



The PUDL Project cleans and distributes analysis-ready energy system data to climate advocates, researchers, policymakers, and journalists.
US government agencies release hundreds of gigabytes of data on utilities and power generators annually. However, due to its voluminous size, scattered nature, and complex structure, it is mostly inaccessible to researchers and advocates.
To overcome these challenges, the Public Utility Data Liberation (PUDL) Project converts government-issued spreadsheets, CSV files, and databases into an integrated resource. PUDL utilizes an open-source data pipeline that automatically extracts, cleans, combines, validates, and publishes US energy data from various agencies, including the Energy Information Administration (EIA), the Federal Energy Regulatory Commission (FERC), and the US Environmental Protection Agency (EPA). This helps energy researchers and advocates focus on innovative analysis rather than data preparation.
We met up with Bennett Norman, Data Engineer at Catalyst Cooperative, to discuss the technical choices the team made as the project grew and why they picked Dagster to rapidly iterate on the pipeline that generates PUDL’s key data assets.
About Catalyst Cooperative:
In 2017, a team of clean energy advocates in Colorado founded Catalyst Cooperative with the goal of making valuable public energy data readily accessible and user-friendly for those working to decarbonize the energy system.
Today, Catalyst Cooperative is an entirely remote data analysis cooperative consisting of seven employee-owners distributed throughout North America. Their primary focus lies in the US electricity and natural gas sectors, and their work caters to non-profit organizations, academic researchers, journalists, climate policy advocates, public policymakers, and smaller business users producing novel research and policy recommendations.
The early days of the PUDL project:
The primary project of Catalyst Cooperative is PUDL, which is both a data pipeline and a set of datasets analysts can query. The PUDL pipeline currently involves integrating, cleaning, and transforming data from three distinct government agencies to provide a comprehensive overview of energy generation in the United States. Since the agencies have yet to adopt common identifiers for the various components of the energy system like utilities, plants, and generators, the project requires substantial effort to ensure record linkage across the datasets.
Initially, Python and pandas were the sole tools used for wrangling and loading data to SQLite and Parquet files.
To automate the ETL pipeline, the team set up a cloud VM and executed the pipeline nightly on a cron schedule. Following a successful nightly run, the updated SQLite database would be pushed to production.
Users could access these SQLite tables through a front-end data portal, but accessing interim outputs, additional analyses, and denormalized versions of the data required downloading all of the normalized data and installing the pudl package. This made it harder for less technical users to analyze the data.
“For users to access this additional layer of functionality, they need to be familiar with Python and virtual environments. This creates a barrier for less technical users."

Pre-Dagster architecture,
The limits of a DIY Python approach
Eventually, the need for an orchestration tool became more apparent:
“There are a lot of gnarly data dependencies between tables, and we got to a point where it just got so entangled and complicated, it was hard to move forward and add datasets,” says Bennett.
The team faced several challenges that hindered their productivity, including:

- Burdensome process for adding a new data source and combining data sources.
- Lack of parallelism in their setup.
- Lacked uniform tooling for adding new datasets, analyses, and handling IO.
- Had to rerun the entire ETL when making changes to portions of the ETL which slowed development.
- Difficult to access interim outputs from the ETL for testing or analysis purposes.
- Difficult to understand the complex dependencies between data assets in the existing codebase.
Ultimately, the team wanted to adopt an easy-to-use data engineering solution so they could focus on data cleaning instead of developing and managing custom tooling.
The right orchestrator: imperative or declarative?
It was clear to the team that there must be a data tool out there that had already tackled many of these issues.
“There had to be a common engineering tool that could handle the infrastructure so we could focus on the areas we are experts in." says Bennett.
The team investigated Airflow, but it seemed like a higher barrier to entry compared to newer orchestration tools. Both Prefect and Dagster, provided easier-to-understand concepts for creating DAGs, validating configuration, and handling IO.
The team decided against Prefect, due to it being too unstructured: “Prefect was almost too flexible for our purposes. We wanted more opinionated Data Engineering abstractions. Many of the data-aware abstractions in Dagster —such as data validation with Pandera, data lineage, viewing metadata as it changes run-to-run, and taking a declarative approach — were a much better fit for our use case." The team documented their head-to-head evaluation in this GitHub issue.
Migrating to Dagster
In September 2022, the team embarked on a project to migrate their system and began by familiarizing themselves with Dagster abstractions and how to optimize their usage. Mapping existing PUDL python objects that are shared among assets to Dagster Resources presented minimal challenges, but mapping existing Pydantic classes that validate the ETL configuration to Dagster types required some effort. However, Bennett notes that this task has become significantly more straightforward following the release of Pydantic Config and Resources in Dagster 1.3.
During the conversion process, Bennett received support from the Dagster team and the Dagster community, enabling him to quickly overcome any obstacles. One of the more significant challenges was creating a DAG composed of partitioned hourly emissions data from EPA and non-partitioned power plant data from EIA. Although incorporating Dagster partitions into a DAG of non-partitioned assets presented challenges, the team successfully utilized a combination of dynamic outputs and asset graphs to achieve their goal.
“We discussed which approach would be best - declarative or imperative, or a combination of the two? Once we committed to a declarative approach, it became much easier to convert our code over to Dagster and map over our existing assets.”
Building with Dagster
Since the initial conversion, contributors have been able to add new data sources with relative ease. “It’s been super positive so far,” says Bennett.
“It is nice to be able to decide how to persist each asset - some assets feel like an important step but do not need to be persisted to the database, while others can be loaded to the database with a SQLite IO Manager - we can just switch things on and off.”
“We mostly publish cleaned versions of the tables. But occasionally our users ask for the raw data or maybe a partially cleaned table that is fit for their purpose. It is now easy for us to make that interim asset available to them.”
“To be able to create the DAG just based on asset names is super convenient. With the imperative approach, you had to think about where these functions should be calling each other, but with Dagster’s declarative approach, you don’t have to worry about it. You just load everything into a Dagster Definition, and it will create the DAG for you.”
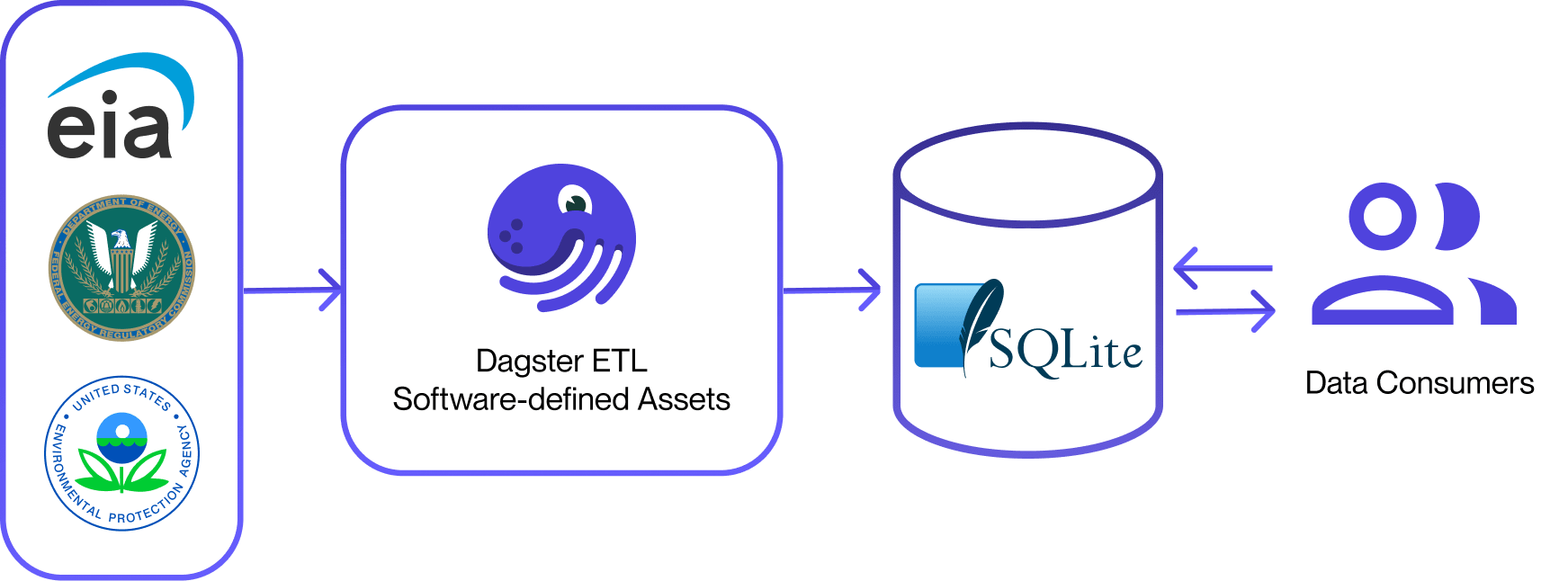
Post-Dagster architecture.
Dagster has improved Catalyst’s workflow by:
- Simplifying the process of adding new datasets to the database thus enabling hundreds of new data assets to be made available to users.
- Accelerating development iteration cycles.
- Reducing mental effort in designing integrations for new or updated data sources.
- Eliminating the need to install the PUDL library will remove a significant barrier that currently prevents less technical teams from utilizing the data.
“Adopting Dagster made it easy to treat all of our datasets as Software-defined Assets and persist them to the database, which can be easily distributed.”
Working with Dagster, Catalyst Cooperative feels more prepared to scale up the project, integrate more diverse datasets, and make them available to their users. They think adopting Dagster and distributing user-friendly data products instead of software will expand their reach and hopefully accelerate the decarbonization of the electrical grid. They are excited to see the Dagster community expand, add additional functionality, and develop best practices.
Interested in trying Dagster Cloud for Free?
Enterprise orchestration that puts developer experience first. Serverless or hybrid deployments, native branching, and out-of-the-box CI/CD.
Try Dagster Cloud Free for 30 days





.jpg)
.png)



.png)

