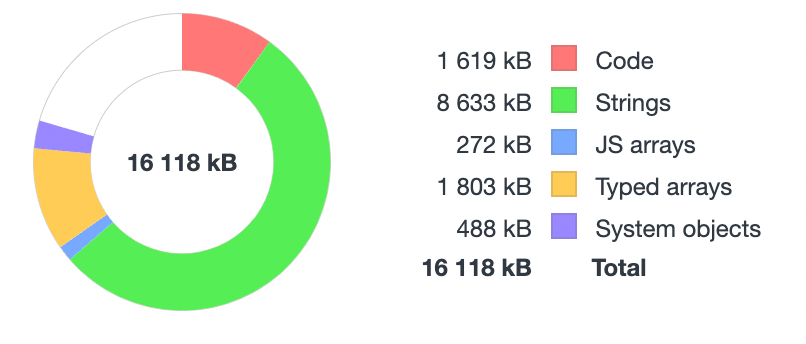
Our implementation, on the other hand, consumed approximately 16mb of memory. Much more reasonable!
Build times
This is one area where our solution is inferior to the existing dbt docs. In the existing system, there was essentially no build step: just copy your JSON files into the right spot and you're done. In the React Server Components version, we generated almost 20,000 files, totalling over 3gb uncompressed (about 600mb compressed). The next build process to generate the static export also took a few minutes.
We believe that this is the right trade-off. Most shops will run the build step once on a CI server, where it will be unlikely to directly affect an engineer's development workflow. Additionally, while we were developing the docs, we used next dev which generated pages on-demand. This meant that we could iterate on the app extremely quickly without waiting for tens of thousands of files to be generated.
Challenges with React Server Components / Next.js
Just to recap, while we ended up with great results, there are still a few outstanding issues.
- We had to patch Next.js to fix a bug. Hopefully this gets fixed soon.
- Our static site must be served from the root of the domain, as all links are hardcoded to absolute paths. From what we can tell, this is a limitation of Next.js.
- It would have been nice to be able to
import()the JSON files directly rather than manually load and parse them with Node.js’sfs/promisesmodule. It wasn’t clear that this was the source of performance issues initially which resulted in some wasted time. - From time to time we get stack traces into transpiled JS, making it difficult to track down the sources of errors.
- We explored using intercepted and parallel routes, which are an advanced routing feature of Next.js, but ultimately ended up not using it.
Overall, we were very pleased with the end result. We definitely recommend trying out React Server Components and Next.js 13.
What’s next for dbt docs?
This project is mainly a technical proof of concept at this point. You can try it out on your own project by dropping in your own catalog.json and manifest.json, but it is not production ready yet. We have not implemented the lineage view, and we have not extensively tested with other dbt projects or versions of dbt. Additionally, there are further performance improvements we could make, including preloading the search index and file tree JSON data. Over time we hope to make improvements, and welcome contributions or forks by the community.
dbt™, dbt Labs™, dbt Cloud™ and the dbt™ logo are all trademarks of dbt Labs™. There is no affiliation between Dagster Labs and dbt Labs.





.jpg)
.png)



.png)

