




Dagster Cloud, the enterprise orchestration platform that puts developer experience first, with fully serverless or hybrid deployments, is now here.
This post was published as part of a five-part series about why Elementl exists, why Dagster is our first project, and where things are going in the wake of our Series A funding. This post was updated in September 2022 after the GA launch of Dagster Cloud.
Dagster Cloud
Open-source code alone isn’t enough to empower every organization to build a productive, scalable data platform. For many enterprises, the stability, security, and scale of hosted services are key even when they’re adopting open-source technologies.
So we knew that in 2021, we would need to build a hosted service to extend the capabilities of open-source Dagster, simplify deployment, and help more organizations manage the complexity of their data platforms.

Reduce the incidental complexity of running a data platform, and unlock the potential of CI/CD
For data practitioners, any concern that isn’t tied to the business logic that actually creates data assets is incidental complexity. We think the role of tools and services is to offload as much of that complexity as possible, so practitioners can focus on the part of their jobs that actually delivers value.
Offload Ops Burden
Dagster’s open-source core is infrastructure-agnostic, so that sophisticated and opinionated data platform teams can adapt it to their unique needs and deploy it anywhere. But many teams don’t want or need to make those kinds of decisions.
In Dagster Cloud, we host the entire control plane of the orchestrator. That means practitioners don’t need to worry about infrastructure upgrades, database administration, scaling, uptime, or backwards compatibility. They can focus on building data pipelines.
Zero-downtime Deployments
Dagster’s core APIs make writing tests easy. This capability, and our philosophical commitment to testing, is unique to Dagster among workflow engines and data orchestrators. But writing tests is only half of the story. What happens when tests pass and it’s time to deploy your new pipeline code?
Dagster Cloud makes CI/CD simple, with straightforward APIs for zero-downtime containerized redeployments. We’ve built a GitHub Action on top of these APIs so you can clone a GitHub repository with a single click and set up a full CI/CD pipeline in minutes with minimal configuration. We’re also building more prepackaged solutions for common CI/CD configurations.
Deployment Previews: Vercel for Data Pipelines
Time and time again, the world of frontend development has proven the value of tight development and deployment loops. For us, the state of the art in frontend CI/CD is Vercel, which we use to build our documentation site. Vercel’s previews let us see what our site will look like with a change applied before we deploy it. Instead of reviewing the text of a styling change, we can view the end result of that styling change in a preview that mimics our production environment, right from a pull request.
With Dagster Cloud, we’re building this kind of collaborative workflow for data practitioners. When you push a change to your pipeline code, Dagster Cloud can automatically build a preview of your pipelines and attach it to your pull requests. This visual preview lets your collaborators inspect your pipeline using our rich UIs as part of the code review process. This is just the beginning of the collaborative development experiences we’re building.
Scale to meet your infrastructure and organizational needs easily and securely
Hosted, Battle-Tested Services
Dagster Cloud’s core services are built on the foundation of our open-source components, which are already battle-tested at scale. In Cloud, our more advanced infrastructure services and monitoring tools let us provide even more reliability. With a hosted service, you can rely on us to keep your control plane up and running—and scale elastically with your usage.
Our dedicated platform team keeps the control plane services up to date, with automatic upgrades and continuous improvements, while guaranteeing backwards compatibility with user code. Customers benefit from performance improvements, bug fixes, and new features, without having to upgrade their code in lockstep.
Hybrid Architecture: Own your code and your data
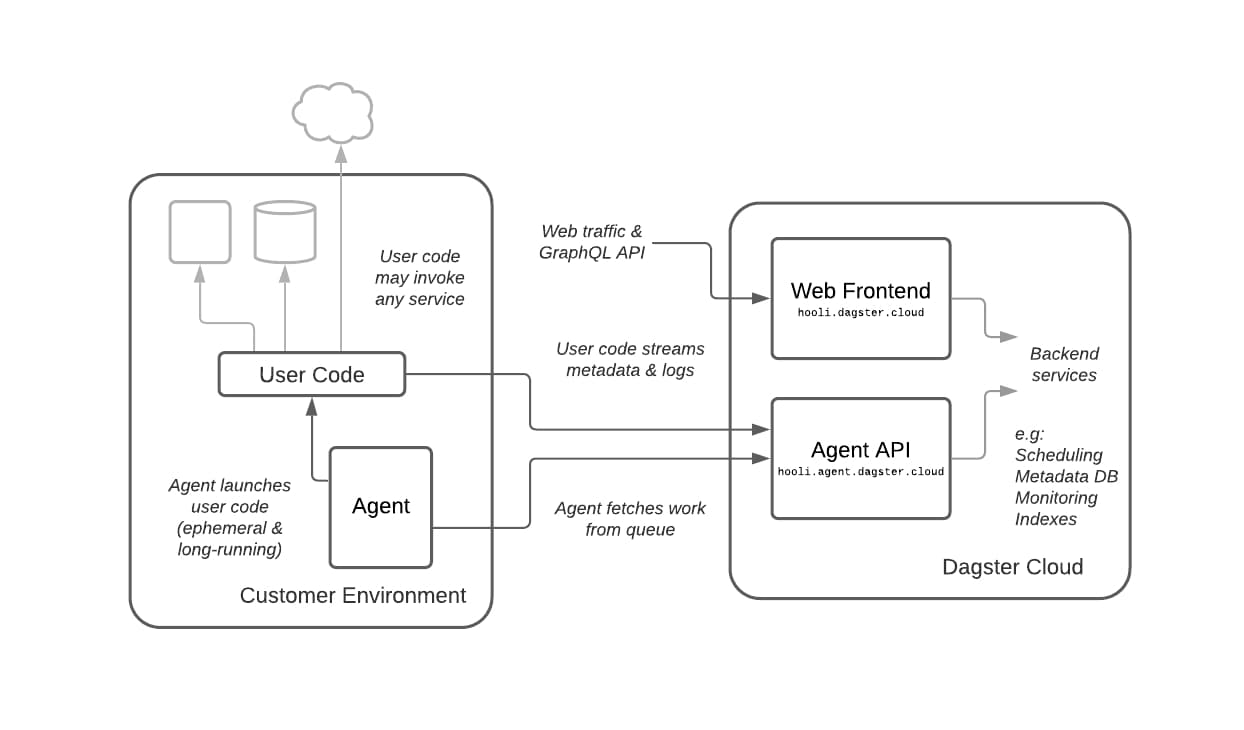
Dagster Cloud’s architecture strictly separates user code and data from the hosted control plane. All user compute is managed by a simple, open-source agent. The agent polls Dagster Cloud for work to be done and then launches user code as appropriate within the user environment. We’ve written agents that work with Kubernetes, container runtimes such as ECS and Docker Swarm, and locally on bare VMs—but the agent API is completely pluggable and agents can be written to run in any user compute environment.
Dagster Cloud is designed to run with cloud-native infrastructure. Task scheduling is distributed to remove centralized bottlenecks and enable massive horizontal scale. The agent is stateless—so orchestration can run on preemptible, on-demand computational resources like spot instances. And no ingress from Dagster Cloud’s hosted services into the user environment is required. Structured metadata and logs stream back from the user environment to Dagster Cloud over well-defined APIs, so deployment and network configuration are straightforward.
Scale across your organization
Scaling infrastructure is hard, but scaling across your organization can be even harder. Dagster Cloud is built to let teams operate and deploy autonomously without impacting other teams. When teams can change their environments on their own cadence (rather than a forced monolithic upgrade cycle), deploy on their own schedule, and operationally isolate themselves from their peer teams, they can own their data pipelines, assets, and environments end-to-end while taking advantage of a shared platform.
With Dagster Cloud, you can provision a completely isolated environment for a team with a click of a button or a single API call. Teams can run separate Dagster codebases in completely different environments, with separate Python versions and dependencies, system dependencies, operating systems, or compute substrates—while still making all of their metadata available on a shared, scalable multi-tenant data platform for collaboration.
Provide the right context about your data platform to the right stakeholder.
Unparalleled context for your data assets
A core design goal of Dagster is to provide complete context around every part of the data platform: your jobs, runs, schedules, sensors, and data assets. Context is the foundation of trust. Complete context means that errors are understood, diagnosed, and fixed quickly. Complete context means that you know when an asset was created, how it was created, who created it, and when it was created. That’s why all of our core APIs let users attach rich metadata to all kinds of artifacts.
When disparate teams start to work together using Dagster Cloud, the power of this interconnected, rich metadata starts to really shine. Users from different teams can navigate across code, runs, and assets to track down issues or quickly understand the state of existing work. And they can express cross-team dependencies natively, using Dagster’s built-in asset catalog.
Access for every stakeholder
Another of our core design goals is to expand the number of different stakeholder personas that can successfully interact with the data orchestrator. We think everyone affected by the data platform should be able to understand the state of data and where it comes from without burdening platform teams and practitioners. Stakeholders should be able to route their requests to the owners of individual data assets and processes, without spamming centralized channels. And even non-technical clients of the platform should be able to operate existing pipelines on their own.
Dagster’s intuitive, consumer-grade UI is at the heart of this vision: the single operational “pane of glass” that assembles all the disparate tools you use into a coherent data platform. In a multitenant, multi-team, enterprise context, Dagster Cloud’s hosted UI can be opened up to stakeholders across the organization without incurring any operational risk.
Enterprise auth and granular permissions
Within the enterprise, security concerns are paramount. You need to make sure that the right user has the right context—and that they can’t see, operate, or edit anything they shouldn’t. Dagster Cloud includes built-in integrations with enterprise SSO and auth providers, including Google, Okta, Azure Active Directory, and a wide variety of other solutions.
User permissions are granular and scoped at the team level, so you can grant limited access with confidence. User permissions make it possible to write tooling against the Dagster APIs. Without that, anyone may accidentally imperil operational stability. This kind of access control is crucial when opening up the data platform to new participants and personas.
Conclusion
We hope this has given you a taste of where we’re going and why with Dagster Cloud—and that you’re as excited about our hosted product as we are. While a hosted solution isn’t for everyone, it’s essential to ensure the long-term success of our open source project and will enable entirely new kinds of organizations to take advantage of our core tooling.
With Dagster Cloud, we’re working towards an ideal world: where a data practitioner writes their code, runs their tests locally, pushes their diff, and everything else just works. We want to make practitioners more productive than ever before; and we want to make the data platforms scalable, trustworthy, and collaborative.
We're always happy to hear your feedback, so please reach out to us! If you have any questions, ask them in the Dagster community Slack (join here!) or start a Github discussion. If you run into any bugs, let us know with a Github issue. And if you're interested in working with us, check out our open roles!
Follow us:





.jpg)
.png)



.png)

