




How I took an excellent lakehouse tutorial and made it even better with modern data orchestration
The Inspiration
I recently came across this fantastic article: Build a Lakehouse on a Laptop with dbt, Airflow, Trino, Iceberg, and MinIO by the team at Data Engineer Things. It’s an excellent tutorial that demonstrates how to build a complete lakehouse stack on your laptop using modern open-source tools.
After reading through their implementation, I thought: “This is great, but what if I could make it even better with Dagster?”
So I decided to implement the same lakehouse architecture using Dagster instead of Airflow, and the results were impressive. I highly encourage you to read the original article first, try their implementation, and then compare it with what I’ve built here.
Why This Comparison Matters
Both implementations use the same core lakehouse technologies:
- MinIO for S3-compatible object storage
- Trino as the distributed SQL query engine
- Iceberg for ACID table format
- Nessie for data catalog and versioning
- dbt for analytics transformations
The key difference? The orchestration layer. This comparison highlights why choosing the right orchestrator can dramatically improve your data platform’s capabilities.
What I Improved Upon
1. Smart Partitioning with Time Windows
Original Article: Basic daily data processing without sophisticated partitioning.
My Enhancement: Dagster’s TimeWindowPartitionsDefinition with proper partition key management
from dagster import TimeWindowPartitionsDefinition
daily_partitions = TimeWindowPartitionsDefinition(
cron_schedule="0 0 * * *", # Daily boundary at midnight
start="2024-01-01",
end="2027-01-01", # Future-proof partitioning
fmt="%Y-%m-%d",
)This enables:
- ✅ Backfill capabilities — Process historical data efficiently
- ✅ Incremental processing — Only process new partitions
- ✅ Partition-aware sensors — Trigger only when new data arrives
- ✅ Selective reruns — Reprocess specific date ranges
2. Event-Driven Architecture with Sensors
Original Article: Time-based scheduling only.
My Enhancement: Intelligent sensors that monitor MinIO for new data
@sensor(
minimum_interval_seconds=60,
job_name="daily_pipeline",
required_resource_keys={"minio"}
)
def sales_sensor(context: SensorEvaluationContext):
"""Monitor MinIO for new sales files and trigger processing."""
minio = context.resources.minio
# Check for new files in the last 7 days
for days_back in range(1, 8):
date = datetime.now() - timedelta(days=days_back)
date_str = date.strftime("%Y-%m-%d")
prefix = f"raw/sales/dt={date_str}/"
file_count = minio.count_objects(prefix)
if file_count > previous_count:
yield RunRequest(
partition_key=date_str,
tags={"trigger": "new_data_detected"}
)
Benefits:
- ✅ React to data arrival — No waiting for scheduled times
- ✅ Cursor-based tracking — Remember what’s been processed
- ✅ Efficient resource usage — Only run when needed
- ✅ Multiple sensors — Different logic for different data types
3. Pure SQL Lakehouse Pattern
Original Article: Uses Python for data loading.
My Enhancement: Pure Trino SQL with Hive to Iceberg CTAS pattern
@asset(
required_resource_keys={"trino"},
kinds={"trino", "hive", "iceberg"}
)
def product_category_data(context: AssetExecutionContext):
"""Create Iceberg table from MinIO using pure SQL."""
trino = context.resources.trino
# Step 1: Create Hive external table
trino.execute_statement(""" CREATE TABLE hive.raw.product_category ( category_id BIGINT, category_name VARCHAR, created_date TIMESTAMP ) WITH ( external_location = 's3a://lake/raw/product_category/', format = 'PARQUET' ) """)
# Step 2: CTAS to Iceberg managed table
trino.execute_statement(""" CREATE TABLE iceberg.raw.product_category WITH (format = 'PARQUET') AS SELECT * FROM hive.raw.product_category """)Advantages:
- ✅ Scalable — Leverage Trino’s distributed processing
- ✅ No Python bottlenecks — Pure SQL operations
- ✅ Better performance — Direct data transfer between catalogs
- ✅ Industry standard — Follows lakehouse best practices
4. Comprehensive Data Quality Framework
Original Article: Basic dbt tests.
My Enhancement: Multi-layered data quality with Dagster asset checks
@asset_check(asset="product_category_data", required_resource_keys={"trino"})
def product_category_completeness(context: AssetExecutionContext):
"""Ensure product category data meets quality standards."""
trino = context.resources.trino
result = trino.execute_query("SELECT COUNT(*) FROM iceberg.raw.product_category")
count = result[0][0] if result else 0 passed = count >= 5 # Should have at least 5 categories return AssetCheckResult(
passed=passed,
metadata={"category_count": count},
description=f"Product categories: {count} (expected >= 5)" )Plus:
- ✅ Freshness policies — SLA monitoring for data freshness
- ✅ Asset checks — Programmatic data quality validation
- ✅ dbt test integration — Leverage existing dbt tests
- ✅ Lineage-aware quality — Quality checks follow data dependencies
5. Advanced Orchestration Features
Original Article: Basic DAG scheduling.
My Enhancement: Sophisticated job definitions with asset selection
# Flexible job definitions
setup_job = define_asset_job(
name="setup_job",
selection=AssetSelection.keys(
["raw", "product_category_data"],
["raw", "product_subcategory_data"],
["raw", "product_data"],
["raw", "territory_data"]
),
description="Load dimension data from MinIO into Iceberg tables")
daily_pipeline = define_asset_job(
name="daily_pipeline",
selection=AssetSelection.keys(["raw", "daily_sales_data"]) | AssetSelection.keys(["curated", "product_dim_simple"]) | AssetSelection.keys(["marts", "sales_summary"]),
partitions_def=daily_partitions,
description="Daily: Sales data → dbt curated → dbt analytics")Features:
- ✅ Asset selection — Run specific subsets of your pipeline
- ✅ Dynamic jobs — Jobs that adapt based on upstream changes
- ✅ Partition-aware jobs — Handle time-series data elegantly
- ✅ Resource optimization — Fine-tune resource usage per job
6. Modern Development Experience
Original Article: Traditional setup.
My Enhancement: Modern Dagster tooling with dg CLI
# Modern project structure
dg dev # Start development server
# - Auto-reload on code changes
# - Rich web UI with lineage visualization# - Integrated logs and monitoring
# - Asset catalog with metadata# Modern project structuredg dev # Start development server# - Auto-reload on code changes# - Rich web UI with lineage visualization# - Integrated logs and monitoring# - Asset catalog with metadata
Developer benefits:
- ✅ Auto-discovery — Assets automatically detected
- ✅ Hot reloading — See changes instantly
- ✅ Rich UI — Visual pipeline development
- ✅ Integrated testing — Test assets individually
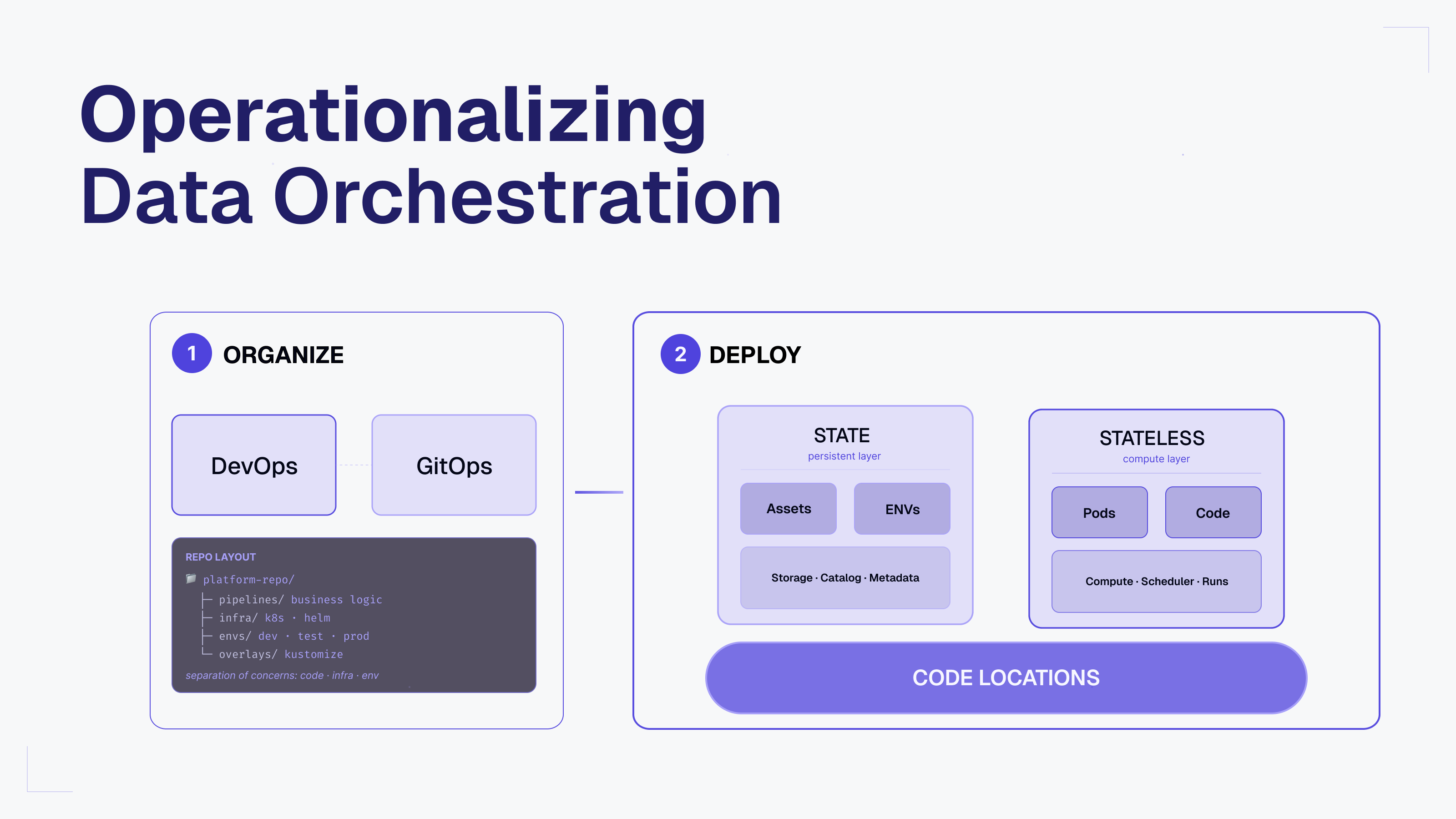
Architecture Comparison
Original Approach (Airflow)
My Enhanced Approach (Dagster)
The Technology Stack
Both implementations share the same robust foundation:
Infrastructure Layer
- Docker Compose — Local development environment
- MinIO — S3-compatible object storage
- Trino — Distributed SQL query engine
- Nessie — Data catalog with Git-like versioning
- Iceberg — Open table format with ACID properties
Data Layer
- Raw Zone — Parquet files in MinIO (
s3://lake/raw/) - Curated Zone — Iceberg tables with proper schemas
- Analytics Zone — dbt-transformed dimensional models
Orchestration Layer
- Original: Apache Airflow
- Enhanced: Dagster with modern features
Why This Matters for Your Organization
Operational Excellence
- Reliability: Event-driven processing reduces missed data
- Efficiency: Smart partitioning minimizes compute waste
- Visibility: Rich monitoring and lineage tracking
- Maintainability: Clear asset definitions and dependencies
Developer Productivity
- Faster iteration: Hot reloading and integrated testing
- Better debugging: Detailed logs and execution context
- Easier onboarding: Self-documenting asset catalog
- Modern tooling: Industry-standard development experience
Business Value
- Faster time-to-insight: Data available when it arrives
- Higher data quality: Comprehensive validation framework
- Lower operational costs: Efficient resource utilization
- Future-proof architecture: Built on modern data stack
Getting Started
I encourage you to:
- Read the original article — It’s an excellent introduction to lakehouse concepts
- Try their implementation — Get familiar with the core technologies
- Compare with the Dagster version — See the orchestration differences
- Experiment with both — Understand the trade-offs
Quick Start with My Implementation
# Clone and start the infrastructure
git clone https://github.com/eric-thomas-dagster/dagster-lakehouse
cd dagster-lakehouse
./start_lakehouse.sh
# Generate sample data
python generate_adventureworks_data.py
# Start Dagster
cd dagster_project
dg devThen visit:
- Dagster UI: http://localhost:3000
- Trino: http://localhost:8080
- MinIO Console: http://localhost:9000
Conclusion
The original lakehouse article provides an excellent foundation for understanding modern data architecture. By enhancing it with Dagster’s advanced orchestration capabilities, I’ve created a more robust, scalable, and maintainable data platform.
The key insight? Technology choice matters at every layer. While the core lakehouse technologies (MinIO, Trino, Iceberg, dbt) provide the foundation, the orchestration layer determines how effectively you can leverage them.
Dagster’s asset-centric approach, combined with its sensors, partitioning, and data quality features, creates a data platform that’s not just functional, but truly production-ready.
Try Both Approaches
I strongly recommend experiencing both implementations:
- The original showcases excellent lakehouse fundamentals
- My enhanced version demonstrates modern orchestration capabilities
The comparison will give you invaluable insights into how orchestration choices impact your data platform’s capabilities, maintainability, and developer experience.
Ready to build your own enhanced lakehouse? Check out my implementation at https://github.com/eric-thomas-dagster/dagster-lakehouse and let me know what you think!
Additional Resources





.jpg)
.png)


.png)

