



Abstracting away infrastructure concerns in large-scale computing with conditional multi-cloud processing.
The team at Empirico runs their data platform on Dagster, abstracting away infrastructure concerns from data scientists and enabling large-scale computing through conditional multi-cloud processing.
Empirico is a drug discovery and development company based in San Diego, CA, and Madison, WI. The organization specializes in speeding up the pace of drug discovery using human genetics and data-centric approaches.

To achieve this, Empirico has built an expert team, including data engineers, data scientists, bioinformaticians, and Biologists. To support this work, they also built a world-class Data Infrastructure team.
We caught up with Zachary Romer, Senior Data Infrastructure Engineer at Empirico therapeutics, to discuss how Dagster fits into their architecture. You will find Zach on the < a href="/slack">Dagster Slack as @zach.
Improving drug discovery through human genetics and big data
Our genomes are 99.5% identical but all of us are born with a collection of genetic variants that can impair or enhance the function of genes and impact our health. By combining genetic data with health information from millions of individuals, we can learn about the effects of altered gene function and design drugs to mimic beneficial ones.
"People complain about compute costs, but it's a drop in the bucket compared to having multimillion-dollar labs with PhDs and lab equipment. What are a few EC2 instances at $10K a month compared to that?" - Zach Romer
Exploring large datasets
Most of the scientists on the Empirico team are experts in the science but are also skilled in data science and programming. This said, most of the team does not have expertise in cloud computing or productionizing analytical pipelines. Nor does Empirico want them worrying about where and how their experiments are computed.
This is where Zach’s team comes in. The data infrastructure engineering team makes it easy for scientists to run analyses at scale without worrying about the infrastructure.
In addition, clinical data is heavily regulated, and regulations vary between regions and dataset providers. As a result, Empirico is limited in where data can be stored and processed, meaning that in many cases, technology choices are limited. While Empirico would run part of the workload on Databricks on AWS, some of the restricted hosting environments would not support Databricks, so Empirico had to adopt a multi-compute environments approach.
To accommodate all this, the team built a bespoke interface (a Scala-backend & React-frontend application) which becomes the thin shell over the cloud compute layer. Once the computation is run on the cloud, results are returned to the data science team either as raw files or using data visualization in the app. This approach allows the biostatisticians to focus on requesting the analysis of specific datasets without having to worry about the complexities of where and how the computation occurred.
On the cloud compute layer, Zach and the team build around standard big data tools like Spark, Pandas, Databricks, and NumPy.
Working with heterogeneous data at scale is a challenge, and Empirico is routinely running analyses across trillions of rows.
The analyses are complex and ever-changing. The cloud infrastructure is also complex and changing. The company is keen to use the most performant tools, but these need to be deployed and maintained. The team has to be vigilant for runaway compute costs, especially when experiments are designed by end users who may not appreciate the demand of a particular analysis.
As both the complexity of the experiments and the sophistication of the environment grew, it was clear to Empirico that they had to implement a more powerful data platform that would unlock some new dynamic capabilities.
Moving to modern orchestration
Zach and the team evaluated many orchestration solutions. They prototyped Airflow since it was the de-facto incumbent, but parallelizing across a number of dynamic tasks was challenging.
“You had to do this crazy bending-over-backward exercise of templating files and templating DAGs." says Zach. “There was no way to fan-out without knowing how many tasks would be run before creating the DAG. We knew it would fan out over thousands of tasks to run for a couple of weeks, potentially being restarted multiple times, so we really needed to be able to dynamically generate the fan out."
The team had also considered some tools that are more niche to bioinformatics, but they found these tools to be lagging in terms of functionality and fell short on collaboration features.
After hearing Nick Schrock describe Dagster - both the framework and the philosophy - Zach gave it a go. Within 30 minutes, he could demonstrate it to the team and rapidly prototype it.
The Empirico team found Dagster was the best solution for their needs based on several criteria:
- Python was the lingua franca of the team, and easier to find Python developers
- Tutorials and docs were easy to follow, and the examples “just worked”
- The UI helped them work efficiently
- The notion of Software-defined Assets matched their mental model.
- The framework seemed built to enable software engineering best practices such as dependency injection and upfront input validation
- There was a thriving, responsive, and growing community of users, with direct support from the Dagster Labs team
- Dagster had proven high development velocity, and was highly responsive to the community’s input.
Dagster as a Data Platform
The team is now using Dagster to build a data platform, to handle the projects requested in the web application and to distribute them to the most appropriate compute environment.
This centralizes the calls to the back-end compute environments and gives the data engineering team control over what compute is used, abstracting away the compute layer from the data scientists, and simplifying their workflows using autocompletes in the App. It ensures that the rules around data sovereignty are not accidentally broken. The engineering team can properly optimize for performance and retain observability across the entire platform.
“This has been working really well so far. We are able to introduce new compute providers on the backend without interrupting anybody’s workflows.” says Zach.
Using StepLaunchers, the Empirico team can decide what compute layer each project is going to run on.
Running Big Data over multiple environments
Some genetic datasets are very large, representing trillions of data points. These datasets are also tightly regulated and data sovereignty must be observed at every step of the analysis. This often means analyzing the data on dedicated third party compute environments with zero egress, returning only the analysis conclusions and none of the data itself.
“We may be crunching hundreds of TB resulting in trillions of rows of data being exported, which is not extreme on the Big Data side of things. To ensure experiment reproducibility, our code has to be the same across all of these environments, so we had to figure out how to distribute our compute across many environments, based on a number of conditions such as the data set being analyzed and the technologies supported by each hosting environment.” said Zach.
Enter the StepLauncher abstraction.
To solve this challenge, Zach turned to Dagster's StepLauncher abstraction, which provided hooks for executing an op externally to the Dagster instance.
By creating a custom StepLauncher based on the DatabricksPySparkStepLauncher (as found in the dagster-databricks library), the team was able to transparently move op code to the remote execution environment and trigger it from a Dagster step worker.
The custom StepLauncher can then poll the remotely-executing job for status updates while ingesting both logs and Dagster events streamed back to the Dagster step worker from the remote process. When the remote execution completes, the step also completes, and the Dagster graph execution continues with any subsequent steps.
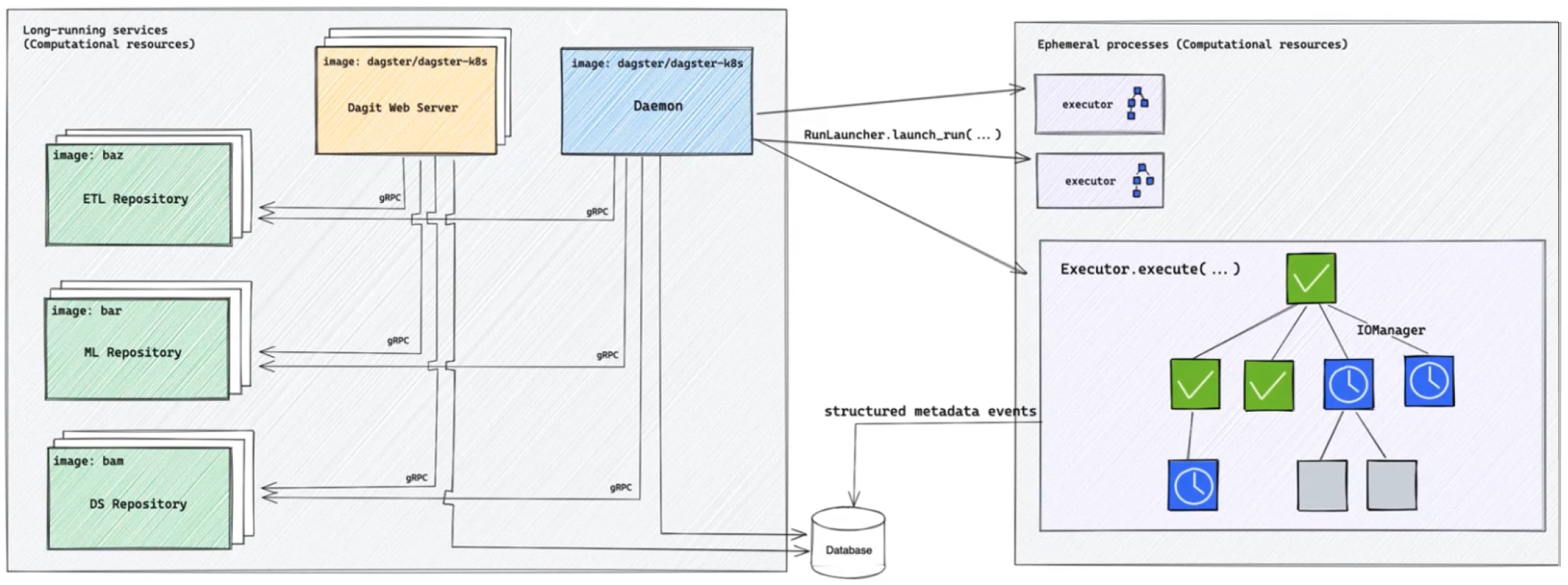
StepLauncher Context
Today the team uses conditional branching paired with StepLaunchers to select the compute environment dynamically. This allows the team to juggle datasets, some of which have to be analyzed on the restricted platform and others that sit on Empirico’s cloud environment. The user selects the data sets and Dagster branches to launch jobs accordingly, combining and returning the results to the user.
Data Engineers can now just worry about writing workflows using Dagster-native code and components. Using branching, the platform determines where to run the compute based on the user’s ask at run time (such as how urgent the analysis or which datasets are required).
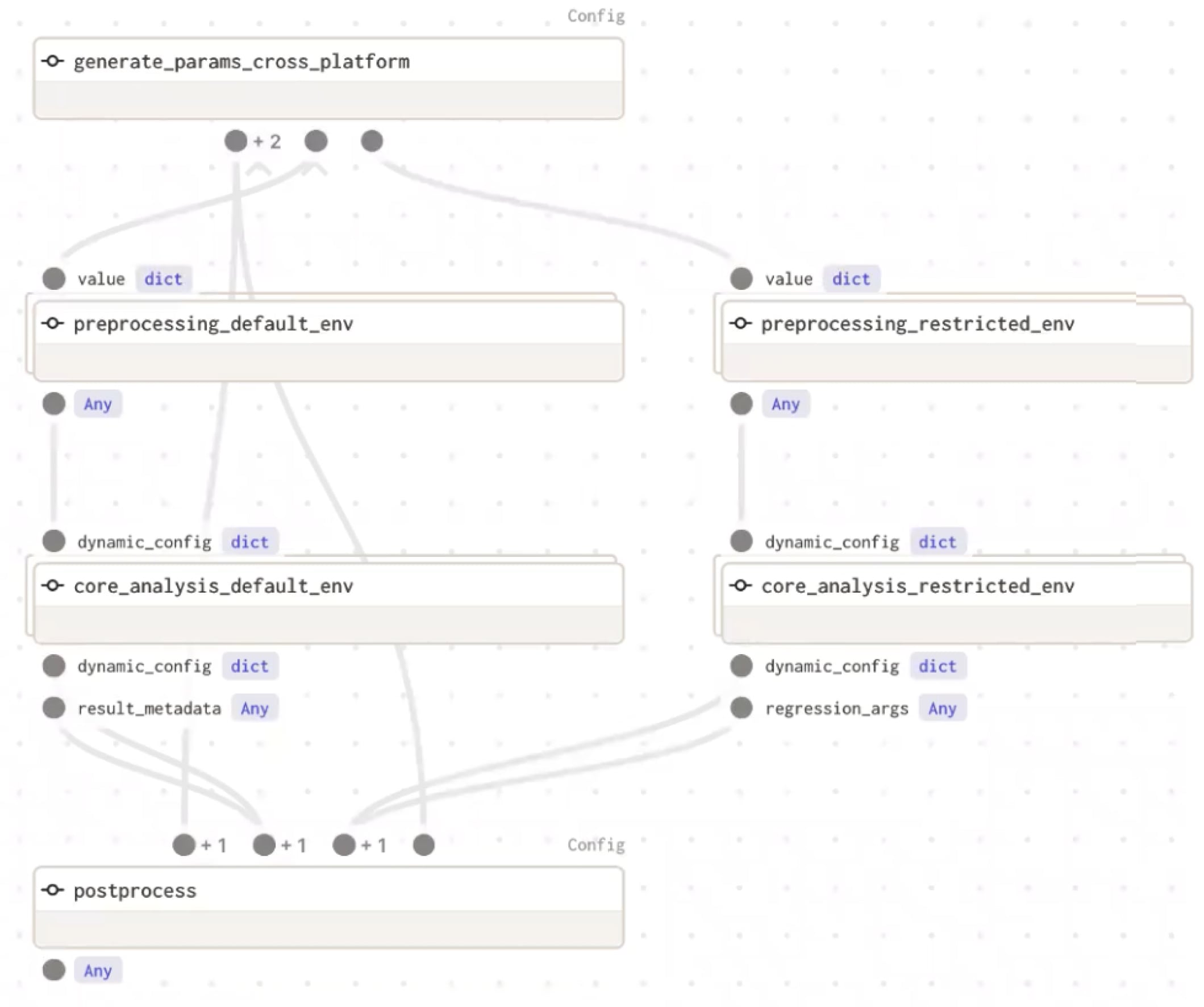
Graph for content-dependent compute platform selection
What’s next at Empirico
Using Dagster as the ‘traffic control center’ for large-scale analyses has transformed how Empirico can support big data analyses.
The team now plans to:
- Complete the transition of legacy assets to Dagster for observability and sharability
- Explore how static partitioning might improve tracking of large-scale analyses
- Use dynamic cluster pools and async remote platform jobs to create a job queue, which would eliminate boot-up time by keeping the cluster ‘warm.’




.jpg)
.png)
.jpg)


.png)

