




To be a more productive software engineer you need to master changes, how these affect the program and others on the team.
So you want to get stuff done. You want to be a productive software engineer. What does that mean?
"pro·duc·tive" adjective: producing or able to produce large amounts of goods, crops, or other commodities.
In the realm of software, the engineer’s commodity is a code change. These changes increase the utility delivered to users via the software we work on. A change may be a bug fix, an improvement to documentation, a new feature, or even the removal of code.
Version control systems are used to manage these changes, and many organizations require these changes to be peer-reviewed before they affect users. Using the lens of Git and GitHub, the unit of change is a commit and the unit of review is a pull request (PR). An accepted change can be merged into the next version to be released to users.
Developing changes to a piece of software is an iterative process. A variety of tools are used to create feedback loops that ensure changes are functional and high quality. Getting the most out of these feedback loops is key to becoming more productive. While computers drive the tools providing the tightest feedback loops—like static analysis and testing—the code review process is driven by people. This makes code reviews a much more challenging and rewarding feedback loop to optimize.
Human in the Loop
Code review involves other participants. Reviewers are often engineering stakeholders who have context on the change and can provide guidance. If they are thorough in the process, the change can immensely benefit from the feedback: it can be simplified, further contextualized, or armed with more wondrous insight. Once feedback is incorporated, the change can be signed off to be merged.
In inspecting this feedback loop, the point to note is that both the author of the change and the reviewers have levers to dictate the iteration process. For example, the author determines the scope and granularity of the change in review. The reviewers determine whether to give small nitpicks or critical comments regarding the structure or approach of the change.
By optimizing this process, the review feedback loop gives the author higher quality changes and reduced latency in getting them merged.
Here, we will focus on what steps the author can take to improve the review feedback loop. To further analyze this perspective, let us follow the journey of making a change.
Making Changes
Roughly speaking, the journey of a change is
- 🤔 Have an idea
- 💻 Make the changes
- 👀 Have it reviewed
- GOTO 2 (0-N times)
- ✅ Merge it
…which might look something like this:

One way to increase our output is to reduce how long this process takes. The first thing that jumps out here is that the time writing code (in blue) is much smaller than the time spent waiting for review. We can spend some extra time reviewing our own code to make sure that we are not repeating things that surfaced in past reviews or making any trivial mistakes. We can also make sure changes are well tested to reduce the burden on the reviewer to validate correctness.

Past optimizing one change at a time, our next step in improving output is to juggle multiple changes. Having different changes in flight is a fundamental skill for a productive engineer to utilize their time. Maximizing output through this approach has its limits, though. This works best when the time to change contexts from between changes is low, like fixing several bugs in the same area.
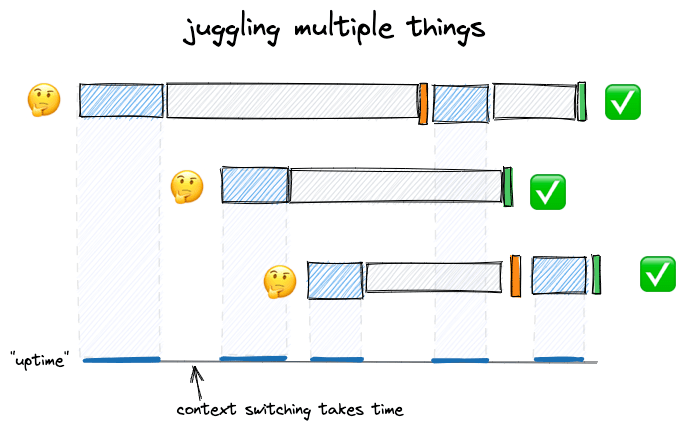
As our skills grow as an engineer, our ideas become more ambitious, and we seek to make greater changes. A journey most engineers go through at some point is working hard to create a large change and putting it up for review in one grand PR, only to experience a long wait and a lack of thoughtful feedback.
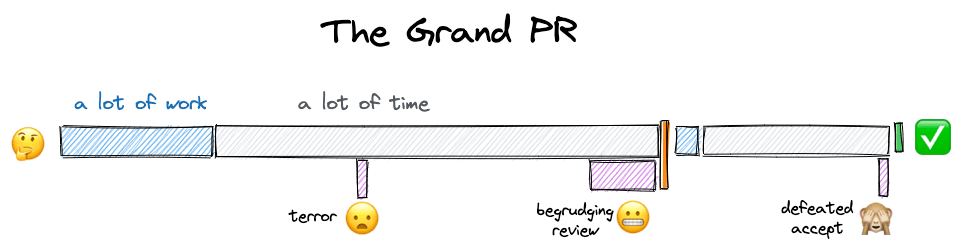
A Better Way
How do we optimize for the code review feedback loop when working on significant changes? By breaking down the large change into smaller dependent changes. This practice has been called “Stacked Diffs” or “Stacked PRs”:
- Stacked Diffs: Keeping Phabricator Diffs Small - Kurtis Nusbaum
- Stacked Diffs Versus Pull Requests - Jackson Gabbard
- In Praise of Stacked PRs - Ben Congdon
Doing this practice natively in Git & Github is cumbersome, so several tools have sprung up that make this flow much easier:

- Graphite - open-source CLI and a code review dashboard
- Super Pull Requests [SPR] - a command line tool
- Sapling - first-class support for editing and manipulating stacks of commits.
Even with these tools, creating stacked changes can be a novel way of working, so let us consider a few ways to think about producing these stacked changes.
Prototype then Split
One approach is to build first and deal with stacking later. This workflow is best if you are new to stacking diffs or are working on something that is speculative and might get thrown away. You can think about this workflow as a two-phase process, prototype, then split.
1) Prototype
- Focus on getting the idea working end to end; build it knowing you may throw it all or large portions away.
- Good local commit organization is helpful but not critical.
- Pay attention to the systemic challenges, local implementation details are easy to improve later. Being quick and dirty in this phase means you should be amenable to seeing how a different approach might work.
- The number of corners cut should match your level of uncertainty
- Keeping a draft PR in sync with your prototype can be useful as a remote backup as well as a means to get peer feedback on the overall approach.
- Try to break out any changes you make along the way that makes sense to merge absent the overall feature.
2) Split
The prototype works well enough to move forward, do a self-review, and clean things up.
- If you didn't manage your local commits well, rewriting things here is not a total loss. Things are usually better the second time you write them anyway.
- Work to break things out into as many small single thesis PRs as possible.
- Most of the review time should be spent on PRs that focus on any controversial changes.
Stacking as you Go
As you become more comfortable with stacked diffs, you will start to be able to manage the decomposition as you go. This workflow is best when you have confidence in your approach, as rearranging the stack can be taxing.
- ‘In progress’ commit(s) make up the "working edge" of the stack.
- As a reviewable unit of change is identified - it is extracted from the working edge, rebased below, and sent out for review.
- The working edge progresses forward as diffs lower in the stack are out for review.
- Interactive rebase is used heavily and is critical for updating mid-stack changes.
- Unless strictly dependent, accepted changes are rebased to the bottom and merged.
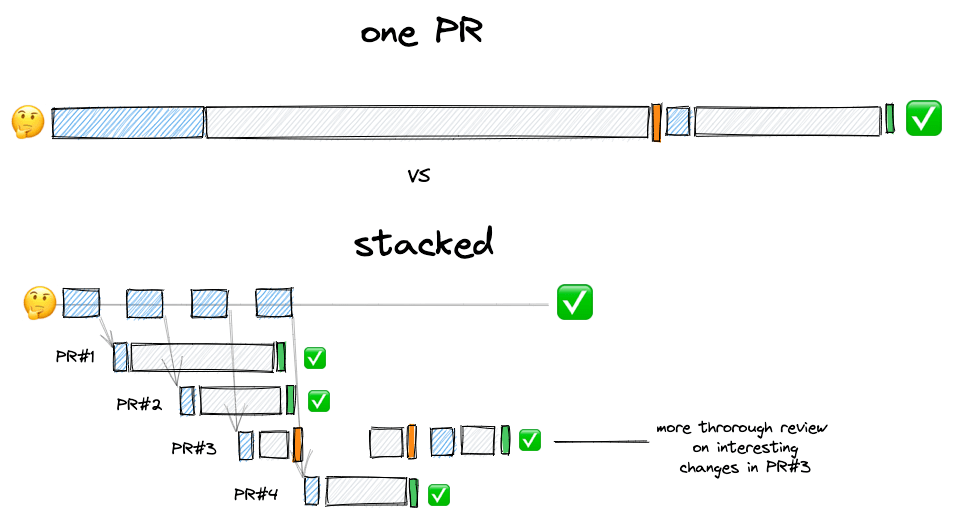
Break it Down
No matter how you go about it, breaking down a large change into smaller dependent changes is a powerful tool. Not only do you increase your output, but the care put into making changes easier to understand benefits every person to ever interact with it.
Most of our focus is on how a change affects the program, but considering how the change affects the other people working on the software is important for the sustainability of both the software and the people working on it. Much of programming can be an isolated exercise of man versus machine, but code review is our chance to cooperate with other people in the pursuit of bettering ourselves and our software.





.jpg)
.png)



.png)

