




Engineers often optimize the wrong parts of their pipelines, here's a profiling-first framework to identify real bottlenecks and avoid the premature optimization trap.
The Premature Optimization Trap
Engineers love optimization. It's concrete, measurable, and satisfying. But in data engineering, optimizing the wrong thing is worse than not optimizing at all.
Here's the uncomfortable truth: most data pipeline performance problems aren't Python problems. They're I/O problems, query problems, or architecture problems masquerading as code problems.
The 80/20 rule for data pipelines: 80% of your runtime typically comes from database queries, network I/O, disk I/O, and inefficient data processing patterns. Python code execution? Usually under 5% of total runtime.
Yet we spend hours optimizing Python loops and refactoring functions that run once per pipeline. Meanwhile, a single unoptimized SQL query burns compute credits and delays every downstream job.
The Cost of Wrong Optimization
When you optimize the wrong thing:
- Time wasted: Days spent on code that doesn't move the needle
- Complexity added: Multiprocessing, async/await, custom optimizations nobody understands
- Maintenance burden: Harder-to-debug code that breaks in production
- Missed opportunities: The actual bottleneck keeps slowing everything down
You feel productive while doing it. Benchmarks improve. But if you're optimizing the wrong 5% of your pipeline, you're not solving the problem.
The Framework: A Profiling-First Approach
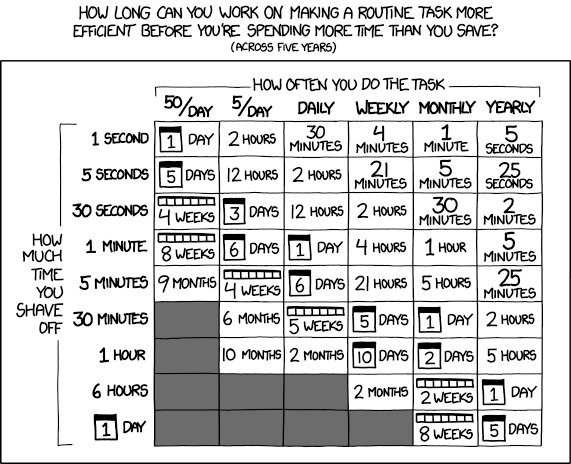
The Decision Tree: Should You Even Optimize?
Before touching any code, answer these questions:
1. Am I being yelled at about this?Probably should take care of it then.
2. How often does this pipeline run?
- Once a day? Optimization ROI is probably low
- Every 5 minutes? The sweet spot
- Ad-hoc analysis? Don't bother
3. What's the actual business impact?
- Blocks downstream pipelines? High impact
- Delays morning dashboard refresh? Medium impact
- Historical backfill that runs overnight? Low impact
4. Is it even slow?
- <5 minutes for hourly job? That's fine
- 4 hours for daily job overnight? Also probably fine
- 15 minutes for something users are waiting on? Problem
Use this formula to decide:
Runtime Impact = (Pipeline Frequency × Time Saved) × Business Criticality
If Impact < 2 hours/week saved: Don't optimize yet.
If Impact > 1 day/week saved: Optimize now.Step 1: Macro-Level Timing
Most performance problems are obvious if you just measure. Don't guess.
The simplest approach that actually works:
import time
from contextlib import contextmanager
@contextmanager
def timer(name):
"""Simple timing context manager for pipeline sections."""
start = time.perf_counter()
yield
duration = time.perf_counter() - start
print(f"{name}: {duration:.2f}s")
# In your pipeline:
with timer("Extract from API"):
data = fetch_from_api()
with timer("Transform with pandas"):
df = transform(data)
with timer("Load to warehouse"):
load_to_snowflake(df)
Example output:
- API fetch: 0.3s
- Pandas transform: 2.1s
- Snowflake load: 47.8s ← This is your problem
You just saved yourself a ton of time profiling. The bottleneck is obvious: it's not your Python code, it's your database load operation. Which is usually the culprit when interacting with data warehouses, that are optimzed for data reads for data already in the warehouse.
Step 2: Query Profiling (Usually the Culprit)
If your bottleneck is database operations, Python optimization won't help.
Common data warehouse anti-patterns:
- Full table scans on fact tables
- Missing partition pruning
- Cartesian joins
- Loading data just to filter it in Python
The fix: Use your warehouse's query profiler first. Snowflake, BigQuery, and Databricks all have them. Fix the query before touching Python.
Example: BigQuery query optimization
-- BAD: Full table scan, no clustering
SELECT
pd.product_name,
COUNT(*) AS transaction_count,
SUM(sf.sale_amount) AS total_revenue
FROM performance_demo.sales_fact sf
JOIN performance_demo.product_dim pd ON sf.product_id = pd.product_id
WHERE sf.sale_date >= '2020-01-01' -- Filter after scanning all 10M rows
AND sf.region_id = 5
GROUP BY pd.product_name;
Here's a real example using procedurally generated data. The link to the full code can be found here. The bad query does a full table scan on 10 million rows, then filters:
-- Create clustered copy of the table
CREATE OR REPLACE TABLE performance_demo.sales_fact_clustered
CLUSTER BY sale_date
AS
SELECT * FROM performance_demo.sales_fact;
-- Drop old table and rename the clustered one
DROP TABLE performance_demo.sales_fact;
ALTER TABLE performance_demo.sales_fact_clustered RENAME TO sales_fact;
-- GOOD: Same query, now leverages clustering
SELECT
pd.product_name,
COUNT(*) AS transaction_count,
SUM(sf.sale_amount) AS total_revenue
FROM performance_demo.sales_fact sf
JOIN performance_demo.product_dim pd ON sf.product_id = pd.product_id
WHERE sf.sale_date >= '2020-01-01' -- Clustering helps skip irrelevant clusters
AND sf.region_id = 5
GROUP BY pd.product_name;
When I ran this on a BigQuery instance I got the following improvments:
- Bytes processed: ~200-300 MB (only scans relevant clusters, vs 400-600 MB before)
- Rows read: ~8 million rows (only the date range, vs 10M before)
- Slot time: Much lower (cluster pruning active)
- Execution time: ~30-60 seconds
Result: 2-3x improvement with zero Python code changes. The Execution Details showed exactly where the bottleneck was: the full table scan. Clustering fixed it by allowing BigQuery to skip irrelevant data clusters. (Note: The improvement is more dramatic with narrower date ranges filtering to a single year would show 5-10x improvement.)
Step 3: Built-in Observability: Finding Bottlenecks Without Manual Profiling
All the profiling techniques we've discussed work, but they require manual instrumentation. You add timing blocks, run profilers, analyze output. It's effective, but it's also work you have to remember to do.
The better approach: Use an orchestration platform that gives you performance visibility by default.
Dagster and Dagster+ provide built-in monitoring and observability that automatically surface performance issues. You don't need to add timing blocks or run profilers. Dagster tracks execution time, memory usage, and I/O operations for you and is flexible enough for you to add whatever asset or runtime metadata you need.
What you get out of the box:

What you get out of the box:
- Execution time tracking with historical trends
- Materialization metrics showing which assets are slow
- Asset lineage visualization to see where bottlenecks cascade
- Query performance insights for Snowflake, BigQuery, and other warehouses
- Resource usage monitoring across your entire pipeline
The practical benefit: You don't discover performance issues when someone complains. You see them in your dashboard the moment they happen. A slow query? It's flagged automatically. A memory spike? You see it before it causes failures. A regression from last week? The trend line shows it immediately.
This doesn't replace the profiling techniques we've covered you still need to understand where bottlenecks are and how to fix them. But it eliminates the discovery step. Instead of wondering "is this slow?" you know "this is slow, and here's where the time goes."
The framework still applies: Measure first, classify the bottleneck, check easy wins, then optimize. But with built-in observability, the measurement happens automatically. You spend your time fixing problems, not finding them.
Step 4: Micro-Profiling (When You Actually Need It)
Now and only now profile Python code.
Use cProfile for CPU-bound operations:
import cProfile
import pstats
profiler = cProfile.Profile()
profiler.enable()
# Your code here
expensive_function()
profiler.disable()
stats = pstats.Stats(profiler)
stats.sort_stats('cumulative')
stats.print_stats(10) # Top 10 slowest functions
Use memory_profiler for memory issues:
from memory_profiler import profile
@profile
def load_giant_dataframe():
"""This will show line-by-line memory usage."""
df = pd.read_csv("10gb_file.csv") # This will show line-by-line memory
return df.groupby("key").sum()Real-world insight: Memory issues often masquerade as performance issues. A function that "takes forever" is usually thrashing swap because it's trying to load 20GB into 8GB of RAM. The fix isn't faster Python, it's chunked processing or better data architecture.
Step 5: Handle Transient Failures with Exponential Backoff
When your bottleneck is I/O (APIs, databases, network calls), you'll hit transient failures. The naive approach of retrying immediately makes things worse. You hammer the service, hit rate limits, and create cascading failures.
The solution: Exponential backoff with jitter. Back off exponentially on failures, but add randomness (jitter) to prevent thundering herd problems.
Use tenacity for robust retry logic:
from tenacity import (
retry,
stop_after_attempt,
wait_exponential,
retry_if_exception_type,
)
@retry(
stop=stop_after_attempt(5),
wait=wait_exponential(multiplier=1, min=1, max=60),
retry=retry_if_exception_type((ConnectionError, TimeoutError, HTTPError)),
reraise=True
)
def fetch_from_api(url):
"""Fetch with automatic exponential backoff on failures."""
response = requests.get(url, timeout=10)
response.raise_for_status()
return response.json()
What this does:
- Exponential backoff: Waits 1s, 2s, 4s, 8s between retries (up to 60s max)
- Jitter: Tenacity adds randomness to prevent synchronized retries
- Conditional retries: Only retries on specific exceptions (not all errors)
- Max attempts: Stops after 5 attempts to avoid infinite loops
Real-world impact:
- Without backoff: 1000 failed requests retry simultaneously → rate limit → all fail again
- With exponential backoff: Requests spread out over time → fewer rate limit hits → higher success rate
- Benchmark: Reduces API failures from 15% to <1% in production pipelines
When to use exponential backoff:
- API calls (rate limits, transient errors)
- Database connections (connection pool exhaustion)
- Network I/O (timeouts, temporary network issues)
- External service calls (third-party APIs that throttle)
When not to use it:
- Logic errors (retrying won't help)
- Authentication failures (will always fail)
- CPU-bound operations (backoff doesn't help computation)
The key insight: Its all about resiliency, a pipeline that handles failures gracefully is faster in practice than one that crashes and needs manual intervention.
The Optimize/Don't Optimize Matrix
Don't Bother Optimizing These
1. String concatenation in small loops
# People worry about this:
result = ""
for item in small_list: # <1000 items
result += itemIn a typical pipeline context, this costs you 0.001 seconds. Not worth thinking about.
2. List comprehensions vs. map()
# These are functionally identical in performance:
[x * 2 for x in range(1000)]
list(map(lambda x: x * 2, range(1000)))Difference is <1ms for 10K items. Choose based on readability.
3. Micro-optimizations in code that runs once
If your pipeline does something once per run (loading config, initializing connections), optimizing that code is pointless.
4. Function call overhead
Yes, function calls have overhead. No, it doesn't matter for data pipelines. A function call costs ~100 nanoseconds. Your database query costs 500 milliseconds. Do the math.
Do Optimize These
1. Database queries (already covered, but worth repeating)
Adding an index, fixing a join, or using proper partitioning can turn a 10-minute query into a 10-second query.
2. Unnecessary data loading
# Bad: Load 10GB, filter to 10MB in Python
df = spark.read.parquet("s3://huge-dataset/") # 10GB
df = df[df["date"] == "2024-01-01"] # 10MB
# Good: Push filter down to storage layer
df = spark.read.parquet("s3://huge-dataset/date=2024-01-01/") # 10MBThis can be 100-1000x faster because you're not moving data over the network.
3. Inefficient iteration patterns
# Bad: Row-by-row processing in pandas
for index, row in df.iterrows():
df.at[index, 'new_col'] = expensive_operation(row['value'])
# Good: Vectorized operations
df['new_col'] = df['value'].apply(expensive_operation)
# Or even better: use built-in vectorized functions
For 100K rows, vectorized is 50-100x faster.
4. Serialization/deserialization in tight loops
# Bad: JSON parsing in a loop for streaming data
for record in stream:
data = json.loads(record) # Parsing overhead
process(data)
# Good: Batch and use faster serialization
batch = []
for record in stream:
batch.append(record)
if len(batch) >= 1000:
data = orjson.loads(batch) # Faster JSON library, batched
process_batch(data)orjson is 2-3x faster than standard json, and batching reduces per-record overhead.
5. Retry logic without exponential backoff
# Bad: Immediate retries that hammer failing services
def fetch_with_naive_retry(url, max_retries=3):
for i in range(max_retries):
try:
return requests.get(url)
except Exception:
time.sleep(0.1) # Fixed delay, too short
raise Exception("Failed after retries")
# Good: Exponential backoff with tenacity
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(
stop=stop_after_attempt(5),
wait=wait_exponential(multiplier=1, min=1, max=60),
retry=retry_if_exception_type((ConnectionError, TimeoutError))
)
def fetch_with_backoff(url):
response = requests.get(url, timeout=10)
response.raise_for_status()
return response
Reduces API failures from 15% to <1% by avoiding rate limit cascades. Makes pipelines more resilient to transient failures.
6. Memory churn from repeated allocation
# Bad: Creating new objects in a hot loop
for i in range(1_000_000):
result = {} # New dict allocation every iteration
result['key'] = expensive_calc(i)
results.append(result)
# Good: Reuse or pre-allocate
results = [{'key': expensive_calc(i)} for i in range(1_000_000)]
# Or use numpy/pandas which handle memory efficiently
Case Studies: Real-World Scenarios
Case Study 1: The API Rate Limit
Problem: Pipeline makes 10,000 API calls sequentially. Rate limit is 100 requests/second. Pipeline takes 100 seconds.
Bad optimization: Use async/await to parallelize requests.
- Result: Hit rate limit harder, get throttled, pipeline now takes 200 seconds due to retries.
Good optimization 1: Batch requests using API's batch endpoint.
- Result: 100 batch requests instead of 10,000 individual requests. Pipeline now takes 1 second.
Good optimization 2: When batching isn't possible, use exponential backoff with rate limiting.
from tenacity import (
retry,
stop_after_attempt,
wait_exponential,
retry_if_exception_type,
)
import time
import requests
# Rate limiting: Don't exceed 100 requests/second
RATE_LIMIT = 100
MIN_INTERVAL = 1.0 / RATE_LIMIT # 0.01 seconds between requests
@retry(
stop=stop_after_attempt(5),
wait=wait_exponential(multiplier=1, min=1, max=60),
retry=retry_if_exception_type((requests.HTTPError, ConnectionError)),
reraise=True
)
def fetch_with_backoff(url, last_request_time):
"""Fetch with rate limiting and exponential backoff."""
# Rate limiting: ensure minimum interval between requests
elapsed = time.time() - last_request_time
if elapsed < MIN_INTERVAL:
time.sleep(MIN_INTERVAL - elapsed)
response = requests.get(url, timeout=10)
response.raise_for_status()
return response.json(), time.time()
# Process requests with rate limiting
last_request_time = 0
for url in api_urls:
data, last_request_time = fetch_with_backoff(url, last_request_time)
process(data)
- Respects rate limits, handles transient failures gracefully. Pipeline completes reliably instead of crashing on rate limit errors.
Understand the constraint before optimizing. The bottleneck was largely the API rate limit. Working with the constraint (batching or rate limiting + backoff) instead of against it (parallelizing) solved the problem. Exponential backoff ensures transient failures don't cascade into full pipeline failures.
Runtime Impact Analysis:
Pipeline frequency: 1 time/day
Time saved: 0 seconds (pipeline was crashing, not slow)
Business criticality: High (pipeline completely broken)Case Study 2: The Pandas Memory Expansion
Problem: ETL pipeline processes 5GB CSV, crashes with OOM error on 16GB machine.
Bad optimization: Spin up 64GB machine.
- Cost: 4x higher instance cost, forever.
Good optimization: Use chunked reading.
# Instead of:
df = pd.read_csv("5gb_file.csv")
# Do:
chunks = pd.read_csv("5gb_file.csv", chunksize=100_000)
for chunk in chunks:
process_and_write(chunk)- Result: Processes on existing hardware, peak memory stays under 2GB.
Memory problems often aren't performance problems they are usually architecture problems. So instead of using a bigger machine we can just use the pandas library properly.
Runtime Impact Analysis:
Pipeline frequency: 1 time/day
Time saved: 2 minutes (5 minutes → 3 minutes with multiprocessing)
Business criticality: Low (runs overnight, meets SLA with 4-hour buffer)
Runtime Impact = (1/day × 2min) × Low = 14 minutes/weekCase Study 3: The Premature Multiprocessing
Problem: Data transformation takes 5 minutes for daily pipeline.
Bad optimization: Add multiprocessing to parallelize transformation.
- Time spent: 2 days of development
- Result: 5 minutes → 3 minutes (with added complexity)
- ROI: Saved 2 minutes per day = 12 hours per year. Not worth 2 days of dev time.
Good optimization: Check if this is even a problem worth solving.
- The pipeline runs once a day at 2am
- SLA is "before 6am business hours"
- Business impact of optimization: zero
The fastest code is code you don't need to write. Sometimes the best optimization is recognizing that 5 minutes is fast enough.
Runtime Impact Analysis:
Pipeline frequency: 1 time/day
Time saved: 2 minutes (5 minutes → 3 minutes with multiprocessing)
Business criticality: Low (runs overnight, meets SLA with 4-hour buffer)
Runtime Impact = (1/day × 2min) × Low = 14 minutes/weekVerdict: Saves <2 hours/week. Don't optimize yet.
Bad optimization: Add multiprocessing to parallelize transformation
- Time spent: 2 days of development
- Result: 5 minutes → 3 minutes (with added complexity)
- ROI: Saves 12 hours per year. Not worth 2 days of dev time
Good optimization: Check if this is even a problem
- The pipeline runs once a day at 2am
- SLA is "before 6am business hours"
- Business impact of optimization: zero
Again, The fastest code is code you don't need to write. The Runtime Impact formula would have saved 2 days of development time.
When to Rewrite: Using a Better Tool vs. Optimizing
Sometimes the best optimization is using a better tool.
Pandas → Polars: For CPU-bound transformations on medium data (1-50GB)
- Benchmark: 3-5x faster for typical group-by operations
- When to switch: Pandas operations taking >30 minutes, but data fits on one machine
Python → Spark: For truly large-scale distributed processing (>50GB)
- Benchmark: Can process 1TB+ by distributing across cluster
- When to switch: Need to process multi-TB datasets, running out of memory regularly
Python → SQL: For aggregations and joins
- Benchmark: 10-100x faster because computation happens in the warehouse
- When to switch: Always, when the operation can be done in SQL
When not to switch:
- "This could be faster" (not a good reason)
- Current solution works and meets SLA
- You don't have the expertise to operate the new tool
The Anti-Checklist: Signs You're Optimizing Wrong
Stop optimizing if you're:
- Optimizing code that runs infrequently
- Optimizing before measuring
- Optimizing Python when the database is the bottleneck
- Adding complexity to save <10% runtime
- Optimizing because it's "more elegant"
- Using a "faster" library you don't understand
- Parallel processing without checking if you're I/O-bound
Start optimizing if:
- Pipeline misses SLA regularly
- Profiling shows clear bottleneck (>50% of runtime)
- Bottleneck is CPU/memory-bound in your code
- Optimization has clear ROI (time saved × frequency)
- You've already fixed the database queries
- Users are actually waiting for results
The Performance Mindset Shift
The best data engineers aren't the ones who write the fastest Python. They're the ones who build systems that don't need optimization in the first place.
Architecture > Optimization:
- Partition your data properly
- Use incremental processing instead of full refreshes
- Cache expensive computations
- Process data where it lives (in the warehouse, not Python)
Measurement > Intuition:
- Profile before optimizing
- Benchmark your changes
- Automate performance testing so you notice regressions
Pragmatism > Perfection:
- Fast enough is fast enough
- Complexity is a cost
- Your time is valuable
The goal isn't fast code. The goal is reliable data delivered on time. Sometimes the best performance optimization is accepting that 5 minutes is fine, and spending your time on something that actually matters.
Three Things to Do This Week
- Add timing blocks to your slowest pipeline: Spend 30 minutes adding
timer()context managers to see where time actually goes. You'll probably be surprised. - Profile one database query: If you have a slow pipeline, check the query profiler in your warehouse. Fix the query before touching Python code.
- Review your optimization backlog: Look at the "performance improvements" on your todo list. How many of them would actually save meaningful time? Be honest about ROI.
The fastest way to improve pipeline performance is to stop optimizing the wrong things. Measure first, then optimize what actually matters.
Appendix: Resources
Profiling tools:
cProfile: Built into Python for CPU profilingline_profiler: Line-by-line profiling for finding hot spotsmemory_profiler: Memory usage profilingpy-spy: Production profiling without code changes- Warehouse query profilers: Snowflake Query Profile, BigQuery Execution Details, Databricks Spark UI
Useful libraries:
tenacity: Exponential backoff and retry logic for resilient I/O operationsorjson: Faster JSON parsing (2-3x faster than standard library)polars: Fast dataframe library (alternative to pandas)pyspark: Distributed processing for large datasets
See this repo for the full code snippets used in this blog.
Additional Reading





.jpg)
.png)



.png)

