




Raising the quality bar requires process adjustments and a cultural shift.
Software engineering teams are often under pressure to ship projects and features as quickly as possible. This often leads to a trail of user pain and a fragile codebase. Over time, engineering teams find themselves spending more and more time on "keeping the lights on" instead of innovating and improving their products. Worse yet, users may start to complain or even abandon the product entirely.
If your company receives negative user feedback about product quality or your engineering team spends too much time fixing high-priority bugs, it's time to change. Raising the bar on quality requires process adjustments and a cultural shift towards prioritizing quality in the development cycle. By doing so, companies can improve their products and avoid spending excessive time on maintenance and bug-fixing.
Bosmat Eldar, Head of Engineering, walks us through how she is leading this transition at Dagster Labs.
Since joining Dagster Labs in November 2022, I have been focused on gaining a deep understanding of the people, the company, the industry, Dagster, our roadmaps, and our community. During this time, I have identified areas where we are excelling and areas where we can improve.
One area that was particularly
A complex product with a growing userbase
Our development cycle at Dagster Labs is somewhat more complex because one part of our product is open-sourced and the other (our Cloud solution) is built on top of it. This means that we have two release cycles with inter-dependencies. And our older versions of OSS are still in use, so we must test against them whenever we do a change. We also have two different development environments (one for OSS and one for Cloud) that require us to test more rigorously when we change things that affect both sides.
Growth also complicates things. We have steady usage growth across OSS and Cloud, and while we are very grateful for it, more usage means more people pushing the product limits. More bugs are found, and the table stakes are only getting higher.
To maintain our momentum and meet the expectations of our users, we needed to change a few things.
The sweet taste of dog food: “Feedback is a gift.”
Manual QA'ing of the product is still the best process for preventing bugs and incidents from happening in production in the very short term, but in the long run, automated tests should be the main way to go.
We added an hour of manual QA for all engineers immediately after we cut the weekly OSS minor release. We found release-blocking issues and gathered good feedback that was used as input for future feature iterations. We now also spend a dedicated “dogfooding” (the act of using your own product) week for major releases, which are roughly once a quarter.
Dogfooding offers numerous benefits beyond just detecting bugs. It cultivates empathy for users and provides team members with a comprehensive understanding of the entire product and newly released features. Over time, it can also motivate engineers to avoid bugs ahead of dogfooding sessions since they become experiences to be avoided. Ultimately, this can lead to the removal of dogfooding sessions altogether.
The ease of dogfooding is crucial for it to be effective. The more steps required, the less it will occur organically. Some products or features are easier to dogfood than others. For instance, Gmail app developers can conveniently use it as their daily work email, while those working on missile management software may face significant barriers.
To ensure the success of these sessions, a culture of trust and openness to feedback must be established. Team members must provide feedback constructively and be receptive to receiving it. As engineering leaders, we should lead by example by sharing and seeking feedback, and actively participating in dogfooding. We can also incorporate this trait into our organization's values and processes to ensure it happens consistently.
Test Automation
Automated tests are a crucial tool for maintaining the quality of software development. Without these, we run the risk of getting swamped by regressions. Integrating automated testing into your development process may seem like a major hurdle, but doing so can improve productivity in the long run. Writing modular and testable code helps makes it easier to review and develop on top of, and prevents regressions. Nevertheless, to reap the advantages of testing, it's okay to add tests to just some parts of the codebase.
For engineering leaders, introducing automated testing can be a challenge. Here are some ideas for making this process easier:
- Prioritize incremental changes that can have the most significant impact on reducing future overhead time.
- Make writing tests as easy as possible. If adding a test is painful or cumbersome, it's less likely to become a habit.
- Focus on covering critical paths in the system or areas that consistently cause regressions to ensure stability.
- Consider establishing a testing standard for future development. Determine when to add tests when new features are added or when old code is modified.
- Consider the testing frameworks being used and evaluate whether they are the best fit for your team's needs. Some frameworks may not offer the same benefits as others, so research may be necessary to find the best option.
- Introduce new types of tests, such as unit tests, integration tests, end-to-end tests, and snapshots, or begin using tests at different stages of development, such as local development, pull requests, build, and release, to ensure code quality.
At Dagster Labs, we firmly believe that quality and velocity are not mutually exclusive. We now keep our codebase covered by unit tests and integration tests.
One area that needed to be improved was our front-end application codebase. It was a recurring area where we experienced severe bugs. A bit of context - to build our Dagster app, we use React and communicate with our backend via GraphQL. We previously used Apollo GraphQL Testing for testing our React components. When I asked about our test coverage, it turned out that engineers found it hard to write tests, and the tests had unexpected default behavior. As a result, we decided to switch to Apollo's MockedProvider. This gave us greater control over our tests and made writing them easier.
Catch problems early with observability.
One area that requires attention is observability — the ability to quickly detect when things are not functioning properly. This can be achieved by utilizing automated monitoring tools to track the product's performance and identify potential issues before they impact customers.
Here are some areas to look into:
- Monitor system health. Track metrics such as CPU usage, performance, DB usage, and cache usage. Set up alerts that notify on-call staff of any issues that arise. Review error logs frequently to identify any new errors or exceptions that have been introduced.
- Track product usage and user behavior to identify areas for improvement. This can include monitoring growth and engagement metrics, feature usage, and other usage-related statistics.
- Track customer satisfaction. Use metrics like NPS scores, surveys, and written feedback. This helps identify areas where customers are having issues or where improvements can be made to enhance the overall product experience.
Another common area of incidents was our Serverless solution since we only released it last year. In Q1 2023, we created a set of Service Level Objectives (SLOs) for our Serverless product and a dashboard that we monitor. Incidents are triggered if these go out of range. We can now monitor usage and proactively address potential issues.
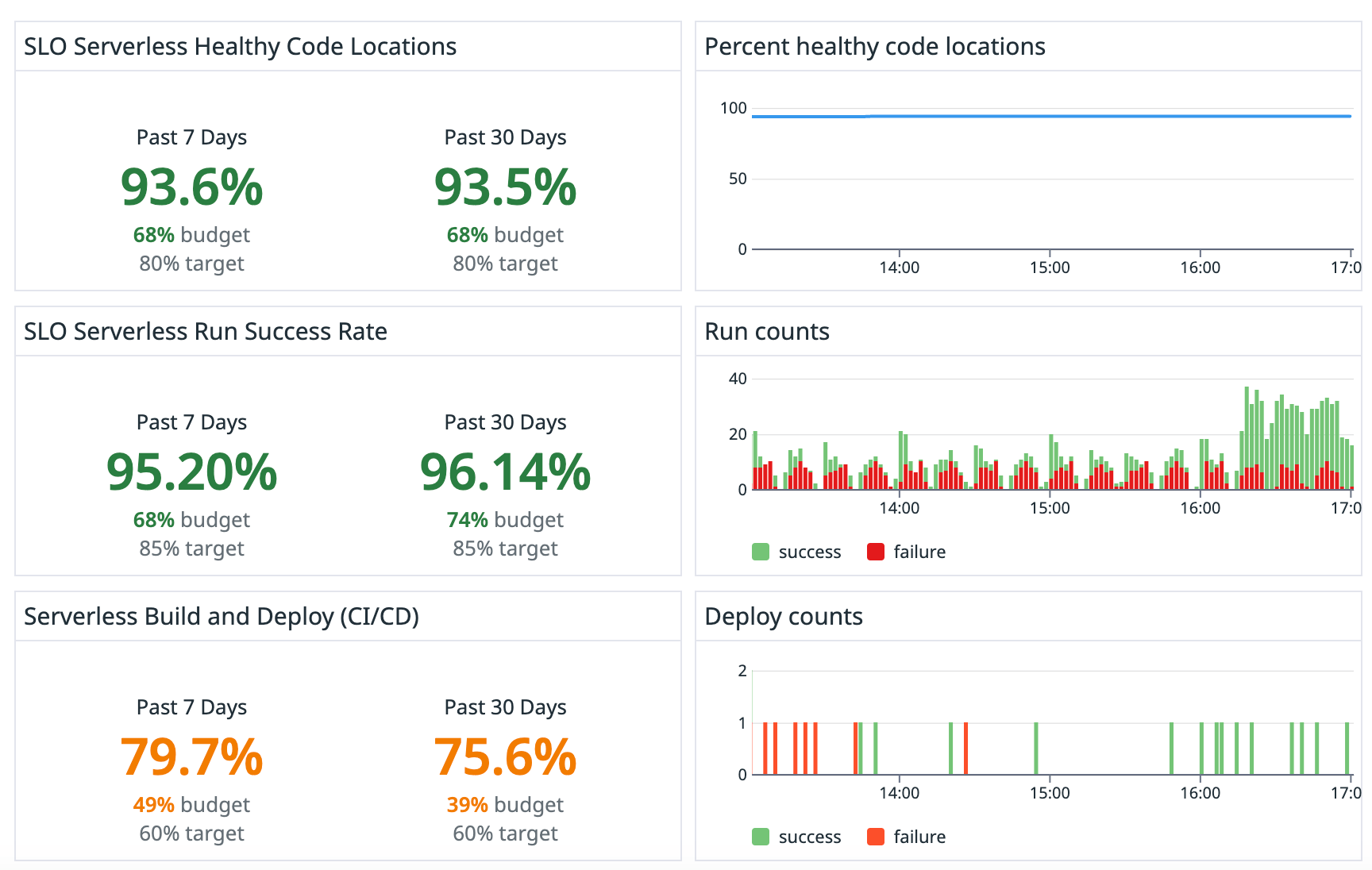
Continuously Improve with Retrospectives
If you encounter a severe issue in production, it's important to conduct an "incident review.” This helps cultivate a culture of continuous improvement where engineers can identify and proactively address issues in systems and processes. It's crucial to establish a blameless postmortem culture that focuses on identifying areas for future improvement rather than finding fault in retrospectives.
Moreover, it's During a retrospective, get a complete understanding of why the issue happened. Consider using the 5 whys method to dig deeper into the problem. In addition, cover the following questions to create potential action items for the team to take on:
- How can we prevent this problem from happening again?
- Are there other areas with similar characteristics that we should improve upon?
- If this problem happens again, how can we catch it earlier, and what changes do we need to make?
- If this problem happens again, how can we mitigate it sooner, and what changes do we need to make?
It's useful to start recording some information about the production issues during incident reviews. Information like: incident duration (with different parts of the lifecycle), severity, area of issue. Those will allow you to get perspective over a longer amount of time:
- Are we getting fewer/more incidents in a certain area?
- Are we getting better/worse in detection/mitigation time?
- Are we solving severe incidents fast enough?
Cultivate a Culture of Quality
Improving the culture of an engineering organization to prioritize quality is crucial for long-term success. By ensuring quality is always top of mind, individuals across the team (and not just the engineering leaders) can take ownership of continuously improving the product.
Here are a few strategies for changing the culture:
- Adjust expectations for engineers: Level up or set new expectations in your next 1:1 to align with the company's goals. Communicate expectations for projects, mentor, and provide feedback as needed.
- Hire to the culture: When hiring new engineers, prepare a set of expectations or questions that signal the importance of product quality.
- Educate the team on the impact of low quality: Share data and examples of how low quality can impact customers and the business.
- Recognize quality improvements publicly.
- Plan time in your roadmap for "keeping the lights on" tasks: encourage engineers to suggest projects that improve efficiency in this area.
- Define quality metrics: Identify clear, easily measurable quality metrics that align with product goals and customer needs, such as % downtime, test coverage, time to resolution, and NPS score. Track progress and set goals accordingly.
- Lead by example: Model new habits and processes you want others to incorporate to demonstrate their value.
Here are some examples of our engineering habits at Dagster Labs:
- We maintain a mono repo, which makes it easier to keep our services high quality and the full stack up to date. Whenever an engineer makes a change, it’s their responsibility to keep code quality consistently high & update all call sites. That’s also true for our public resources - engineers are responsible for updating documentation, examples, and guides.
- When we plan our roadmaps, ~20% of our engineering time is assigned to work not directly tied to a feature - things like incident management, fixing bugs, fixing technical debt, making process improvements, etc.
- We keep our code changes digestible and rely heavily on stack diffs in which each pull request can individually pass tests. That facilitates quick and straightforward reverts. This is especially important as we strive to get close to continuous deployment on our cloud solutions. To learn more about our approach, check out this blog post.
Impact
Here is an example of our SEV1 incidents since we started tracking in 2023:
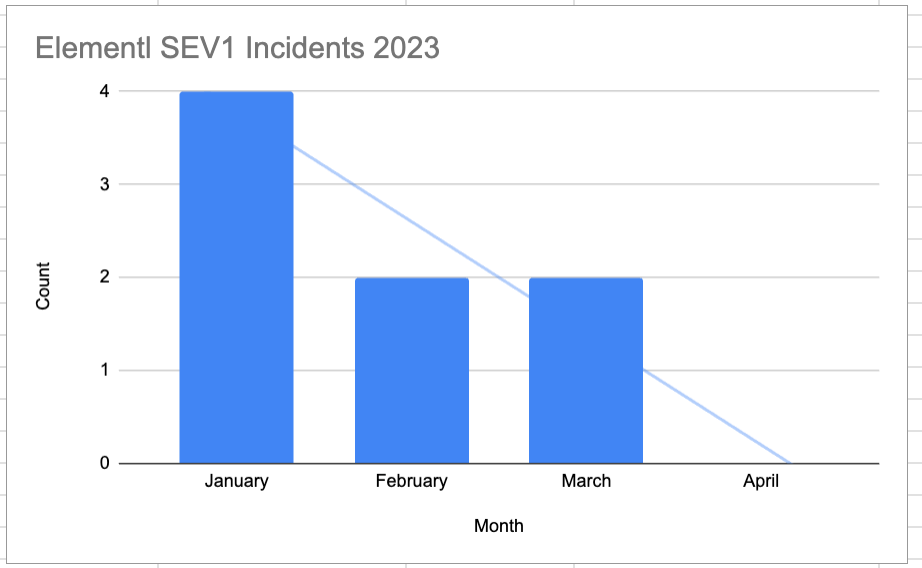
These results are a direct outcome of the improvements discussed earlier. I am appreciative to collaborate with a team of exceptional engineers who demonstrate a strong commitment to our community and customer experience. Moving forward, our focus is on reducing the time taken to detect incidents as ~96% the our incident duration is spent on the engineers not realizing there is an incident. This is just part of the continuous improvements we are planning to work on as part of our commitment to our users to always improve.
In summary, there are numerous ways to improve the quality of the engineering team’s output. This said it is imperative to find a balance between quality and speed of new product changes especially when resources are limited. The approach for ensuring product quality may vary depending on factors such as company resources, product usage, product type, and growth stage, so each product and organization requires a bespoke quality plan.
Finally, while striving for quality, remember to enjoy the journey :-)
Interested in trying Dagster Cloud for Free?
Enterprise orchestration that puts developer experience first. Serverless or hybrid deployments, native branching, and out-of-the-box CI/CD.





.jpg)
.png)



.png)

