



See how US Foods transformed their chaotic data infrastructure into a reliable, scalable platform using Dagster. This Fortune 500 case study reveals how they achieved 99.996% uptime, eliminated data silos, and built a self-service platform that supports $24B in annual operations.
US Foods is one of America's leading foodservice distributors, currently offering over 350,000 products to approximately 250,000 restaurants and foodservice operators nationwide. With 30,000 employees across more than 70 locations, the company provides a broad and innovative food offering alongside comprehensive e-commerce, technology, and business solutions to help their customers succeed. As a major player in the foodservice industry with approximately $24 billion in annual revenue, US Foods was the 10th largest private company in the US until its IPO and now ranks at #119 in the Fortune 500 list — but their original data architecture was failing to scale with the company’s success.
Key Results
- Exceptional reliability: 99.996% platform uptime across nearly 750 production deployments
- Usability: Bespoke and completely unstandardized -> modern composable platform
- Execution excellence: Fragile, “ad-hoc” system with frequent failures -> Millions of jobs run with 99% execution success rate
- Visibility: duplicate code and data sets -> single pane of glass
Before he joined US Foods as a Machine Learning engineer, Lee Littlejohn was a restaurant chef. “Running a busy kitchen and building a data platform might not seem terribly connected, but I found that they're actually quite similar,” Lee says. “In either one, success is all about coordination, efficiency, quality under pressure, constantly juggling multiple stations, managing inventory, and ensuring consistent quality while maintaining rapid service.”
.png)
Technical debt, limited visibility, and siloed teams experiencing cognitive overload
When Lee arrived at US Foods, he found that the existing data architecture was creating significant technical and operational friction, to the point where US Foods was unable to fully leverage its data to drive business value. With a large organization processing massive volumes of data across multiple business units, these inefficiencies were increasingly costly and unsustainable:
- Technical debt and inconsistent infrastructure: The existing data architecture consisted of disconnected systems with no standardized approach to data pipeline development or management. Teams were using a mix of legacy ETL tools, custom Python scripts, and manual processes. “We had different teams using different tools, different processes, basically speaking different languages,” Lee says.
- Siloed team organization: Each team operated independently with their own environments, approaches, and tooling, creating redundancies and making it difficult to share data assets or establish consistent practices. “We had redundant work happening with duplicate code and data sets because teams simply didn't know what already existed.”
- Limited observability: There was no centralized way to monitor pipeline health, track failures, or understand dependencies between data assets. When issues occurred, extensive manual investigation was required to identify root causes: “One change could break something completely unrelated and troubleshooting was a nightmare.”
- Deployment challenges: The deployment process was manual and error-prone, with no consistent pattern for promoting code between environments. This led to frequent failures and difficulty tracking changes.
- Scaling limitations: As US Foods' data needs grew, the existing ad-hoc approach couldn't scale efficiently. Adding new teams or use cases required significant overhead and created additional silos.
- Cognitive overload for engineers: Without clear patterns and organization — and also lacking defined responsibilities and boundaries between teams – engineers spent excessive time understanding complex systems rather than delivering business value.
- Inadequate dependency management: Dependencies between data assets weren't explicitly tracked, making it difficult to understand the impact of changes or failures.
As a new employee, it was certainly challenging to get a solid handle on how the data platform worked. Jenkins jobs running random scripts on inconsistent schedules, fragmented dags, ingestion that nobody fully understood. Ad hoc scripts living on individual laptops, infrastructure soup…bottlenecks and fragile systems. One change could break something completely unrelated and troubleshooting was a nightmare.
Why US Foods chose Dagster
There are parallels between running a kitchen and managing a data platform: both require clear systems, defined responsibilities, and consistent patterns to operate efficiently. Tasked with transforming US Foods' fragile and fragmented data ecosystem, Lee Littlejohn needed a data orchestration platform that aligned with his vision for a more organized, efficient system.
Dagster's asset-based approach resonated with Lee's background as a chef, where the focus is on the final product rather than the steps to prepare it. This alignment between his culinary principles and Dagster's data philosophy was compelling: Dagster's structured approach enabled the creation of clear, repeatable patterns across the platform — similar to how standardized recipes ensure consistent results in a kitchen.
“Anybody who practices a craft loves their toolkit, and engineers are no different,” Lee explains. “We selected Dagster as an orchestrator for compelling reasons:
Assets over process: “Dagster’s asset-based orchestration focuses on the data product itself that you're creating, not just the process. This aligns perfectly with our goal of creating clear, visible data products.”
Built-in observability: “Dagster has a great UI, and real-time monitoring of pipeline health and performance that gives us unprecedented visibility into what's happening with our pipelines.”
Integration capabilities: “Dagster’s got extensive and extendable integrations that we can connect to virtually any system we need, including AWS, Snowflake, and container-based deployments.”
Consistency between environments: “Another huge advantage with Dagster is the parity between local and cloud development. You run the exact same code, same packages on your laptop that will run in production, which makes development and testing a lot smoother.
Single source of truth: Dagster provided a unified view of all data assets and their dependencies, establishing a definitive resource for understanding the data ecosystem. “Dagster gives us VISIBILITY, We can see what's running, what's failed, what depends on what, and so much more.”
Basically anything you can do in Python, you can do in Dagster. It's extremely flexible, and that flexibility is very powerful.
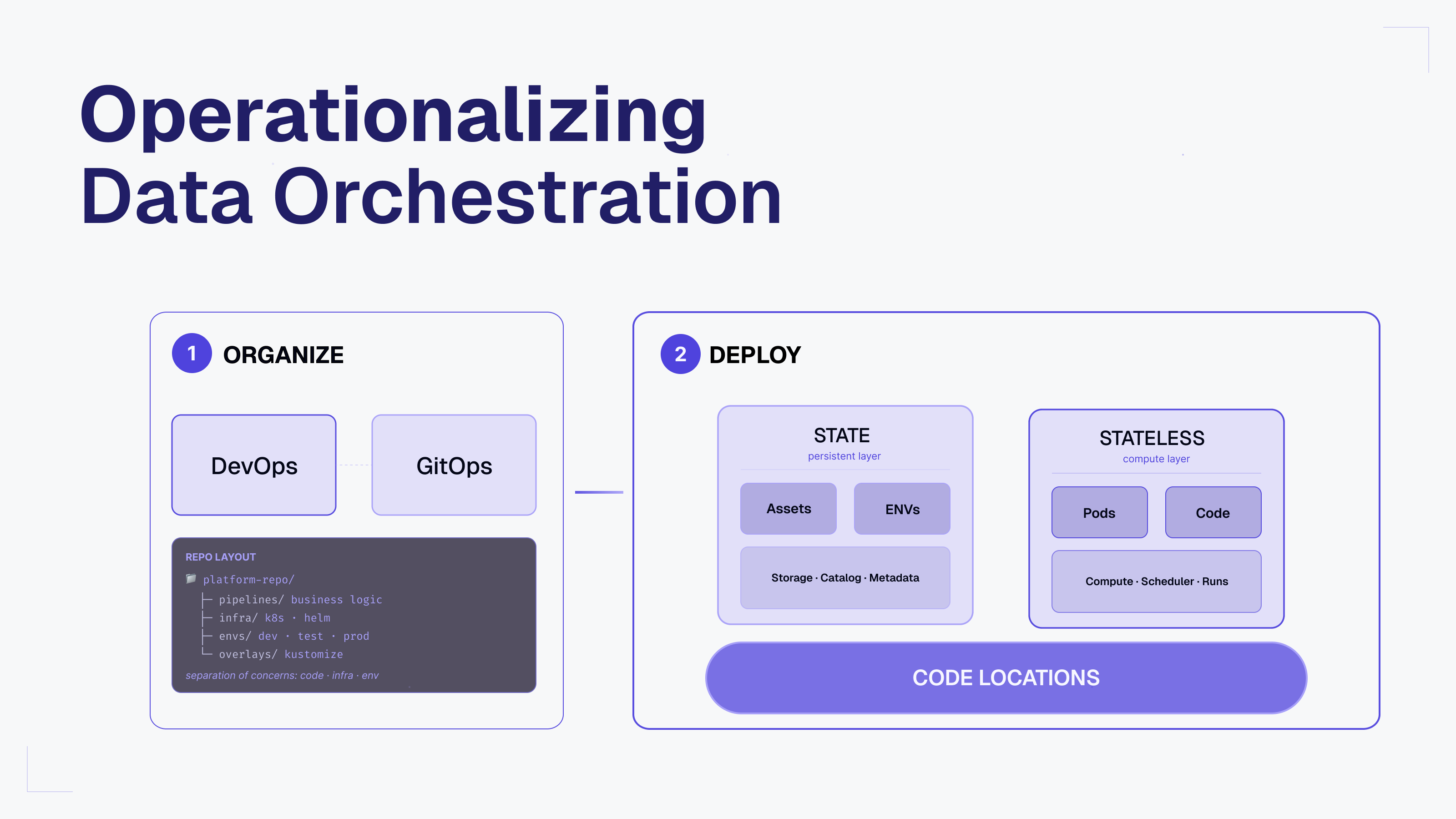
Building a modular, consistent data platform
Lee's team designed a comprehensive platform that addressed the full spectrum of the company’s data needs, using Dagster to build a data system that is accessible while maintaining consistency and providing clarity throughout.
Modern deployment architecture
The team established a containerized, infrastructure-as-code approach that supported clear boundaries between US Foods’ technical teams:
Poetry for dependency management. Team-specific dependency groups created clean separation between components while ensuring consistency. "Each team has their own dependency group, which maps directly to a stage in our Docker builds," Lee explains. Meanwhile, dependencies were strictly controlled and explicitly tracked to prevent conflicts.
Multi-stage Docker containerization. Lee oversaw a standardized build process that mapped directly to Poetry dependency groups. Base images included only the dependencies needed for each specific team, while build patterns were consistent across all teams. “This was major for reducing cognitive load for developers,” Lee says.
AWS CDK for infrastructure. Cloud infrastructure was defined with one stack per team for clear ownership. Infrastructure definitions were treated as code with proper version control and testing, and each team maintained their own stack while adhering to platform-wide standards.
GitHub Actions for CI/CD. The new platform implemented automated deployments with team-specific labels. Pull requests were automatically deployed to development environments for testing, and production deployments followed a consistent, automated pattern with appropriate safeguards.
Dagster implementation
Dagster served as the platform’s central orchestration engine, providing the essential structure and visibility central to Lee’s vision for the org’s new data platform. Each component maps directly to the next in a consistent pattern, maintaining team identity throughout the system.
Code location per team. One Dagster code location was established for each team to maintain clear boundaries. Teams worked independently within their own code locations, and the Platform team maintained visibility across all code locations.
Standardized patterns. Asset-oriented organization enabled US Foods to create consistent approaches to common problems. The team created reusable components for frequent operations, as well as standardized testing and deployment workflows.
Snowflake integration. Implemented one database per team per environment in Snowflake, with clear separation between development, staging, and production. Team-based access controls and resource allocation
Development workflow. Dagster was central to creating new processes that supported both independence and standardization. Engineers could test their changes locally before committing, and Dagster's local development capabilities allowed for rapid iteration.
Consistency through modularity. The platform maintained consistency by establishing clear patterns that mapped across components. Each component of the platform (dependencies, Docker builds, infrastructure, Dagster code locations, Snowflake databases) was organized by team, and this consistent structure reduced cognitive load for developers.
“Our configuration approach accommodates team differences while maintaining consistency, thanks to the Dagster resource construct and dependency injection," Lee says. “We define environment specific resources and configurations once, and then inject them into functions where they're needed.
As a result, the same code can run in different environments with appropriate configurations without requiring changes to the code itself — so you only code it once and it just works everywhere.
Exceptional reliability and operational excellence
Within a year of implementation, US Foods' Dagster-centered data platform has delivered remarkable results, transforming a once chaotic and failure-prone system into a transparent, accessible, and above all, reliable data ecosystem — one that significantly reduces operational overhead. For US Foods, their new data platform centered around Dagster has delivered:
Unparalleled reliability
The new platform’s structured, consistent approach has virtually eliminated downtime and reduced failures to a minimum:
- 99.996% platform uptime: Across nearly 750 production deployments, the platform has experienced 8 deployment failures — none of which resulted in actual downtime.
- 99% job success rate: Failures are quickly identified and addressed through comprehensive monitoring. The consistent patterns and clear ownership boundaries make troubleshooting faster and more effective.
- Proactive issue detection: Problems are identified before they impact business operations. Automated monitoring alerts teams to potential issues, and end-to-end data lineage makes it easy to understand the impact of any failure.
Enhanced developer productivity
The now-cohesive workflow reduces cognitive load on developers and has accelerated development cycles.
- Standardized development practices: All teams follow consistent patterns for development, testing, and deployment. Reusable components reduce duplication of effort across teams and new team members can quickly become productive due to the clear, consistent structure.
- Self-service capabilities: Teams can deploy independently without platform team intervention, and clear boundaries and patterns reduce the coordination overhead between teams.
- Clear visibility and understanding: A Dagster-centered unified control plane has made the data ecosystem transparent and accessible
Scalable, future-friendly platform
Migration from the previous system was accomplished with just 6 to 7 engineers, demonstrating the efficiency of applying consistent principles and thoughtful design patterns.
- Sustainable growth: The modular, team-based organization allows for expansion without increased complexity. New components can be added without disrupting existing workflows. Clear patterns make it easier to extend the platform to new use cases.
- Organizational alignment: The platform has helped bridge the gap between technical and business stakeholders. Clear visibility into data assets improves communication, and consistent organization makes it easier to map technical assets to business processes.
Operational efficiency
US Foods succeeded in reducing the overhead of managing a complex data ecosystem:
- Automated deployments: The CI/CD pipeline has eliminated manual deployment tasks with a consistent, reliable process for promoting changes to production, reducing time spent on operational tasks.
- Clear ownership: Defined responsibilities with enforced boundaries mean that, when issues arise, the responsible team is immediately clear. Coordination between teams “has never been easier.”
- Streamlined troubleshooting: When problems do occur, they're resolved more quickly because clear system structure and visibility makes it easy to identify root causes.
Out of almost 750 full production deployments, we have had less than eight failures and none of those resulted in actual downtime. I think that's pretty good. And four of those were me and one of my coworkers playing a little fast and loose and trying to get around our own branch protections.
Lee recently did a deep dive with us about around their Dagster use case and implementation. Watch the full session here:





.jpg)
.png)


.png)

