




A case for asset-oriented over workflow-oriented in data orchestration.
The Primary Concern of Data Engineering
The primary concern of data engineering is building and maintaining data assets such as dbt models, data warehouse tables, and even dashboards and ML models.
Data assets are tangible, have meaning, and are ultimately what our data work revolves around. Naturally, most tools in the data engineering tech stack take an asset-oriented approach. Whether it’s Snowflake, Monte Carlo, Fivetran, dbt, or Airbyte, all modern data stack tools from ingestion to visualization adopt the data asset (by one name or another) as their central concept.
The Orchestration Impedance Mismatch
And then there are orchestration tools.
In contrast to the rest of the (asset-oriented) data platform, most orchestration tools are workflow-oriented. They concern themselves with executing a series of black-box tasks.
Examples of these workflow-oriented tools include Airflow, Prefect, and GitHub Actions. They are Swiss Army knives. They can orchestrate data pipelines, microservices, compile code, and more. On the surface, these seem like great, flexible tools.
The problem arises when using these Jack-of-all-trades orchestrators for asset-oriented work like building data pipelines. You get an impedance mismatch: they don’t work well with the rest of the stack. The mismatch results in all sorts of headaches: clunky integrations, fragmented dataflows, and limited observability and understanding of how your data flows from point A to point B.
"An impedance mismatch refers to the discrepancy between two systems' data representations or communication protocols, causing inefficiencies or errors in data transfer or integration."
Placing a workflow-oriented orchestrator at the center of your otherwise asset-oriented data platform creates as many problems as it solves, forcing developers to continuously translate between the workflow-oriented world of the orchestrator and the asset-oriented world of the rest of the data platform.
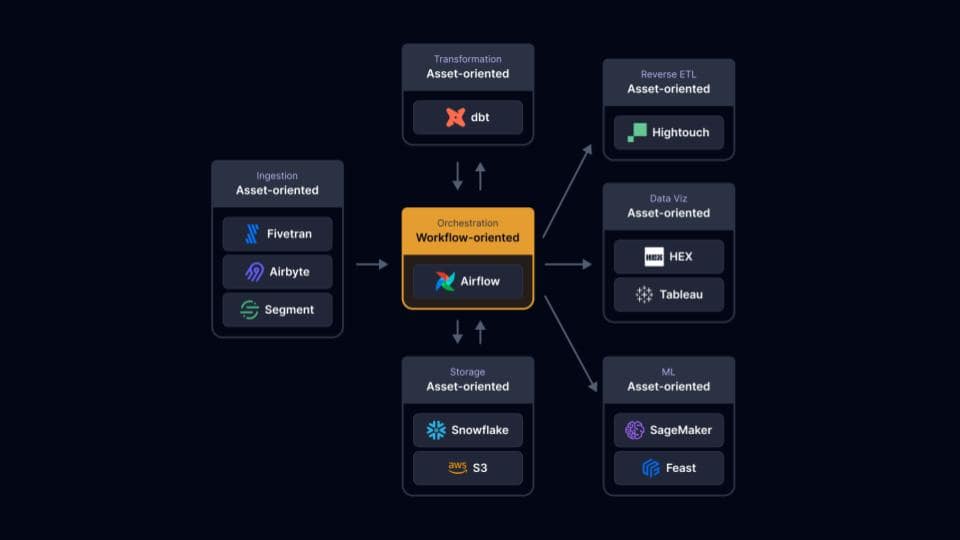
What Asset-Orientation Enables
We built Dagster to be an asset-oriented data orchestrator and fix this impedance mismatch. Immediately, we were able to realize several benefits on behalf of our customers.
First, asset-orientation enabled super developer experience. Platform owners and pipeline builders were able to write code and visualize their pipelines in a very natural style. Tasks which had previously been a huge hassle became fun.
Second, asset-orientation enabled the dream of the decentralized data platform. With workflow-oriented orchestrators, large organizations were unable to adopt data mesh best practices because the tangled web of dependencies was difficult to manage. By overlaying a single, global asset graph over the whole organization - as an asset-oriented orchestrator does - large organizations were able to empower individual teams to work autonomously while also enabling them to depend on each other.
Furthermore, this approach enabled centralized data platform teams to maintain a “single pane of glass” over the whole platform.
However, as we worked with customers, we realized that the asset-oriented approach enabled us to deliver value beyond the scope of traditional orchestrators.
Dagster+: Moving Beyond Traditional Orchestration
Dagster’s asset-oriented fundamentals lays the foundation for additional capabilities that leverage the lineage and metadata of the assets. Dagster+ brings new capabilities to the category that leverage this core asset-oriented data model.
Data Reliability, Quality and Freshness
The first capability we are building into the orchestration layer is data reliability: a suite of capabilities that encompasses quality and freshness checks. Colocated with the definition of our assets, we can state our expectations for completeness, pattern matching (i.e. non-nulls, phone numbers, etc.), shape, and update frequency of a data asset. This makes Dagster the single pane of glass for both operational and quality information, and also enables Dagster to make orchestration decisions based on the result of reliability checks.
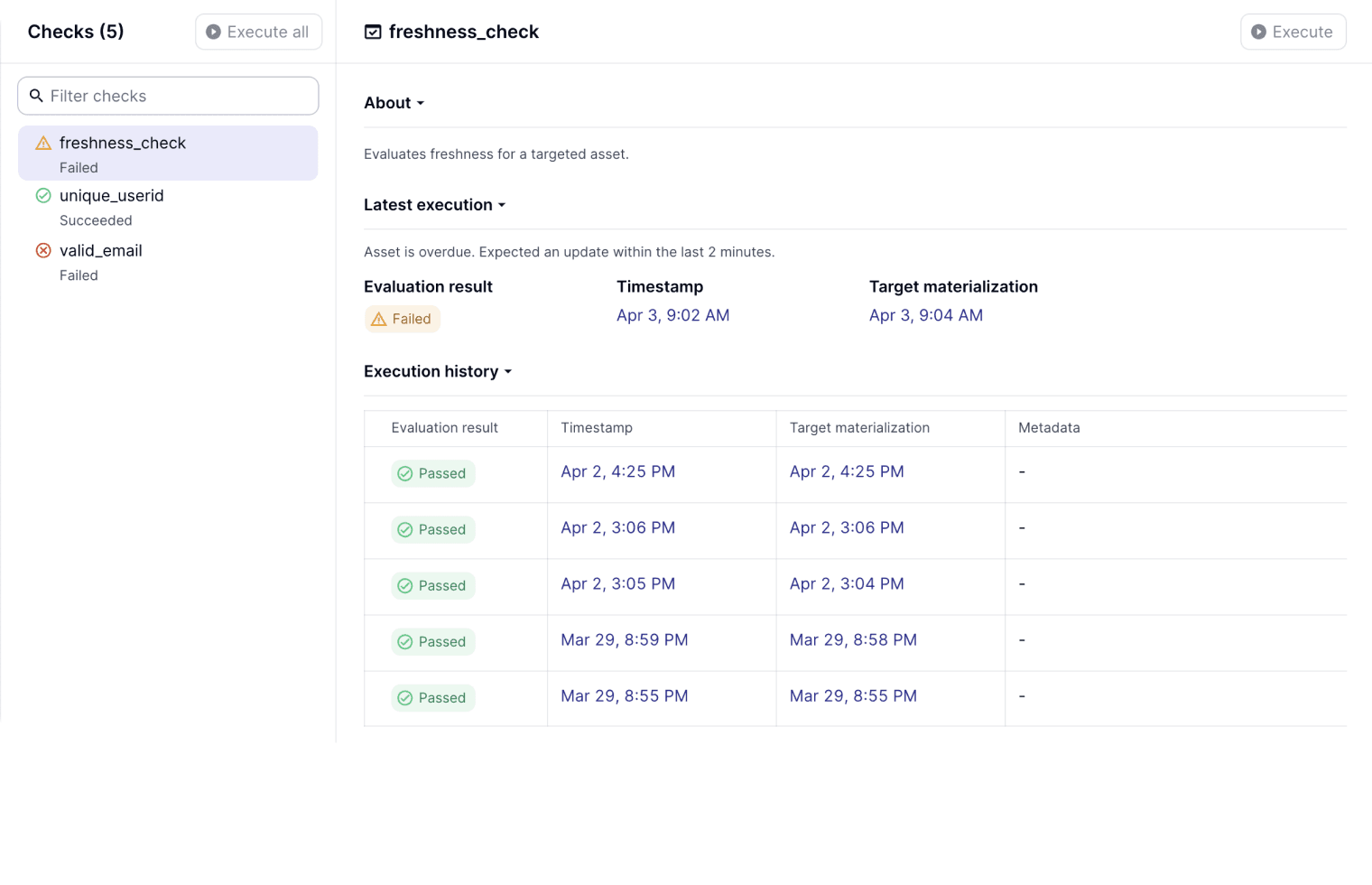
Operational Insights
An asset-oriented orchestrator is the source of truth for both the asset graph and the underlying compute that materializes assets. This implies that an asset-oriented orchestrator is the natural place to aggregate, visualize, alert on and optimize data pipeline cloud spend.
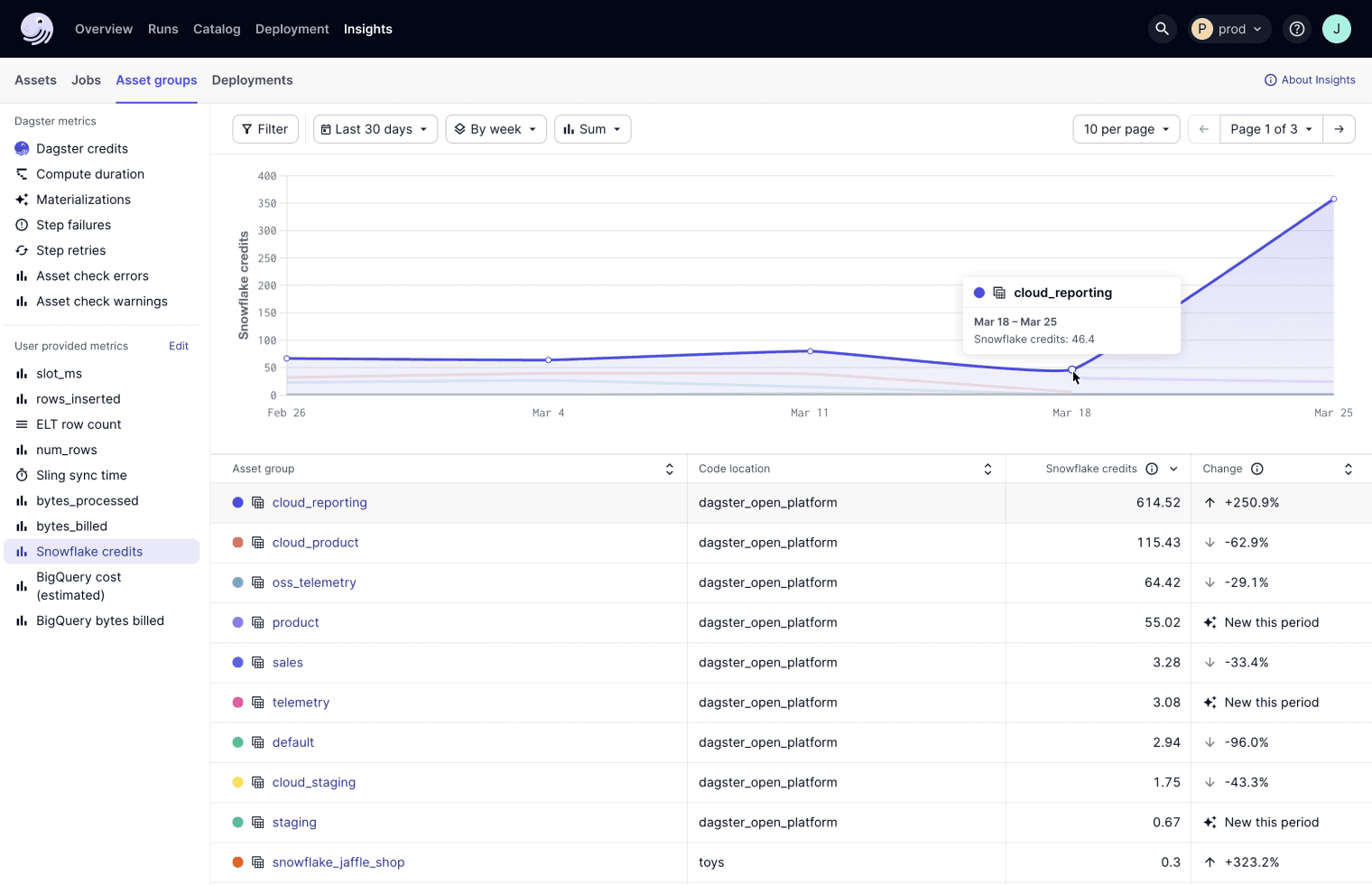
Data Cataloging
A final high-value-add capability of an asset-oriented system is that it already collects all the critical metadata related to your data assets, and therefore is uniquely placed to maintain an always-up-to-date data catalog. With Dagster+ we are launching a brand new data catalog experience that includes advanced features like column-level lineage. This catalog serves every data practitioner: from those owning the platform, to those building data pipelines, and data consumers leveraging the outputs of those data pipelines.
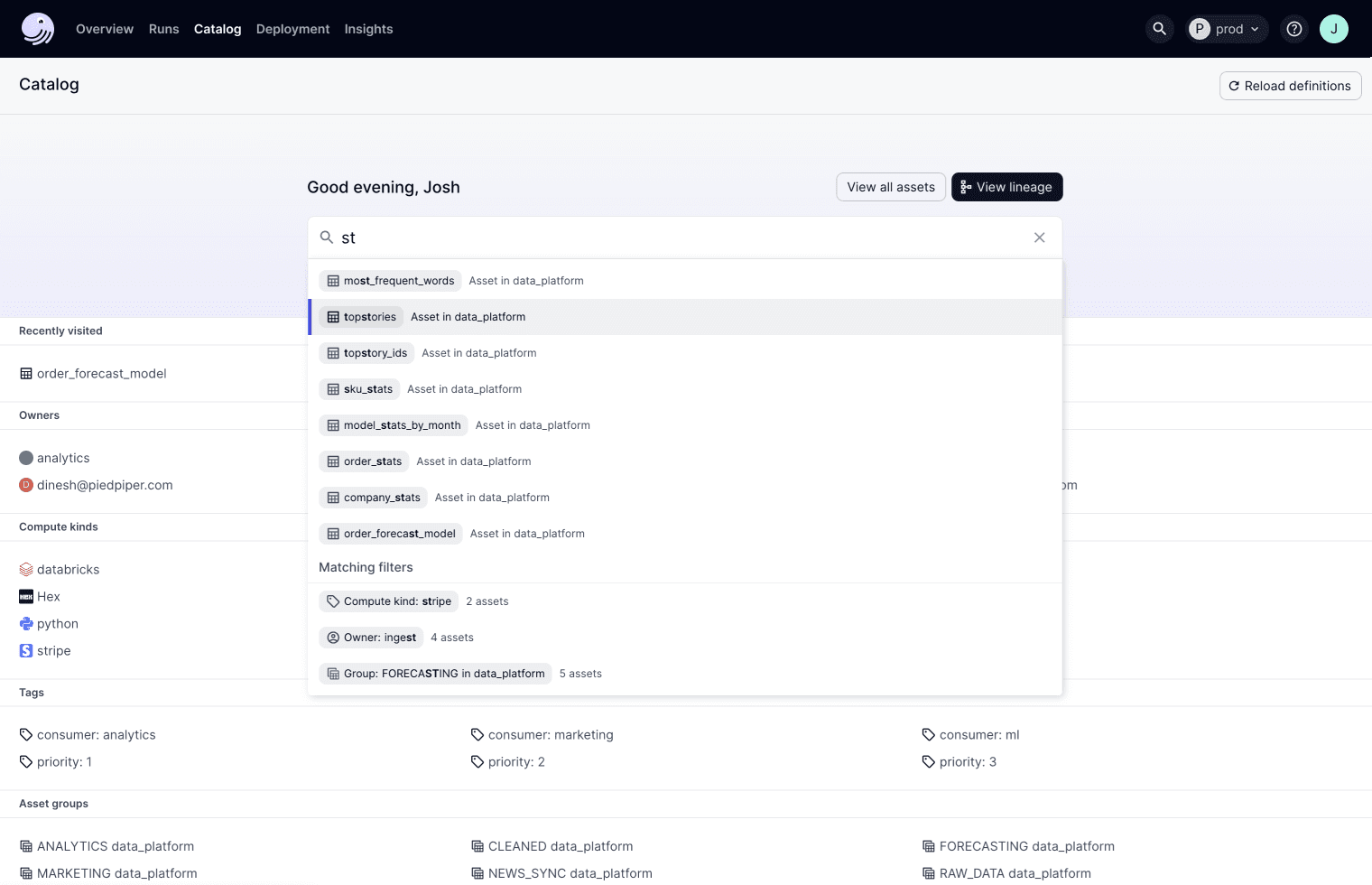
Looking Ahead
With Dagster+, we envision a future where data orchestration is fully integrated into the data platform, reducing complexity, enhancing transparency, and fostering collaboration. The asset-oriented approach addresses the technical impedance mismatch and aligns with the organizational and operational needs of modern data teams. By focusing on assets, Dagster+ not only streamlines the development and operation of data pipelines but also paves the way for innovative features and capabilities that leverage the full potential of the data stack.
On April 17th, we released Dagster+, a new hosted solution from Dagster Labs that challenges the limitations of traditional orchestration tools.





.jpg)
.png)



.png)

