




It's easy for an open-source project to buy fake GitHub stars. We share two approaches for detecting them.
In this blog post, we explore the topic of fake GitHub stars. We will share our approach for identifying them and invite you to run this analysis on repos you are interested in. Click here to skip the background story and jump right to the code.
And if you enjoy this article, head on over to the Dagster repo and give us a real GitHub star!

In this post:
- Why buy stars on GitHub?
- Where to buy GitHub Stars?
- How can we identify these fake stars?
- Identifying obvious fakes
- Identifying sophisticated fakes
- Clustering intuition
- Improving the clustering
- The results
- Try this for yourself with our open-source solution
- Epilogue - what happened after we published
Why buy GitHub stars or buy GitHub followers on GitHub?
GitHub stars are one of the main indicators of social proof on GitHub. At face value, they are something of a vanity metric, with no more objectivity than a Facebook "Like" or a Twitter retweet. Yet they influence serious, high-stakes decisions, including which projects get used by enterprises, which startups get funded, and which companies talented professionals join.
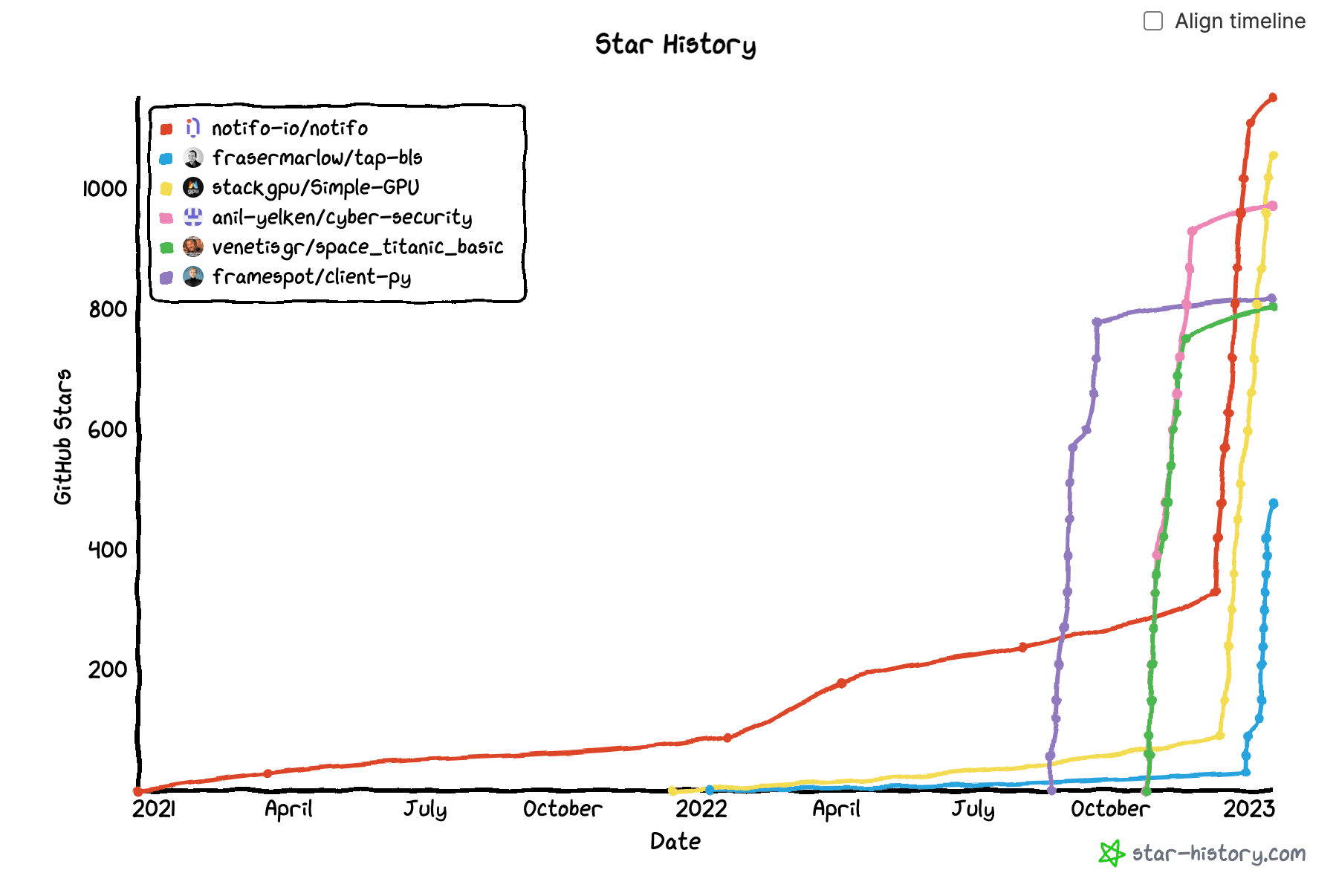
Naturally, we encourage people interested in the Dagster project to star our repo, and we track our own GitHub star count along with that of other projects. So when we spotted some new open-source projects suddenly racking up hundreds of stars a week, we were impressed. In some cases, it looked a bit too good to be true, and the patterns seemed off: some brand-new repos would jump by several hundred stars in a couple of days, often just in time for a new release or another big announcement.
We spot-checked some of these repositories and found some suspiciously fake-looking accounts.

We were curious that most GitHub star analysis tools or articles that cover that topic fail to address the issue of fake stars.
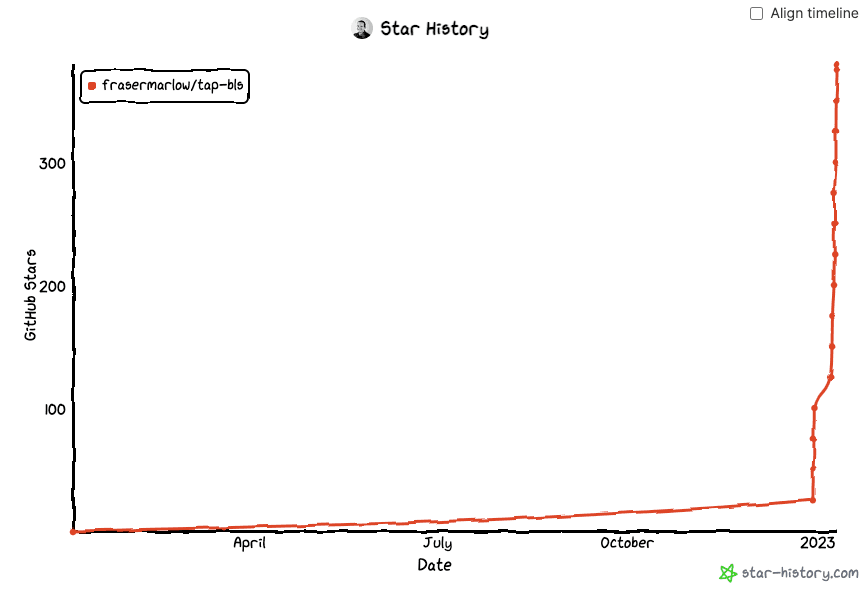
We knew there were dubious services out there offering stars-for-cash, so we set up a dummy repo (frasermarlow/tap-bls) and purchased a bunch of GitHub stars. From these, we devised a profile for fake accounts and ran a number of repos through a test using the GitHub REST API (via pygithub) and the GitHub Archive database.
Where to buy GitHub Stars (or GitHub followers)?
So where does one buy GitHub stars? No need to go surfing the dark web. There are dozens of services available with a basic Google search.
In order to draw up a profile of a fake GitHub account used by these services, we purchased stars from the following services:
- Baddhi Shop - a specialist in low-cost faking of pretty much any online publicly influenceable metric. They will sell you 1,000 fake GitHub stars for as little as $64.
- GitHub24, a service from Möller und Ringauf GbR, is much more pricey at €0.85 per star.
To give them credit, the stars were delivered promptly to our repo. GitHub24 delivered 100 stars in 48 hours. Which, if nothing else, was a major giveaway for a repo that, up until then, had only three stars. Baddhi Shop had a bigger ask as we ordered 500 stars, and these arrived over the course of a week.
That said, you get what you pay for. A month later, all 100 GitHub24 stars still stood, but only three-quarters of the fake Baddhi Shop stars remained. We suspect the rest were purged by GitHub’s integrity teams.
How can we identify these fake stars?
We wanted to figure out how bad the fake star problem was on GitHub. Just by clicking around, we can stumble over some obvious cases. Here is an example: this repo has 24 suspicious looking stargazers (edit: these fake profiles have been deleted since publication), all created on the same date. If we use these as a starting point, we see that these fake profiles have been used to follow the same users, fork the same repos and star the same projects. But how do we systematize our research?
To get to the bottom of this, we worked with Alana Glassco, a spam & abuse expert, to dig into the data, starting by analyzing public event data in the GitHub Archive database.
You might be tempted to frame this up as a classical machine learning problem: simply buy some fake stars, and train a classifier to identify real vs fake stars. However, there are several problems with this approach.
- Which features? Spammers are adversarial and are actively avoiding detection, so the obvious features to classify on - name, bio, etc - are generally obfuscated.
- Label timeliness. To avoid detection, spammers are constantly changing their tactics to avoid detection. Labeled data may be hard to come by, and even data that is labeled may be out-of-date by the time a model is retrained.
In spam detection, we often use heuristics in conjunction with machine learning to identify spammers. In our case, we ended up with a primarily heuristics-driven approach.
After we bought the fake GitHub stars, we noticed that there were two cohorts of fake stars:
- Obvious fakes. One cohort didn't try too hard to hide their activity. By simply looking at their profiles it was clear that they were not a real account.
- Sophisticated fakes. The other cohort was much more sophisticated, and created lots of real-looking activity to hide the fact that they were fake accounts.
We ended up with two separate heuristics to identify each cohort.
Identifying obvious fakes
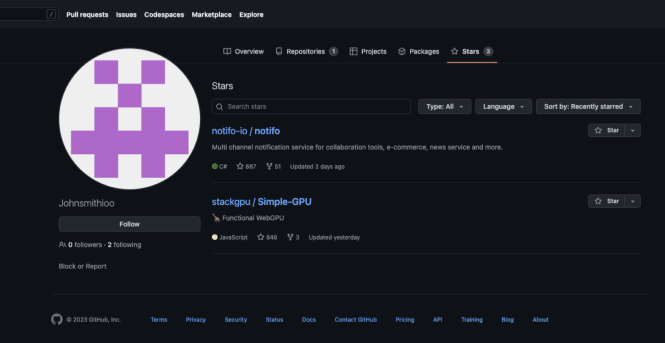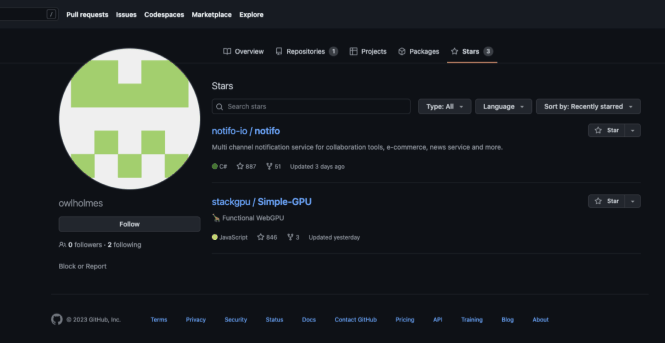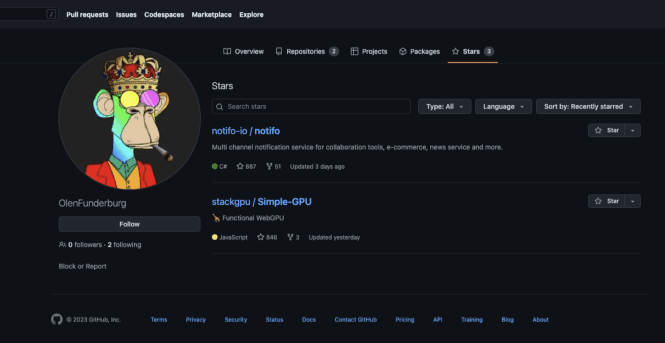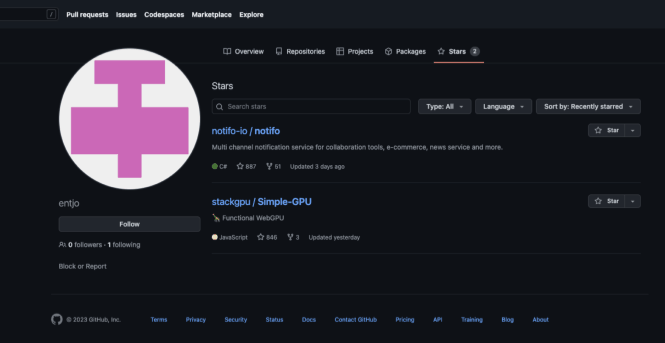
During our fake star investigation, we found lots of one-off profiles: fake GitHub accounts created for the sole purpose of "starring" just one or two GitHub repos. They show activity on one day (the day the account was created, which matches the day the target repo was starred), and nothing else.
We used the GitHub API to gather more information about these accounts, and a clear pattern emerged. These accounts were characterized by extremely limited activity:
- Created in 2022 or later
- Followers <=1
- Following <= 1
- Public gists == 0
- Public repos <=4
- Email, hireable, bio, blog, and twitter username are empty
- Star date == account creation date == account updated date
Using this simple “low activity” heuristic, we can detect many (but hardly all) suspected fake accounts that starred the same set of repositories, using nothing but data that’s available from the GitHub API.
Identifying sophisticated fakes
The other cohort of fake GitHub accounts was quite challenging to identify. They had realistic human activity: they had profile pictures, bios, and realistic contribution activity. The simple heuristic above didn't identify these accounts as fake, even though we knew they were from our purchase from vendors. How could we identify these realistic—yet known to be fake—accounts?
Clustering intuition
We ended up settling on a technique called unsupervised clustering. Conceptually, we wanted to construct a set of features per account. Normal users should be fairly diffuse; that is, their features should be fairly unique to them and they should not belong to any large clusters. Fake users, on the other hand, would all share similar features and would cluster together when visualized. In order to detect fake users, we'd simply check to see if they are part of a suspicious-looking cluster.
This is easiest to understand with an example. Consider "activity date". Most users on GitHub don't have public activity every day. If an account uses GitHub a few days a month, and those days are the exact same as another account, and they share similar activity on those days, it's a sign that, potentially, both accounts are controlled by the same underlying script.
To get a sense of what this looks like, we can plot the set of users who starred a given repo by the number of activity dates they share with other users (x-axis) and the total number of repositories they interacted with (y-axis):

Here’s an example of what that looks like for our dummy repo, which has nearly 100% fake stars:

And for the Dagster repo, which has (as far as we know) zero fake Github stars. Notice the tiny yellow dots in the bottom left corner, which represent a handful of false positive accounts (false positive rate = 0.17%):
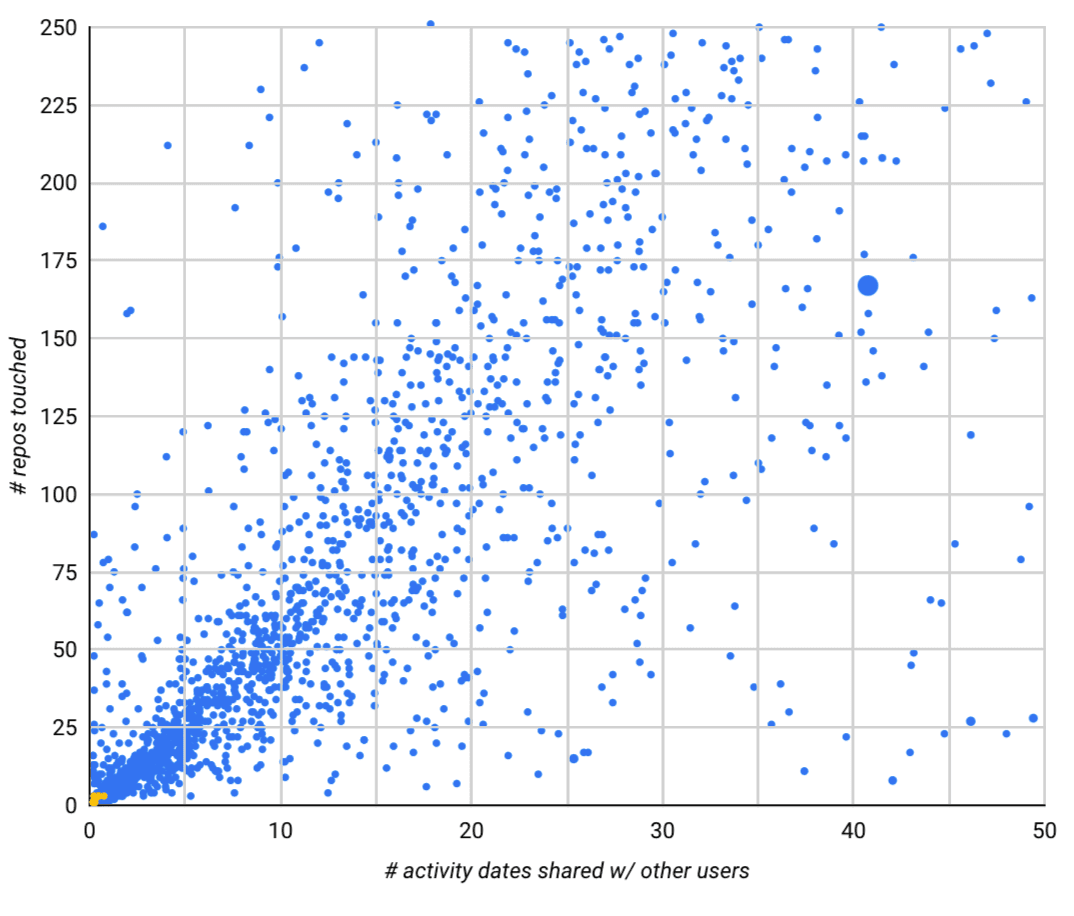
And finally, for something in the middle, we can take a look at one open source project repository that has a large number of suspected fake stars mixed in with real engagement. The clusters of fake GitHub users stood out.

Improving the clustering
While this initial technique was interesting, it wasn't good enough at identifying high-confidence fake users on its own. We needed to improve on it.
After digging into the data from this initial intuition, we discovered another pattern. Though these sophisticated fake accounts were interacting in realistic ways, we found that all the fake accounts tended to interact with a small set of repositories shared between them. Essentially, each fake account seemed to be adding GitHub stars to a subset of overarching "suspicious repositories."
Unfortunately we couldn't just find that list of repositories and be done as spammers would constantly rotate through new sets of repositories to star. However, we could use our unsupervised clustering techniques to identify these suspicious repos automatically. Then we would know which GitHub accounts were fake based on whether (and how much) they interacted with these suspicious repos.
Specifically, here is how we identified whether or not a user was suspicious:
- First, we pulled a list of all the users who starred the repository we're interested in analyzing.
- Then, we identified a set of potentially suspicious repositories based on high overlap with other users in this set. Remember, since these users are already related by having starred the same repository initially, it could be suspicious if they star a large number of overlapping additional repositories. (It could also just mean that this cluster of repositories is legitimately interesting to the same set of users - which is why the additional step below is important!)
- Finally, we looked for accounts with relatively low activity levels, where the vast majority of their activity was on the set of suspicious repositories identified above, and that had no additional legitimate-seeming activity. These were our fake accounts.
When we tested this heuristic on the known fake stars in our dummy account, we found that while it could be very computationally expensive, it was both very good at detecting fake accounts and also extremely accurate (98% precision and 85% recall). Things are bound to be a bit messier in a real repository, so we were eager to test this out.
The results
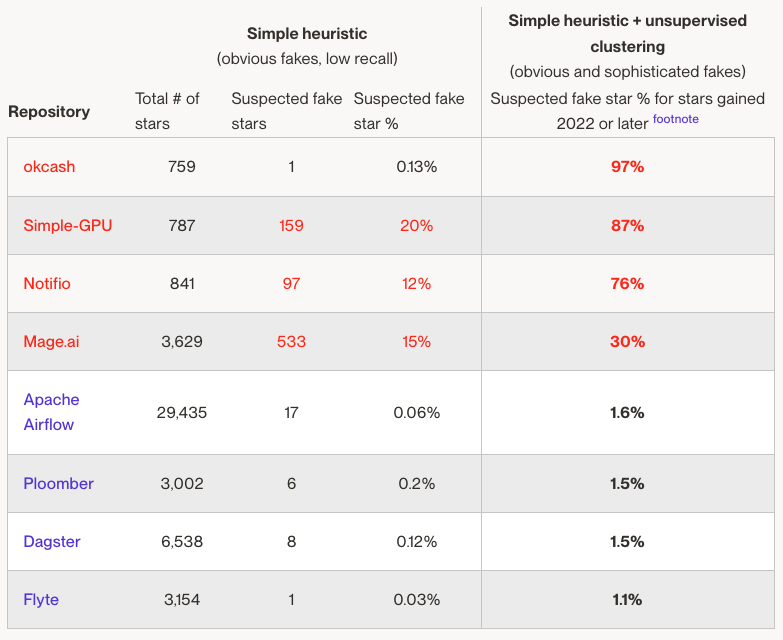
By putting these two methods together, we can get a more complete picture of the suspicious engagement found on a given GitHub repository and the recall of each method:
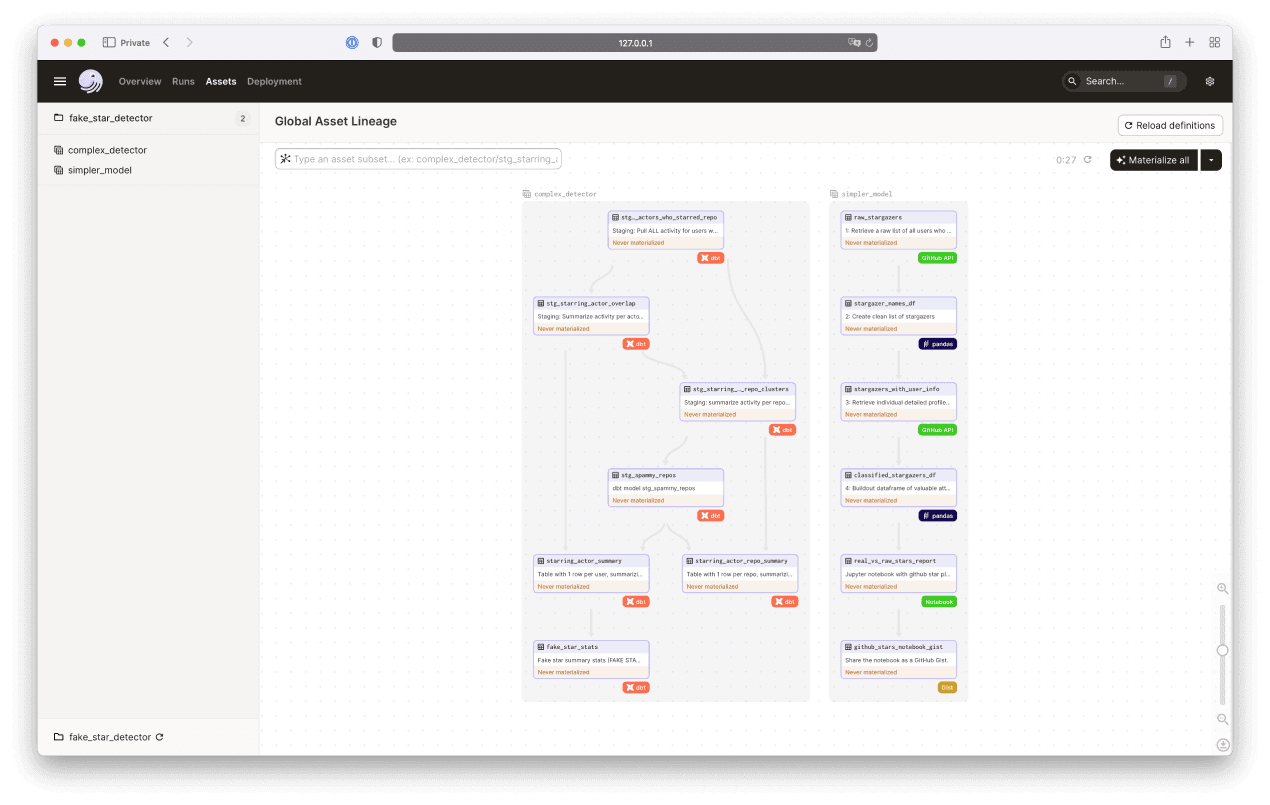
Ready to try this for yourself with our open-source solution?
If you would like to analyze other Github repositories using this logic, you will find a full Dagster and dbt project on Github here. The simple heuristic is implemented in Python, so all you will need is a Github account and an access token.
The unsupervised clustering method is implemented as a dbt project, so you'll need a Google Cloud BigQuery account to run it. Note that for large repos it may be quite costly to run.
Conclusion
Building models for detecting fake accounts (or other forms of spam) with 100% accuracy is hard. We can develop techniques with fairly high precision and recall but they become computationally expensive. Furthermore, the world is continuously changing around us, and many models need constant adjustment. Sometimes going with a simple heuristic can get us enough data at a fraction of the cost, so it's always good to keep a range of options in mind. And finally, just because a repo has some fake stars, it doesn't necessarily mean that the owners bought them, as spammers often try to hide their fake accounts by starring legitimate repos.
Given the incentives at play here, and the ease with which one can buy fake GitHub stars, it's heartening to see that this is not a widespread phenomenon, and speaks well of the values of the broader developer community.
However the option of stuffing a repo with fake stars exposes gaps in GitHub's own trust and safety mechanisms and there are certainly projects that have exploited them. We've shared these findings with the GitHub team, so don't be surprised if all of the fake accounts we detected in this tutorial disappear in the coming months [see epilogue], and the GitHub star count on those repositories takes a dive.
Epilogue...
Within 48 hours of publishing this article, either the GitHub team or both fake star vendors took action. All of the profiles used to star our test repository have been deleted. This said, we hope to repeat this exercise in a few months time. We will keep you posted.
In the meantime, here are some profiles flagged by our analysis to give you an idea of what is out there. We cannot guarantee there aren't some false positives in the mix, but take a peek and see what you think. Also, many of these accounts are now on the radar and are being deleted, so some of these links may be dead...
List users with suspect GitHub stars
AnastasisTheofan | djsharma73Analyst | RoryTronmomld | Chronos-Orb | donaldLhamilton | adamsmith335521 | AdarianJack | aieveryday | aigesda | AKumar-world | aladfgjh | alan2228 | ale-gayle | alexdevid123 | alexgonchi | alexiafernado | alianjumfty | allanYIOK | Almajeskai99 | alxbaby | anaerfs | anarion51 | andromsa | angachowdhu | angakrishn | angie-rkoa098 | anielgibbo | animesh-agarwal-unskript | ankhasa | arbiterrss | arcane-spam | arcouxwysyik | ariajam | arkjasa | artifact-am47 | artifact41 | artinkea | arycdys | asassdsd | ascendmarla | asevban | asifaas | aspervern | asternadk | astjoe | billiemarra83 | billiestbt93 | bjohnsonphpni | bluevegaquant | Bobbysteven | boltdiioe032 | boltParadigm | boltrt83 | brendatgrundy | brettsummers | brittneee | Brooknsgea | brooksdf | brunostockmansg | bushido06 | bushidoStormvltoh | callie110 | cannonlamar610 | Carboneh | Carla-093 | caryrohan18 | celestial-083 | cesarstrickland | CharlesCosmic | charlmay | chipper29 | chronocutter | claraferna | clarkmorris | Cleonoe9 | colemanlanning | colinauf2019 | connorjhon199 | creedmatrix | csehdz1 | cwowl | daemonscry | DAINEIO | daletnam63 | Daviusar | dcmesaikumar1 | dcookegluu | delay4eva | deltalegion | demesnne | derfinn3e | Desiree096 | dijuhae | dileep-lingamallu | DimonX90 | dino-tlnne74 | dinosle | DJamesss | Donaldj23 | drucillla | ebertdillan | ebuwaevbuoma-fike | edith-sword | edmon96 | eerthankar | effie-ica | eggonthe1st | ekkaramas | ElectricDen | eliasflare | Emmacamelia | emmamadison | emmettullrich12 | Enchant-046 | endymcarey | enesce1ik | ennachaseyik | entjo | eonardf | er447799 | ernse | EspirituChris | esterhami | esvonh | exodusqueue | ezra-rbiv74 | F4vz-Undertale | fadediff | FarhinZahra | fatherofpearl | fay088 | feifei116 | ferdiewal | Flare006 | Flareat | flarescrollrkaio | FoxNdwandwe | francisashan | ganesh-gaan | garciarafad | garrettcoleyio | garricklang1 | Gerharddfg | glowingred | gontoos | gravity-west | greeneye-bandit | gregorio099 | grozersmith | guiseppeebert7 | gusikowskitrey444 | haaratb | haikujunky | haileyondricka14 | halliescom3t | handreshoo | haribandiyi | hashsanta | HaywoodCollins | hellohelod | Hexmagecl | hexmui | hextsni038 | Hitika-Teckani | hjirtdd | hnautry | hncenn | hngard | holmes0125 | Hopempo029 | horacrux | HT1975 | hugogramm | hulktom335 | ibbhassan | ichardrhod | ichigo-hokage | ictoas | icybadr | ileygrego | illuminothing | illyhoormy | ina-053 | innergates | ioncan0n | ionutcristianmanica | irgitwech | istsfa | itschimenow | iwqsjk | jaamo22 | JackCusicked | jackie-kaea | jadetheo | jadevaky | jaffarazeem49 | jamespra | javierschutte | jblinji429081 | jdyions | jeana017 | jennyfromthebl0ck | Jeonsarker | jesedbodiford | jinyoung-kim-dinnercoding | jlannisters | Jnvrrz | Jobworker | johnadisa | johnbpalmer | johnmartin414 | Johnsmithioo | jonnie-il081 | jorgsa | joshepsalvatore505 | jphinek | jukenistanskijuk | julianneacamacho | justinmcdermott97 | jwelch13 | kafkamikaze | Kaliislam | karamanisd | Karenm0 | karenskky | keeblergilbert | Keenanprium | kelleyhodge86 | kelliprium083 | khalidhasanice | Khanbaab1 | khannn932 | kingjames5 | kitanaaa | KittenHugz | kuphaleli15 | lambjohnk62 | lanbrian | larrylloos | Lavina830 | lbertdo | Leonardohilpertdf | leonmbradley17 | liamyiok | licesds | lightninglane | lillianknnae | linaslayer | linathebean | lincoln-040 | lindseysimo | lopesjeniffer | lorenzodte | loyal-arbiter | Luna-iz16 | lunarcar | mable0 | Mackback332 | MageKai | Magnetose12 | mainekyle25 | majorcelestial | Maplevie | mariemare2010 | matrix555555 | Maury10 | maxcreidyio | maximusmillsmaximu | mayoyasar | mbernisa | MbondeCyril | meat-baller | mehrdade | melodyfortin02 | mesmayik | metatrongeal40 | meteor-05 | miamalkova19696 | Miguelboltai072 | Milonh | minhriley | minoreleventh | Mintieeux | miraedorashean | miriam008 | mmckesd | mohamedbello4848 | mosciskit | MoseFolmar | moses-75 | msbignoodles | mthhastigf | mwarsss | mwisyou | myausaur | myrna-Radiance | Nabin0714 | naimiakanamiayou | naldotra | nancytfield | natlydb | nayem72846 | ndonmessi | nebula-Operator068 | neon-cali | neon-dark-dreams | neutron-dt | neutron-ohs | neutronTitus | new1wen | newvc044 | nexilien | NickAcev | nickblack883399 | NickLekkas227 | NinoDui | nlavas | nofsylhe | nordic-hordic | Novalunar | oancha | Obaidullahsabir | obi-wan-nobody | octaviusspear | ohntgr | ohsia | olegriffi | OlenFunderburg | olliewollie2022 | omenidor | onahsir | onaldreig | onavonc | One-Tw0 | onnorwis | onnywsd | onsinsa | orbital71 | Otisimperator | otsfordne | owlholmes | oyasuyuki | p4tir | palmarrobert | pandowu | paragondnen | Pat0999 | pdili493386 | pencerwe | pentagonia | pezjoh | philjtsa | phrenelith | Pierrelefort | PierreSnell | pilis | planeswalker29 | planeswalkerKageaua | PLBRM | potterenola | pratikadaha | prezpotz | primevector | priyadil | PriyavKaneria | psuidt | Pulse045 | Purna770 | qalandarsurani | qop0qop | Quantumne3 | qwertyiytrewq | rachaelbarker499 | Rahat11210 | raisingraisin | raj1333 | ramizads | randopop | rantbas | rath-nsao | rayan512 | raymcarty788 | rdynads | red-trainer | Revan878 | revanngehn | rexemmerich | ReynaldoMR3 | rhy5s | ridez22 | rightasteroid | ristophyik | robertstevy | robpose333333 | roybase1982 | ryangiovanni2 | ryangreg97 | saadbahir | sachinjagtap98 | sadamsk | sadhumandalklg123 | Saifi78 | sallugamingyt26 | sandres16 | Santhin | scottscotts | sdi2100006 | sentientworm | sexditnhau | Shahg4 | shasta-ra | shaunedyyik | Shehzada50 | shinobi-082 | Shinra006 | shoguncelestial | shogunrma | ShogunTronngrl22 | shogunvalkyrionria | shrey-mage | shuklasrishti | shumailashe | sidtirivavi | Silenius077 | silentdespot | skcasw | smoothop3rat0r | snzcc047 | solidsnak3s | spacer-goose | Sparkinvaders | sparkpriscilla | sravanthirajs | sreginaldc | Stack-068 | stackers5 | steveagilbertstevea | steven-yampolsky | stevesradience | sumensad | sunlei | Supenkumar | surroc | tahakamiy | takeshigold | Tamaf6500 | Tamra-6 | tanto-ya | taskanell | taskmaster73 | tattedtwo | tellyphone | tena-70 | teri-lrr46 | Tetragrammaton007 | Thmp6 | thragusjr | tinkeroo | tiromy | Titusnnv13 | tobygreen1111 | Tolejon | Toma-Mo | tonyabracadabra | tory-of-troy | Tourmalines | travissmith99 | trenner1 | tristario | trompjulius02 | turnergerald70 | ufosoftwarellc | ulasfid | ulkleyc | ultra-viola | urgeshg | urtonds | usesad | ustinlokh | uxgri | vader7777 | valamirr | vallie-Kensei061 | valoranter | vectorarray | vectorrevan | victra-68 | VictraBolt | vidacicvuk | vijayajiths | viven25 | vzulauf67 | waderkrk80 | waildzess | walterajoycew | ward09 | warenwuckertYIO | waryths | watsicakristofer47 | wellsadam57 | whiteheadmatthew | wilfridsimonis11 | williamjdavis | Wilsonbruv3 | wilsonezrayio | wooodsIO | wrongmeteorr | wasirabbbas123 | ydahsh | yogesh-wego | yongchand | youngt33 | Zanbadoshaj | zonggeliu | zulqarnainalikha | nanirules153 | jaymewest123 | odafeeny | brekkeno | Lemke1221 | johnathanmurray4 | JamesBond5 | Ahmadpk922 | sarathkumkk | dweissnat | izaiahbernier01 | davwillian99 | sammyjakubowski | thomasbnee | Gaksbd79 | mjem45502 | Charles64564 | Davejohnson6 | john8967 | chsjsn6283 | zuckerjohn | Pete8899 | riyaislamhg | ohnsmitt | ismongera | olojinngf | dwardskin | zerdlufg | imetcymo | lekbydf | amesfgh | toddlbrafford | javedwilliamson69 | matadio | jonyfred2002 | Manazir899 | orvinfa | Jaadi6737 | billogds | oikhsands | obidfg | anceg | albert786 | uaswa | ayasanaka | Durjoy257 | arlosvah | ruhBruuh | ararosD | uizstefa | adushashg | tiral111000 | lueilwitzlemue | papatyasoldu | Beckerrashawn | dixontom792 | b4teL | markjasonnyiom | bdyion | brevelyemmy | abdulhaqswati | hmaguireyio | isyions |





.jpg)
.png)



.png)

