




We now have an officially supported dlt integration.
Today, we’re excited to introduce our officially supported dlt integration. Last October we introduced the first integration in the Embedded ELT family of integrations; leveraging Sling to easily ingest and replicate data between systems.
The excitement around the Sling integration has been motivating. Approaching nearly 1000 downloads a day, it is clear that the community has a need for ELT integrations in the Dagster platform.
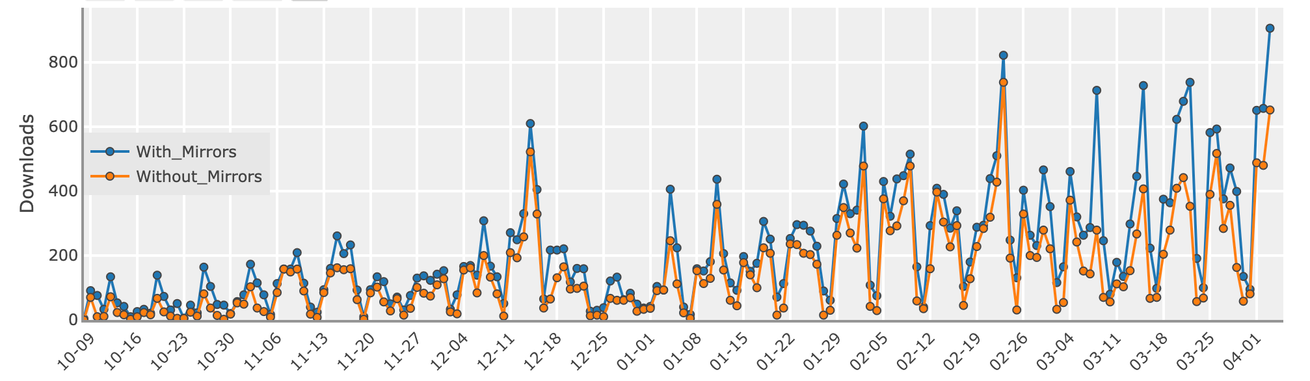
In the RFC: Community Input for the Dagster Embedded ELT GitHub discussion we polled the Dagster community members to see which ELT integrations were most desired, and it became clear that there was a strong demand for a dlt integration. With some users already using dlt in production — these individuals were integral in helping form the requirements for what was necessary for flushing out the officially supported integration, and we look forward to continued collaboration and enhancements to the dlt integration over time.
While Sling works fantastically for replicating data between databases and filesystems, and ingesting files, adding dlt to the embedded ELT library expands our functionality greatly. The dlt library fills the gap in ingesting data from endpoints, APIs, and disparate systems. Plus, with the flexibility of defining your own sources in Python, the possibilities are nearly limitless.
Overview
Data load tool (dlt) is an open-source Python library for building pipelines to ingest organic data sources into well-structured datasets. The dlt ecosystem and community are rapidly growing, with a large number of verified sources and destinations. Some notable sources that ingest data from APIs include Salesforce, Hubspot, and Stripe, but dlt also supports ingesting data from databases. As for destinations, dlt supports file systems like S3, databases like PostgreSQL, and data warehouses like MotherDuck, Snowflake, and BigQuery.
One of the magical things about dlt is that the developer does not need to define the logic for transforming their ingested data to a structure that matches their destination. One has to yield their Python objects in their pipeline, and the transformation happens under the hood. This alone can drastically improve the developer’s velocity when building pipelines.
Both dlt and Dagster offer Pythonic approaches for developing pipelines, relying on decorators. For example, when building a pipeline in dlt you define a @source comprised of @resources. These concepts map quite nicely to Dagster, allowing us to translate these resource objects into Dagster assets!
Our integration is built on top of the concept of multi-assets. The dlt pipeline and source are defined as one would use them traditionally, however, instead of running the pipeline directly, they are passed into the @dlt_assets decorator as parameters. The resources are extracted from the dlt source and converted into Dagster assets. Then, from within the body of our decorated function, we can trigger the pipeline to run, with materialized results being returned. Let’s walk through a quick example of building a pipeline that ingests GitHub issues and pull requests using the official GitHub-verified source.
By initializing the pipeline, we are able to pull the ingestion code for collecting data from GitHub directly into our codebase.
Without writing any of the ingestion code ourselves, we are able to leverage it from our Dagster project, defining a @dlt_assets definition from the GitHub source, and passing the github_reactions source definition that we’re importing from the initialized code.@dlt_assets definition from the GitHub source, and passing the github_reactions source definition that we’re
And just like that, we were able to define a simple pipeline for collecting data from GitHub in nearly no time at all.
For more advanced scenarios the dlt integration has followed the implementation architecture of the dbt and Sling integrations, in which a translator can be defined to adjust the parameters of the generated assets. For more information, reference the API documentation.
While dlt provides a fantastic framework for building ingestion pipelines, Dagster provides a robust framework for building and orchestrating fault tolerant jobs. By combining these two technologies, it’s possible to build data ingestion pipelines from a variety of sources with an intuitive developer experience.
Conclusion
We’re excited to join forces with dltHub by providing an integration that can pair with their engineering and ecosystem. If you find yourself writing a new source for dlt while working with Dagster, please consider contributing it upstream!
Community members are crucial in measuring the value of an integration, and our members along with those from dlt have gone above and beyond to provide early feedback and testing for the dlt integration. We are very grateful for their activity, and we look forward to further collaboration. We’re always looking for feedback and contributions. You’re welcome to join the conversation on GitHub discussions.
Finally, if you’re looking to get up-and-running with Dagster right away, consider exploring Dagster Cloud and you’ll have a production ready orchestrator in minutes.





.jpg)
.png)



.png)

