


Fan-out definition:
"Fan-out" is a tricky term in data engineering as it can be applied to many different scenarios. It originated in the design of electronic circuits in which a "fan-out" design involves a signal being split or merged from one 'upstream' component to many parallel sub-components for effective processing (or in the case of 'fan-in', it's the other way around.)
In data engineering and the design of data pipelines, "Fan-out" generically refers to a scenario where one upstream operation triggers many similar downstream processes. One example could be an overnight data update that triggers dozens of downstream reports.
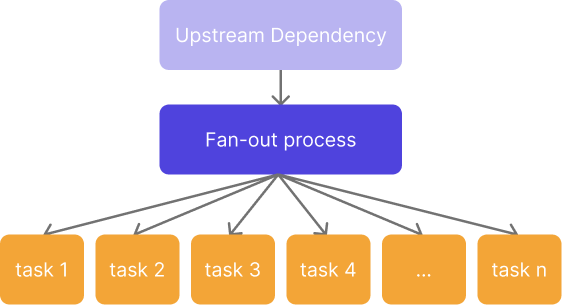
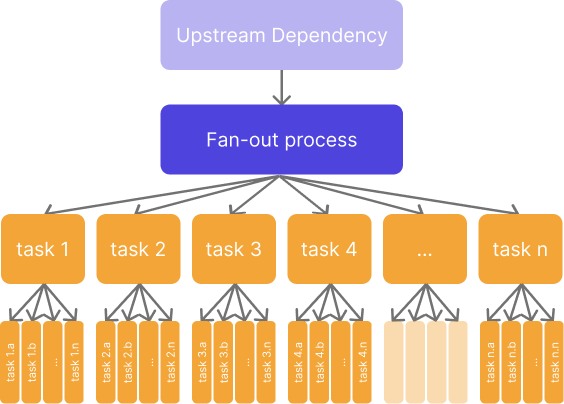
From here, it's easy to picture how a second fan-out step in a pipeline can logarithmically scale the number of tasks required:
In a 'fan-out' scenario, the individual 'branches' of the fan-out process can be referred to as "tasks", "jobs", or "workers", depending on the specific context or the tool being used.
- In data pipelines or data orchestration, they might be referred to as "tasks" or "jobs".
- In the context of parallel computing or distributed systems, these branches might be referred to as "workers" or "processes". A "worker" typically refers to a single entity (like a CPU, thread, or machine in a cluster) that is responsible for executing a piece of work.
Use cases
In data engineering, there are various processes and scenarios where a fan-out approach is often applied to improve efficiency and performance. Here are a few examples:
- Data Ingestion: In high-velocity data ingestion scenarios, data needs to be captured from various sources and processed rapidly. Fan-out can be employed to distribute the incoming data to multiple processing nodes. This is common in real-time analytics or streaming applications where data is captured and processed concurrently.
- Distributed Computing: With big data, it's common to use distributed systems such as Dask or Spark. These systems use a fan-out approach to distribute data across multiple nodes in a cluster for parallel processing. For instance, in the MapReduce programming model, the Map phase is a fan-out operation where input data is divided into chunks and mapped onto various nodes.
- Data Transformation: During ETL (Extract, Transform, Load) operations, transformations may need to be performed on large datasets. Fan-out can be used to distribute the transformations across multiple workers to speed up the process.
- Distributed Databases: In distributed databases, a fan-out approach can be used to distribute queries across multiple nodes. Each node searches a portion of the data, improving the query's speed.
- Message Brokers: In message-oriented middleware or event-driven architectures, a single message published to a topic can be delivered to multiple subscribers, effectively implementing a fan-out pattern. Apache Kafka is an example of such a system.
- Data Replication: Fan-out is often used in data replication strategies, where data from one database is copied and distributed to multiple replica databases for load balancing or redundancy purposes.
Scaling up execution in a fan-out design
While "fan-out" does not explicitly mean scaling up data processing through parallelization or multi-threading, data engineers often imply such a process when using the term. It is easy to see how a pipeline with a 'fan-out' requirement would rapidly require a scale up of computing power, with each sub-task ran in isolation from the others.
With this in mind, we will see definitions of "fan-out" that explicitly refer to concurrent isolated execution:
The term "Fan-out" refers to the design of systems or algorithms to distribute tasks, data, or computations across multiple nodes or processes. This term is often used in reference to the structure of networks, database systems, or distributed computing environments.
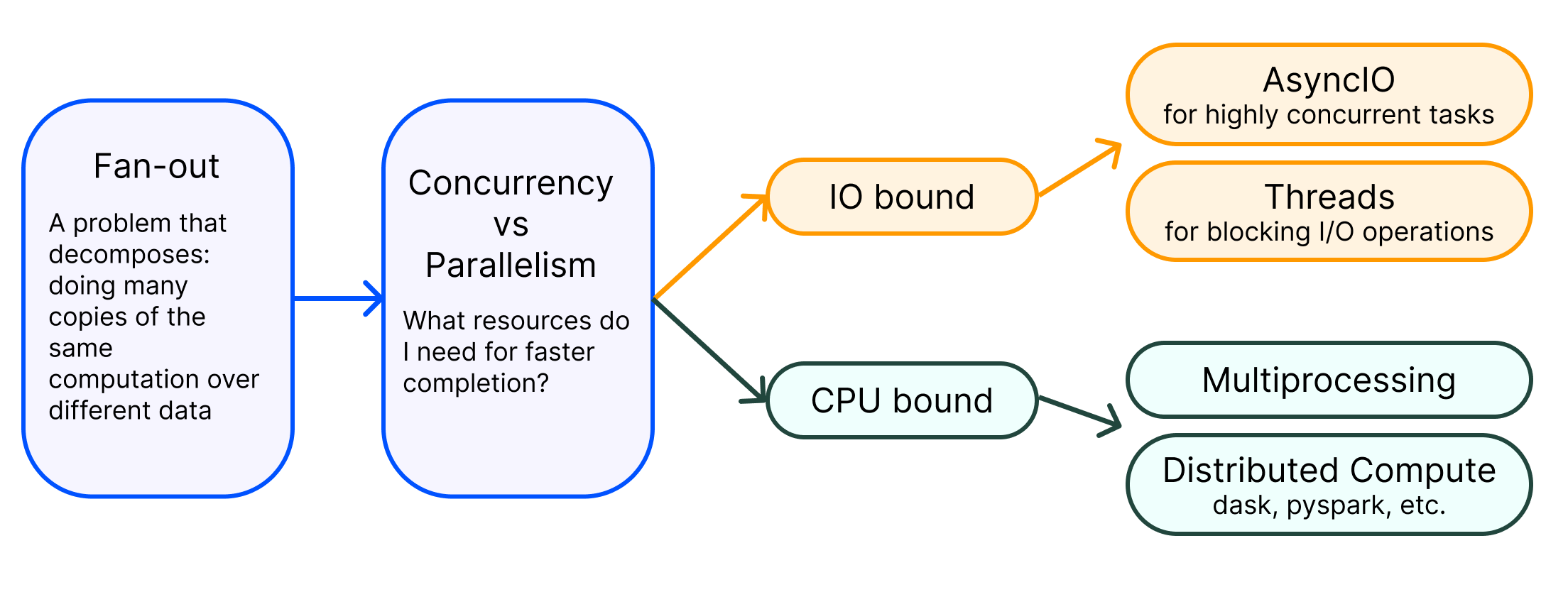
In Python, there are four main techniques to managing processing in a fan-out design: multiprocessing, threading, parallelizing, and AsynchIO. These are both common techniques to achieve concurrent execution and improve performance. However, they differ in how they handle parallelism and utilize system resources.
- Multiprocessing is typically used for tasks that involve heavy data processing, such as large-scale data transformations, computations, or machine learning training on multiple cores.
- Threading is more commonly used for tasks that involve I/O operations, such as reading and writing files, network communication, or interacting with databases.
- Parallelizing refers to the breaking down of data processing tasks into smaller units of work that can be executed concurrently, either on a single machine with multiple processing units or across distributed computing resources.
- AsynchIO is a specific library in Python for asynchronous I/O, built around the coroutines of Python and provides tools to manage them and handle the I/O in an efficient way.
You can find more details on each technique in their respective glossary entries:
Jump to the entry for 'Multiprocess.'
Jump to the entry for 'Threading.'
Jump to the entry for 'Parallelize.'
Jump to the entry for 'AsychIO'.
Note that while these techniques can enhance performance, each may also introduce complexities related to shared data access, synchronization, and potential race conditions. Therefore, proper care should be taken when implementing concurrent solutions using either approach.
Concurrency vs. parallelism
There is a rich conversation in the world of Python programming around concurrency vs. parallelism. Here's a brief explanation of each:
- Concurrency is when multiple tasks are able to start, run, and complete in overlapping time periods. It doesn't necessarily mean that they'll be all executing at the same instant. For example, if you are running a multi-threaded program on a single-core machine, you might have multiple threads of execution, with the processor switching between threads. This is a form of concurrency.
- Parallelism, on the other hand, is where multiple tasks are executing at the same time. It implies a system with multiple processing units (i.e., multicore or multiprocessor). In a parallel system, multiple tasks are being executed simultaneously on different cores or processors.
Concurrency is about dealing with lots of things at once. It's a concept used to structure a solution to solve complex problems that may involve multiple asynchronous tasks. Concurrent programming can make a significant impact on the responsiveness and performance of software where managing multiple simultaneous connections, users, or inputs is essential. It's more about the design of your system, how it's organized.
Parallelism, on the other hand, is about doing lots of things at once to maximize computational speed. It's often used in contexts where a problem can be divided into discrete, independent tasks that can be executed simultaneously (like matrix operations in scientific computing or rendering graphics).
The key is choosing the right approach for the right problem in your pipeline. If you have a lot of IO-bound tasks (like reading and writing to disk or network), then concurrency can be a good way to keep your program responsive and efficient. If you have a lot of CPU-bound tasks (like computations), then parallelism can help make your program faster by utilizing multiple cores or processors.
Note that concurrency and parallelism are not mutually exclusive. Concurrency is about the structure of the software, parallelism is about its execution. Concurrent software may or may not execute in parallel, depending on the runtime conditions and hardware.
Python's Global Interpreter Lock (GIL)
When it comes to Python programming, understanding these two concepts is crucial due to Python's Global Interpreter Lock (GIL), a mechanism used in the CPython interpreter to synchronize access to Python objects, preventing multiple native threads from executing Python bytecodes at once. The GIL is a barrier to multithreaded Python programs achieving true parallelism on a multicore processor.
The consequence of the GIL is that in Python, multithreaded programs don't execute threads truly concurrently on multiple cores; they merely interleave the execution of threads, which is beneficial for I/O-bound programs (waiting for I/O such as disk or network operations) but not for CPU-bound programs (intense computation tasks). This is where multiprocessing comes in, which involves using multiple separate Python interpreter processes, not threads. Because these processes are separate, they can execute on different cores and achieve true parallelism (with the right kind of task).
In Python:- You use threads or AsyncIO for I/O-bound tasks, achieving concurrency.- You use processes for CPU-bound tasks, achieving parallelism.
However, other Python interpreters such as Jython and IronPython don't have a GIL and can achieve multithreading parallelism, but they are less commonly used compared to CPython. Also, using Python with external libraries like Numpy, which release the GIL when they do heavy computation, can achieve parallelism.
For a more complete exploration of concurrency vs. parallelism, we recommend Parallelism, Concurrency, and AsyncIO in Python - by example by Amal Shaji
