




Dagster+ further enhances identification and collaboration around changes to your data pipelines.
One of our primary beliefs at Dagster is that data engineering is software engineering. Data pipelines should be expressed as code and use a version control system like git. Before changes to a data pipeline are deployed to production, they should be reviewed by stakeholders and other engineers on your team and validated in a staging or test environment.
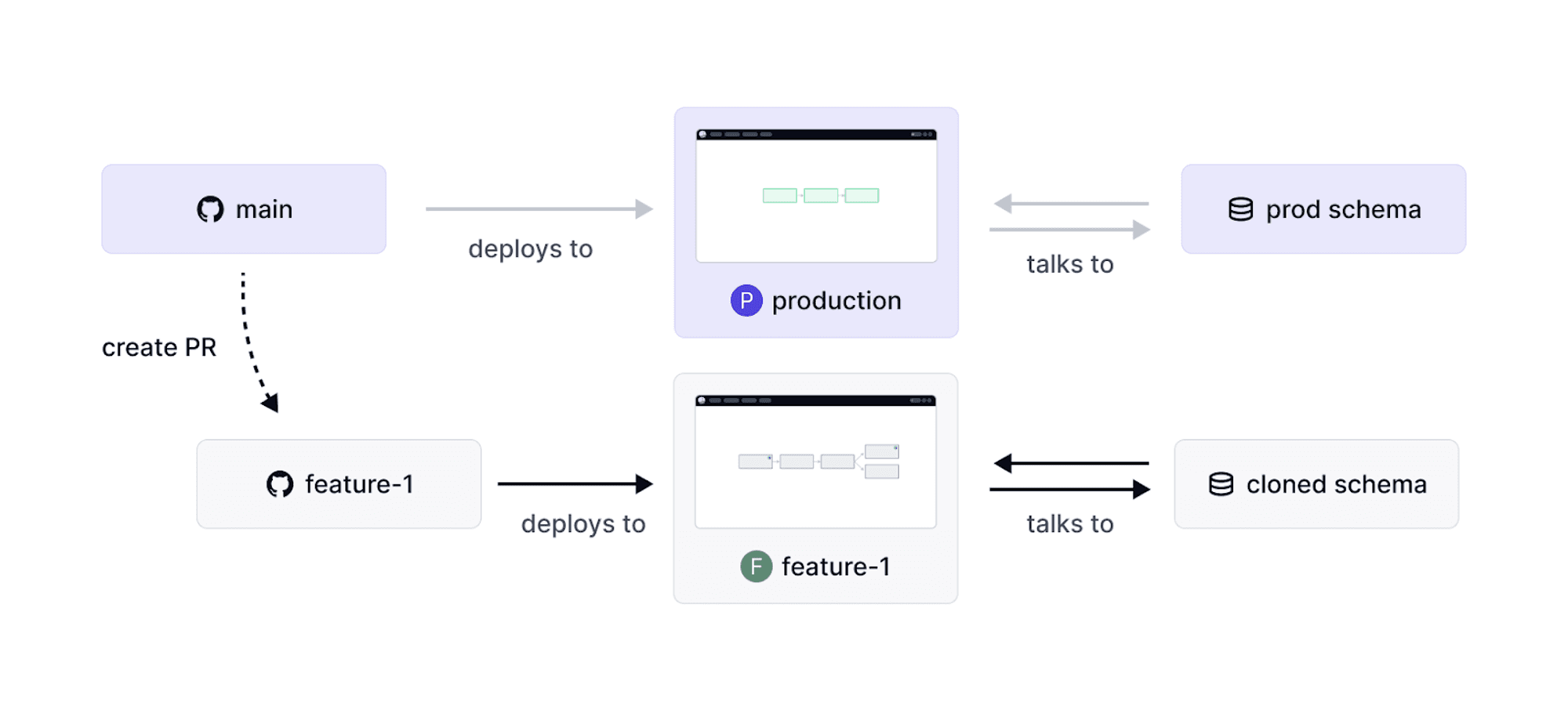
In practice, this means most Dagster users have a main branch that contains their code and a production Dagster deployment where that code is deployed.
When developers make changes to their data pipelines, they create a branch off of main, make their changes, and open a pull request in a Git hosting service like GitHub or GitLab. Once these changes are reviewed and approved, they are merged into main and the production Dagster deployment is updated.

But this skips over a crucial step in the development process - testing the changes!
This is where Branch Deployments come in.
How Branch Deployments Work
When you create a pull request, Dagster+ creates a corresponding Branch Deployment. Just like how GitHub shows what the code will look like after a change is merged, the Branch Deployment incorporates the code changes in the pull request and creates a lightweight, ephemeral, but detailed and interactive deployment to show what production will look like after the change is merged.
We designed Branch Deployments to fit seamlessly into the existing development process and reduce the friction of reviewing, testing, and collaborating on data pipelines.
Branch Deployments can be configured to interact with staging resources, which allows you to materialize your assets in the Branch Deployment without affecting production data.

Branch Deployments: Now with Change Tracking
Let’s take the git analogy a bit further. In GitHub and other Git hosting services, a pull request will show only the changes in a particular branch. These changes are highlighted so you can easily see what needs to be reviewed. With Dagster+, Branch Deployments also highlight which assets have changed with a feature called Change Tracking. When a Branch Deployment is created, the assets are compared to the production deployment. Assets that are changed in the branch are highlighted directly in the UI.

Change Tracking brings a whole new level of visibility into the testing and review process. Here are some ways it can help you test and review code more effectively:
Testing
In a Branch Deployment with Change Tracking, you can use filters to show just the assets that are affected by your code changes. With this knowledge, you can be more precise about which assets you test in the Branch Deployment. This directly translates to increased velocity and cost savings since time and compute are not wasted materializing unchanged assets.
Reviewing
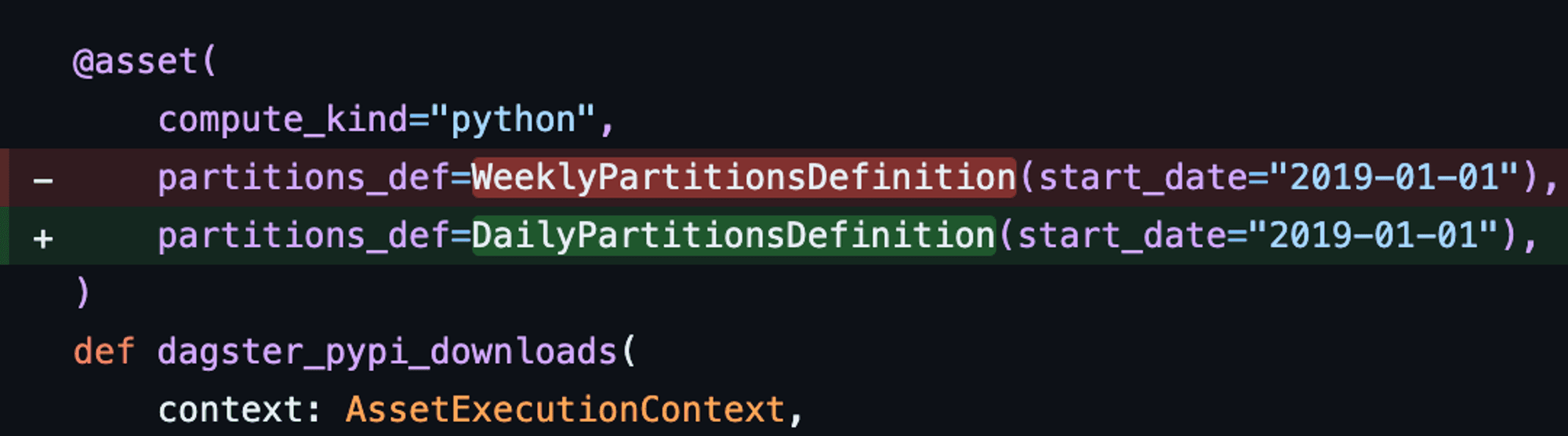
Change Tracking also makes reviewing and understanding code changes easier. For example, the following code change looks pretty innocuous:

However, it’s hard to know how many assets this change affects. To find out, you’d need to search through the code base, and even then it’s hard to know if this encompasses the full scope of the change that took place.
With Change Tracking, your team can use the Dagster UI to show all of the assets affected by this change.

This immediately reveals the full impact of this code change and allows you to better understand the code you are reviewing and spot potential problems.
Dagster+ enhances the development process by detecting and highlighting several types of changes within branch deployments. These include the creation of new assets; additions, modifications, or removals of partitions; changes in upstream dependencies of assets; updates in asset tags and metadata; and changes in the code version of an asset's compute function. For a deeper understanding and examples of each type of change, refer to our detailed documentation here.
Look Out for Future Enhancements
Dagster+’s Branch Deployments enhance existing code review processes and improve your team’s ability to test and review code. This enables you to move faster and increase the quality of the data pipelines you deploy.
At Dagster Labs, we're constantly seeking innovative ways to streamline the development and testing processes for data teams. We’re actively exploring ways to make Branch Deployments even more authentic test environments, including the ability to read production data but write to staging. We would love to hear how you would like to see Branch Deployments evolve.





.jpg)
.png)



.png)

