


Data mining definition:
Data mining is the process of extracting useful information, patterns or insights from large volumes of data using various statistical methods and machine learning algorithms. It is an integral component of the data pipeline, often occurring after data cleaning and preprocessing stages, and before data visualization and reporting stages. Data mining techniques are used to build predictive or descriptive models, perform segmentation, clustering, anomaly detection, or discover association rules, among other tasks, which support data-driven decision-making processes in various domains.
Note that, while we provide a definition above, The term "Data Mining" is sometimes used interchangeably with machine learning, statistics, or predictive analytics, but other times it is used to refer to a specific subset of techniques within those fields.
Example of data mining in Python
Let's use the Pandas library for data manipulation, the Scikit-Learn library for machine learning, and the Seaborn library for data visualization. For the purposes of this example, let's use the Iris dataset, a classic dataset in the field of machine learning that includes measurements for 150 iris flowers from three different species.
Please note that you need to have the necessary Python libraries installed in your Python environment to run this code.
# import necessary libraries
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import seaborn as sns
import matplotlib.pyplot as plt
# load the iris dataset
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(data=iris.data, columns=iris.feature_names)
data['target'] = iris.target
# explore the data
print(data.head())
# visualize the data
sns.pairplot(data, hue="target")
plt.show()
# prepare data for model training
X = data.iloc[:, :-1] # features
y = data['target'] # target
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# train a RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
# evaluate the model
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))This example includes several steps common in data mining workflows:
- Loading and inspecting the data.
- Visualizing the data to understand relationships between features and the target variable.
- Preparing the data for machine learning, including splitting it into training and testing datasets.
- Training a machine learning model on the training data.
- Evaluating the model on the testing data to understand its performance.
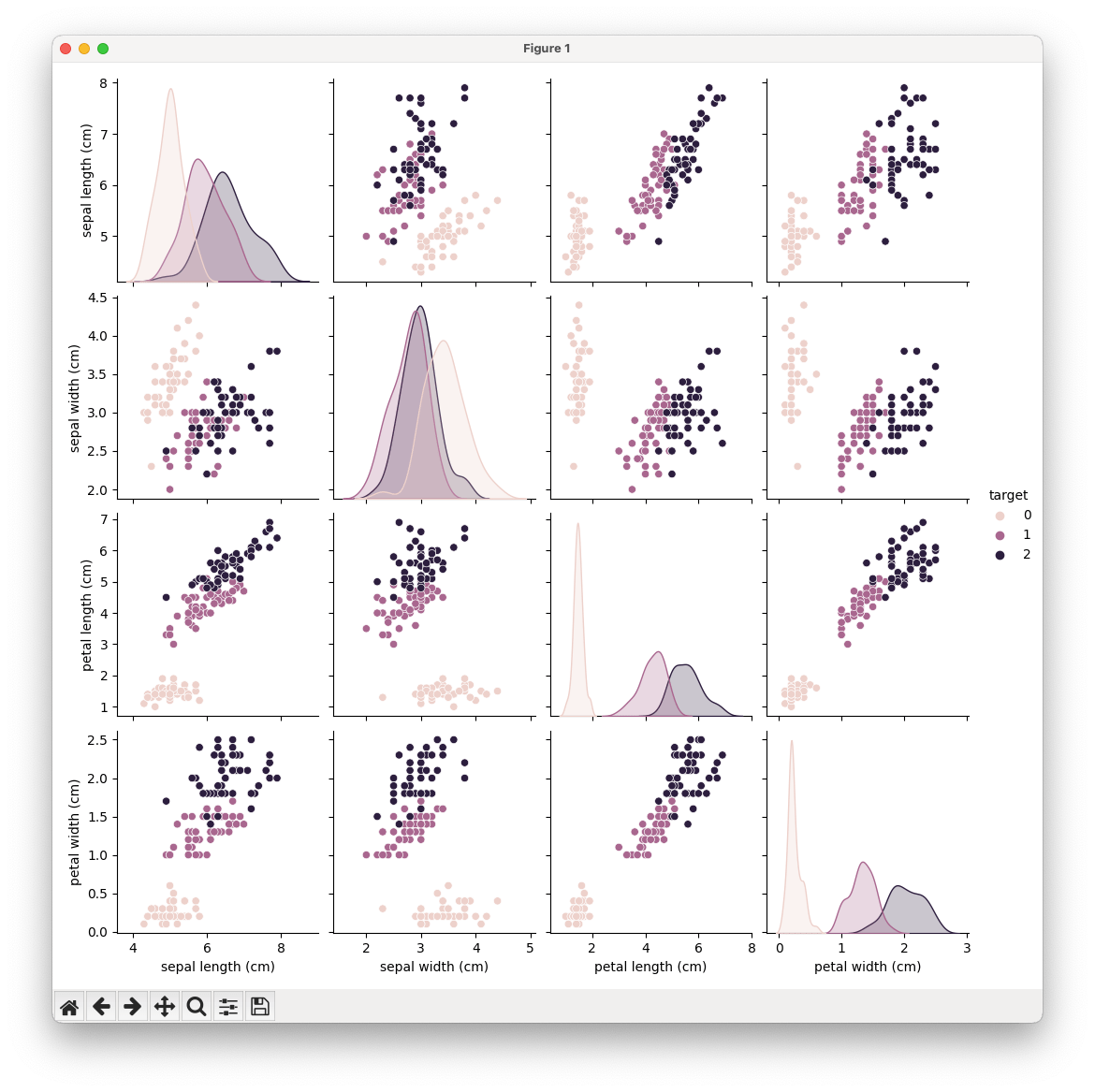
It will also print out the data to the terminal:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) target
0 5.1 3.5 1.4 0.2 0
1 4.9 3.0 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5.0 3.6 1.4 0.2 0
precision recall f1-score support
0 1.00 1.00 1.00 10
1 1.00 1.00 1.00 9
2 1.00 1.00 1.00 11
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30While this example provides a simple demonstration of data mining in Python, real-world data mining tasks are typically much more complex and often require significant data cleaning, feature engineering, and model tuning.
