July 8, 2019 • 12 minute read • ![]()
Introducing Dagster
Today the team at Dagster Labs is proud to announce an early release of Dagster, an open-source library for building systems like ETL processes and ML pipelines. We believe they are, in reality, a single class of software system. We call them data applications.
What is Dagster?
Dagster is a library for building these data applications.
We define a data application as a graph of functional computations that produce and consume data assets. In a Dagster-built data application, business logic can be in any tool; the graph is queryable and operable via an API; and actual execution is on arbitrary compute targets.
Builders can use the tool of their choice — e.g. Spark for data engineers, SQL for analysts, Python for data scientists — all while collaborating on the same logical data application. They do not have to abandon all their existing code or investments in those tools.
By adopting this library, builders and operators gain access to new tools, built on an API. These tools are meant for visualization, configuration, local development, testing, monitoring, and so forth. Because these tools built on an API, there is the opportunity to build an entire tooling ecosystem around this library, not just a set of first-party tools.
Dagster’s computational graphs are (a) abstract and (b) queryable and operable over an API, and therefore can be deployed to arbitrary compute targets. Example targets include Airflow, Dask, Kubernetes-based workflow engines, and FaaS (functions-as-a-service) platforms. This means that regardless of the physical compute infrastructure, builders and operators can both benefit from the shared programming model and tools.
We believe that adopting Dagster will immediately improve productivity, testability, reliability, and collaboration in data applications. If broadly successful, it will lead to an entirely new open ecosystem of reusable data components and shared tooling. The rest of this article will dive into the genesis of and inspiration for this project, the unique challenges of building data applications, more details on Dagster itself, and our road ahead.
Where did this come from?
I’ve been working on Dagster for over a year, but the bulk of my career was spent at Facebook on our product infrastructure team. Product infrastructure’s mission was to make our product developers more successful and productive. I worked up and down our technology stack, and ended up creating GraphQL, now a successful open source technology used by hundreds of thousands of developers.
But Dagster is not a technology for product developers. It is for data scientists, data engineers, analysts, and the infrastructure engineers that support them.
The move from focusing on product infrastructure to focusing on data infrastructure was an interesting transition. I left Facebook in 2017 and began to explore what to do next. As I was talking to leaders and practitioners inside Silicon Valley and in more traditional firms, the same refrain kept on coming up over and over again:
“Our data is totally broken”
My immediate reaction was confusion: How does one break data? I quickly came to realize that it wasn’t a technical or engineering problem statement. Instead, it was an instinctive recognition that something is wrong at a systemic level. Data integration, analytics, and machine learning are simultaneously some of the most important and least reliable systems in the modern enterprise.
It is difficult for leadership to get engineers to work on data management problems because they aren’t considered glamorous. Further compounding the problem, engineers and non-engineers who do engage report that they feel as if they waste most of their time.
How do they express this? If you’ve been to any conference with data engineers or data scientists, you’ve probably heard someone say something like:
https://twitter.com/BigDataBorat/status/306596352991830016Practitioners who aren’t Borat say something more like:
I spend 80% of my time cleaning the data, and 20% of my time doing my job.
Taking this statement literally, it would be logical to focus exclusively on making data cleaning faster. However this would be the classic mistake of blindly accepting what people say instead of figuring out what they mean.
They say they waste their time data cleaning, but what they mean is a whole host of other activities: Rolling their own custom infrastructure, maintaining unreliable processes built atop untested software, and the instinctive — and accurate — sense that they are doing repetitive work that should not be necessary. This is not about the speed of data cleaning, but problems at a deeper, structural level.
Where has this happened before?
Travel back in time to 2009 and talk to a frontend web engineer, and you would likely hear them say something like: “I spent 20% of my time building my app, and 80% of my time fighting the browser.”
Sound familiar? Just as data practitioners do today, frontend practitioners said one thing but meant another: They said they were fighting the browser, but what they meant is that they were using the wrong software abstractions.
If you were to take that same frontend engineer in 2009 and show them the developer experience today, their minds would be blown.



While the browsers did get better, it was ultimately the software abstractions and the ecosystem around them that proved decisive. In particular, React. Released in 2013, React was critical to this transformation, and it now dominates frontend development.
React defined its domain well, and then was able to solve entire classes of problems within that domain:
A [React] program is one that predictably manipulates a complex host tree in response to external events like interactions, network responses, timers, and so on. — Dan Abramov
Describing React in full is well beyond the scope of this article. For that we recommend:
https://overreacted.io/react-as-a-ui-runtime/React provided a novel, well-designed, higher-level component model over the native browser APIs. React took more formal engineering principles — functional programming in particular — and adapted them in a way that was intuitive to practitioners. It did all of this while being incrementally adoptable in existing systems.
React respected and acknowledged this new, emerging engineering discipline, and recognized the true, essential complexity of this class of software. These engineers were no longer just cobbling together scripts to animate a website; they were building fully-fledged frontend applications.
What does this have to do with data?
At Elementl, we believe that data processing is both in need of — and on the cusp of — a similar transformation that frontend needed nearly a decade ago.
Historically, these data processing systems have been organized as a set of jobs or scripts, loosely stitched together with a workflow engine. Or, they were assembled in a highly constrained, graphical tool or development environment meant to “abstract” away the engineer.
In modern systems, we believe they are more appropriately thought of as data applications.
They are complex pieces of software difficult to author, test, and operate. They are built collaboratively by a wide variety of personas using a vast array of heterogeneous tools. They are mission critical to businesses whose downtime can result in massive costs, convenience, and loss of efficiency. And the current software meant to structure these systems is woefully inadequate to the task at hand.
What is a Data Application?
Data Application (noun): Graphs of functional computations that consume and produce data assets.
There is a lot of terminology in this domain: ETL, ELT, ML pipelines, data integration systems, data ingestion, data warehouse builds, and so on and so forth. We believe that most of this terminology is outdated or duplicative: All of these terms in reality encompass a single, well-defined category of software systems.
Take ETL (Extract-Transform-Load). Historically this term was used to describe the process and tools used to transform — in a single batch process within a single tool — the data in a relational database with well-defined schema to a similarly schematized data warehouse structured for efficient analytical queries.

Today’s so-called “ETL” in no way resembles that. Practically speaking, it is shorthand for any sort of data processing. It typically has many stages of processing and materialization, in many different languages, runtimes, and tools, dealing with the full range of un-, semi-, and fully-structured data.
Given this redefinition, a modern-day “ETL” process has virtually the same structure as a typical SaaS (software-as-a-service) integration or an ML pipeline: they are all graphs of functional computations that produce and consume data assets. Only the final output differs: an ML pipeline the final step produces a model, whereas the final step of an ETL or a data integration process produces a dataset.
This class of software is increasing in both prevalence, importance, and complexity. Data, analytics, and machine learning are only becoming more widespread, valuable, and demanding over time. SaaS integrations are only increasing in number — a typical modern business uses dozens if not hundreds of SaaS services — and complexity. Finally, data applications also are ideal candidates for execution on emerging cloud technologies such as functions-as-a-service (FaaS) and infinitely elastic, interruptible runtimes. Both the dynamics of cloud computing and the increasing importance of data processing will compel more software to be written in this form over time.
What makes it hard?
Creating reliable data applications is a software discipline with its own unique challenges. Many of the best practices of generalized software engineering are not directly transferable to the data domain, and specialized approaches are needed. We’ll discuss three of the properties that are unique to the domain: their (1) uncontrollable inputs; (2) multi-persona and -tool nature, and (3) how difficult they are to develop and test.
Uncontrolled inputs
Data applications differ from traditional applications in that data application authors typically have far less control over their inputs. In a traditional application, if the user inputs data, the application can refuse to do the requested computation, present an error to the user, and have her re-enter the data.
This is not possible in data applications. Data applications are ingesting data from systems or processes that they do not directly control. If unexpected inputs break the computation, you can either update the upstream input — which is rarely possible — or update the computation — which is what almost always happens. Software abstractions and techniques in data must account for this unfortunate reality.
We believe that data quality tests — known as expectations within Dagster — are the critical tool for managing the complexity of data within these systems. An inspiration in this area is Abe Gong and the team working on Great Expectations. See this article for an excellent discussion of this issue:
https://medium.com/@expectgreatdata/down-with-pipeline-debt-introducing-great-expectations-862ddc46782aMulti-persona, multi-tool
The world of data is very heterogeneous, and that will not change anytime soon. Data applications are built and supported by diverse teams: business users, analysts, data scientists, data engineers, machine learning engineers, and traditional engineers. Each of those user types has domain-specific tools and languages that they are accustomed to and productive in. Data engineers might use Scala/Spark, data scientists might write Python within Jupyter notebooks, and analysts likely use SQL — all logically within the same data application.

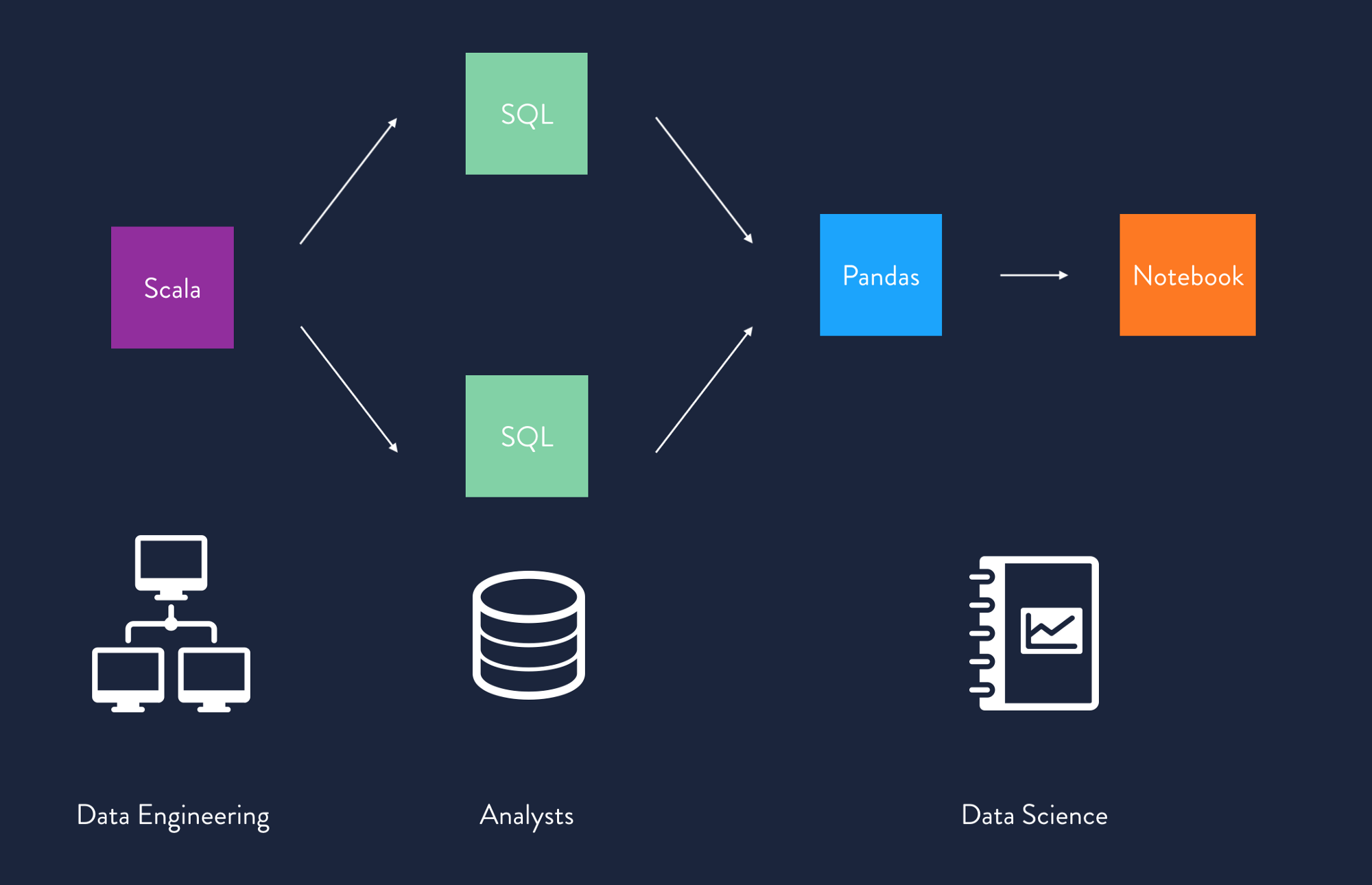
This leaves data applications in a state where computations are written in a wide variety of tools and languages, but without an integration layer to describe the meaning of those computations or the relationships between them. As a result, massive amounts of metadata and context is often lost as data is flowed from tool to tool, and there is no standard for interacting with the computations crafted within those tools. Up until now, the focus of higher level tools has been the mechanics of the physical orchestration of those computations — ensuring correct ordering, retries, and so forth — and not the semantic meaning of those computations. This is the gap that Dagster is designed to fill.
Difficult to develop and test
Data applications are notoriously difficult to test and are therefore typically un- or under-tested. The reality of most existing code is that it is deeply coupled to its operating environment and difficult to test in isolation and reused in other contexts. Even in teams that focus on testing, this testing usually occurs far too late in the process, perhaps as a late stage integration test immediately before deployment. More testing should be in the critical path of the developer workflow or in an earlier stage CI/CD pipeline.
Frequently much of the business logic of a data computation is executed in a heavy external dependency such as a data warehouse (e.g. Redshift, Snowflake) or a distributed computational runtime such as Spark. Reconstructing this business logic for local development and testing is generally not worth the effort and introduces an entire new layer of software that must be correct and itself tested.
Data applications are also often high latency and computationally intensive. This — in combination with the coupling to the production environment — can cause extraordinarily slow developer feedback loops, measured in hours when it ideally should be seconds. This not only slows down business logic development, but also makes it expensive and risky to restructure and refactor code. These factors compound, resulting in software that is difficult to test; expensive and risky to change; and, as a result, often have low code quality.
Dagster does not “solve” testability. What we do believe is that in the current state of affairs high quality testing early in the developer workflow is essentially impossible in most data systems. We’re not claiming to make the impossible easy; we are claiming that we can make the impossible possible.
Enter Dagster
These pain points highlight what we believe is the absence of a fundamental layer of abstraction in the data ecosystem today: A layer that models and describes the semantics and meaning of an application’s computations and produced data assets, rather than just the scheduling and execution of those computations.
We believe deeply that data engineering should adopt a coarse-grained functional programming model. We were inspired and heavily influenced by this article by Maxime Beauchemin, the creator of Apache Airflow:
https://medium.com/@maximebeauchemin/functional-data-engineering-a-modern-paradigm-for-batch-data-processing-2327ec32c42a
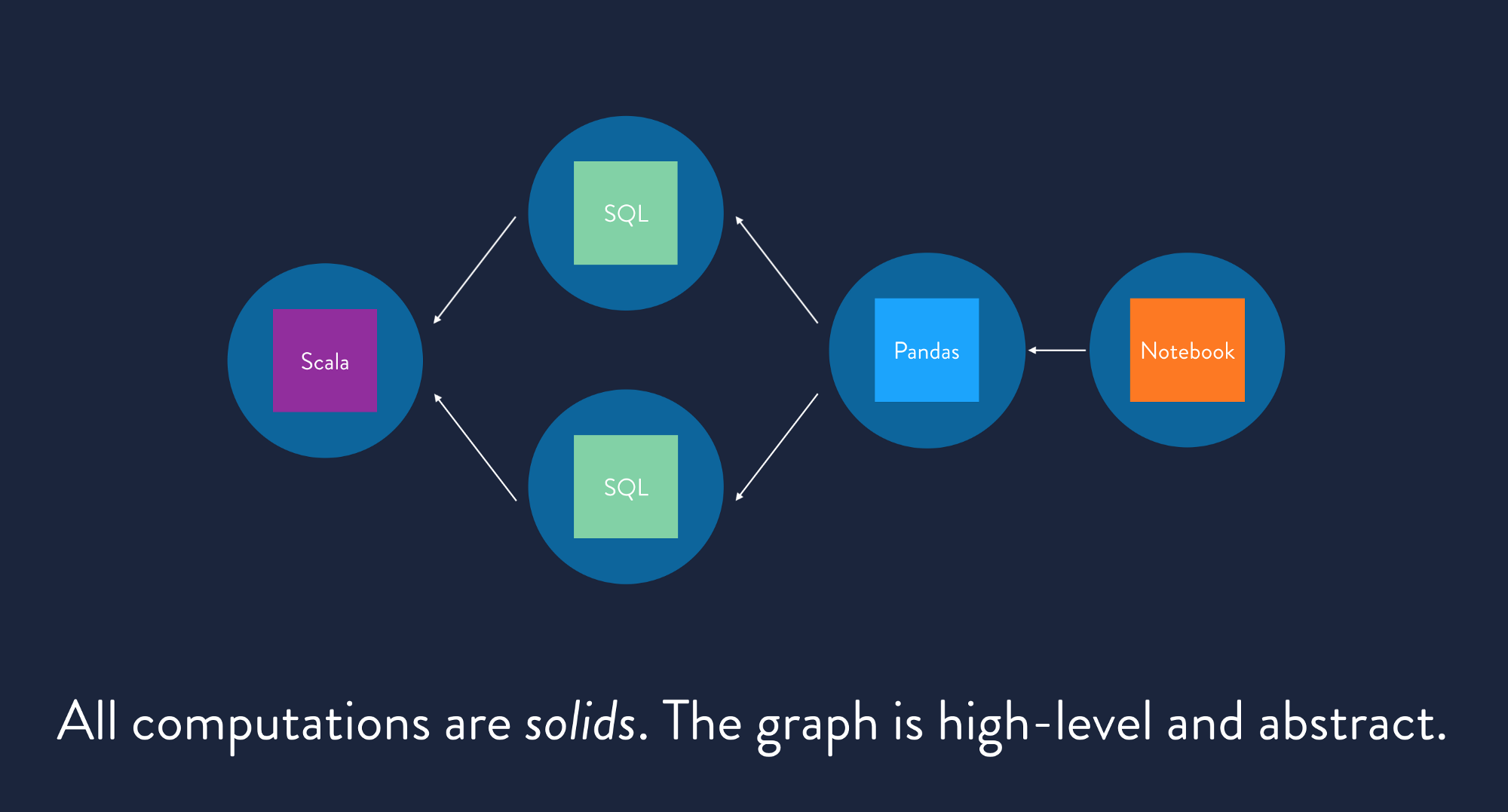
Once the computations have been structured to be plugged into the Dagster system, they are accessible via an API. Through the API you can use high quality tools built on top of that API, including local development tools and integrations with existing infrastructure and ops tools.

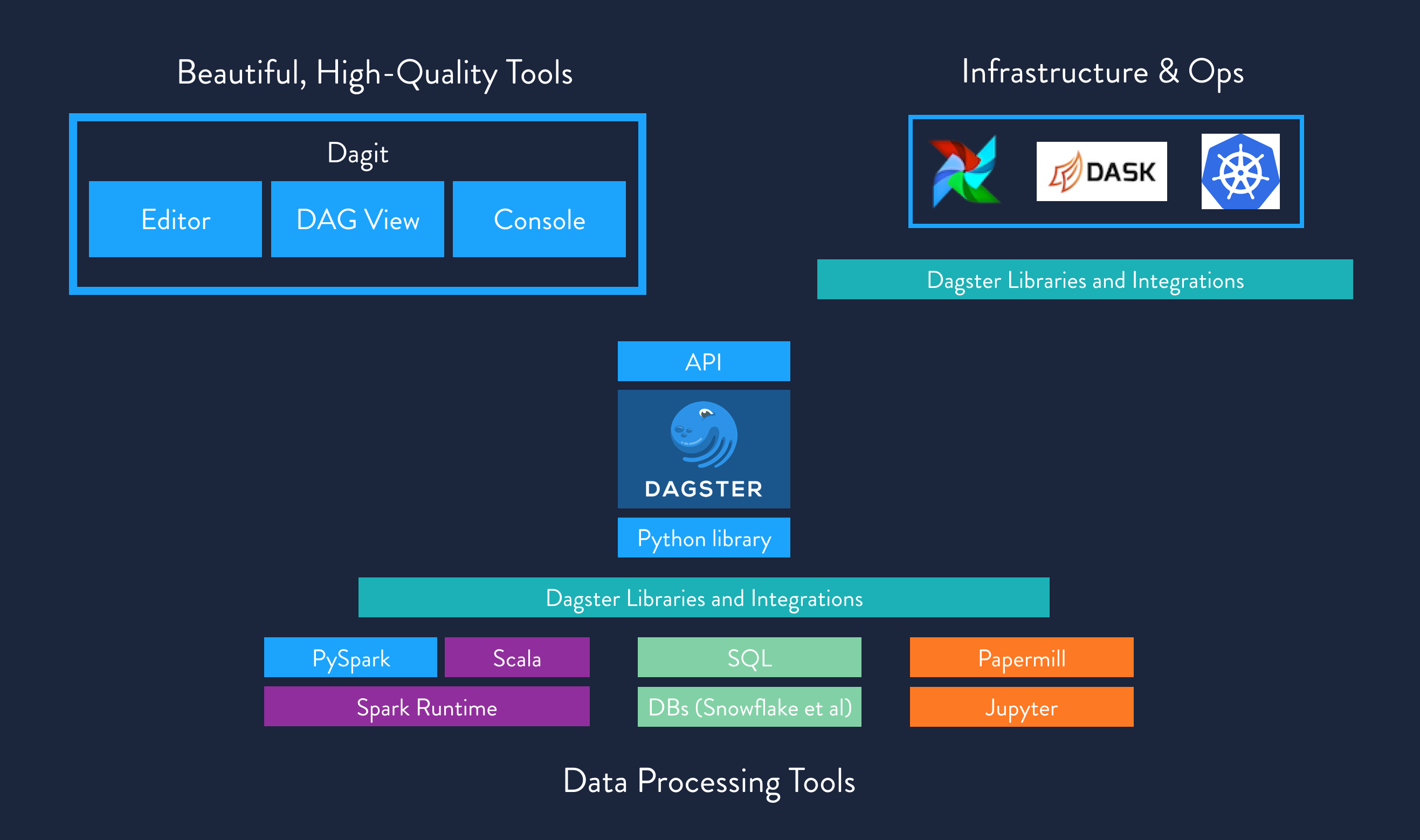
Data applications built with Dagster will have the following properties:
- Queryable, operable, and monitor-able by tools through an API.
- Constructed with data dependencies, rather than just execution dependencies. In addition to defining the execution order of computation within a graph, Dagster also expresses data flowing through a graph.
- Self-describing with well-defined metadata, consumable by users and tooling alike.
- Business logic defined in your tool of choice, from Spark, to Python, to SQL, to Jupyter notebooks, or any arbitrary computation.
- Executable in a number of environments — locally, within CI/CD pipelines, staging, production so forth — by having first-class abstractions that allow an author to modify their computing environment/context while leaving their business logic unchanged.
- Designed for local development, with an out-of-the-box IDE-esque tool called Dagit.
- Monitorable by emitting a structured stream of events during computation, rather than solely relying on unstructured logging. These events describes the semantic meaning of a computation using a well-defined API, consumable and interpretable by tooling.
- Able to describe their data using a type system which is gradual, flexible, and optional, allowing for incremental adoption. It is designed to supplement, not supplant, the type system of language or system that defines the actual computation.
- Designed for reuse. Solids describe their metadata, types, configuration, and resource requirements and are potentially reusable within many contexts.
- A typed configuration system, which enables high-quality error messages and tooling support, such as the config editor provided within Dagit.
- Targets existing computational infrastructure — e.g. Kubernetes, Airflow, Dask, FaaS platforms, etc— for scheduling and execution in a pluggable fashion. Airflow and Dask initially supported.
Explore our codebase and documentation to see how Dagster actually implements and embodies these properties.
The Future as We See It
There are deep, systemic issues in the data domain, and these issues often end up being expressed by practitioners saying that they spend only 20% of their time (or less) doing what they believe is their core activity or job.
How does a system like Dagster move the needle on these issues?
We do not claim that this is an immediate, out-the-box solution to all of the pain points of building modern data applications. What we do believe is that this is a new way to structure these systems, and as well as the basis a surrounding ecosystem to make it possible to solve address these issues in a more collaborative, systematic fashion.
Fast forward a few years and we hope to see a world where people are using a diverse set tools building coarse-grained computations in a format that makes the programmable and reusable. We hope to see a world where the solid is a standardized way to describe and package a data computation, where authors and operators of data applications build within that common standard.
This ecosystem would be more interconnected and collaborative, with reusable, well-tested, and flexible data computations. They would be packaged and shared both within and between organizations; crafted by a diverse set of personas and people — from analysts to data scientists to engineers — using the tools they know and love; and deployed and operationalized programmatically with dramatically less duplicative infrastructure.
This future vision is aligned with how Chris Bergh and the team at Data Kitchen envision when they describe the term “DataOps.” We’ve been inspired by their work. We highly recommend this podcast for an overview of DataOps:
https://www.dataengineeringpodcast.com/datakitchen-dataops-with-chris-bergh-episode-26/What’s happening today
Today we are releasing an early version of our core library and programming model.
We are also releasing Dagit, an IDE-like tool for local Dagster development. It’s a beautiful tool that will provide immediate value and productivity gains in your developer workflow:

We also ship with early versions of out-of-box integrations with existing tools: data processing systems such as Spark, PySpark, and Pandas; cloud providers such as AWS and GCP; workflow engines such as Airflow and Dask; as well as ops tools like DataDog and PagerDuty:

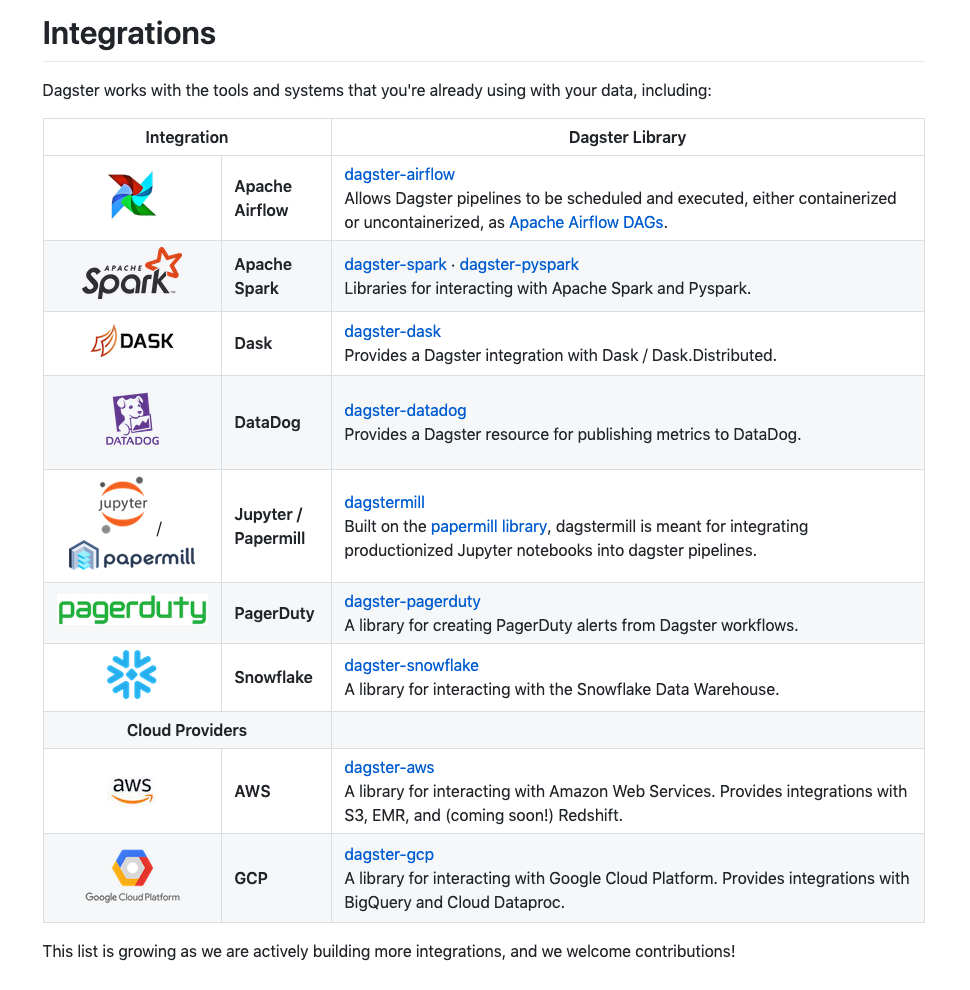
We are still very early in this multi-year process. This early version of the software that we believe is very promising and can deliver immediate value today, but still needs to be battle-tested and validated with more real-life use cases. We are looking for partners on that journey. While we welcome all users, we really want to deeply collaborate with a few teams building complex data applications.
If you are interested in doing that please reach out to me (DMs open on Twitter (@schrockn), email us directly (hello at elementl dot com), or sign in to our slack instance (link is on the GitHub site). We want to work a small number of highly aligned teams so we can deeply engage, consult directly, and respond to feedback quickly.
We are also hiring for our fantastic and growing team:


We are looking for engineers, data engineers, data scientists, and infrastructure engineers with a passion for productivity tools. Those who believe in the ability of tools and software abstractions to reshape not just the developer workflow, but the structure of organizations and industries. Please reach out to join our San Francisco-based founding team!


We're always happy to hear your feedback, so please reach out to us! If you have any questions, ask them in the Dagster community Slack (join here!) or start a Github discussion. If you run into any bugs, let us know with a Github issue. And if you're interested in working with us, check out our open roles!
Follow us:


Dagster 1.7: Love Plus One


- Name
- Fraser Marlow
- Handle
- @frasermarlow

Dagster 1.6: Back to Black

- Name
- Sandy Ryza
- Handle
- @s_ryz

Dagster 1.5: How Will I Know?

- Name
- Yuhan Luo
- Handle
- @yuhan