




How we saved $40k and gained better control over our ingestion steps.
Recently at Dagster Labs, we did something really exciting: we opted out of an upcoming contract renewal with a managed ETL provider in favor of Dagster’s Embedded ELT library. For us, this means:
- Saving $40,000/year on a renewal contract
- One less source of vendor lock-in
- More granular control over our ingestion
From start to finish this project took us about two weeks, which would never have been possible without the help of Embedded ELT and Sling. We’d like to take you through how we migrated to Embedded ELT, saved a bunch of money, and gained better control over our ingestion steps — and how you can too...
What is Dagster Embedded ELT?
The Dagster Embedded ELT library provides a lightweight toolkit for ingesting and loading data with Dagster. In its current form, Embedded ELT provides a series of assets and resources for syncing data using Sling. Sling is a powerful and lightweight ingestion engine that allows us to define how data is synchronized from source to target data system. To learn more about Embedded ELT you can check out Pedram’s blog post introducing the library.
Embedded ELT provided all we needed to make the switch; the next step was creating a plan to build, test, and swap our ingestion scheme with little or no downtime for our downstream data assets.
Why the Move to Embedded ELT?
As data engineers at Dagster Labs, we’re always looking for ways to apply and test new Dagster tools internally. We felt that migrating our ingestion to Embedded ELT provided a great use case for the library, and when we learned that we could potentially save $40,000 by making the switch it made the project all the more enticing. So what did this mean for us and what exactly did we need to move to Embedded ELT?
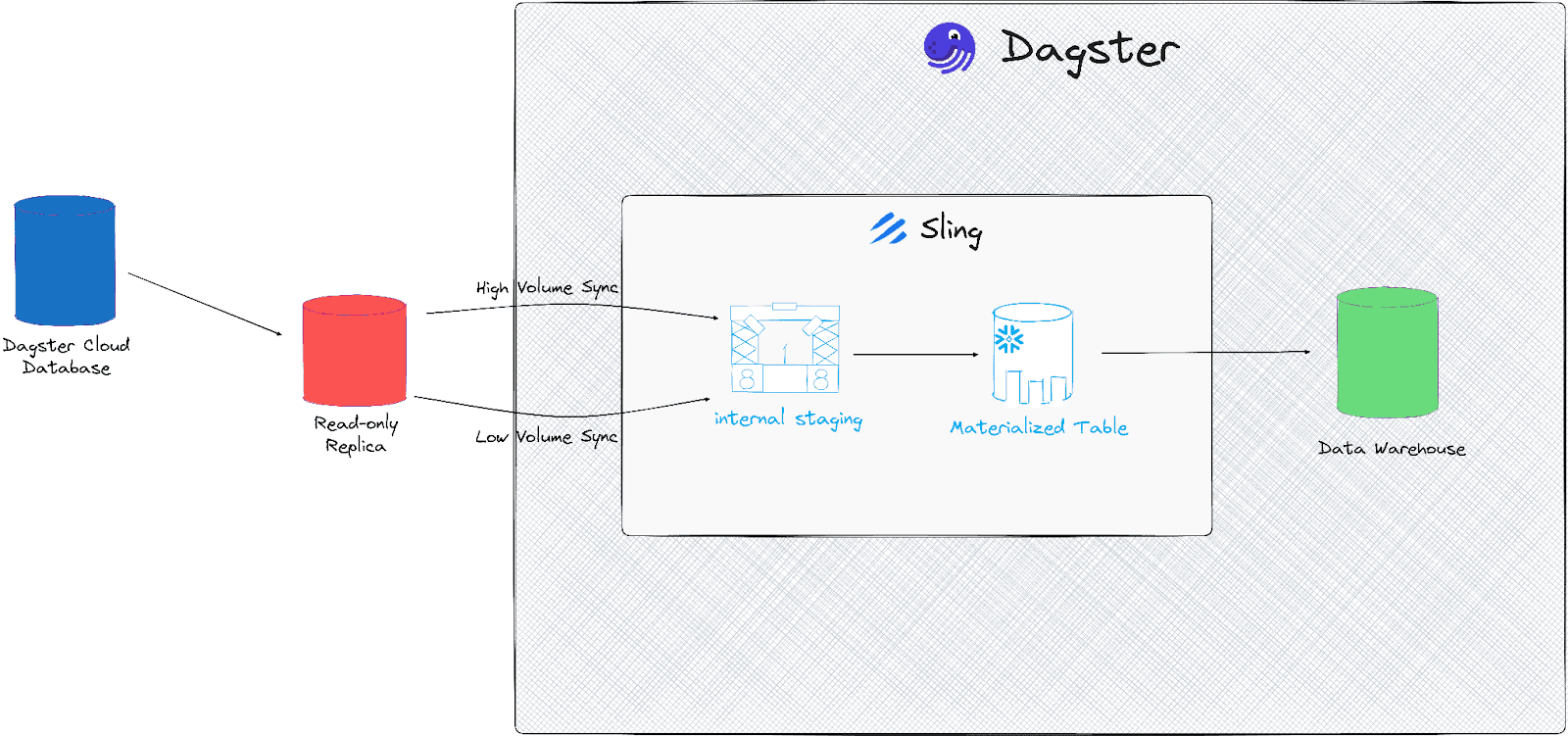
There were a few different data sources that we ingested via this ETL provider, but the largest and most important to us was the data coming out of our Dagster Cloud service. These data include all of the event logs, runs, organizations, deployments, and various other data that are collected by the cloud platform. In particular, our event logs data is extremely high volume, with 13 billion rows in the table already and hundreds of thousands of rows coming every 5 minutes. These data would be the perfect test as to whether Embedded ELT could handle ingestion at scale.
Making the Switch
Creating a Testing Environment
To test our pipeline, we created a database in Snowflake called SLING_DEV with a corresponding SLINGUSER with role SLING that had full access to the database. Additionally, we recommend making a schema for every source that you plan to land using Sling, so for our case, we’ll start with a CLOUD_PRODUCT schema that will hold all of our Dagster Cloud data. Lastly, we set up a corresponding SLINGUSER with permissions on the tables we wanted to ingest in our source system. In our case, this was Dagster Cloud’s read-only Postgres database.
Building Replication Configurations
Sling makes it easy to define what data we’d like to replicate and how we’d like it to land in our data warehouse using YAML configuration files. For our use case, we wanted to set up two separate replication configurations: one that would handle all of our small to midsize tables and would run on some infrequent cadence (say, every 3 to 6 hours) and another that would run at a much more frequent cadence (every 5 minutes) and handle our larger tables that collect new data much more rapidly, like our event logs table that currently sits at approximately 13 billion rows. All we have to do is list out our tables in the stream section of our config with any additional Dagster metadata, like adding a custom asset key. For more information on Sling configurations, refer to Sling’s documentation.
You may ask why we can’t just have all of the assets run on the same configuration at the same cadence. This is primarily because the read-only Postgres database has to sync to the production database every 5 minutes. If our job is running when this sync happens, Postgres will kill our replication job, and since we’re dealing with lots of tables – some with very large amounts of data – this is likely to happen pretty often. So separating the jobs allows us to more easily avoid those Postgres syncing issues.
We started with our infrequent cadence job, which handles any assets that require a full upsert along with any other smaller tables that aren’t generating large amounts of data in a small time frame:
// infrequent_sync.yml
source: read_only_pg
target: snowflake_dwh
defaults:
mode: incremental
object: '{stream_table}'
primary_key: [id]
streams:
public.deployments:
meta:
dagster:
asset_key: sling.cloud_product.deployments
public.organizations:
update_key: update_timestamp
meta:
dagster:
asset_key: sling.cloud_product.organizations
...
Note that for some assets, we were able to provide an update_key. This tells Sling to only add/modify rows coming from the source table with an update key greater than the latest update key in the target table.
Next, we built our more frequent replication job, which includes rapidly-generated data: assets like event logs, runs, and run tags. Our event logs table is append-only, so all we had to do was set our update_key as the event log table’s ID field and Sling takes care of grabbing the event logs only after the last ID in our target table:
// frequent_sync.yml
source: read_only_pg
target: snowflake_dwh
defaults:
mode: incremental
object: '{stream_table}'
update_key: id
streams:
public.event_logs:
meta:
dagster:
asset_key: sling.cloud_product.event_logs
public.runs:
primary_key: [id]
update_key: update_timestamp
meta:
dagster:
asset_key: sling.cloud_product.runs
public.run_tags:
meta:
dagster:
asset_key: sling.cloud_product.run_tags
Testing Connections with the Sling CLI
To start, we wanted to make sure that Sling could move our data, so we tested ingesting a few of our smaller tables using Sling’s command line tool. We first set up connections to Dagster Cloud’s read-only Postgres database and our Snowflake data warehouse in ~/.sling/env.yaml:
connections:
read_only_pg:
type: postgres
host: ***
user: slinguser
password: ***
port: 5432
dbname: dagster
schema: public
ssh_tunnel: ***
ssh_private_key: ***
snowflake_dwh:
type: snowflake
host: ***
user: slinguser
password: ***
database: sling_dev
schema: cloud_product
warehouse: ***
role: sling
Now that we have those connections set up, we started testing some of our smaller tables with the Sling CLI:
$ sling run \
--src-conn read_only_pg \
--src-stream 'public.organizations' \
--tgt-conn snowflake_dwh \
--tgt-object 'cloud_product.organizations' \
--mode full-refresh
Notice that for now, we’re just testing with --mode full-refresh with our smaller tables. Eventually, we’re going to put as many tables as we can in incremental mode to save on Snowflake credits.
Once we confirmed that the data landed in our target Snowflake schema, we moved on to building configurations for our replication jobs.
Testing Replication with the Sling CLI
Before we put anything into Dagster, we needed to confirm that these replication configurations were doing what we expected them to do. We added a default to both configs setting a row limit of 1000 rows. We weren’t necessarily testing scale at this point, we just wanted to make sure data was moving from source to target. To test that incrementality is performing as expected with our event logs table, we created a zero-copy clone of the event logs table that the ETL provider is landing in our data warehouse and made a note of the last ID in the table. From here, we ran our replication jobs with the Sling CLI:
$ sling run -r infrequent_sync.yml
$ sling run -r frequent_sync.yml
Once we confirmed that our data is landing in our Sling dev database, we moved on to bringing this work into Dagster and setting up Embedded ELT.
Setting Up Dagster Embedded ELT
Now that we had the Sling end of things figured out, we were ready to set up Embedded ELT and create recurring replication jobs.
Setting Up Our Sling Resource
Following the documentation for Embedded ELT, we created two SlingConnectionResources and supplied them as the connections argument to a SlingResource, which effectively acts as our env.yml within Dagster.
from dagster_embedded_elt.sling.resources import (
SlingConnectionResource,
SlingResource,
)
embedded_elt_resource = SlingResource(
connections=[
SlingConnectionResource(
name="read_only_pg",
type="postgres",
host=EnvVar("PG_HOST"),
user=EnvVar("PG_SLING_USER"),
database=EnvVar("PG_DATABASE"),
password=EnvVar("PG_SLING_PASSWORD"),
ssl_mode="require",
ssh_tunnel=EnvVar("PG_TUNNEL"),
ssh_private_key=EnvVar("PG_SSH_PRIVATE_KEY"),
),
SlingConnectionResource(
name="snowflake_dwh",
type="snowflake",
host=EnvVar("SNOWFLAKE_ACCOUNT"),
user=EnvVar("SNOWFLAKE_SLING_USER"),
password=EnvVar("SNOWFLAKE_SLING_PASSWORD"),
database="sling_dev",
schema="cloud_product",
warehouse="sling",
role="sling",
),
]
)
Building Our Sling Assets
Embedded ELT made it easy to build the assets that run our Sling replications: all we needed to do was provide the configuration files to the @sling_assets decorator and the embedded_elt.replicate function inside our decorated function.
from dagster_embedded_elt.sling.asset_decorator import sling_assets
from dagster_embedded_elt.sling.dagster_sling_translator import DagsterSlingTranslator
from dagster_embedded_elt.sling.resources import (
SlingResource,
)
cloud_production_infrequent_sync_config = "path/to/infrequent_sync.yaml"
@sling_assets(
replication_config=cloud_production_infrequent_sync_config
)
def cloud_product_low_volume(context, embedded_elt: SlingResource):
yield from embedded_elt.replicate(
replication_config=cloud_production_infrequent_sync_config,
)
cloud_production_frequent_sync_config = "path/to/frequent_sync.yaml"
@sling_assets(
replication_config=cloud_production_frequent_sync_config
)
def cloud_product_high_volume(context, embedded_elt: SlingResource):
yield from embedded_elt.replicate(
replication_config=cloud_production_frequent_sync_config,
)
And that’s it! From here we just set up a Dagster job and schedule for each configuration, one that ran every 3 hours and another that ran every 5 minutes.
Setting Up Our Production Environment
We had everything we needed to start moving data, now we needed to prep Snowflake. This meant cloning all of the previously-ingested data from our provider’s Snowflake database into a new production SLING database and removing any provider-specific fields that were added by the tool (e.g. _SDC_BATCHED_AT). From here, Sling could just add and modify the existing data in this database with no need to backfill historical data.
Parity Testing
With Embedded ELT set up and our Snowflake database ready, we could now turn on our jobs in Dagster and start ingesting data. We wanted to make sure things were running smoothly for a while before we started pointing downstream tables at our Sling database, so we decided to let Sling run for a few days and do comparisons with the provider throughout the following 3 or 4 days. We made a few minor adjustments to the configuration files and our Dagster jobs throughout those days, but generally, Sling stayed aligned with the ETL provider from start to finish and we felt confident that we could make the swap downstream.
Swapping Downstream Tables to Source Sling
After a few days of running Sling and our ETL provider in parallel, we felt confident we could start swapping our downstream tables to source our Sling data. We still kept our old pipelines up and running at this point, just in case there was some catastrophic issue. We made the switch to all of our downstream tables at once because we trusted Sling, but the best practice is to go table-by-table and ensure nothing breaks as you make the swap.
We continued to parity-test against our previous ETL provider over the next few days to ensure we weren’t falling behind, but we saw no discrepancies and – after confirming that downstream stakeholders and dashboards felt no impact – we felt we could turn off our old syncs and run solely off of Embedded ELT and Sling.
And we’re done! After all of this, we just removed any references to our old ETL provider from our Dagster project and notified stakeholders of the switch.
Conclusion
The two most exciting takeaways from this project for the data engineers at Dagster were:
- The immediate $40k savings, with no loss of functionality
- The speed at which we were able to complete this work
We feel that the way we approached this project provided us with a means of testing at production scale without affecting production processes. Embedded ELT and Sling gave us the tools to quickly get code into our pipelines and start moving data. Additionally, Dagster and Dagster Insights give us the ability to monitor both the performance and cost of ingesting data from our cloud service.

If you have any questions or would like to learn more about Embedded ELT and ingesting data with Dagster, check out our documentation and join our Slack channel.
Interested in learning more? Watch Pedran Navid’s presentation: Embedded ELT: Save your budget and simplify your data platform with Dagster Embedded ELT.





.jpg)
.png)



.png)

