May 18, 2021 • 6 minute read • ![]()
Incrementally Adopting Dagster at Mapbox



- Name
- Ben Pleasanton
- Handle

The Geodata teams at Mapbox are responsible for continually updating the map of the world that powers our developer data products and services.
Like many teams using Airflow, we found that continued development in Airflow was painful and costly.
Our data sources range from hard drives that get delivered from our vendors in the mail once a month, to public-facing APIs that we poll every day, to real-time feedback on thousands of addresses from the 700M end users who touch our maps every day.
We process this data using about a hundred different data pipelines and flows to create maps, road network data for navigation, point of interest datasets, and search indices for addresses. The core of our address data processing is the conflation engine and correction system, which combines over a billion addresses with road, parcel, and building datasets to get maximum coverage of existing addresses and calculate the most correct address points possible.
Mapbox has historically relied heavily on Airflow for orchestration, and many teams, including ours, run their data pipelines on their own Airflow instances.
But like many teams using Airflow, we found that continued development in Airflow was painful and costly.
To fully test their orchestration code in Airflow, our engineers would typically need to run a bunch of deploys to production, since setting up the dependencies to run DAGs locally and ensuring that they were correctly configured was too cumbersome. This led to unacceptably slow dev cycles — not to mention significant cost, since all our dev work had to be done on our production infrastructure.
We needed a solution that would allow for incremental adoption on top of our existing Airflow installation.
In an environment like ours, where the outputs of data pipelines are business-critical, SLAs are strict, and many teams are involved in creating data products, we can’t stop the world and impose a new technology all at once. Luckily, Dagster comes with a built-in Airflow integration that makes incremental adoption on top of Airflow possible.
We started using Dagster because we needed to improve our development lifecycle, but couldn't afford to undertake a scratch rewrite of our existing, working pipeline codebase. Dagster lets us write pipelines using a clean set of abstractions built for local test and development. Then, we compile our Dagster pipelines into Airflow DAGs that can be deployed on our existing scheduler instances.
This is especially critical for us since our Dagster pipelines need to interoperate with legacy Airflow tasks and DAGs. (If we were starting from scratch, we would just run the Dagster scheduler directly.)
We started by writing new ingestion pipelines in Dagster, but we’ve since moved our core conflation processing into a Dagster pipeline.
Let's look at a simplified example, taken from our codebase, of what this looks like in practice for normalizing, enriching, and conflating addresses in California.
Our Dagster solids make extensive use of Dagster's facilities for isolating
business logic from the details of external state. For example, one solid,
export_conflated, reads enriched and normalized addresses from the upstream
solids and then conflates them into a single deduplicated set of addresses,
taking the best address across multiple sources.
@solid(
required_resource_keys={"conflate_emr_step_launcher", "pyspark"},
config_schema={
"export_table": Field(str, is_required=True),
"execution_dt": Field(str, is_required=True),
"export_csv_enabled": Field(bool, is_required=False),
...
},
)
def export_conflated_addresses_solid(
context,
iso_3166_1: str,
iso_3166_2: str,
input_database: str,
...
):
spark_session = SparkSession.builder.enableHiveSupport().getOrCreate()
execution_date = get_execution_dt(context.solid_config["execution_dt"])
export_csv_enabled = context.solid_config["export_csv_enabled"]
enriched_source_1 = spark_session.sql(
f"SELECT geojson FROM {input_database}.{source_1_enriched_table} "
f"where dt = '{source_1_delivery_dt}' and state = '{iso_3166_2}'"
)
...
enriched_unioned = enriched_source_1.union(enriched_source_2).union(
enriched_internal_source_3
)
final_df = conflate(spark_session, enriched_unioned)
export_data_to_conflate_table(
TableOperations(spark_session),
tableOps,
final_df,
output_database,
export_table,
execution_date,
iso_3166_1=iso_3166_1,
iso_3166_2=iso_3166_2,
)
yield Output(execution_date, output_name="conflated_dt")
if export_csv_enabled:
csv_exported = export_csv(
spark_session, final_df, output_database, execution_date
)
The body of this solid is mostly Pyspark code, operating on tables that have been constructed by upstream solids. In a pattern that probably feels familiar, we constuct some source tables, join them, and then export them to a conflated table.
You'll note that we use Dagster's config schema to parametrize our business
logic. So, for example, we can set export_csv_enabled to control whether a
.csv of the output data frame will be exported or not.
We also use Dagster's resource system to provide heavyweight external
dependencies. Here we provide an conflate_emr_step_launcher resource and a
pyspark resource. By swapping out implementations of these resources, we
can control where and how our Pyspark jobs execute, which lets us control
costs for development workflows.
Our step launcher is actually a fork of the open-source Dagster EMR step launcher: we've modified it to handle packaged Airflow DAGs and dependencies, as well as to create ephemeral EMR clusters for each step rather than submitting jobs to a single externally managed EMR cluster. This was straightforward for us to implement, thanks to Dagster's pluggable infrastructure.
What's really exciting about this is that our solid logic stays the same regardless of where we're executing it. Solids are written in pure Pyspark, and the step launcher implementation controls whether they execute in ephemeral EMR clusters or on our production infrastructure. The code itself doesn't change between dev and test.
This means that as we're developing our solids, we can work with them in Dagit for incremental testing and a tight dev cycle.

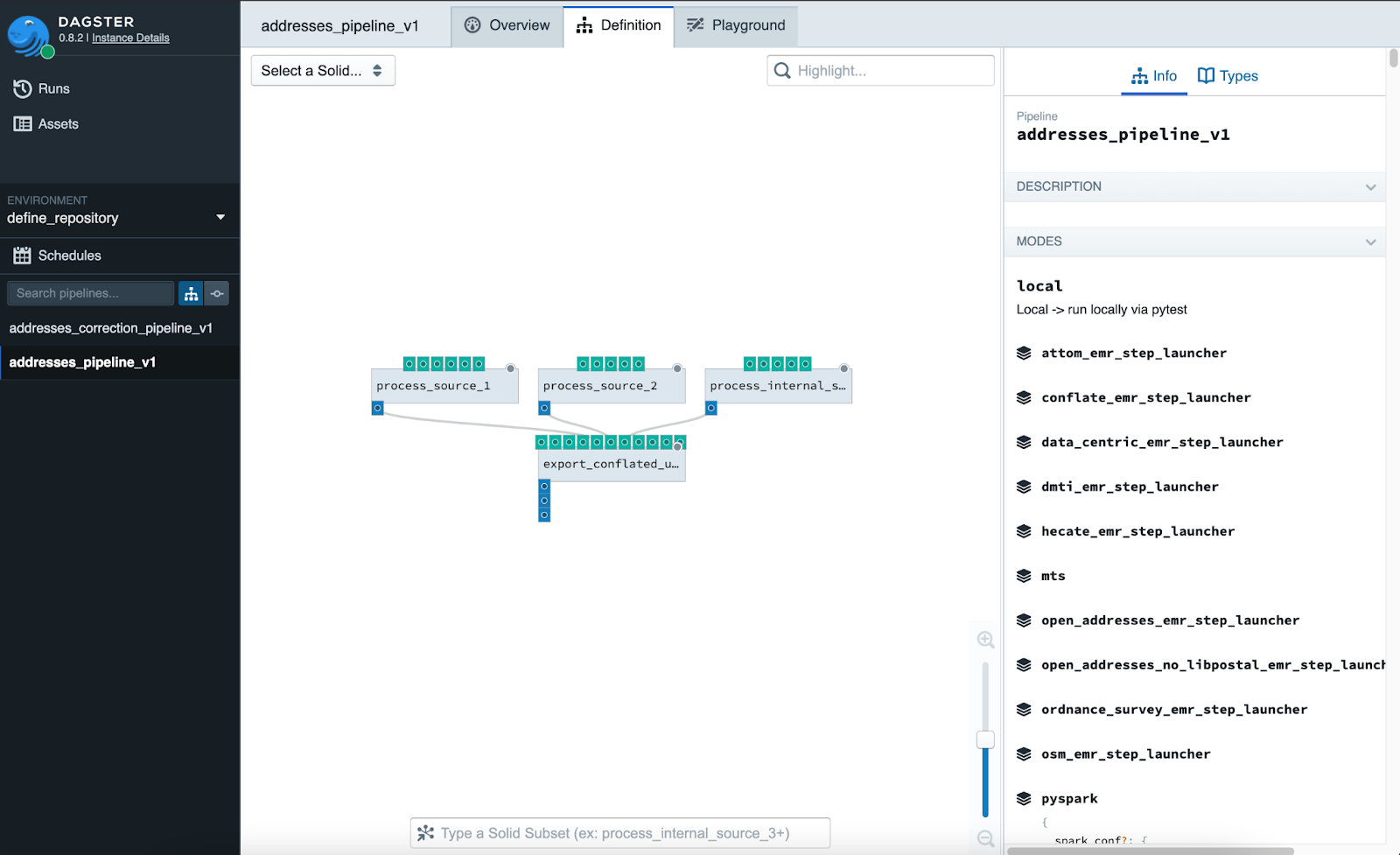
After we construct our Dagster pipelines from our solids, we compile them into
Airflow DAGs. Here, for example, we take a Dagster pipeline,
repository_addresses_pipeline.addresses_pipeline_v1 (containing the example
solid above). We compile it to Airflow using
dagster_airflow.factory.make_airflow_dag, and then edit the compiled
template to hook our new DAG up to an existing Airflow Task, create_index.
default_args = {
"retries": 2,
"start_date": datetime.datetime(2020, 6, 1),
"on_failure_callback": alert_pagerduty,
...
}
# Make airflow dag/tasks from Dagster pipeline
dag, tasks = make_airflow_dag(
dag_id="addresses_pipeline",
dag_description="processing of addresses",
module_name="repository_addresses_pipeline",
pipeline_name="addresses_pipeline_v1",
mode="production",
...,
dag_kwargs={"default_args": default_args, "schedule_interval": "@once", ...},
)
# Add in airflow operator task
create_index = PythonOperator(
task_id="create_index", dag=dag, python_callable=index, provide_context=True
)
# Link dagster dag with the airflow task above
# This ensures the Dagster pipeline executes prior to generating the search index in the Airflow task
for task in tasks:
if task.task_id != "create_index":
task.set_downstream(create_index)
In production, we do some even fancier things -- for instance, hooking up our compiled DAGs to our existing library of Airflow callbacks for custom alerting.

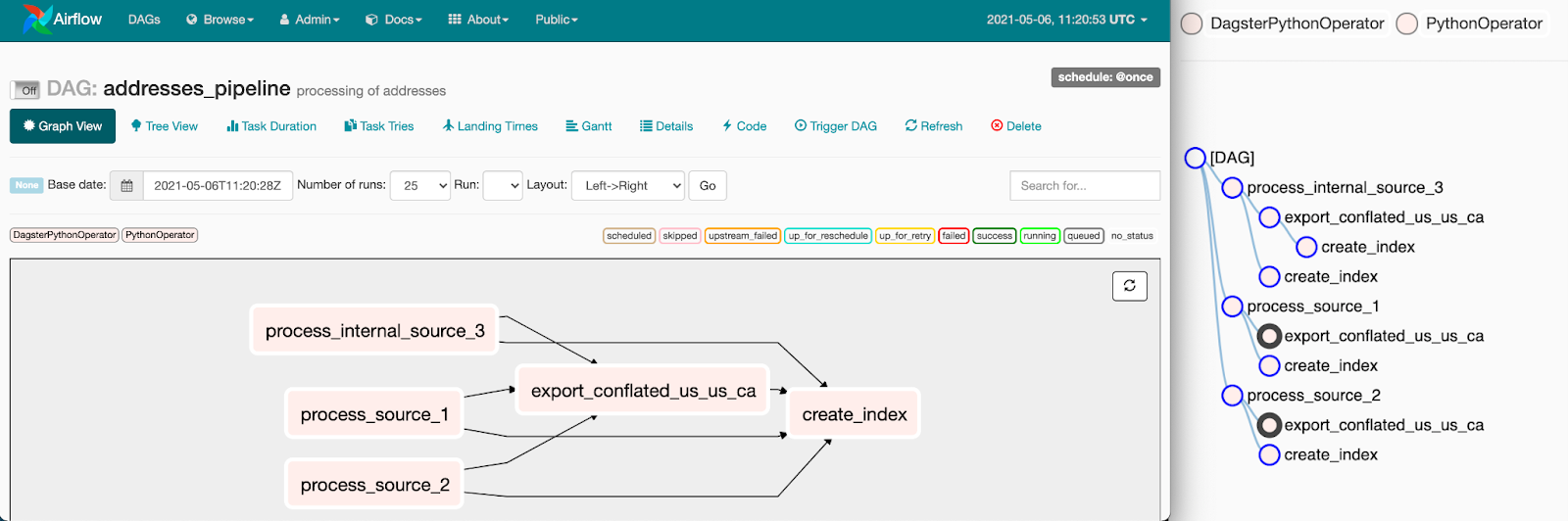
Our compiled Dagster pipelines sit with all our other Airflow DAG definitions, and they're parsed into the DagBag and scheduled with all the rest.
That means we can develop and test a Dagster pipeline locally using Dagster tooling, including Dagit, and then monitor production executions and view the dependencies on Airflow tasks using Airflow.
We started adopting Dagster by writing new ingestion pipelines in Dagster instead of in Airflow, but we’ve since moved our core conflation processing into a Dagster pipeline.
With Dagster, we've brought a core process that used to take days or weeks of developer time down to 1-2 hours.
This has made a huge difference for developer productivity. Just to give a sense of scale, one of the goals of this project was to reduce the human time it takes to conflate all sources in a region (i.e. state or country) down to a day or less -- this previously took days or weeks of human effort. With the new Dagster pipeline and other performance improvements, we were able to reduce this to an average of 1-2 hours. This improvement in productivity was also seen in creating new ingestion pipelines for new address data sources.
With Dagster, developers can orchestrate their pipelines locally in test, swapping in ephemeral EMR clusters to test Spark jobs instead of running on our production infrastructure. Because we can now run on dev-appropriate infrastructure, testing is so much less costly -- more than 50% -- that in the first few weeks of this project our engineering manager was worried there was something wrong with our cost reporting.
Testing is so much less costly that our engineering manager was worried there was something wrong with our cost reporting.
Dagster has let us dramatically improve our developer experience, reduce costs, and speed our ability to deliver new data products -- while providing a path for incremental adoption on top of our existing Airflow installation and letting us prove the value of the new technology stack without a scratch rewrite.
If the kind of work we're doing on the Mapbox data teams sounds interesting to you, Mapbox is hiring!


We're always happy to hear your feedback, so please reach out to us! If you have any questions, ask them in the Dagster community Slack (join here!) or start a Github discussion. If you run into any bugs, let us know with a Github issue. And if you're interested in working with us, check out our open roles!
Follow us:


BenchSci: A Leap Forward with Dagster


- Name
- TéJaun RiChard
- Handle
- @tejaun

Abstracting Pipelines for Analysts with a YAML DSL

- Name
- Fraser Marlow
- Handle
- @frasermarlow

Catalyst Cooperative: Liberating Public Utility Data with Dagster
- Name
- Fraser Marlow
- Handle
- @frasermarlow