




Designing better data tooling with DSLs
Dagster’s move into `dg` and Components is a big step forward. These features make it easier to create well-organized Dagster projects and offer a full toolkit for building YAML-based domain-specific languages (DSLs) with Components.
If you don’t spend all day thinking about data tooling, the appeal of building around DSLs may not be immediately obvious. However, DSLs are incredibly common in the data space and power many of the most popular tools. Before diving into how Dagster Components bring DSLs to life, let’s first define what a DSL actually is.
What is a DSL?
A domain-specific language (DSL) is a programming or configuration language dedicated to a narrow problem domain, offering specialized syntax and semantics. Compared to general-purpose programming languages like Python, which are flexible but verbose, DSLs are optimized for expressing logic with minimal effort and maximum clarity within a particular domain.
A familiar example is SQL, which has several DSL traits:
- Focused purpose: Designed specifically for querying and managing relational databases.
- High-level abstraction: Commands like `SELECT`, `INSERT` and `JOIN` map directly to database operations.
- Limited scope: Only concerns itself with data retrieval and manipulation, nothing else.
At first glance, these might seem like limitations. But in practice, they’re what makes SQL so powerful. SQL allows users to aggregate billions of rows with just a few lines of SQL. All of this can happen without needing to be aware of the parsing, optimization, planning, and execution occurring behind the scenes within the database.
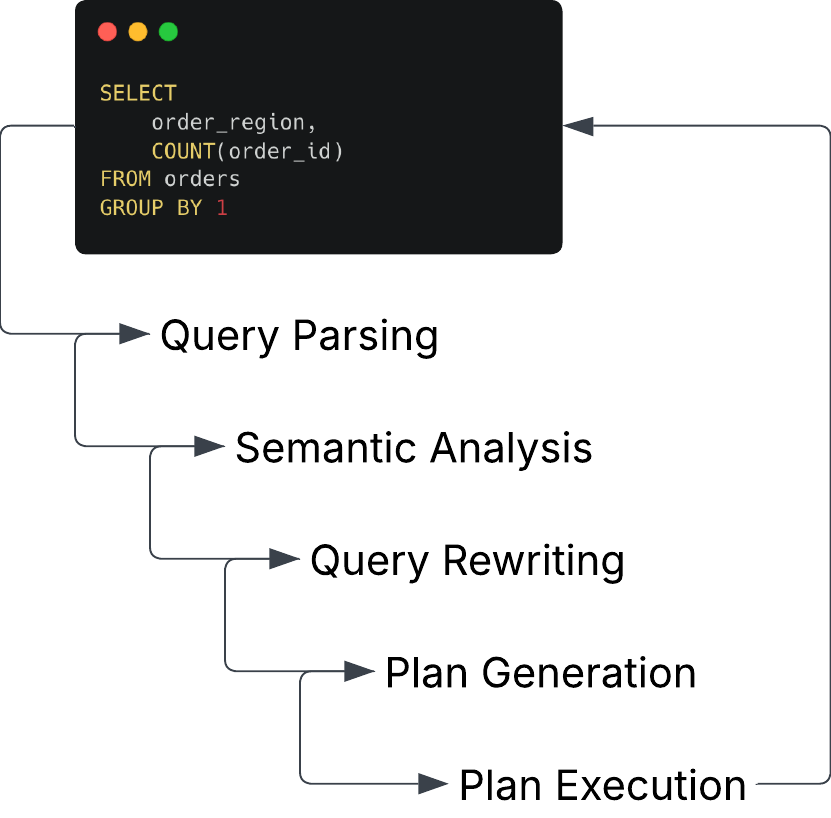
SQL has remained a successful and enduring DSL because it empowers users with immediate impact. For many data practitioners, it’s the first language they learn because the return on investment is so high. With just a day of learning, you can write queries that unlock real business insights. While mastery takes time, even basic SQL opens the door to powerful data exploration and reporting, making it accessible and rewarding.
This is exactly the kind of abstraction Dagster aims to provide through Components. Empowering users across the data stack to quickly implement workflows without getting bogged down in low-level technical details. Components make it easy to turn repeated patterns into reusable, declarative building blocks, accelerating development while maintaining clarity and consistency.
DSLs in Dagster
Even before Components, Dagster’s asset-based model leaned naturally toward declarative, DSL-friendly design. Traditional tools treated data pipelines as imperative DAGs: you define a sequence of steps and manually wire them together. This can work but these types of pipelines tend to be overly bogged down with their own implementation. This makes it hard to standardize tasks and share responsibility across DAGs.

Dagster, in contrast, encourages you to model your platform as a collection of assets. Each asset represents a logical piece of a data platform. These assets are independent, composable, and buildable, offering a better mental model for complex platforms.
This declarative mindset makes Dagster a natural host for DSLs. Instead of defining the how of each individual step, you define the what, your individual assets, and focus on their meaning. This allows the system to infer things about execution and dependencies. And that’s where Components come in.
Components
So, how do we map real-world systems like data sources and APIs into assets without forcing users to write low-level code? Similar to how SQL hides the execution details of a query, Components can abstract away the how of asset creation, exposing only the minimum necessary configuration.
Take a common task like extracting data with Sling. In a traditional imperative setup, a user would have to write and maintain how Sling is being used. With Components, since we know certain properties about Sling, we can simplify the interface for the user and only expose those fields that matter to them:
type: dagster_sling.SlingReplicationCollectionComponent
attributes:
sling:
connections:
- name: MY_POSTGRES
type: postgres
host: localhost
port: 5432
database: test_db
user: "{{ env(POSTGRES_USER) }}"
password: "{{ env(POSTGRES_PASS) }}"
- name: MY_DUCKDB
type: duckdb
instance: "{{ env('DUCKDB_DATABASE') }}"
replications:
- path: replication.yamlThis YAML defines what the user cares about for data extraction, where the data comes from, and where it goes. Everything else is handled under the hood. The DSL empowers the user without overwhelming them.
Designing DSLs
Dagster Components are not a walled garden. One of the most powerful aspects of Components is that they can be developed like any of the other abstraction layers in Dagster. This allows you to design your own Components and DSLs tailored to your organization’s needs. If your team repeatedly solves the same types of problems or interacts with certain tools, those patterns can be captured in Components. By codifying them with a declarative YAML interface, you can create clean, composable abstractions that hide messy implementation details.
If you've never built a DSL before, it can be hard to know what to expose and what to abstract away. A good rule is to always design around your user. What’s the minimum configuration someone needs to get value from your Component? Only expose options when they’re essential for clarity, flexibility, or control.
Good DSLs for data products tend to share a few key characteristics:
- Ergonomic: Users can describe what they want in a few lines, with helpful defaults.
- Purpose-built: The DSL solves a well-defined task, like “loading data from Postgres” or “generating weekly reports for a customer.”
- Opinionated but flexible: It nudges users toward best practices, while still allowing for variation.
- Composable: DSLs should play well with each other and support layering. For example, configuring an upstream extract and a downstream transform via separate Components.
By keeping DSLs scoped and centered around user intent, you empower data teams to move faster without being bogged down by unnecessary code or brittle DAG configurations. It is also good to watch out for common anti-patterns with DSLs:
- Premature Abstraction: Creating generalized solutions before fully understanding user needs or the problem domain.
Excessive Abstraction: Hiding too much detail, leading to inflexible systems that restrict necessary configuration or customization. - Leaky Abstractions: Exposing implementation details of the underlying systems, undermining the DSL’s purpose.
Insufficient Documentation: Failing to provide the guidance needed for users to understand, adopt, and extend the DSL effectively.
If you want to learn more about creating proper abstractions and best practices. You can see our talk at this year’s MDS Fest.
Beyond DSLs
Of course, no DSL can capture the full complexity of every data system. Every platform has its own quirks. This is why DSLs alone aren’t enough and why Dagster’s design is so effective.
With Dagster, you don’t have to choose between abstraction and flexibility. You can freely mix DSLs and imperative Python, using Components for common patterns and falling back to code when needed.
The end result? A platform that scales not just technically, but organizationally, where users can confidently describe their intent, and engineers can support them with reusable, maintainable infrastructure underneath.





.jpg)
.png)



.png)

