



A guide for CIOs/CTOs and engineering leaders looking to master the Modern Data Stack and develop a high performance data platform - while avoiding pitfalls along the way.
Over the last year, EvolutionIQ overhauled its data platform. In doing so, they positioned the company for growth, strengthened developer morale, accelerated development cycles, and slashed new client onboarding from several months to less than a week. Here’s how they approached this transformation and what they learned along the way. Spoiler alert: they use Dagster.
When your data pipelines are your business
The data pipelines at most businesses power internal processes such as business intelligence and customer insights. But at some companies, the data pipelines are the business.
This is the case at EvolutionIQ, the New York City-based company providing ML insights to some of the world’s largest insurance carriers. EvolutionIQ uses advanced, proprietary machine learning and natural language processing to understand medical recovery and treatment like a healthcare expert – and then deliver daily guidance on extremely complex bodily injury claims.
Founded in 2019, EvolutionIQ has raised $26M to develop an entirely new class of software that acts as an AI partner to reprioritize thousands of insurance claims daily, enabling adjusters to focus their time on a subset of cases ready for immediate action. Their software products for disability, general liability, and workers’ compensation are now deployed with some of the world’s largest insurance carriers and third-party administrators.
A key challenge for the data team is to test and iterate on the ML models, onboard new clients, and build out the data platform, all while running a steady, reliable service for established clients.
Today, EvolutionIQ is running on a modern, reliable data stack. They manage a single code base and have a disciplined development lifecycle that carefully protects client data while giving the team the flexibility to deploy new innovations across multiple environments. Testing and security is built into the design, and the data platform facilitates collaboration across teams.
But like all tech startups, the company had to build up to such a tech stack by innovating and demonstrating the validity of their model along the way.

Tom Vykruta

Stanley Yang

Karan Uppal
We sat down with EvolutionIQ’s co-founder and CEO Tomas Vykruta, along with Stanley Yang (Principal Engineer) and Karan Uppal (VP of Engineering), to discuss this challenge, how they adopted Dagster, and the lessons they learned along the way. Tom and Stanely are both former Google engineers, while Karan sharpened his AI engineering skills at Bloomberg.
The approach in the early days
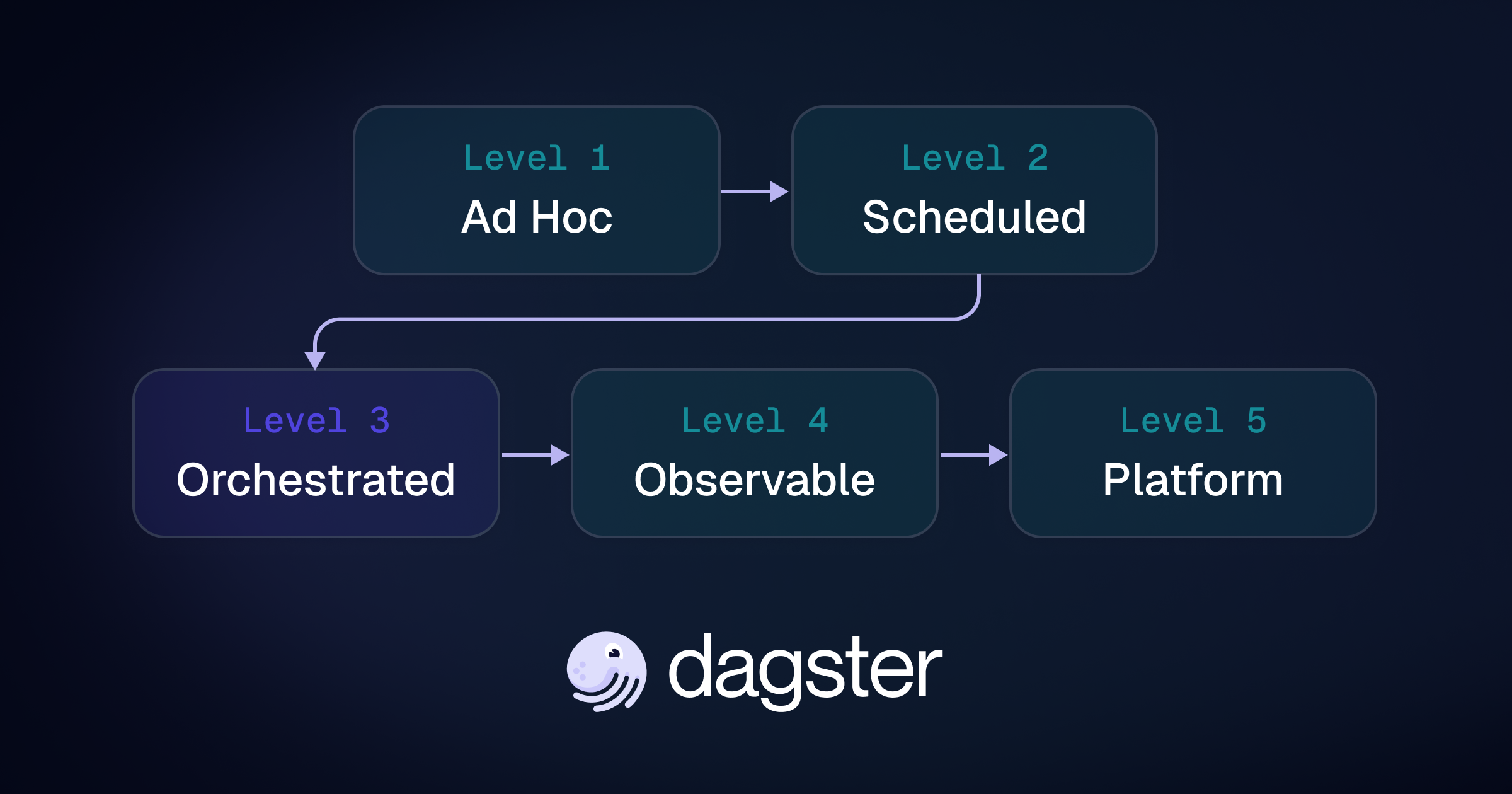
In its early days, EvolutionIQ built out several instances of its core data pipeline, one per customer. Each pipeline was a copy of the most recent version at the time, with some customizations per client. This early approach clearly was not going to scale in the long term, but it got the company through the first couple of years and the first handful of clients.
There was a lot of iteration, with just five engineers on the team handling all aspects of the process.
The core AI model was refined by working with one client’s data, and the learnings then being manually reapplied to the other clients' pipelines. This may seem laborious, but the team’s focus at the time was first to demonstrate the performance of the model, not to build out a large, repeatable process.
Orchestration, such as it was, was done with Cron-based Python scripts designed to run the pipeline end to end. In the morning, each customer would dump data into EvolutionIQ’s systems, and the Cron table would kick off scripts based on an estimate of when - hopefully - the data had arrived.
“We were entirely dependent on data arriving as expected and everything finishing on time,” said Stanley.
Naturally, in dealing with insurance claims, the EvolutionIQ team has to maintain strict confidentiality and data sovereignty, so each customer ran on a separate GCP virtual private cloud.
Over time the team built out four separate code bases which were not fully tested and were mostly undocumented. At this stage, only the founding team really knew where everything was and how things worked.
Hitting a key growth stage
As the number of clients expanded, small challenges became much larger, and it was clear that the business would not scale.
- Testing headaches: There were no options for testing the pipeline other than to run the whole thing end to end. A full test would take two hours. “We were wasting hours of time rerunning the pipeline; it was ridiculous. This also was a massive consumption of compute resources as each test required a run of the whole batch,” said Stanley.
- Slow at developing new features: Even if a test was successful, there was not enough regression testing to make it safe to port the changes from one pipeline to the next. Besides, the team was getting so mired in maintaining the many heterogeneous pipelines and separate code bases that they had less and less time to work on innovations.
- A lack of extensibility: The architecture at the time was to run the pipeline as a single monolithic job and go straight from data processing into Postgres. Few data assets were generated along the way, making intra-run checks impossible. The data team also had no process for generating the data assets required by other teams who might develop new business capabilities in—say—customer success or business intelligence.
- Developer frustration: Ultimately, the biggest challenge with the old model was ramping up new hires and retaining good engineers. “The problems were actually more about the people than about the size or number of datasets” says Tom, “As you scale, you need to be able to hire specialists, rather than the jacks-of-all-trades developers needed in an early stage start-up. Specialists expect more structure and want to focus on a narrower part of the platform. So you need to get your house in order before you can move to that level.” EvolutionIQ learned this the hard way. After they joined, new developers were surprised by how difficult it was to get started. There was no standardized onboarding, and each pipeline was customized, making quality assurance a challenge. With a complex system, there is a lot of institutional knowledge, and new hires would need to learn the whole setup before they could contribute. The engineering team was both hindered by productivity barriers and low morale as a result.
When to move from individual pipelines to a data platform
Clearly, something had to give.
“We needed to create a framework for how we transform claims and make it repeatable, manageable, and scalable,” says Tom. “We would not exist today as a company if we didn’t move to a single unified codebase, with a real data platform beneath it.“
“We would not exist today as a company if we didn’t move to a single unified codebase, with a real data platform beneath it.“
“For AI companies, if you don’t do this, you will end up having a mini team for each client, and the company is not going to scale. Your margins will suffer, and your people will not be happy as they can’t innovate on a platform. You face all sorts of limitations if you don’t make that investment early on,” he said.
But when leading a tech startup, the CEO has to know when to make the call on major initiatives. Too early, and the team won’t have all the insights needed to make the right tech decisions. Too late, and you are falling behind, dragged down by tech debt. “It’s easy to do this too early, and it’s easy to do this too late. When you reach 20 employees as a tech company, the time is probably right,” says Tom.
With this in mind, Tom set forward an internal initiative: DataStack 2.0. The goal: take EvolutionIQ to the next stage of maturity, move past the sandboxing phase and prepare for scale.
Unify behind a vision
It’s hard to get people to commit to change, so Tom started out by aligning the team behind a common vision.
Tom pitched this as much more than an engineering upgrade. The effort was to get the whole company leveled up and ready for the next phase of growth.
Every insurance carrier that EvolutionIQ works with has a slightly different representation of claims data. By mapping this data to a unified schema on a well-architectured data stack, EvolutionIQ would be able to develop major new capabilities: run analytics across the data of all clients, create an industry profile of the best and worst performers, enable the marketing team to create valuable insights, shed tech debt and innovate faster. The firm would also reduce onboarding overhead and address developer attrition.
Tom shared the vision with the engineering team, the technical leaders, and eventually to the entire management team.
Pinning down the requirements
With the vision shared, a core group set to work and did three reviews of possible architectures over three years. In total, they iterated over 10 possible frameworks, each with its own POC.
The team had a number of non-negotiables.
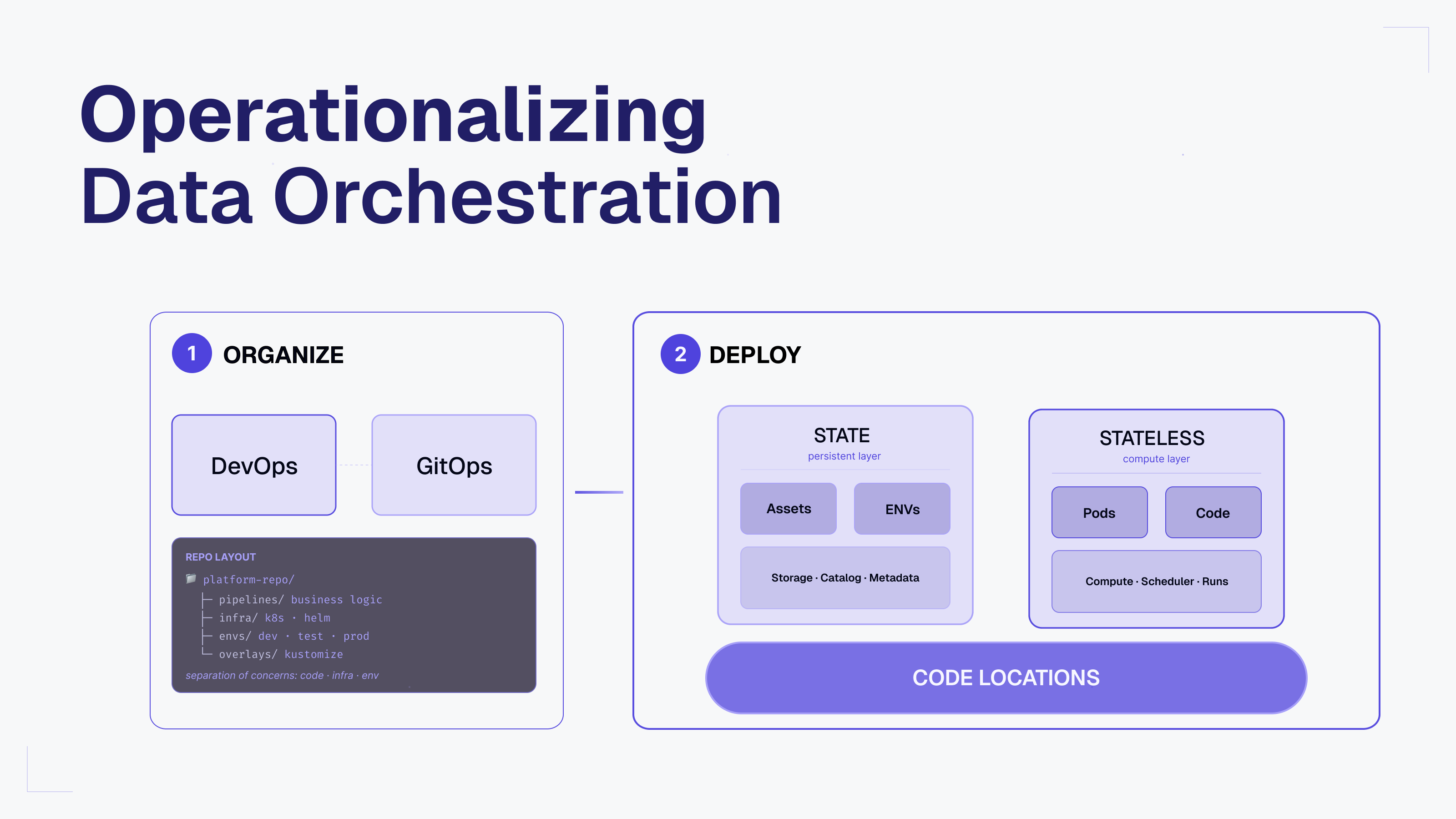
- InfoSec and data sovereignty were major considerations. Databricks, for instance, required that they ship some data into the Databricks environment, which was not an option for EvolutionIQ’s clients. Decoupling the DAG from the other components was critical to meeting regulatory requirements.
- Cloud-agnostic: Although the team was fully established in GCP, they wanted the flexibility of moving to other clouds if necessary.
- And the platform had to support a unified development framework in a common programming language.
Selecting the orchestration layer
EvolutionIQ’s DataStack 2.0 was going to need a solid orchestration layer, so the team evaluated the leading contenders: Airflow, Prefect, and Dagster.
Karan Uppal did the research, asking, “What does the right pipeline look like?” He questioned what engineers wanted to control and what should be handled by the tool out of the box.
A key focus for the orchestration layer: to optimize engineer productivity. A productive engineer is able to work on things that are both personally satisfying and most important to the business.
There were other obvious criteria for the team: observability of the pipeline runs; versioning; ability to repeat the pipeline easily; developer ergonomics; Python native; understanding of dependencies; extensibility.
The team needed an orchestration tool that could deliver the required functionality today but also demonstrated a strong commitment to a roadmap aligned with EvolutionIQ’s direction.
With requirements in hand, the team had to pick between the most widely adopted orchestrator (Airflow) or take a chance on something that was not used as widely.
Typically the team would opt for the proven, familiar solution. But when the idea of developing on Apache Airflow was floated, the team was divided. The solution had trouble giving users what they wanted, and EvolutionIQ’s use case was demanding.
Prefect seemed like a decent open-source option, but the team was underwhelmed by the vendor’s development and deployment philosophy as well as the firm’s long-term focus: it was clear from their hiring that the priority was on commercial exploitation before engineering or community efforts.
Enter Dagster…
The way things were designed in Dagster gave the team confidence they could expand the capability going forward. “For example, if you want to hold code and data together, DVC does that. But Dagster does that and other things. Airflow does not do that out of the box. You have to build that around it.” says Stanley.
Because the Dagster framework is very flexible, EvolutionIQ was able to implement a multi-tenant environment with separate I/O managers using Terraform.
EvolutionIQ does adhere to a disciplined deployment (dev | stage | prod), and Dagster supported this use case beautifully. It was clear EvolutionIQ would not have to run a new Dagster deployment per client. They could develop a single unified code base that could be deployed and configured for each client while being fully isolated and run under separate Kubernetes service accounts.
The EvolutionIQ team was confident they could design an architecture whereby they assign one service account with access to a single client, conservatively avoiding any leakage between clients, and repeat the design across environments.
When it came to testing, Dagster provides a strong suite of debugging capabilities, and pipelines could be re-run from one of any number of stop-points. Dagster’s interface would clearly be a great addition to the team's ability to observe pipelines and support clients if any issues arose.
"I've been building AI solutions at Google for ten years, and I now realize that a DAG for a feature store is absolutely the future. It enables incredible scale, consistency, and reliability. As a company, we'll innovate more, and that has immeasurable value to advancing our machine learning models and quality of the product." — Georg M Goerg (head of ML at EvolutionIQ, formerly Google AI)
Finally, the team was impressed by the support and responsiveness on Slack from the Dagster Labs engineers and the community.
… but, not so fast.
Was Dagster an overnight success with the whole development team? Not quite.
The first few months of implementing DataStack 2.0 were tough, and the orchestration layer was only one piece of it. The overall effort was a major ask: to maintain the stability of all client pipelines while redesigning the core platform.
Adopting any new technology is a hurdle. Luckily when it came to Dagster, EvolutionIQ had Stanley Yang as an internal evangelist.
Stanley invested time in sitting down with each team member as they built familiarity with the new toolset, reviewing how best to use Dagster. He coached the new engineers through any questions but also demonstrated the value of the orchestration capability and why this would get the team to a better place.
Stanley also kept a direct connection to the Dagster team to help iron out any issues.
Here’s Stanley’s take on the experience:
“The adoption curve is more of a mindset change. Dagster is quite flexible - which is good and bad - there are not always hard recommendations on how to do something yet. There is no single approach to how you write pipelines, so it’s easy for a less experienced engineer to go off the rails. In retrospect, we should have reached out for best practices and architectural review early on, then established a workflow around Dagster.“
Selling the team on using the framework was harder when faced with a short task that could be quickly executed in a tool they might be familiar with, like dbt.
“Sensors, repo, and schedulers all sit in the same code as your pipeline. This is also both good and bad. In some instances, when you are just running a transformation, it can be harder to explain to the team why the overhead of running in Dagster is warranted rather than running directly in dbt. This is challenging when you have customer demands and short periods to deliver a result.” says Stanley.
As with any powerful, versatile platform, it takes some investment to learn and tailor it to a specific context or need and to achieve the right developer experience in the long run. It is also important to create room for iteration.
For instance, by running dbt tasks from within Dagster, the team was able to have all executions tracked in a single system, which made it easier to understand what had happened, debug problems, and trigger downstream steps that depended on the dbt transformations.
“We learned a lot from our first prototype, and our understanding and appreciation of Dagster evolved as we used it, moving from a single client to multiple ones. Our second [build] was good,” says Stanley.
“We learned a lot from our first prototype, and our understanding and appreciation of Dagster evolved as we used it."
While it took time to bring all engineers on board and build familiarity with the system, the leadership team approached this in such a way that the adoption of Dagster provided incremental gains along the way, which helped achieve buy-in.
Putting new wings on the plane
Every data team whose outputs are critical to the day-to-day running of the business faces the same issue. How to put changes into production while minimizing the disruption to customers?
“Like putting new wings on the plane mid-flight,” as Tom describes it.
EvolutionIQ has customers in production, customers in a pilot phase, and new clients just starting.
So the approach was to build the framework for new client deployments and move accounts gradually: unify around a single code base, establish a deployment model, then clean up the tech debt gradually. The bar for changing things for established customers is much higher than it is for new ones, and you certainly can’t risk deploying in a half-finished state.
So they battle-tested on the newly developed pipelines, then reapplied the packets to the older clients. Having started on this journey about one year ago, the team is now migrating their final account to their DataStack 2.0.
Running on DataStack 2.0
The change took time and effort. Now, things are much better for the team.
Thanks to this new vision and new data stack, EvolutionIQ went from a two-month implementation timeline to getting new customers up and running in just a few days, mapping each clients' data to EvolutionIQ's unified schema.
“We now run in a multi-tenant environment on a single Dagster deployment. This did not come out of the box, but Dagster is quite flexible, so we were able to build this out,” says Stanley.
- Built for testing and debugging: Today the team has all the benefits of observability into the pipelines. Testing of new functionality, deploying ML model updates, and debugging are all radically improved. Now, if the team had a flaky job, they could work locally, kick it off from halfway through the pipeline, and rerun it. If needed, they could go back to the parent ID to see what had run. It was night and day compared to the prior setup. “It was like going from the cavemen shell script to a properly built platform.” says Stanley, “We now almost have breakpoints in our code and can just rerun from there. That’s a leveling up of the development workflow.” The team’s approach to breaking down the pipeline has also changed. They can now focus on building subcomponents that can be developed and tested individually.
- Better accountability: And working on a single platform improved accountability. With Dagster as the single plane of glass across all clients, engineers have shifted the mindset from dealing with the pipeline of individual clients to managing a multi-tenant platform. Dagster provides a unified framework and a centralized tool upon which the team could have a shared view and a shared responsibility for the quality. “Today, the engineers take accountability for the data pipelines for ALL clients. If any one of them is failing, it’s because the platform itself failed.” says Tom, “Now you own a system, you don’t own a client.“
- Moving to a higher level: As such, developers are now focused on more high-level problems: how to get the pipeline running faster and smoother? How can we sample the data? They have moved from “my pipeline is broken” to “how can we improve the process and the platform as a whole?” The more strategic engineers on the team are now able to zoom out and look at the runs holistically and ask themselves where they might have the most leverage in improving performance. They ask, “How can we simplify, sample, or reduce things down earlier in the pipeline and improve downstream processing?”
They have moved from “my pipeline is broken” to “how can we improve the process and the platform as a whole?”
- Accelerate adoption and open the data platform up to other practitioners: Onboarding new hires has become easier. They have a clearer framework to focus on and the I/O of each node helps paint a clearer picture of the pipeline structure. Today EvolutionIQ has four teams working hands-on with Dagster (data engineering, operations, applications, machine learning), and they are able to do so very autonomously. Having mapped the ingested data to a single unified schema, teams can write pipelines without help from data engineering. For example, the engineering team can make assets available to the Applications team that consumes the data artifacts, moving them to their own Postgres instance. It brings the teams together but also allows the teams to work independently, reducing dependencies.

With a new data platform in pace, Karan can now relax with Wrenny.
Lessons learned
Here are EvolutionIQ’s key best practices for implementing the orchestration layer using Dagster:
- Adopt a data platform approach early on to bring structure to the work, and allow the engineering team to focus on higher order issues.
- Create a vision with senior executive support, then have hands-on champions who can coach other engineers through the adoption of new tools.
- Carve out time for learning the tool and establish internal best practices for how you will implement Dagster - there are many ways to do something, but you benefit from standardizing. Tap into the Dagster team and the Dagster community on Slack.
- Do not focus on a big-bang release. Aim for incremental gains as you transition to the new tech stack.
Every start-up will face the same step-up moment that EvolutionIQ did: moving from prototyping and experimentation to a fully-fledged data platform. This is true whether your pipelines support internal processes or deliver critical customer-facing services. When you get to that stage, your choice of orchestration platform will be critical. Dagster gives you the flexible programming framework and robust development lifecycle needed in today's demanding data flows.
What’s next
So, where does the EvolutionIQ team go from here? David Loewenstern, Staff Engineer and original architect of DataStack 2.0, explains:
“DataStack 2.0 moved EvolutionIQ’s client delivery into a scalable, robust, cross-client data platform, but a key component remained in the sandbox: the training, tuning, and evaluation of new machine learning models. DataStack 2.1 will move these processes into the data platform by using Dagster for orchestration, coupled with Vertex AI for feature and tuning management. This will make the use of feature stores, metric stores, model selection and hyperparameter tuning across clients as seamless and scalable as delivery.”
Bonus content: EvolutionIQ's interview with Seattle Data Guy





.jpg)
.png)

.png)

