




A new protocol and toolkit for integrating and launching compute into remote execution environments from Dagster.
We’re proud to announce Dagster Pipes, a protocol for integrating and launching compute into remote execution environments from Dagster and a toolkit for building those integrations.
Pipes has a few goals:
- Make it easier to incorporate existing code and onboard stakeholder teams onto Dagster incrementally.
- Launch code in external environments—while adding minimal additional dependencies to that environment—and get parameter passing, streaming logging and structured metadata back into Dagster's lineage, observability, and data quality tools.
- Support for the strict separation of orchestration and execution in Dagster.
- First-class multi-language support in Dagster.
The Problem
An essential function in orchestration is launching external computations that execute business logic and transformation. This can take the form of a opening a subprocess, spinning up and executing Kubernetes Pods, launching a Spark Job, or invoking a custom runtime via a REST API, to name a few examples.
Users need to pass parameters and context to these external processes, and then want to collect logs and structured metadata from those processes for observation, monitoring, and other purposes.
This is challenging to standardize because the underlying constraints and technologies are so different. As a concrete example, there is no common API for launching a Kubernetes pod or Databricks job. They are simply too different.
Users today are left to fend for themselves to write the plumbing for this interaction. They often have to write custom CLI apps, tediously passing parameters through shell commands, or write custom code to stash context in some commonly available durable storage.
We have a novel solution to this problem: Pipes, a composable RPC protocol that standardizes the process of invoking and retrieving structured results from external computations, while remaining agnostic to how that compute is launched and the storage substrates available for data interchange. The result is much lower complexity burdens for both infrastructure engineers and their stakeholders writing business logic, more flexibility in infrastructure, and more reliable systems.
Historical Context
It is also worth discussing why we at Dagster felt compelled to write this system. Historically, Dagster has been considered a powerful, elegant tool, but one that could be challenging to adopt and deploy, especially across multiple stakeholder teams.
The biggest obstacle to adoption we've seen for many users is that Dagster expects you to adopt it as both an orchestration tool and transformation tool at the same time. While this vertical integration has enormous benefits, it is not always feasible or desirable. If you do not embrace that vertical integration, you are forced to write nasty, error-prone integration code, similar to what they would need to write in conventional orchestration techonologies. Pipes addresses this difficulty head-on, offering a best-of-both-worlds solution that is both convenient and flexible.
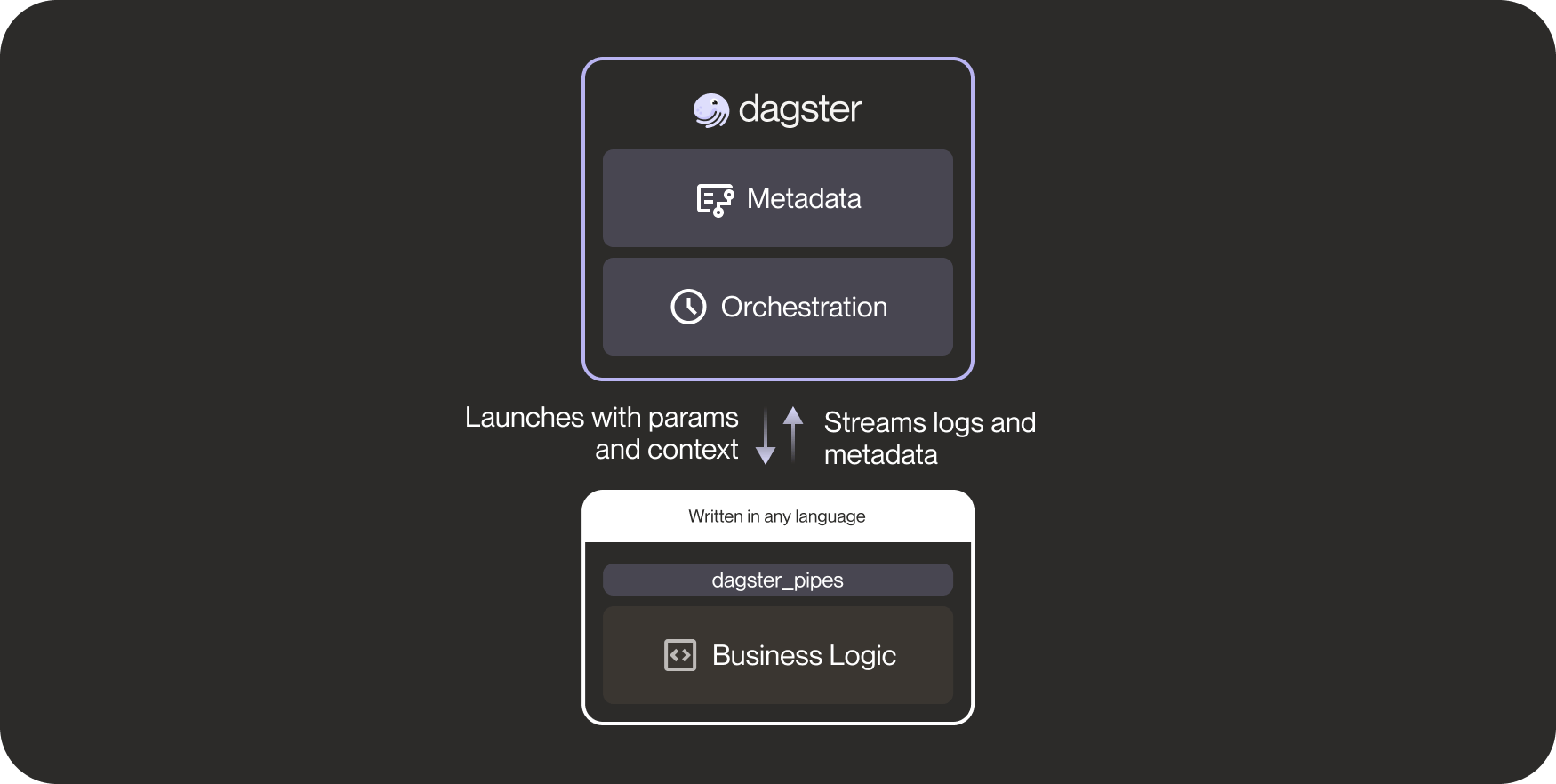
One System, Three Layers
Dagster is not just an orchestrator, even though it is typically categorized as one. It is actually the vertical integration of three layers of software:
- A metadata platform for lineage, observability, cataloging, and, data quality
- An orchestrator
- A Python framework for business logic and data transforms
If a user is able to adopt these three layers in concert in a single infrastructure layer, the improvements in developer workflow and tooling are remarkable. However this is just not possible in many situations and organizations.
Pipes fundamentally decouples the orchestration and transformation layer of Dagster while still retaining the orchestration and metadata-driven features that constitute the “single pane of glass” represented by Dagster.
With Dagster Pipes, there now exists a realistic path forward for a ubiquitous data control plane to power your data platform or data mesh strategy. A living, breathing, metadata-rich graph of assets that spans your entire organization, seamlessly orchestrating any technology or hosted runtime, serving as a powerful point of leverage for data platform teams.
How does it work?
Pipes can be conceived as a composable RPC (remote procedure call) protocol. With Pipes, the orchestrator launches external processes, passes parameters to them, and then can ingest streaming logs and structured metadata produced by those processes.
What distinguishes Pipes from more traditional RPC is that it is agnostic to how the processes are launched, how the context and parameters are actually injected into those processes, and what storage medium is used to stream logs and metadata.

The reason why this must be a pluggable protocol is that in practice, there is no standardization on how to parameterize and get logs out of external runtimes and environments that are in broad usage today.
For example, we are shipping out-of-the-box Pipes integrations to launch local subprocesses, Kubernetes Pods, and Databricks Jobs. Each of these has different constraints, and therefore require different transport mechanisms:

Despite this heterogenity of execute and storage substrates, the code to launch and execute Pipes processes is straightforward and uniform, both on the launching side–typically authored by the data or infrastructure engineer–and on the launched side–typically authored by the data practitioner or stakeholder.
Here is an example of launching a pipes computation in a Kubernetes Pod.:
In the launched process–where author who wants the orchestrator and control plane abstracted away from them as much as possible–you need a few lines of code to access passed parameters and get metadata back into Dagster. This makes it very straightforward to integrate with existing code.
Compare the equivalent with the code needed to do this in Airflow in a script launched by the KubernetesPodOperator:
One of our users vividly described this approach as "CLI Hell" where every task in the data platform requires its own custom CLI application and associated marshalling. Pipes provides a way out of CLI Hell while preserving the separation of orchestration and execution.
Pipes also is pluggable on a per-capability basis. For example, we have both S3 and dbfs implementations available for passing context information and structured log messages. By default our Databricks integration uses dbfs, but if a user wanted to instead use S3 for whatever reason, it requires changing a single line of code in the launching process and a single line of code in the external process.
Deployable on Existing Infrastructure
We have talked about how Pipes can work with existing stakeholder code. But what about an existing data platform infrastructure? We work with tons of teams that have invested countless engineer-hours into their data platform. Teams like that want to add capabilities on top of software that works, rather than do a risky, costly rip and replace.
Pipes is designed explicitly to work for teams in this situation. That means flexibly adopting it in the launching process controlled by the data platform team, not just the receiving process controlled by the stakeholder team.
For example, we work with customers that rely on Spark and Databricks for mission-critical data pipelines that operate at massive scale. They have heavily invested in code to manage, observe, and customize their Spark jobs. Before Pipes they would have written code like this:
This works, but is tedious and error-prone. There is no way to easily pass parameters to the remote job, or to get structured events and streaming logs back from the remote job into Dagster without rolling your own complicated code.
However there is still the existing launching infrastructure code to contend with. In effect, you want the capabilities of Pipes, but in an additive fashion that does not invasively replace your existing launching code. We have designed an API for this exact purpose, open_pipes_session. This is used in the implementation as the core of all of our out-of-the-box integrations, but it itself is a public API, usable by those who wish to seamlessly integrate Pipes into their existing platform infrastructure.
Whether you use open_pipes_session or an out-of-the-box client, the code a stakeholder written in the external process is, in most cases, identical. That means your stakeholders are completely isolated from the complexity of the launching process and the orchestration layer, which is the ideal outcome.
The Multi-language future
All the code in the world is not and will not be written in Python. At the same time any code that lives in the data platform should be orchestrated and incorporated a universal data-aware control plane like Dagster. With Pipes, for the first time, there is a clear path forward for reconciling that heterogeneity with the goal of a universal data platform control plane.
Pipes is a protocol defined by serialization. While the physical transport can vary, all data structures in Pipes have a corresponding Json Schema definition. From the standpoint of launching code, it launches a process with bootstrap parameters, stashes a schematized json context object in a location the external process can load from, and then reads schematized json objects from an underlying agreed-upon channel. You’ll note that nothing in that sentence mentions the programming language in the external process.
That is because it can be in any programming language and still be compliant. This unlocks enormous possibilities in data platforms, both in terms of incorporating existing code, but also greater flexibility in the platform as whole. Many Data practitioners still write Spark in Scala. Rust is gaining momentum for demanding use cases. R, Julia, Java and many others have passionate users in the data ecosystem. Those technologies can and should be first-class citizens in the data platform. Dagster Pipes makes all of that possible.
We are in very early stages, but we have, as a proof of concept, a prototype implementation of Dagster Pipes in Rust in our repository, invokable via the Kubernetes client. This enables users to write business logic and transformations in Rust that interact with Dagster in first-class way:
This Rust implementation is in no way ready for production use. But it provides a prototype and vision for future production-ready versions of this in Rust and other programming languages.
When Pipes reaches maturity, a data asset written in any programming language can be a full, self-serve participant in a ubiquitous data platform control plane. This opens up a data platform not just to additional use cases, but to entirely new persona types. It is perfectly natural and right for application developers to be first-class participants in the data platform. Up until now, technological barriers have stood in the way of that vision. With the potential inclusion of application-developer-friendly languages (e.g. Ruby, TypeScript, C#) this possibility is no longer a pipe dream. We think this is a massive leap forward not just for Dagster, but for the entire ecosystem.
Learn more about Pipes in the Dagster Docs.
Conclusion
We’re incredibly excited to launch Dagster Pipes to wrap up launch week. We believe this, when combined with Dagster’s other features, will provide data and ML engineers with unprecedented leverage to improve outcomes for the organization. They will be able to bring every computation that produces data into the fold, and then apply observability, lineage, data quality, consumption management, and great developer workflow across the entire platform.
Please join our slack, download OSS Dagster, and/or try Dagster Cloud to see what’s possible.





.jpg)
.png)



.png)

