




Snowflake handles AI compute while Dagster handles orchestration, observability, and the operational patterns that turn AI experiments into reliable production pipelines.
Snowflake has evolved into an AI compute platform. Cortex AI lets you run sentiment analysis on millions of rows, extract entities from unstructured text, and generate intelligent summaries directly in SQL without moving your data.
However, one does not simply integrate AI into their data platform.
When do those AI queries run? What happens when they fail? How do you track costs? Who coordinates the steps between raw data and actionable intelligence?
Snowflake handles AI compute. Dagster handles orchestration, observability, and the operational patterns that turn AI experiments into reliable production pipelines.
This post walks through a real project: a Hacker News Intelligence Pipeline that demonstrates how Dagster and Snowflake work together. The pipeline includes authentication, incremental processing, cost tracking, and patterns your team can adopt today.
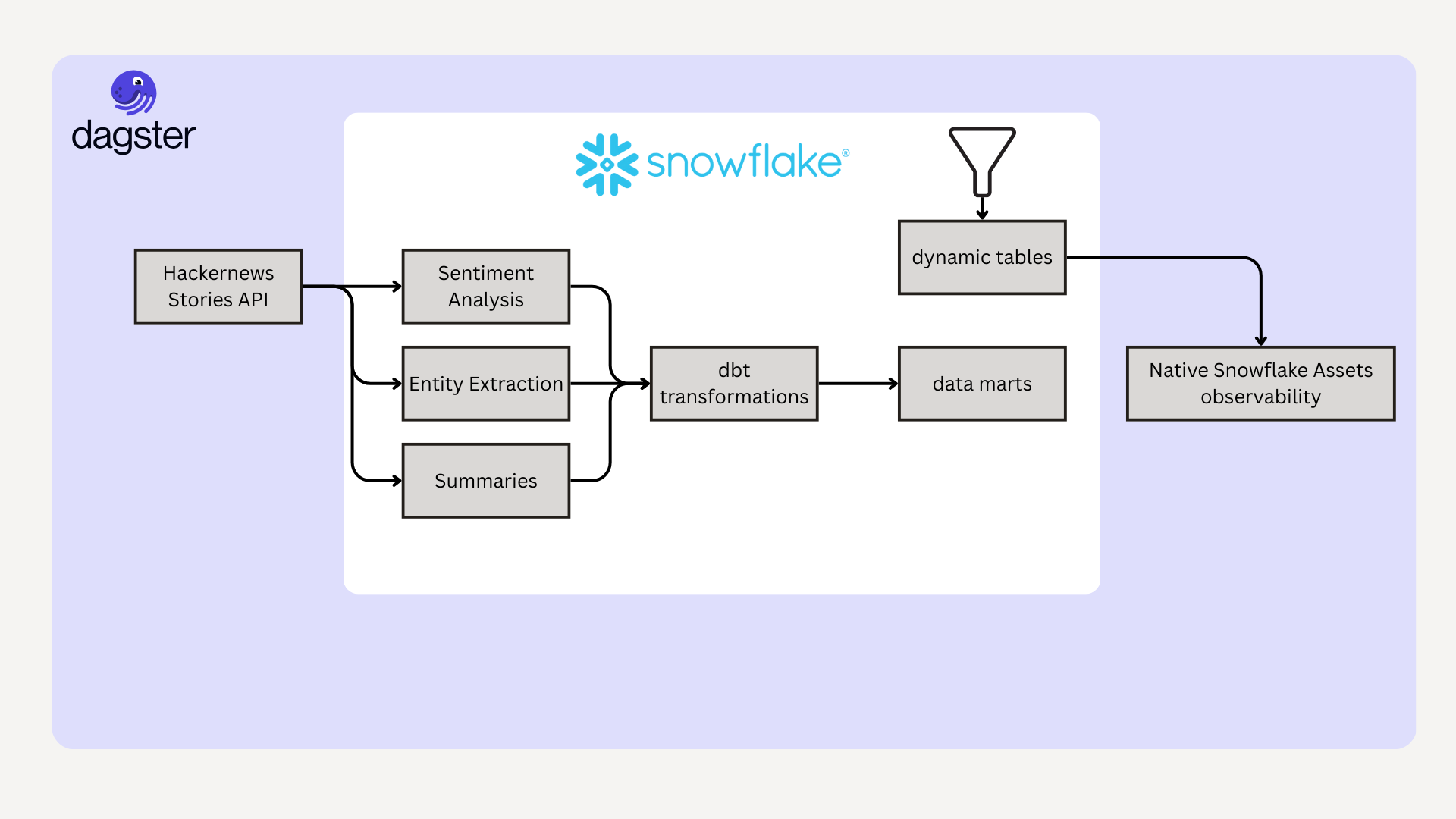
Clear Separation of Concerns
Dagster + Snowflake work well together because each platform does what it does best:
The separation is clean: Snowflake executes, Dagster orchestrates.
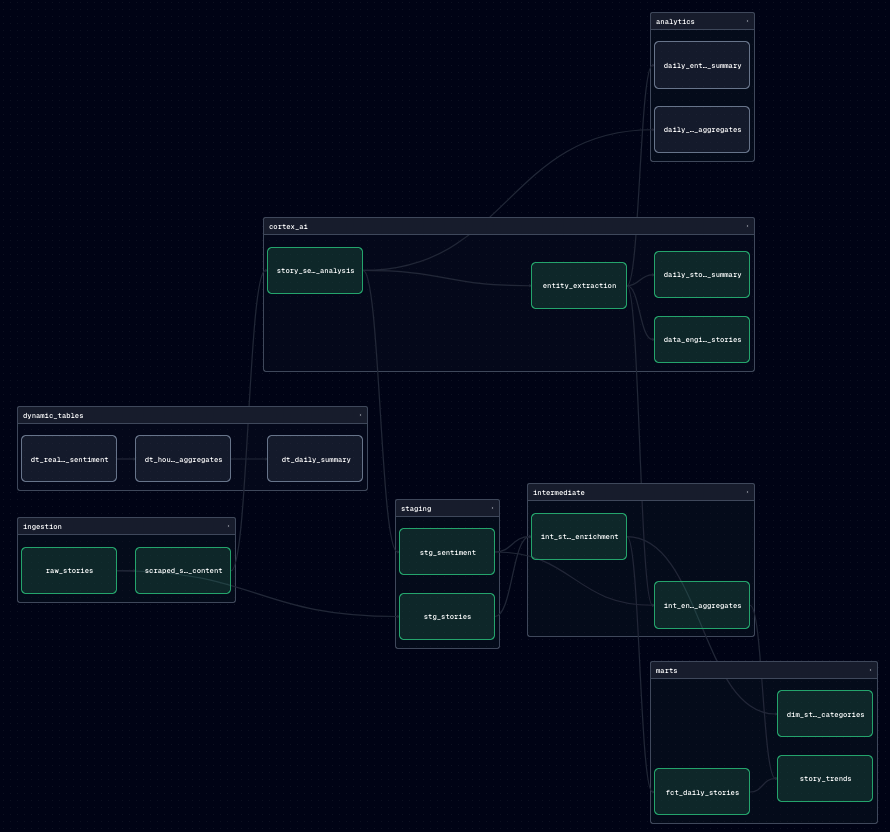
Hacker News Intelligence Pipeline
Our demo project scrapes Hacker News stories, enriches them with Cortex AI, and produces daily intelligence summaries. The pipeline covers the patterns needed for production AI workloads:
This end-to-end project showcases the power of both platforms and their complementary nature.
Pattern 1: Cortex AI Orchestration
Cortex AI functions like AI_CLASSIFY, COMPLETE, and AI_AGG run inference at scale. But production requires more than the function itself. You need scheduling, dependency tracking, and monitoring around it. LLM usage can be expensive if you are not monitoring it and only executing when needed. When you wrap Snowflake SQL inside Dagster assets, you get data lineage for the transformation, detailed run history, and versioning.
Dagster orchestrates Cortex AI using Assets like this in Python:
@dg.asset(
deps=["scraped_story_content"],
compute_kind="snowflake-cortex"
)
def story_sentiment_analysis(
context: dg.AssetExecutionContext,
snowflake: SnowflakeResource
) -> dg.MaterializeResult:
"""
Dagster orchestrates WHEN this runs and TRACKS the execution.
Snowflake executes the AI inference.
"""
with snowflake.get_connection() as conn:
cursor = conn.cursor()
# Snowflake runs AI_CLASSIFY - no data movement
cursor.execute(f"""
UPDATE {schema}.stories
SET sentiment = AI_CLASSIFY(
content,
['positive', 'neutral', 'negative']
):label::STRING
WHERE sentiment IS NULL
""")
# Get processing stats for observability
cursor.execute(f"""
SELECT
COUNT(*) as total,
COUNT_IF(sentiment = 'positive') as positive,
COUNT_IF(sentiment = 'negative') as negative
FROM {schema}.stories
""")
stats = cursor.fetchone()
# Dagster captures metadata for lineage and monitoring
return dg.MaterializeResult(
metadata={
"stories_processed": dg.MetadataValue.int(stats[0]),
"positive_count": dg.MetadataValue.int(stats[1]),
"negative_count": dg.MetadataValue.int(stats[2]),
"sentiment_ratio": dg.MetadataValue.float(
stats[1] / stats[0] if stats[0] > 0 else 0
)
}
)What's happening here:
- Dagster schedules when sentiment analysis runs (after ingestion completes)
- Dagster tracks dependencies (waits for
scraped_story_content) - Snowflake executes
AI_CLASSIFYdirectly on the data without extraction - Dagster captures metadata for observability and cost tracking
This pattern scales to any Cortex function. Entity extraction with COMPLETE:
@dg.asset(deps=["story_entity_extraction"])
def daily_intelligence_summary(context, snowflake):
"""Generate AI-powered daily briefing."""
with snowflake.get_connection() as conn:
cursor = conn.cursor()
cursor.execute(f"""
INSERT INTO {schema}.daily_summaries
SELECT
CURRENT_DATE() as summary_date,
AI_AGG(
content,
'Synthesize these Hacker News stories into a 3-paragraph
tech intelligence briefing. Include: (1) dominant themes,
(2) notable launches or announcements, (3) emerging trends
to watch. Be specific with names and details.'
) as intelligence_summary,
COUNT(*) as stories_analyzed
FROM {schema}.stories
WHERE DATE(posted_at) = CURRENT_DATE()
""")Cortex runs the inference. Dagster ensures it runs reliably, in the correct order, with full observability.
Pattern 2: Incremental Processing at Scale
Processing your entire dataset every run is expensive. Leveraging Dagster partitions and Snowflake MERGE patterns enables efficient incremental processing.
# Define daily partitions
daily_partitions = dg.DailyPartitionsDefinition(
start_date="2024-01-01",
timezone="America/New_York"
)
@dg.asset(partitions_def=daily_partitions)
def daily_sentiment_aggregates(
context: dg.AssetExecutionContext,
snowflake: SnowflakeResource
) -> dg.MaterializeResult:
"""
Dagster provides partition context.
Snowflake executes efficient MERGE for incremental updates.
"""
partition_date = context.partition_key
with snowflake.get_connection() as conn:
cursor = conn.cursor()
# MERGE pattern: only process the partition, not the whole table
cursor.execute(f"""
MERGE INTO {schema}.daily_sentiment_aggregates target
USING (
SELECT
DATE(posted_at) as agg_date,
sentiment,
COUNT(*) as story_count,
AVG(score) as avg_score
FROM {schema}.stories
WHERE DATE(posted_at) = %(partition_date)s
GROUP BY DATE(posted_at), sentiment
) source
ON target.agg_date = source.agg_date
AND target.sentiment = source.sentiment
WHEN MATCHED THEN UPDATE SET
story_count = source.story_count,
avg_score = source.avg_score,
updated_at = CURRENT_TIMESTAMP()
WHEN NOT MATCHED THEN INSERT
(agg_date, sentiment, story_count, avg_score, updated_at)
VALUES
(source.agg_date, source.sentiment, source.story_count,
source.avg_score, CURRENT_TIMESTAMP())
""", {"partition_date": partition_date})
result = cursor.fetchone()
return dg.MaterializeResult(
metadata={
"partition_date": dg.MetadataValue.text(partition_date),
"rows_merged": dg.MetadataValue.int(result[0] if result else 0)
}
)Benefits of this pattern:
- Cost efficiency: Process only what changed, not the entire history
- Backfill support: Dagster can backfill specific partitions without reprocessing everything
- Auditability: Each partition has its own metadata and run history
- Parallelization: Multiple partitions can process concurrently
Pattern 3: Snowflake Resources
We use Dagster Resources for direct SQL control while keeping Dagster's orchestration benefits, enabling a clean separation between storage and business logic.
from dagster_snowflake import SnowflakeResource
# Resource configuration supports multiple auth methods
snowflake_resource = SnowflakeResource(
account=dg.EnvVar("SNOWFLAKE_ACCOUNT"),
user=dg.EnvVar("SNOWFLAKE_USER"),
password=dg.EnvVar("SNOWFLAKE_PASSWORD"), # Or use private key
warehouse=dg.EnvVar("SNOWFLAKE_WAREHOUSE"),
database=dg.EnvVar("SNOWFLAKE_DATABASE"),
schema=dg.EnvVar("SNOWFLAKE_SCHEMA"),
)
# Use in assets with full SQL control
@dg.asset
def my_asset(snowflake: SnowflakeResource):
with snowflake.get_connection() as conn:
# Direct cursor access - write any SQL you need
cursor = conn.cursor()
cursor.execute("SELECT ...")
Why this matters:
- Authentication flexibility: Easy to switch from password to private key to OAuth
- Fine-grained control: Choose warehouses per asset based on workload
- Query optimization: Write exactly the SQL you need (CTEs, window functions, etc.)
- Transparent: Clear, debuggable code that does what you expect
Pattern 4: dbt Integration
Many data platforms include dbt for transformations. Dagster's integration with dbt works cleanly because they are both asset-based.
from dagster_dbt import DbtCliResource, dbt_assets
# dbt models automatically become Dagster assets
@dbt_assets(manifest=dbt_manifest_path)
def my_dbt_assets(context, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()Dagster automatically resolves dependencies between Cortex AI assets and dbt models. If a dbt model references the story_sentiment table created by a Cortex asset, Dagster runs the AI processing first.
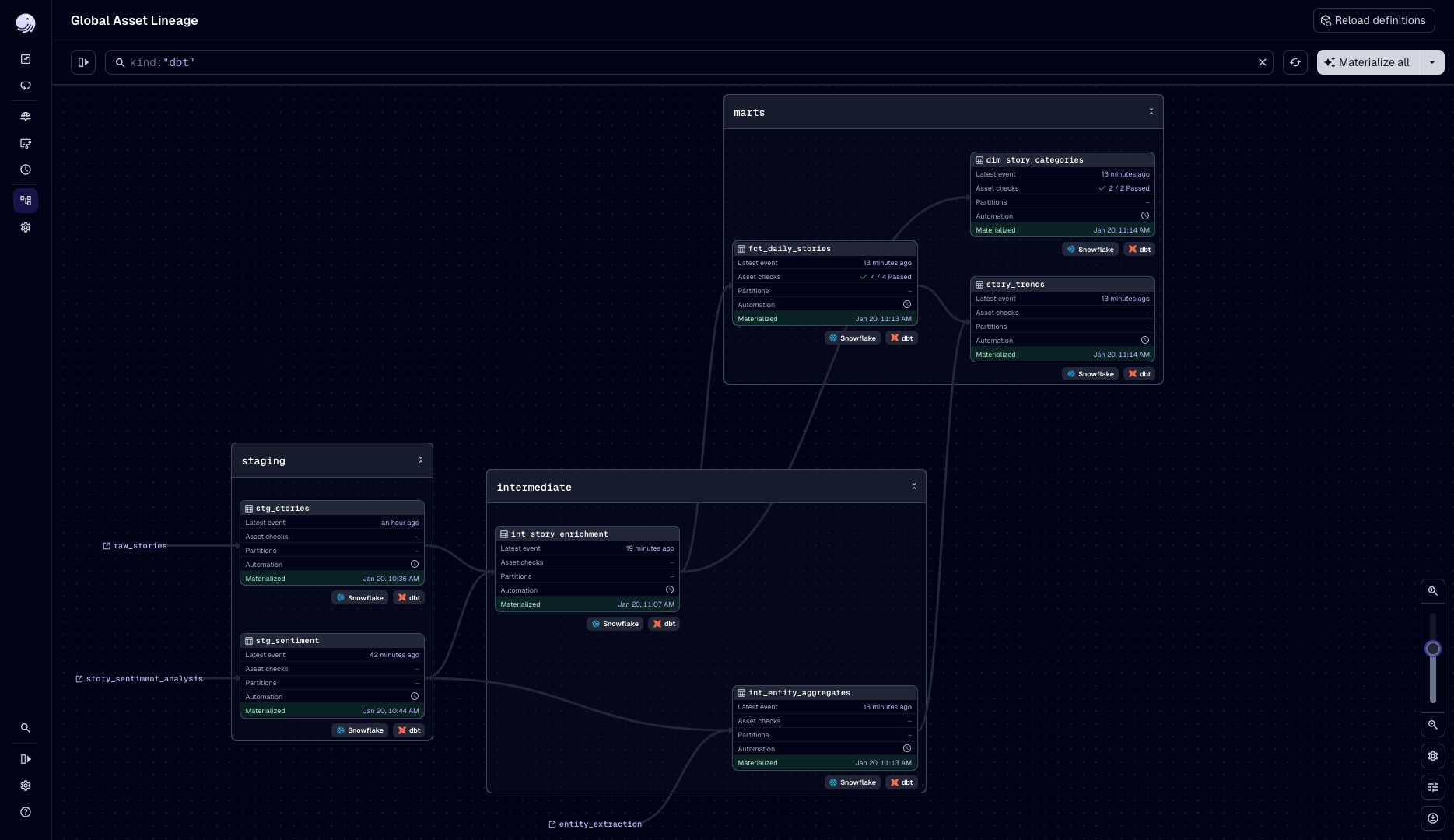
All orchestrated by Dagster. All executed in Snowflake. Zero manual dependency management. One less thing to think about.
Pattern 5: Production-Ready Operations
Real production systems need more than just writing the code. Those so-called “day 2 operations” or quality-of-life improvements that reduce the toil of reactive firefighting and improve data platform uptime. Whether it is improved developer ergonomics or observability that cuts through the noise so you can quickly nip problems in the bud.
Timezone-Aware Scheduling
@dg.schedule(
cron_schedule="0 2 * * *", # 2 AM
timezone="America/New_York",
job=daily_intelligence_job
)
def daily_intelligence_schedule(context):
"""Run daily intelligence pipeline at 2 AM EST."""
return dg.RunRequest()Dagster handles timezone-aware scheduling. Snowflake handles timezone-aware queries. No manual conversion needed.
Cost Tracking and Retries
Every asset materialization captures metadata that flows into Dagster Insights (on Dagster+):
return dg.MaterializeResult(
metadata={
"rows_processed": dg.MetadataValue.int(row_count),
"cortex_function": dg.MetadataValue.text("AI_CLASSIFY"),
"warehouse": dg.MetadataValue.text("COMPUTE_WH"),
# Dagster Insights aggregates this for cost analysis
}
)
See exactly which assets drive your Cortex compute costs. Optimize where it matters.
@dg.asset(
retry_policy=dg.RetryPolicy(
max_retries=3,
delay=30, # seconds
backoff=dg.Backoff.EXPONENTIAL
)
)
def resilient_ai_processing(snowflake):
"""Automatically retry on transient failures."""
# Your Cortex AI logic hereTransient failures happen, but Dagster retries automatically to keep your pipeline healthy.
The Complete Picture
A production run follows this sequence:
- Dagster schedules the daily job at 2 AM EST
- Dagster orchestrates ingestion → Snowflake stores raw Hacker News data
- Dagster triggers sentiment analysis → Snowflake runs AI_CLASSIFY
- Dagster manages dependencies → Entity extraction waits for sentiment to complete
- Snowflake executes entity extraction → CORTEX.COMPLETE extracts structured data
- Dagster coordinates dbt transformations → Snowflake runs dbt models
- Dagster monitors pipeline health and freshness
- Dagster tracks Cortex compute costs in Insights
The result: an orchestrated, observable, cost-tracked AI pipeline that runs with minimal intervention.
Why This Matters
The Dagster + Snowflake partnership addresses a real gap: AI functions are available, but production AI systems require more.
Snowflake made AI accessible through SQL. But accessibility differs from production-readiness. Production systems need:
- Scheduling and dependency management
- Observability and lineage tracking
- Cost monitoring and optimization
- Error handling and recovery
- Incremental processing at scale
Dagster provides these capabilities, complementing Snowflake rather than replacing it.
Snowflake handles the AI compute. Dagster handles the orchestration. Together, they make AI pipelines as reliable as traditional ETL.
Getting Started
To build a similar pipeline:
- Clone the example project: [GitHub link]
- Configure Snowflake credentials: Set environment variables
- Run the pipeline: dagster dev and explore the UI
- Adapt the patterns: Use these building blocks for your use case
The patterns in this post are demonstrated in working code you can run today.





.jpg)
.png)



.png)

