





Why running data ingestion jobs straight from the orchestrator is often a preferred approach.
ELT (Extract, Load, Transform) processes are crucial for moving and transforming data from various sources into a centralized data warehouse or data lake. As data volumes grow and the complexity of data workflows increases, having a flexible data platform becomes essential.
Dagster is a powerful data platform. You may know of Dagster as an orchestrator, but did you know it also provides a range of options for implementing ELT processes?
In this post, we'll discuss why you might want to look beyond commercial SaaS solutions, and explore the different ELT options available with Dagster including:
- rolling your own solution
- using our official integrations with Fivetran and Airbyte
- leveraging embedded ELT
We'll compare and contrast these options and provide recommendations to help you choose the right one for your needs.
Why Look Beyond SaaS Solutions for Data Ingestion?
As ELT overtook ETL in the modern data stack, being able to ingest data easily, rapidly, reliably and cheaply became a key concern in data engineering teams. The rapid adoption of SaaS solutions like Fivetran, Airbyte, Stitch or Meltano helped address this need. But in the long term, third-party SaaS solutions proved less flexible and expensive.
For example, using Fivetran’s Starter Plan for ingestion costs about $120 per month for 200K Monthly Active Rows (MARs) and can quickly escalate to an average of $4,628 per month for 50 million MARs, demonstrating how costs can accumulate even for small to medium-sized enterprises (source: Datrick, Quoting Fivetran).
Most data teams - even small ones - will quickly scale up to tens of thousands of dollars in data ingestion bills a year.
The truth is data ingestion is both a commodity, low value-add task, but also a critical step in your pipelines and often needs some bespoke tweaks to get it working the way you need.
Today, there are several open-source libraries for doing data ingestion, which is a great option if you have a system in which to configure and run the ingestion jobs.
Dagster and ELT
By running data ingestion jobs in Dagster, you not only benefit from a free and efficient ELT step, you also gain all the benefits of testability, versioning, and observability. You can monitor ingestion runs, and you can partition your dataset for more efficient jobs.
With Dagster, the outcome of your ingestion run is a software-defined asset. This opens the door to all the benefits of SDAs: cataloging, column-level lineage tracking, and the ability to schedule your ingestion steps in a fault-tolerant, context-aware fashion.
By selectively replacing your expensive data ingestion steps with Dagster embedded ELT you can achieve both significant cost savings, and improve the performance of your data processes.
ELT Options in Dagster
Rolling Your Own ELT Solution
Rolling your own ELT solution gives you complete autonomy over the entire process. You can fine-tune every aspect of the process to fit your unique needs, creating a system that aligns perfectly with your operational objectives.
However, substantial development effort is required. Additionally, there are potential issues around maintenance and scalability. As your data grows or your needs change, you may find it challenging to scale your solution or keep it up-to-date. This option, therefore, is best suited for scenarios that involve highly specialized data workflows or organizations that have specific compliance or security requirements that a more generic solution may not meet.
SaaS solutions: Fivetran, Airbyte, et al.
Fivetran and Airbyte are examples of managed ELT solutions that provide pre-built connectors for a wide range of data sources. These solutions can be seamlessly incorporated into Dagster pipelines using Dagster integrations, allowing you to leverage the benefits of managed services while using Dagster for orchestration. These integrations greatly simplify the process of setting up and managing ELT workflows.

The pros of using these integrations are manifold. For one, they significantly reduce the development and maintenance effort required, as much of the groundwork is already done for you. Additionally, they offer scalability and reliability, which are critical for handling large volumes of data and ensuring the smooth execution of workflows.
However, there are a few cons to consider as well. Cost is a significant factor. Also, there's the risk of potential vendor lock-in, which could reduce flexibility in the long run.
Despite these considerations, these managed solutions are especially useful for organizations seeking a quick and reliable ELT setup and teams with limited engineering resources that need a ready-to-use, efficient solution.
Embedded ELT with Dagster
Dagster's embedded ELT feature is a cost-effective and flexible solution for implementing ELT processes. It includes components like Sling and dlt within the dagster-embedded-elt package, which facilitate data ingestion and transformation within Dagster pipelines. This feature provides better control over ingestion steps and integrates with Dagster's orchestration capabilities, making it a cost-effective choice.
It's a good fit for teams seeking a balance between control and ease-of-use, and for organizations aiming to reduce costs while maintaining flexibility in their ELT processes.

Comparison of ELT Options
To help you decide which ELT option is best for your needs, let's recap a bit and compare them based on several key factors:
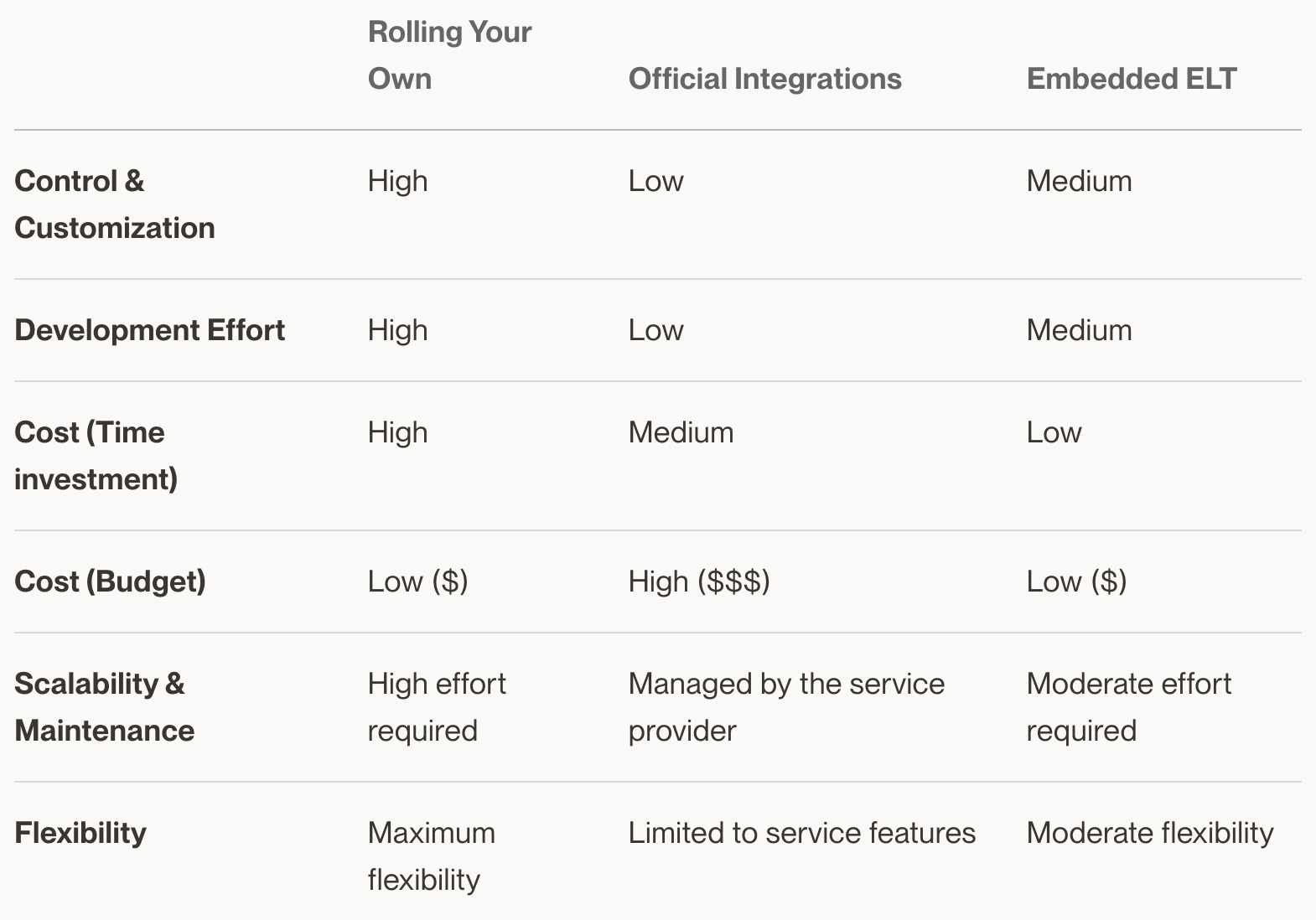
Recommendations: Approaching ELT in Dagster
Having reviewed the options, here are our implementation recommendations:
Startups / Small Teams
This category includes teams of 1-10 members, limited or no dedicated technical infrastructure, generally low to moderate customization needs, While official integrations such as Fivetran, Airbyte, or Stitch provide a quick and reliable ELT setup without the overhead of managing infrastructure, it’s important to assess the customization they allow versus what is actually needed.
Medium to Large Enterprises
Teams of 11-50 members (medium enterprises) and 50+ (large enterprises) typically have access to more substantial technical resources. These teams should consider a multi-tool: using standard tools for basic ingestion needs and transitioning to more customizable solutions like embedded ELT for processes that require specific tailoring.
For cases requiring more complete control, rolling your own bespoke solution might be necessary to fully cater to your unique data processing requirements.
Cost-Conscious Organizations
For organizations focused on optimizing expenditures, leveraging a combination of tools can help balance cost and functionality.
If the objective is simply to move data from A to B outside of the orchestrator, then SaaS solutions (official integrations) are the best option assuming they (a) function as expected for your use case and (b) have an acceptable cost. This means that you will have a process that needs scheduling and checking outside of your main data orchestrator.
But if you need to orchestrate the ELT task, building in full control and observability, then embedded ELT provides the best of both worlds: composability and low cost.
Only for very bespoke situations would you want to adopt a rolling your own approach, building your own ELT solution from scratch.
Conclusion
Choosing the right ELT solution depends on your specific needs, resources, budget, and goals.
Dagster's flexibility and orchestration capabilities make it a powerful solution for managing your data workflows, regardless of the ELT approach you choose.
Ready to get started? Visit our docs for detailed guides and tutorials to help you implement your chosen solution and start building your ELT pipelines with Dagster today.





.jpg)
.png)



.png)

