




Empowering engineers with flexibility and analysts with accessibility
Developing simple data pipelines often means hours of boilerplate: wiring integrations, setting up configs, and stitching together monitoring. Even for well-understood use cases, the work drags engineers away from the business logic that actually matters.
On the flip side, low-code tools promise speed. They make it easy to drag-and-drop a solution together in minutes. But the moment you need to express real complexity, custom transformations, nuanced dependencies, or domain-specific logic, the tool that once felt freeing suddenly becomes a cage.
This is the trap teams find themselves in. High-code puts all the responsibility on experts, leaving non-technical teammates on the sidelines. Low-code starts simple but hits a ceiling the moment you try to model non-trivial business logic. Both paths create friction, just in different places.
Why High Code Falls Short
Pure high-code approaches solve for flexibility but often at the expense of accessibility. With full control comes full responsibility:
- Steep learning curves make it difficult for new team members or less technical stakeholders to contribute.
- Boilerplate and complexity slow down initial development, even for common, well-understood use cases.
- Duplication of effort emerges as every team reinvents patterns for the same integrations, like connecting to a data warehouse, orchestrating models, or monitoring pipelines.
In practice, this means experts spend precious time on wiring and scaffolding instead of business logic, while non-experts are left out altogether. High-code maximizes power, but not productivity.
Why Low Code Falls Short
Low-code solutions, on the other hand, rarely deliver depth. By design, they simplify. That simplicity is attractive for getting started, but it comes at the cost of flexibility.
The problem shows up the moment you need to move beyond basic use cases. An analyst might be able to drag-and-drop a pipeline together in minutes—but as soon as they need to add a conditional transformation, express nuanced dependencies, or integrate with a custom API, the tool that once felt empowering becomes a cage. Quick wins stall out, teams split across different toolsets, and the work produced in one environment can’t be reused in the other. What began as a shortcut ends up creating silos and dead ends.
Low-code maximizes accessibility, but it does so by flattening the very complexity that makes real-world systems work. The ceiling comes fast, and once you hit it, there’s nowhere to go.
Attempts at Combining High and Low
To bridge the gap, some teams try to build their own domain-specific languages (DSLs) on top of high-code systems. The idea is to make complex tools more approachable for teammates who don’t want to dive into the full API.
But DSLs almost always fall into one of two traps:
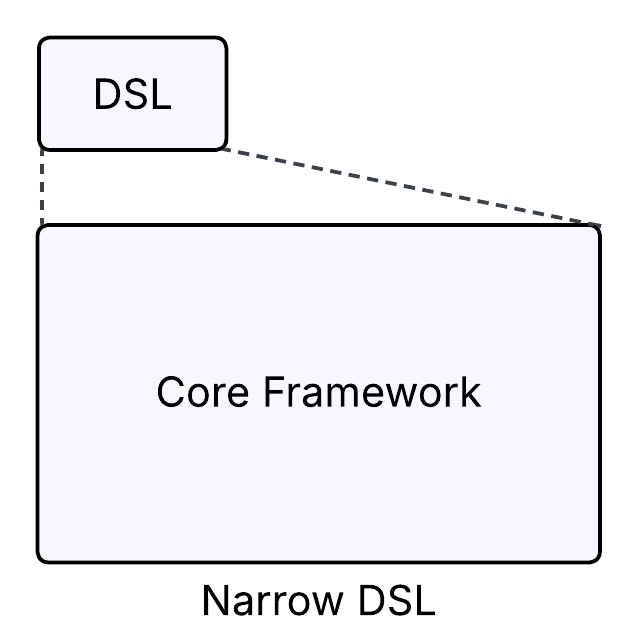
- Narrow DSLs hide too much. At first, they feel simple and accessible, but the moment someone needs to go beyond the basics, they hit a wall. Frustration sets in, and users abandon the DSL for the underlying system.
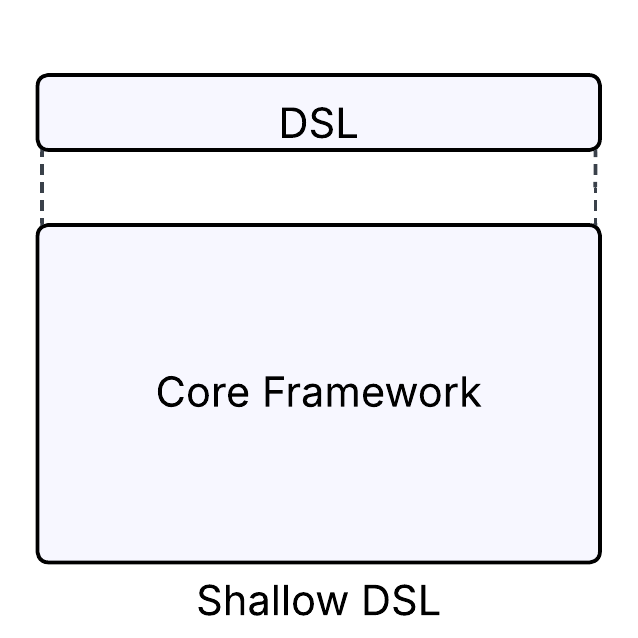
- Shallow DSLs expose too much. They try to re-surface every feature of the underlying system, bloating the interface until it’s just a clunkier version of what already existed.
In both cases, the outcome is the same: engineers spend huge amounts of time maintaining a parallel abstraction that neither lowers the barrier to entry nor delivers real long-term value.
What’s needed isn’t another fragile layer, but a way to package domain expertise into reusable, discoverable building blocks—ones that newcomers can pick up quickly, and experts can refine without limits. That’s exactly the role Components are designed to play.
Dagster’s Approach: Components
At Dagster, we’ve seen data engineers push the framework in creative ways. With Dagster Components, we’re now watching teams design platforms that bridge the gap between high-code and low-code in ways that feel both natural and powerful.
What makes Components unique is its philosophy. Instead of adhering to the restraints of low or high code, components let teams combine domain knowledge with Dagster’s primitives to create intuitive, purpose-built entry points. An ingestion pipeline, a machine learning model, a reporting job, each becomes a first-class, discoverable unit in Dagster.
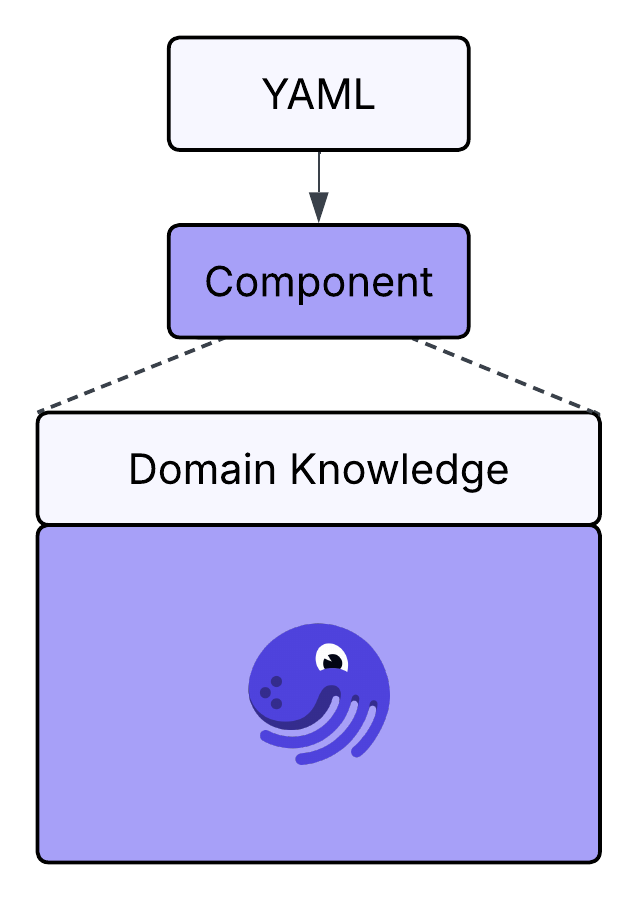
This opens the door for everyone who touches the data platform:
- Newcomers can get productive quickly, using components that encode best practices.
- Experts can refine, extend, or even bypass components entirely, while staying inside the Dagster ecosystem.
- Teams avoid the split of “parallel tools,” where low-code and high-code users drift into separate worlds.
The YAML interface makes it simple to encapsulate complex logic in just a few lines, while still leaving room for deep customization. Unlike Airflow plugins, which often feel like thin wrappers around Python code and still demand significant effort, Dagster Components expose reusable building blocks that newcomers can configure without wading into the full API. And while dbt macros offer powerful templating for SQL workflows, they lack the breadth to unify ingestion, orchestration, and ML use cases.
Instead, high-code and low-code reinforce each other in Dagster Components. Abstractions provide rich customization that allow simple inputs to trigger complex Pythonic transformations so users can harness powerful logic without needing to understand implementation detail.
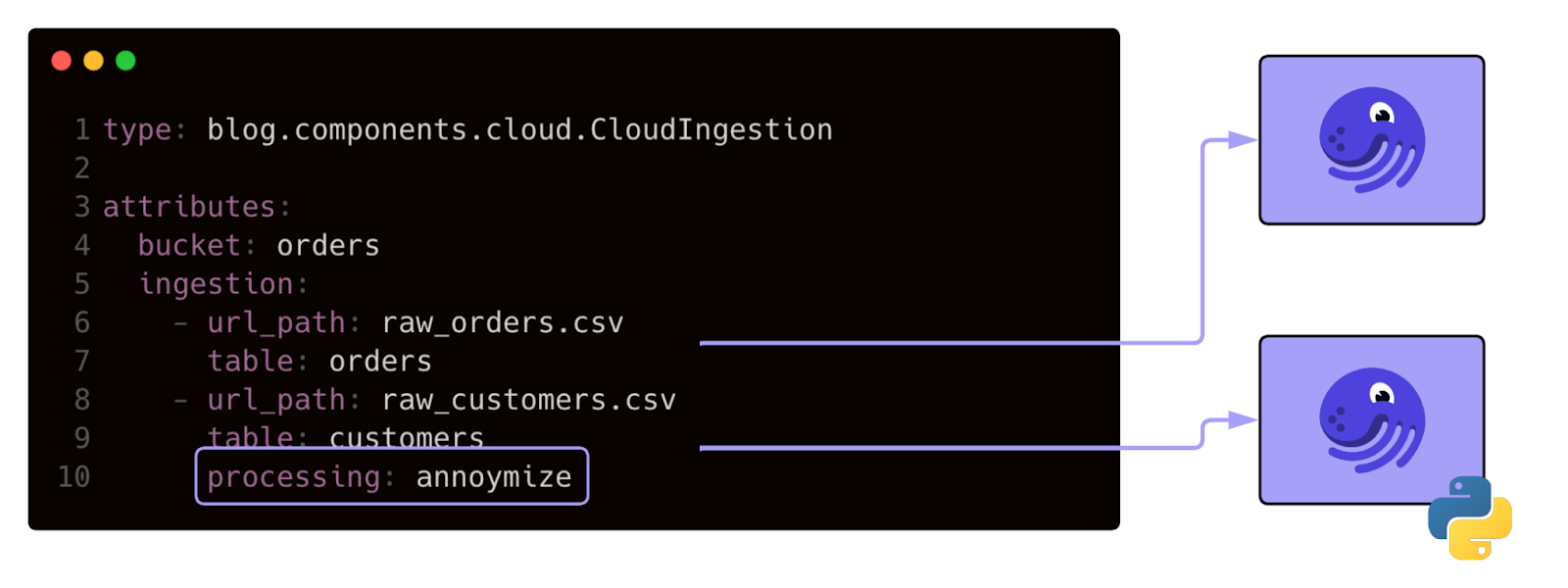
A centralized interface for building Dagster objects not only opens the platform to more users, it also streamlines configuration. Many teams use Components to share values across systems with YAML, dynamically injecting template variables from existing configs. The result is a single, easy-to-understand source of truth for configuration.
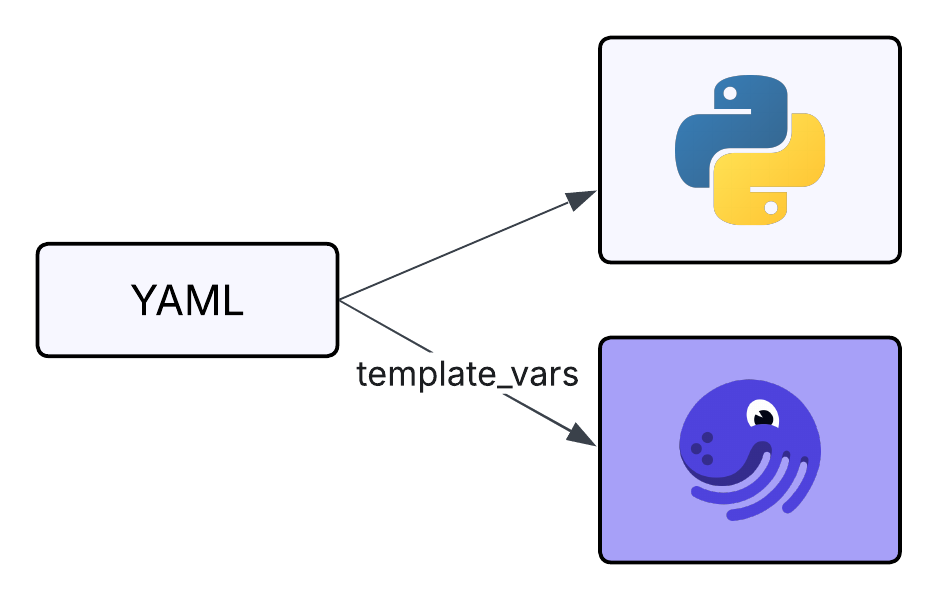
High and Low Code, Together
Components are reshaping how teams build on Dagster. Simple abstractions make it easy to get started, while rich APIs ensure experts never hit a ceiling.
The result is more than just efficiency. It’s a cultural shift: high-code and low-code no longer pull in opposite directions. Instead, they amplify one another, accelerating collaboration and turning complexity into clarity. With components, the data platform becomes a place where everyone can build, extend, and innovate together.





.jpg)
.png)


.png)

