




Partitioning is a technique that helps data engineers and ML engineers organize data and the computations that produce that data.
If you build or operate data pipelines, there's a good chance you think a lot about, or should think a lot about, partitions. Partitioning is a technique that helps data engineers and ML engineers organize data and the computations that produce that data. Partitioning also makes data pipelines more performant and cost-efficient by letting them operate on subsets of data instead of all of it at once.
The idea behind partitioning is that a data asset can correspond to a collection of partitions that are tracked and computed independently. Typically, each partition corresponds to a separate file, or a slice of a table in a database.
For example, you might have a daily-partitioned table where each partition corresponds to the set of event records that arrived on a particular day. At the end of each day, you fill out the partition for that day.

Or you might process data separately for each of your customers. Each customer submits their data as a file on S3, and you want to take each file and derive refined datasets or ML models from it. Each derived data asset is partitioned by customer.
Partitioned data assets - best of both worlds
A partitioned data asset is a way of modeling data that lies between (a) a single monolithic data asset and (b) a set of distinct data assets.
It's similar to a single monolithic data asset, because all the partitions are computed using the same code, and they're derived from the same upstream data assets (usually also partitioned). This makes them easy to visualize and operate on in bulk. For example, it's common to want to backfill all partitions at once: if you change the logic that determines how your data is derived, you likely want to re-derive it for all those hours in the past or all those customer files you processed previously.
However, a partitioned data asset is also similar to a set of distinct data assets, because the partitions within an asset can function independently: when debugging, you might want to look at the logs that correspond to a particular suspicious date. If your customer tells you they resubmitted their data because of a problem with the earlier version, you likely want to re-run your pipeline on just that single customer file.
Partitioned data pipelines
A graph of data assets that are partitioned in the same way naturally forms a partitioned data pipeline. You can often think of a partitioned data pipeline as a collection of miniature data pipelines that all have the same topology.
Partitions and data orchestration
To effectively orchestrate data pipelines, data orchestrators need to understand partitions.
Data orchestrators are systems responsible for running data pipelines and keeping data assets up-to-date. Orchestrators answer questions like "what needs to run?" and "what did I run?" The most useful answers to those questions often involve partitions: e.g. "I need to fill in the users table for hour X" or "I generated the ML model for customer Y". To kick off the right computations, you need to know what partitions you need to target. To understand whether a partitioned asset is up-to-date, you need to know when each partition was last updated.
Without an understanding of partitions, a data orchestator can only give an answer like "I executed something that changed the users table". Unless you overwrite the entire users table every time you update it, this answer doesn't get you very far: is the users table up-to-date? Is it missing data? Do more runs need to be launched to get it up-to-date? And if the data for a particular date looks strange, there's no clear way to find out what run produced the data for that date. For many data engineers, this is the status quo, and it results in uncertainty, less trustworthy data, and painful debugging.
Partitions at the orchestration layer sometimes, but don't always, correspond to partitions at the storage layer. Systems like Hive have an explicit notion of partitions: each partition in a table typically corresponds to a subdirectory in the directory where the table is stored, and it's typical for orchestration partitions to correspond to Hive partitions. In contrast, data warehouses like Snowflake abstract away storage entirely and have no explicit notion of partitions.
But even when the storage system doesn't understand partitions, partitions are still useful at the orchestration layer, because they help organize the operations that you perform on your data. It's common for a single Snowflake table to correspond to many "logical" partitions: e.g. when you overwrite the data for partition 2022-02-04, you delete all the rows that have that date and then insert a new set of rows for that date.
It's also worth noting that data processing engines sometimes have partition concepts that aren't relevant at the orchestration layer. For example, Spark splits DataFrames and Datasets into partitions in order to perform work in parallel. Similarly, Kafka partitions enable distributing Kafka topics across multiple machines. These kinds of partitions aren't important for an orchestrator to understand, because they're purely used for performance, not related to how users think about organizing their data.
Orchestrators that think primarily in tasks, like Airflow, aren't well-suited to model partitions, because partitions are fundamentally a property of the data, not the task. Airflow has some functionality, like its grid of historical runs and the ability to parameterize DAG runs with an execution_date, that resembles an understanding of partitions. However, this functionality only works well in a narrow set of cases - e.g. it requires that all data updated by the DAG is partitioned in the same way and that partitions are one-to-one with task runs. When pipelines don't fit these constraints, this support can actually increase confusion by mispresenting what's going on in the data pipeline.
Where partitions get complicated
The relationship between partitions and computation can get complicated. In the simplest case, every time you run your data pipeline, you operate on a single partition that's shared by all the data assets in the pipeline.
But life often isn't that simple. Realistic data pipelines combine different data sources, different shapes of data, and different cadences of updating data. Let's look at five examples of ways that partitioning can get complicated.
Different data assets, different partitions
It often doesn't make sense to partition all your data assets in the same way. For example, you might have a daily-partitioned table that depends on an hourly-partitioned table. Each partition in the daily-partitioned table depends on 24 partitions in the upstream table.
Depending on earlier or later partitions
Even when data assets are partitioned in the same way, the dependencies between partitions might not be straightforward. For example, each daily partition in a table might depend on partitions corresponding to prior days in an upstream table – this could occur if the calculations for a given day in the downstream table are based on moving average over the last week of data in the upstream table. Or each partition of a dataset might even depend on earlier partitions of the same dataset.
Ranges of partitions in a single task
You often don't want to run a separate task for each partition. If you're performing a backfill and using a massively parallel warehouse like Snowflake or compute engine like Spark, then it's often wisest to delegate the parallelization to that system and kick off a single run that covers multiple partitions.
Multi-dimensional partitions
It often makes sense to organize partitions along multiple axes. For example, one axis might be customer ID, and the other axis might be date. This allows enables launching computations to refresh the data for a particular customer for a particular day, as well as tracking which customer-date combinations you never filled in the data for.

Dynamic partitions
Sometimes you don't know the set of partitions ahead of time, and you want to be able to add and remove partitions dynamically. For example, maybe you want to add a new partition every time a new data file lands in a directory. Or every time you want to experiment with a new set of machine learning hyperparameters.
Dagster and partitions
As a data orchestrator, Dagster strives to fully model the relationship between computation and data. To this end, Dagster has deep and flexible support for modeling partitioned data assets and data pipelines. It handles all the complex interactions between partitions, assets, computations, and time that are outlined above. This distinguishes it from orchestrators like Airflow and Prefect, which aren't well positioned to model partitions because they focus on tasks, not data.
from dagster import DailyPartitionsDefinition, HourlyPartitionsDefinition, asset
@asset(partitions_def=HourlyPartitionsDefinition(start_date="2023-01-01-00:00"))
def events():
...
@asset(partitions_def=HourlyPartitionsDefinition(start_date="2023-01-01-00:00"))
def logins(events):
...
@asset(partitions_def=DailyPartitionsDefinition(start_date="2023-01-01"))
def logins_cleaned(events, logins):
...Here's a Dagster data pipeline made up of three partitioned assets:
Python
Here's how it shows up in Dagster's UI:
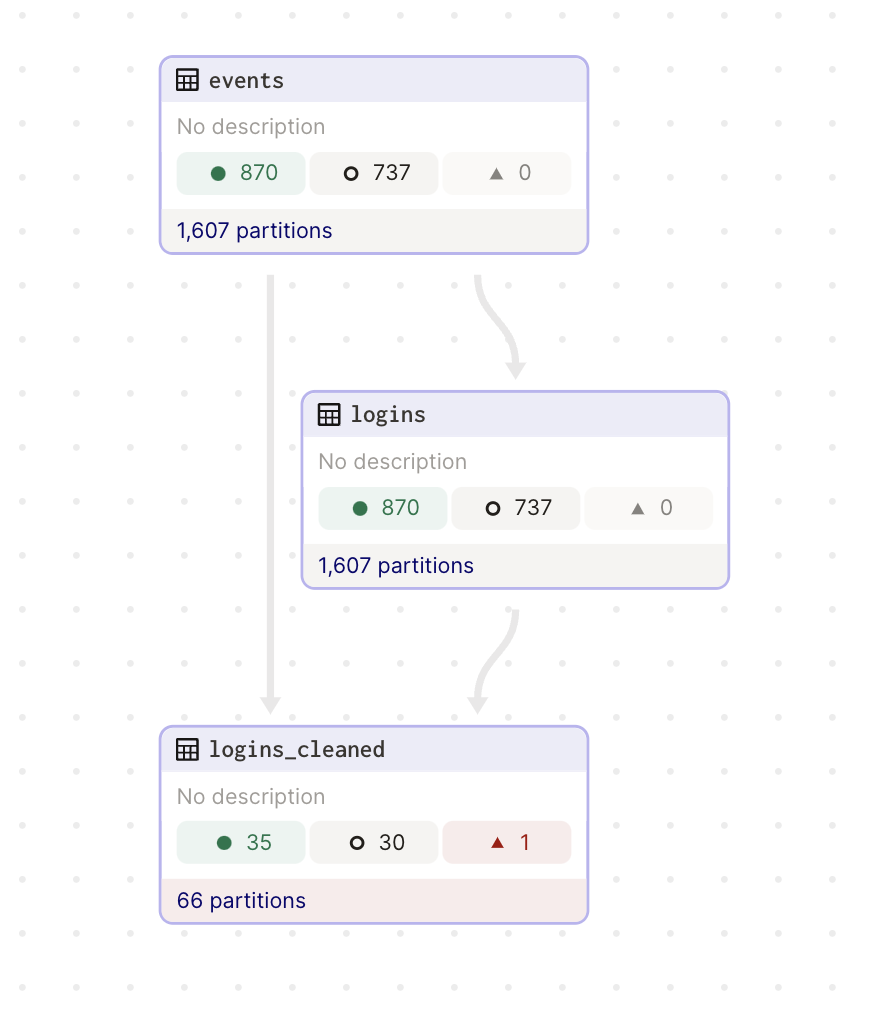
Dagster supports partitions by allowing each Software-defined Asset to be assigned a PartitionsDefinition, which determines the set of partitions that make it up. Different subtypes of PartitionsDefinition correspond to different kinds of partitions. For example:
- An
HourlyPartitionsDefinitionpartitions the asset by hour. - A
StaticPartitionsDefinitionpartitions the asset by a fixed set of partitions, e.g. a partition for each country. - A
DynamicPartitionsDefinitionallows adding and removing partitions dynamically. - A
MultiPartitionsDefinitioncombines sub-partitions-definitions to partition the asset along multiple dimensions. E.g. an asset can be partitioned both by "date" and by "region".
You can understand the aggregate status of an asset across all of its partitions, as well as drill down into an individual partition to find metadata about the partition's contents and logs for the computation that produced it.

Partition dependencies in Dagster
When a partitioned asset depends on another partitioned asset, each partition in the downstream asset depends on a partition or multiple partitions in the upstream asset. Dagster has default dependency rules that create the expected partition dependencies in most situations. Users can override them by supplying a PartitionMapping, e.g. to handle a rolling window situation where each daily partition of an asset depends on the prior three daily partitions of an upstream asset.
Modeling partition dependencies in the orchestrator is important, because these data dependencies determine what makes sense to run before what else. If you have a rolling window dependency and you update one partition of the upstream table, you'll need to update multiple partitions of the downstream table if you want to accurately reflect that update.
Partitioned runs and backfills in Dagster
Once you've defined a graph of partitioned assets, you can kick off runs that materialize the same partition across a set of assets: "run my entire pipeline on the data for yesterday".
You can also kick off "backfills", which operate across multiple partitions. Backfills can even span assets that have different partitions. For example, if you have a daily-partitioned asset that depends on an hourly-partitioned asset, you could launch a backfill that materializes all the hour and date partitions in a given range.
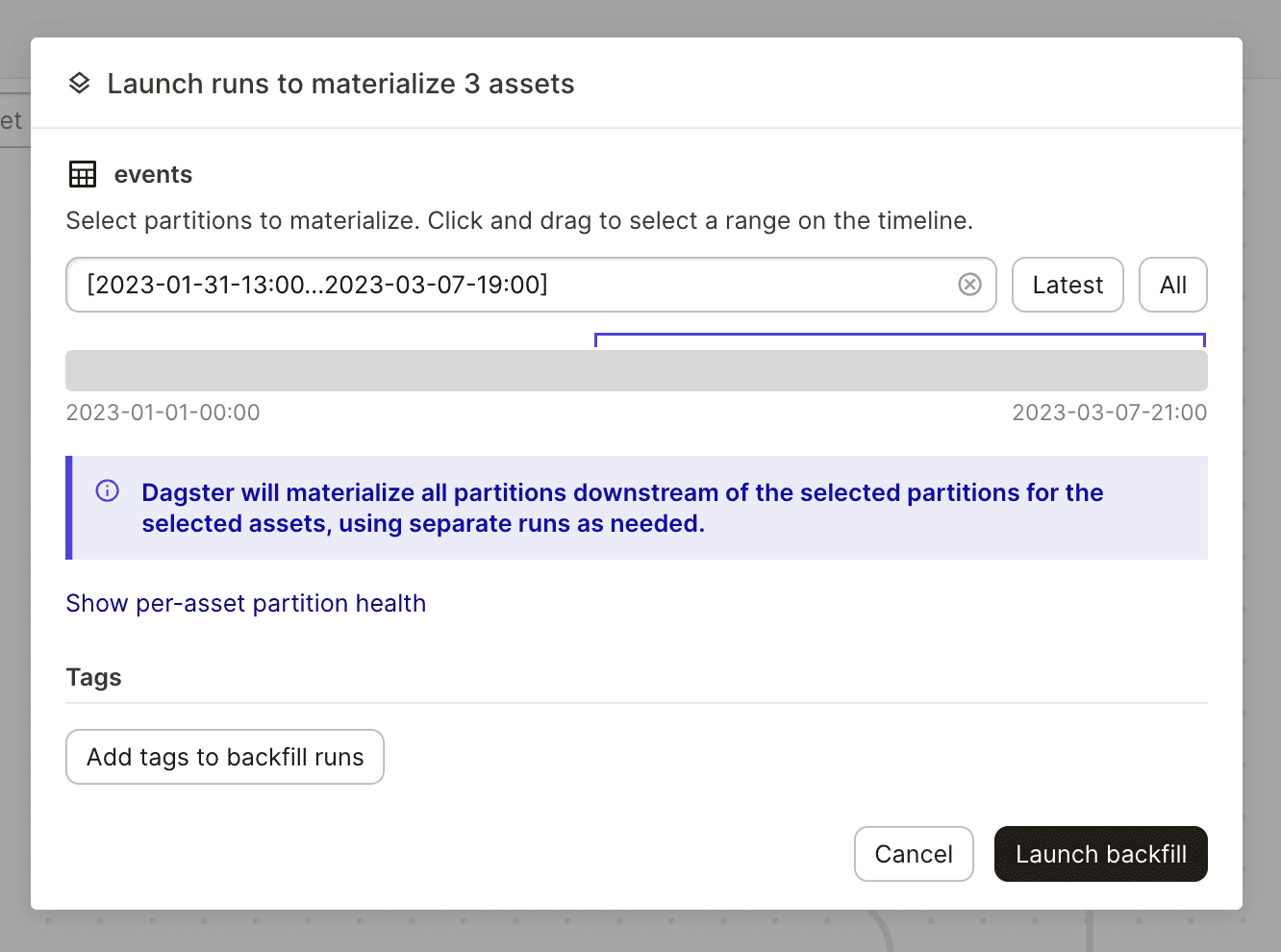
By default, a backfill launches a separate run for each partition. However, for backfills over time-partitioned assets, you can cover a range of partitions in a single run. This allows you to run your backfill as a single Snowflake query, for example, instead of one Snowflake query for each partition.
Partitions and auto-materialize
Dagster's auto-materialize system is also partition-aware. If you attach an eager auto-materialize policy to an asset, its partitions will be automatically materialized after their upstream partitions are materialized.
Conclusion
Partitions are a fundamental abstraction in data engineering that allows scoping operations to known subsets that matter in a particular context. They help write more performant and cost-efficient data pipelines, as well as structure them in a way that limits risk and makes them more observable.
For an orchestrator to be a data orchestrator, it needs to be able to faithfully answer questions like "is my data up-to-date?". When data is partitioned, this requires understanding the partitioning of the data and how partitions are connected in the data graph.
Unlike other orchestrators, Dagster has an deep understanding of partitions, which allows it to faithfully model the relationship between the computations it runs and the data those computations produce.
Dagster’s dynamic partition definitions allows engineers to use the power of partitions in a broader range of scenarios. See: Introducing Dynamic Definitions for Flexible Asset Partitioning.





.jpg)
.png)



.png)

