

.jpeg)


Give your data teams a powerful new system of record without the overhead of maintaining a third-party catalog.
With a small team and a simple data platform, a few well-placed questions in Slack are usually sufficient to find and understand the specific data assets you’re looking for. But as data platforms scale, tribal knowledge quickly starts to fail. And suddenly rework and duplication become common as data practitioners struggle to navigate their own platform.
This is why teams adopt data catalog: To help everyone find and use trusted data assets and to reduce the complexity of everyday platform management.
Why Data Catalogs Fail
Traditional standalone data catalogs are no magic bullet, because the overhead of running data catalogs often outweighs the efficiency gains of clearly documented data. In the end, most data catalogs are abandoned.
Here’s why they fail -- data assets and processes are distributed across many tools and storage locations, but data catalogs aren’t natively involved in the flow of data.
Stand-alone data catalogs have to capture, document, and update all of the metadata being generated from the exhaust of all of these different systems. It forces the data engineering team to constantly troubleshoot accuracy issues while coaxing the rest of their stakeholders to adopt new development practices to ensure that things remain in sync.
Why the Data Catalog in Dagster+ is Different
Because Dagster is an asset-oriented orchestrator, it is constantly receiving information about the state of data assets and the processes that produce them. It does this while retaining a git-based record of your assets, defined in code. By making software-defined-assets a fundamental part of the data platform, Dagster eases data discovery and documentation issues without adding to platform complexity.
With the launch of our catalog, Dagster+ will capture and curate the output metadata of your data assets as they are managed by data pipelines, delivering a real-time, actionable view of your data ecosystem. Your data team gets a powerful new system of record out-of-the-box, without the effort of maintaining a third-party catalog.

How Dagster Elevates Data Discoverability and Analysis
Let’s look at the new Dagster+ enhancements for data asset management.
Context-Rich View of Assets
A good data catalog must document and display a variety of key information about data assets for both pipeline-builders and data-consumers. This includes the definition of the asset, metadata about the generation of the asset, information about its usage and dependencies, status changes, and operational history.
With the release of Dagster 1.7, sorting between multiple screens to figure out the backstory on a data asset is no longer required. With the launch of a new assets UI, definition level data and metadata can be combined with operational data to help all stakeholders find and understand data assets with less effort.
Data Exploration at the Column Level
With Dagster+, users will see metadata about data asset definitions at a glance, while able to dive into structured assets investigating not only the raw SQL (or Spark) queries. They can still dig into the asset AND column-level lineage.
Much like our asset-lineage graphs, users can move through upstream and downstream dependencies for individual columns to track the flow of data through assets in their platform.
In cases where users are relying on dbt to define their assets, these new capabilities can be enabled with a few targeted changes in their project config files or enabled with a few definition-level metadata changes in the MaterializeResult object.
Flexible Organizational System
With the release of Dagster 1.7, metadata can be used to create a clear link between users or teams and the assets they support. This “Owner” data is searchable in the UI, filterable for views of analytics data in Dagster Insights, and targetable by alert policies, lowering friction for teams running data platforms in decentralized environments.
Asset-level definition tags are also available for the same purposes, so teams can better sort and filter large sets of assets within the Dagster+ platform.
Search UI That Improves Discoverability
With all of this new information, finding the right data at the right time will be crucial. Dagster+ significantly enhances the searchability and discoverability of data assets, ensuring that teams can quickly locate the information they need to drive decisions and innovation.
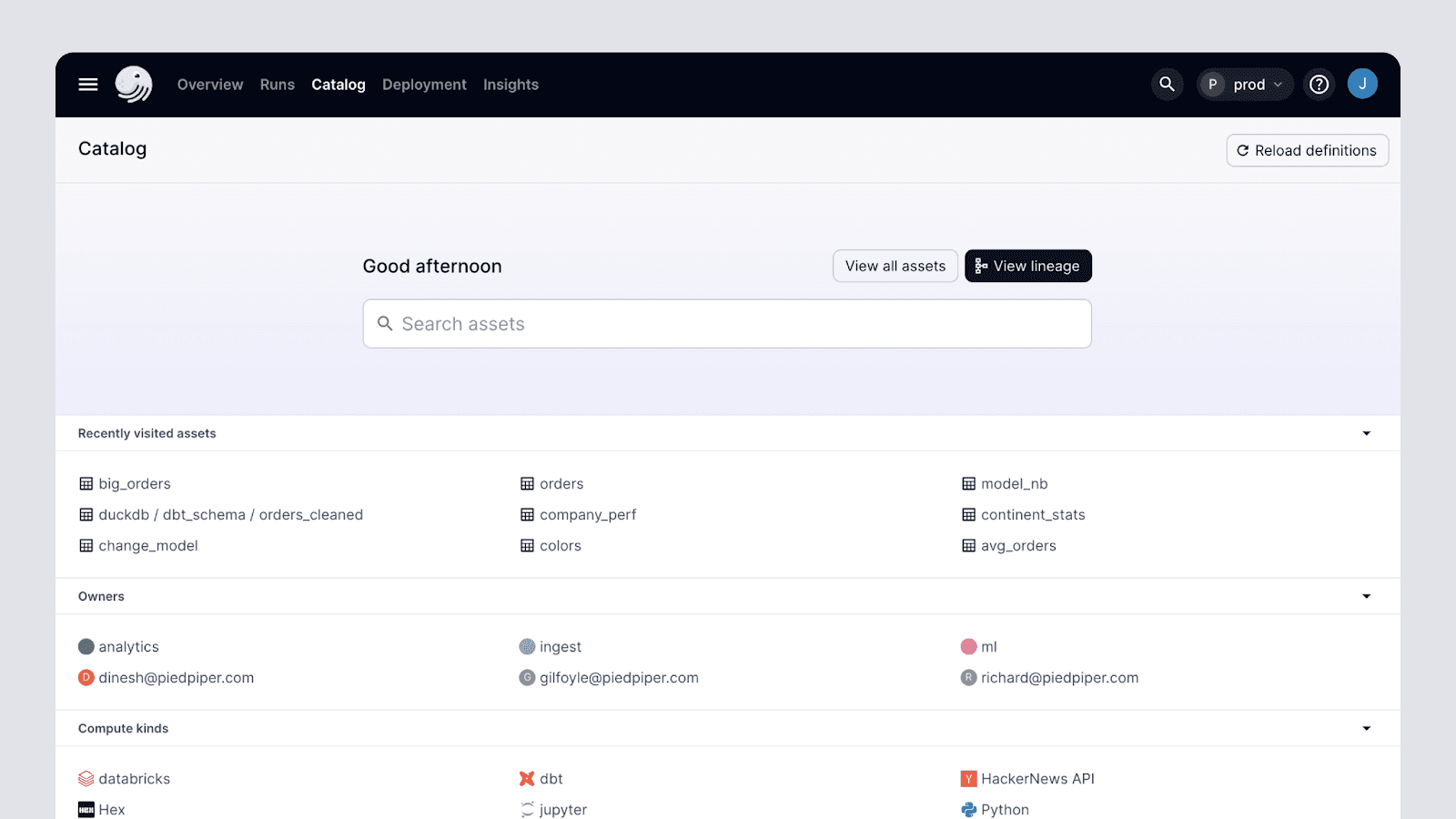
A Catalog UI for All Stakeholders
Recognizing that some data practitioners need an asset-focused experience on Dagster, teams can simplify the UI with a feature called ‘Catalog Mode.’ This intuitive interface subtracts much of the operational context specific to pipeline-builders and opens up access to data-consumers and business stakeholders. This democratizes access to data assets without the need to increase user seats or navigate complex permissions.
Platform Integration with External Assets
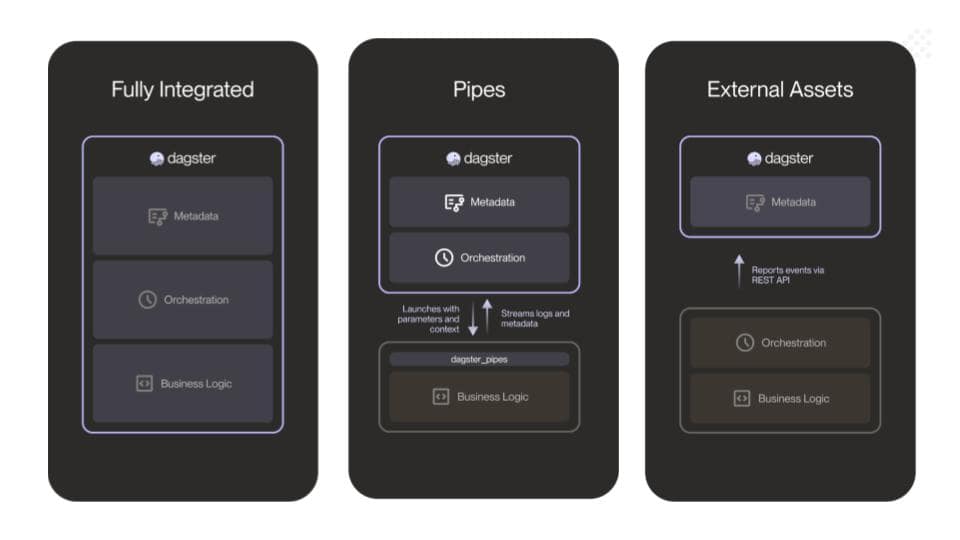
For teams leveraging the power of External Assets, Dagster+ extends its cataloging capabilities beyond the boundaries of its own platform. This integration ensures that all key assets, with relevant metadata, are centralized in one comprehensive catalog. That simplifies management and oversight.
Transforming Data Management with Dagster+
By integrating cataloging directly into the fabric of Dagster+, we're not just simplifying the technical stack; we're unlocking new levels of insight and collaboration across data teams. This approach reduces the total cost of ownership and enhances the agility and effectiveness of data operations.
As we continue to innovate and expand the capabilities of Dagster+, our focus remains on empowering data teams to harness the full potential of their assets and build fully-featured data platforms with ease.
With Dagster+, the future of data management is not just centralized; it's revolutionized, opening doors to unprecedented collaboration and efficiency across all facets of the data ecosystem.





.jpg)
.png)



.png)

