




Dagster’s dynamic partition definitions allow engineers to use the power of partitions in a broader range of scenarios.
Modern data pipelines are often responsible for applying consistent computations to diverse batches of data. For example, every time a file arrives in a directory, you might need to parse it and build a dataset of statistics derived from it.
When working with small numbers of data assets, you can understand their lineage and discern which are up to date. But what happens when you need to process thousands of data entries from different sources? If a single data entry is corrupted, you don’t want to have to regenerate all of your data outputs. Or if you receive new data entries, how do you recognize which ones are duplicates you’ve already processed?
In this post, we will explore Dynamic Partitioning in data pipelines, a strategy for enabling a single pipeline to process items selectively from a data collection, rather than managing a different parallel pipeline for each data asset in the collection. We developed this feature in response to feedback that users liked our declarative asset model, but found it restrictive in common situations. We believe this solution offers the best of both worlds, with both flexibility and declarative data management capabilities.
If you were looking for a broader explanation and examples of partitioning, we recommend Sandy Ryza’s recent blog post “Partitions in Data Pipelines” and his article "Backfills in Data & Machine Learning: A Primer."
Declaratively Defining Partitions: Unlocking Granular Control
The idea behind partitioning is that a data asset can correspond to a collection of partitions that are tracked and computed independently. Typically, each partition corresponds to a separate file, or a slice of a table in a database.
Building your data pipeline with partitions enables your pipeline to (a) track the full set of partitions and (b) operate on subsets of your data. In doing so, you unlock granular control over your pipeline.
Declaratively define a new partition
Say you have a data pipeline responsible for processing a collection of files in a directory. If you declaratively define a new partition in your data pipeline for each file in your folder:
- You can detect when new files exist and kick off processing for just these files without re-processing past files.
- If certain files contained corrupted data, you can reprocess just the affected files.
- If there was an error in your processing logic, you can run a backfill that re-processes all your files.
Prior to Dagster 1.2, Dagster had support for partitioned data pipelines where the set of partitions was known up-front. In code, you could either say something like “create a partition for every hour” or “here’s a list of partitions”.
However, you don’t always know the set of partitions up-front. Consider the following situations:
- Unknown arrivals: you want to process each file in a bucket, but you don’t know what files will arrive or when they will arrive.
- Ad-hoc parameters: you have an ML pipeline, but you don’t know which hyper-parameters will be used in the future to generate ad-hoc models.
In the next sections we’ll explore how Dagster can represent these unknown partition spaces while still providing the observability and control that declarative data management offers.
Dagster's Solution: Dynamic Partitions
In Dagster, a data collection where each element is produced by the same computation can be modeled as a partitioned asset. When the partition space is unknown at definition time, you can represent this as a dynamically partitioned asset. For these assets, partitions can be added and removed dynamically, via code or the UI.
Modeling each data output as a partition, as opposed to its own data asset, ensures that even with thousands of items in your data collection, the data lineage remains clear and digestible.
If you were to represent each of these partitions as its own asset, then the asset graph would get overwhelmingly (and unnecessarily) complex, and it would be difficult to operate on many partitions at once.
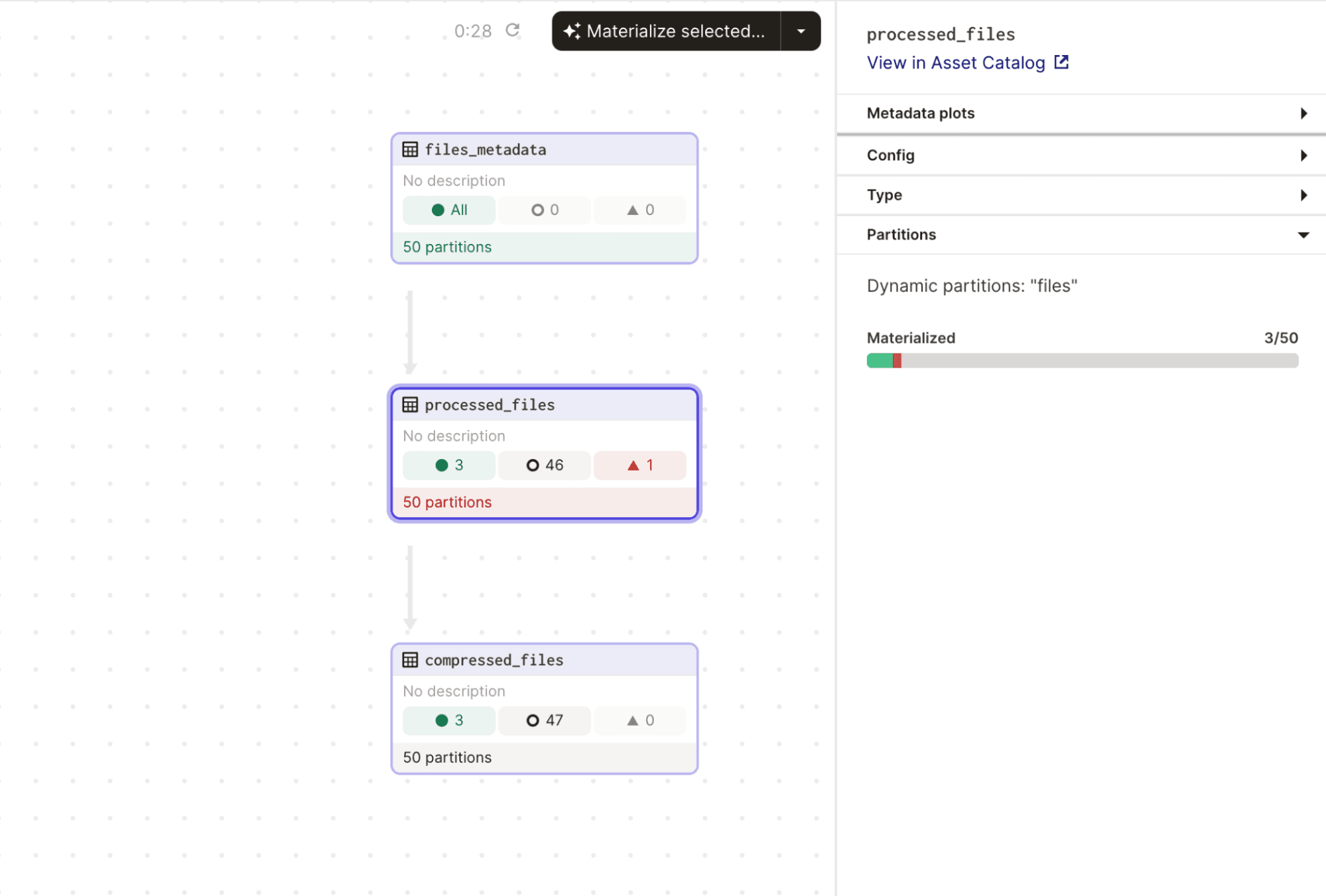
A birds eye view of your data pipeline
Using the asset graph view, you can observe the status of each object in your data pipeline at a high level. Because each element in your data collection is represented as a partition, you can easily identify which new partitions exist and require processing.
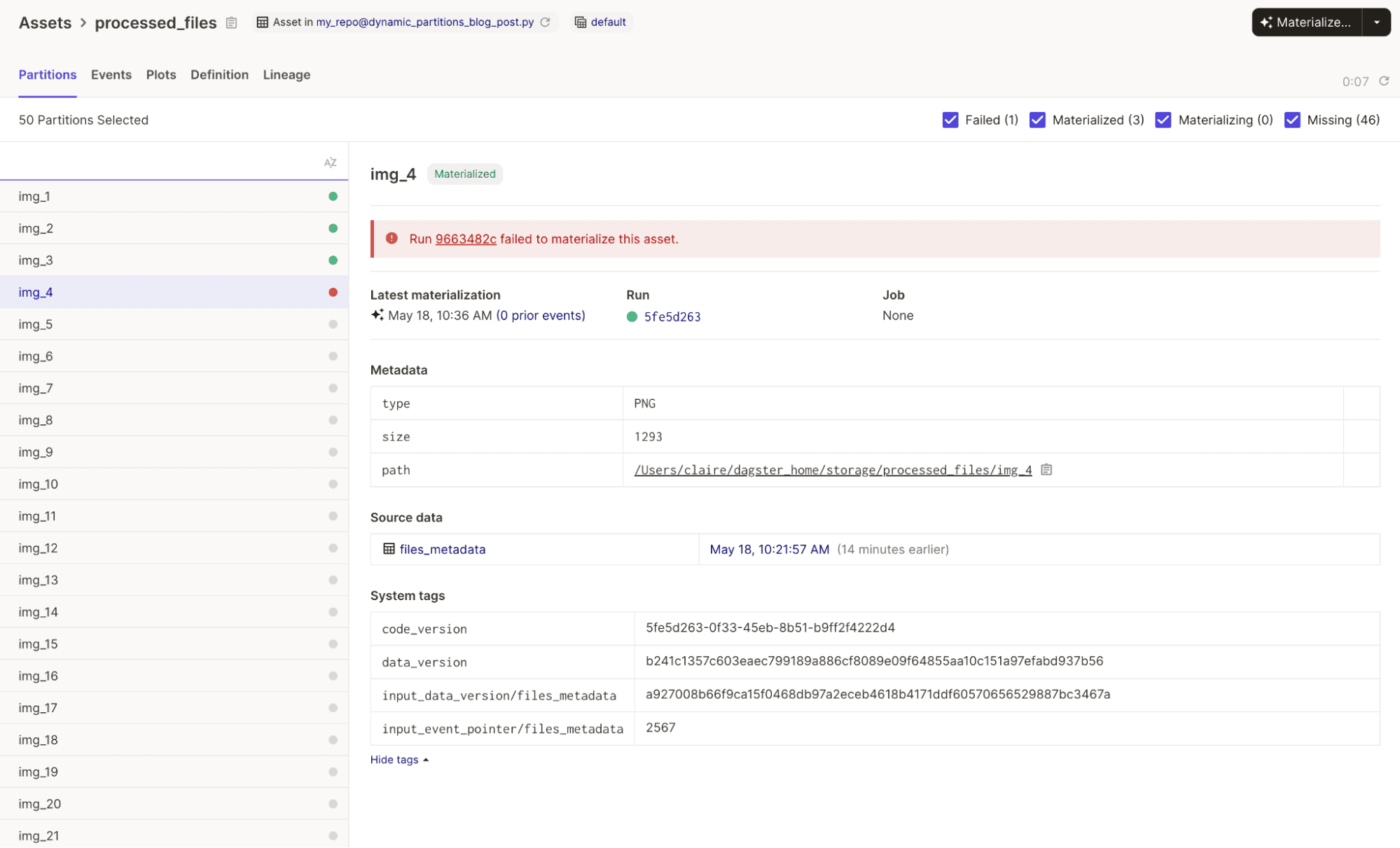
Troubleshoot bugs
You can easily spot corrupted partitions that might be causing an error. And for those specific partitions, you can deep-dive and see logs for the run that errored, or what data was generated in the past:
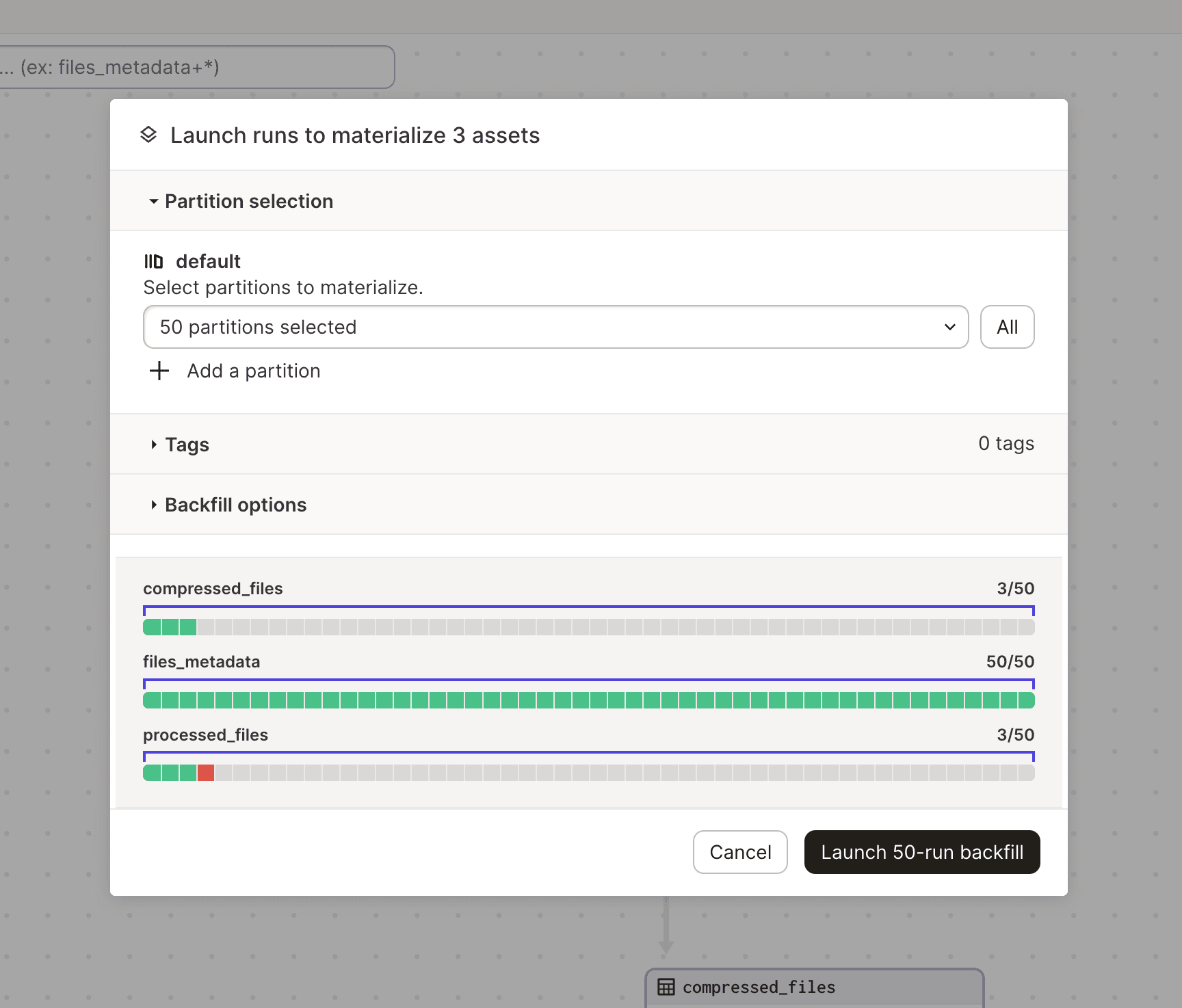
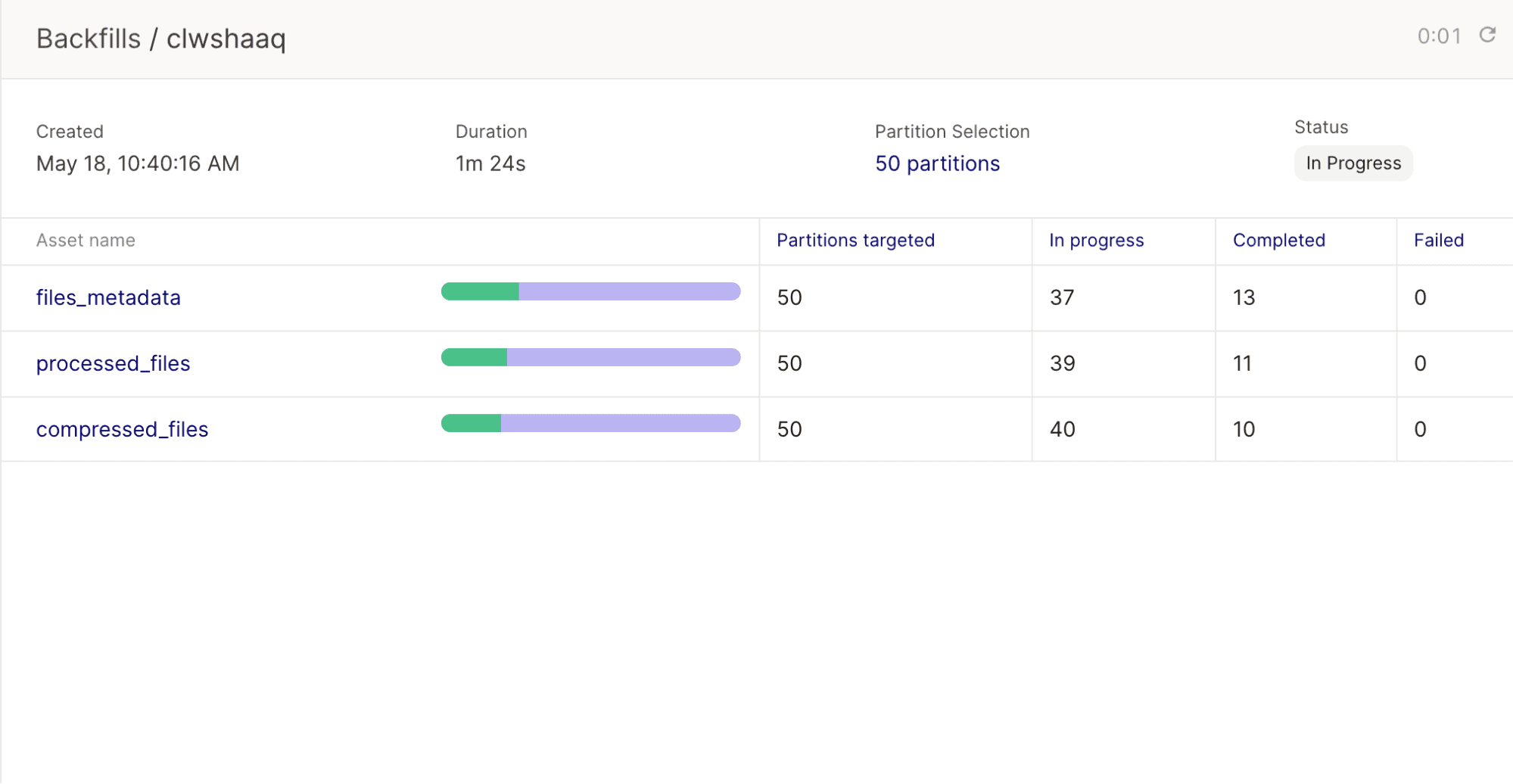
Backfills
If you update the logic in your shared computation, you’ll want to ensure that all partitions are re-processed with the updated logic. With just one action, you can backfill across all partitions:
Track execution progress
Then, you can view a condensed view of which partitions have succeeded, failed, or are still in-progress:
How can you use a dynamic partition?
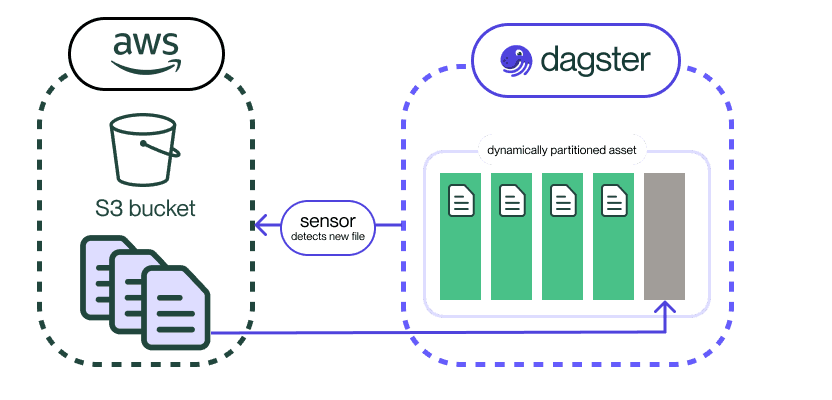
A common pattern in data pipelines is detecting new files as they land in a bucket, processing them, and producing output files. Here’s an example of how you can implement this incremental update approach in Dagster through a sensor:
from dagster import (
DynamicPartitionsDefinition,
asset,
sensor,
SensorResult,
RunRequest,
AssetSelection,
)
files_partitions_def = DynamicPartitionsDefinition(name="files")
@asset(partitions_def=files_partitions_def)
def files_metadata():
...
@asset(partitions_def=files_partitions_def)
def processed_files(files_metadata):
...
@asset(partitions_def=files_partitions_def)
def compressed_files(processed_files):
...
@sensor(
asset_selection=AssetSelection.keys(
files_metadata.key, processed_files.key, compressed_files.key
)
)
def file_sensor(context):
new_files = [
filename
for filename in os.listdir(os.getenv("MY_DIRECTORY"))
if not context.instance.has_dynamic_partition(
files_partitions_def.name, filename
)
]
return SensorResult(
run_requests=[
RunRequest(partition_key=filename) for filename in new_files
],
dynamic_partitions_requests=[
files_partitions_def.build_add_request(new_files)
],
)
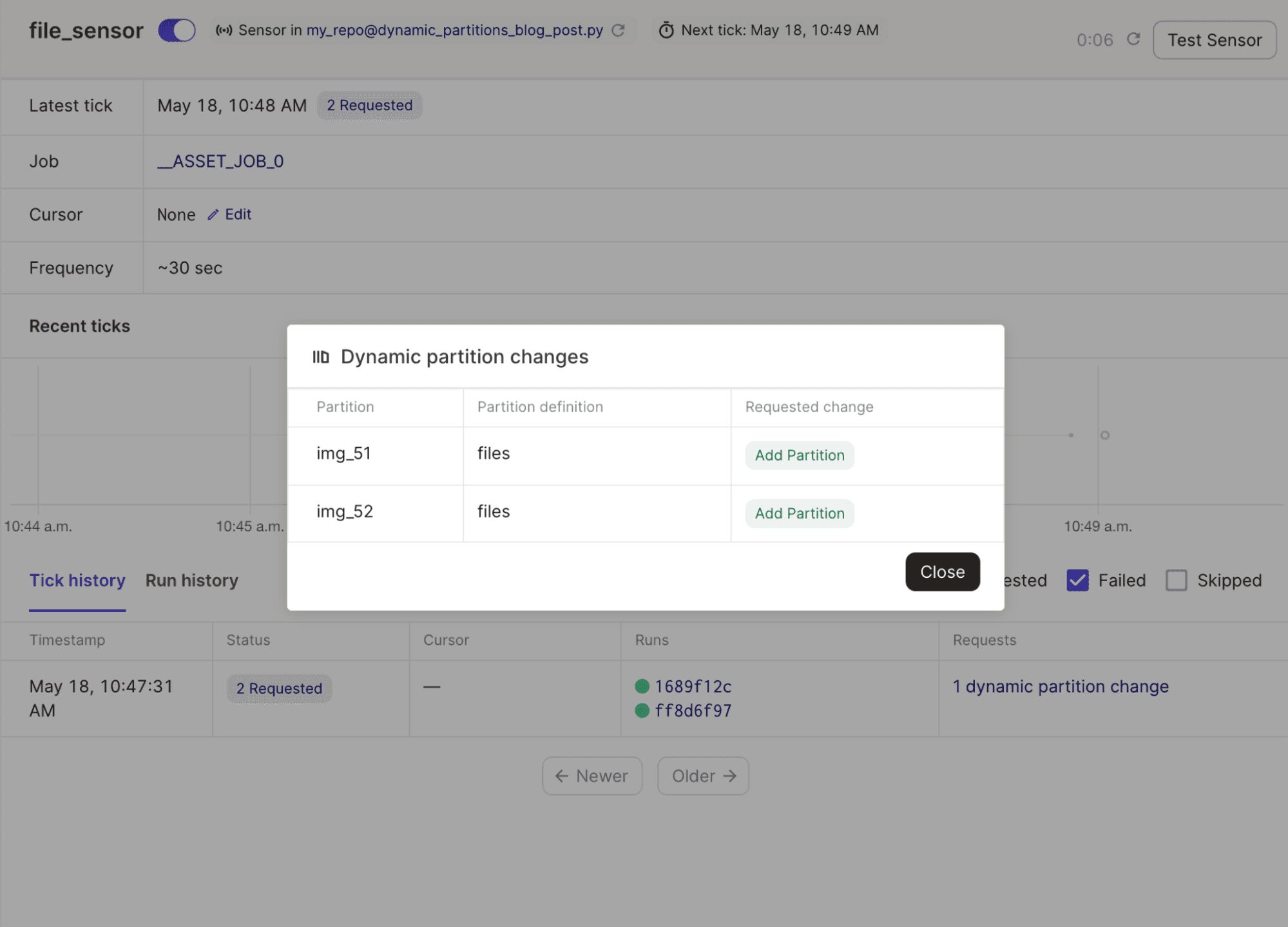
With this file_sensor() sensor, you can detect when new files are added to the folder and kick off runs to process just those new files. Scoping the execution of each run to just one partition via Dagster’s system ensures you can incrementally load new partitions instead of reading the entire bucket.
Then, in the UI, you can observe which new partitions were added (as a result of the new file being added), as well as any runs that were kicked off to process these partitions. This gives you a condensed view of the history of your data collection, and the actions taken to process new elements.
Conclusion
Data engineers are challenged to manage diverse data collections with thousands of files or tables. Declaratively defining these collections as partitioned assets in Dagster offers granular control, high-level observability, efficient backfilling, and simplified incremental updates. Dynamically partitioned assets enable you to leverage these benefits even for an unknown partition space.
Even if your data pipeline processes a data collection containing thousands of items, dynamic partitioning will allow you to say goodbye to the complexity of a sprawling data lineage, and hello to a single pane of glass for managing and observing your assets.
For the reference documentation on dynamic partitioning, please see Partitioned assets and jobs.





.jpg)
.png)



.png)

