



Mature orchestration environments often work operationally while still leaving critical data dependencies implicit. This post introduces the Orchestration Maturity Model, explains the architectural ceiling of job-centric systems, and shows how Dagster’s asset-aware approach helps teams reason about freshness, lineage, quality, and self-service at enterprise scale.
Most data teams eventually hear the same three questions.
Did it actually work?
When will my data be ready?
Can I just run it myself?
These questions show up in planning meetings, incident channels, dashboard reviews, and casual messages from stakeholders who depend on the data platform but do not live inside it. They sound simple. They are not.
A job-centric orchestration system can tell you whether code ran. It can tell you whether a task failed, when a schedule fired, and whether a retry succeeded. But stakeholders are asking whether the data is usable, whether it is fresh enough to trust, and whether the platform can support them without waiting on a central data team.
That gap is where many orchestration conversations go wrong. The problem is not usually that the existing team has failed, or that the current scheduler is bad. Many organizations at this stage have strong engineers, alerts, documentation, and years of hard-won operational knowledge. The problem is structural: the platform answers questions about jobs, while the organization needs to reason about data.
That is the architectural case for Dagster.
Name the Ceiling, Not the Tool
In an enterprise Dagster adoption I've been embedded in since last September, the legacy orchestration layer ran business-critical operational data workflows. It worked, but the graph was implicit. Dependencies lived in code paths, logs, schedules, and the heads of experienced engineers. Engineers had to translate logs to code to data to understand the system.
That sentence captures the real burden of many mature orchestration environments. The platform exposes atomized tasks, but the organization operates in data flows.
This matters most when something changes. A downstream table may depend on a side effect from another job. A schedule may quietly encode an ordering assumption. A re-run may be risky because the job is not idempotent. A dashboard may be missing data even though the upstream job is green.
In those moments, the platform does not fully represent the thing the team needs to understand. People fill the gap.
That is why skepticism about changing orchestration infrastructure is reasonable. When orchestration runs operational data, "replace the orchestrator" can sound like "rewrite the thing that keeps production alive." Engineers are not resisting change because they dislike new tools. They are protecting a fragile, business-critical system with unclear dependencies, hidden ordering assumptions, non-idempotent jobs, and re-runs that can carry real production risk.
The case for Dagster only started to click when the conversation changed. It was not "new scheduler versus old scheduler." It was: our current system is centered around tasks, but the organization cares about data flow.
The Maturity Model as Shared Vocabulary
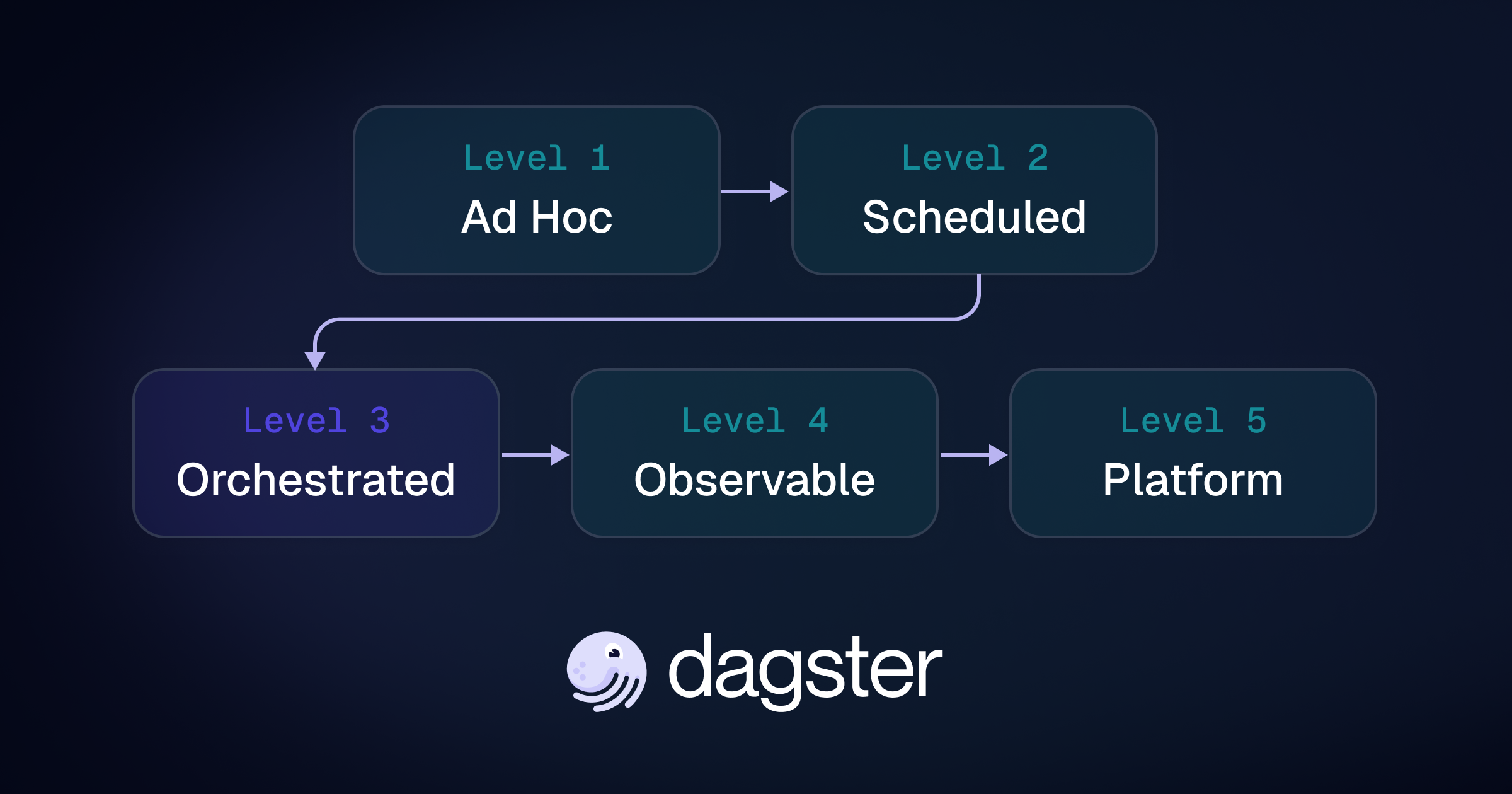
I built the Orchestration Maturity Model during an enterprise adoption because engineers and leadership needed a shared roadmap. Engineers were debating tools and implementation details. Leadership needed to understand why this initiative deserved budget over other data priorities. The model gave both groups a common language for the L2 to L3 crossing.
Earlier framings did not land as well. "Asset-centric orchestration" sounded precise to engineers already close to the problem, but to leadership it read like tooling language. "Better orchestration" was too vague. The framing that changed the conversation was the maturity model: the current platform exposed tasks, while the organization needed to reason in data flows.

The Orchestration Maturity Model. Originally developed for an enterprise Dagster adoption; full framework at conceptuallayer.com.
Most organizations are at L2, including many doing high-quality work. A central scheduler runs jobs. Alerts fire when something breaks. Engineers keep the system alive. The operating model is still job-centric.
L3 is different because the platform starts with assets: what data exists, what produces it, what depends on it, whether it is fresh, and whether it passed its checks.
That crossing is not "bad teams becoming good teams." It is a change in architecture. The organization stops treating orchestration as a control layer for jobs and starts treating it as a platform for managing data assets.
L3 is the inflection point, not the destination. Once the platform models data as a first-class object, the next levels become natural extensions rather than separate initiatives — though they extend along different axes.
L4 is operational maturity of the platform itself. Freshness SLAs, automated remediation, and lineage-driven impact analysis mean the organization stops asking whether data is ready and starts being told when it isn't.
L5 is organizational maturity around the platform. Data contracts, self-service authoring through code locations, and measured ownership turn the platform into a shared product that multiple teams build on.
The crossing to L3 is the work. L4 and L5 are what that work makes possible.
What Dagster Changes Architecturally
The practical case for Dagster becomes much stronger when each architectural property starts with the failure mode it solves. These failure modes mark the L2 ceiling; how Dagster resolves each one traces the path through L3 and toward L4 and L5.
The first failure mode is a successful run with unusable data.
A job finishes. The alert does not fire. But downstream, a table is missing records, a dashboard refreshes with incomplete data, and the data team is now explaining why "green" did not mean "safe to use."
That is the limit of job status as a proxy for data health. A task can complete successfully and still produce data that is incomplete, stale, or untrustworthy.
Dagster changes the unit of orchestration to the asset: a table, file, model, report, or other persistent data object. Software-defined assets describe in code what should exist and how it should be produced. Asset checks then make quality signals part of orchestration rather than a separate afterthought.
The question changes from "did the script finish?" to "is the asset healthy?"
The second failure mode is a dependency graph that exists only in people's heads.
One common pattern is a downstream table depending on a side effect from another job. The dependency is real, but not formally represented. It works because schedules usually fire in the expected order, or because a few senior engineers know the unwritten rules.
That kind of system can operate for years. But it becomes difficult to change safely. Every incident, re-run, or upstream modification requires someone to reconstruct the graph manually.
Dagster's asset graph makes lineage part of the implementation. Dependencies are not an external diagram that slowly goes stale. They are encoded in the platform's working model of the data system.
That matters for impact analysis. Before changing an upstream asset, the team can see what depends on it. Before re-running part of the platform, they can reason about the downstream effect. The graph becomes something the organization can inspect, not something engineers must infer.
The third failure mode is schedule-based automation hiding ordering assumptions.
In one migration, increasing pipeline frequency exposed hidden dependencies in the old orchestration layer. When frequency changed, execution order changed. When execution order changed, missing data appeared. The old schedule had been carrying more meaning than anyone wanted it to carry.
This is the problem with using time as the main coordination mechanism. "Run this at 7:00" is not the same as "run this when the required upstream data is ready."
Dagster's declarative automation helps move orchestration closer to the state of the data. Assets can update based on dependency status, missing partitions, freshness expectations, or other declared conditions. The platform can respond to what has happened in the asset graph instead of relying only on wall-clock assumptions. This is part of what opens the path from L3 toward L4: when orchestration follows data state, freshness SLAs and automated remediation become natural extensions to layer on top.
The fourth failure mode is every production change feeling dangerous.
If jobs are non-idempotent and dependencies are unclear, re-runs become risk assessments. Engineers have to ask: what will this overwrite, what already consumed this data, what downstream state might change, and which order is safe?
That kind of friction limits how quickly the organization can move.
Dagster does not magically remove the need for careful migration work. But it gives teams a better architectural surface for change. Asset-aware execution, partitions, checks, lineage, and reviewable Dagster code reduce the amount of behavior that has to remain implicit.
Branch deployments are important in this context. When the asset graph is part of the platform contract, changes to assets and dependencies should be visible before they affect production. A pull request should not only show code changes; it should help the team understand how the operational graph changes.
The fifth failure mode is the central data team becoming the bottleneck for every new data workflow.
One analyst team knew fresher sales data existed but could not access it through the platform quickly enough to do its work. The old architecture made it difficult to increase the pipeline frequency safely, and the result was delayed analysis and manual workarounds.
That is the kind of moment where "self-service" stops being an abstract platform goal. The point is not that everyone can do anything. It is that product teams can bring their own data pipelines into the shared orchestration layer without rebuilding the platform from scratch or bypassing governance.
Dagster code locations support this operating model. A product team can own its Dagster definitions in its own code location while participating in the broader orchestration platform. In practice, that means a team can onboard through an internal build pipeline or repository template, define its own assets, and still connect to the existing asset graph.
That is where the architecture starts to unlock organizational energy, and where the L5 transition becomes possible. Product teams can build their own pipelines, see existing assets, and contribute to a shared platform rather than creating another isolated system.
The Same Questions, Different Answers
Return to the three stakeholder questions.
Did it actually work?
In a job-centric system, the answer often starts with a run status. In Dagster, the answer can start with the asset: whether it materialized, whether its checks passed, what upstream data it depended on, and whether it is fresh.
When will my data be ready?
In a schedule-centric system, the answer is usually inferred from expected run times. In an asset-aware system, readiness can be represented directly through freshness, materialization status, dependencies, and automation conditions.
Can I just run it myself?
In a fragile system, that question creates anxiety because the blast radius is unclear. In an asset-aware system, self-service can be governed by the graph itself: what asset is being materialized, what it depends on, what partitions are involved, and what checks need to pass.
In an asset-aware system, more of that operational context lives in the platform itself, not in people's heads.
Why This Is More Than a Tool Swap
In leadership conversations, the most useful pushback was not "why Dagster?" It was "why this initiative and not a different initiative?" Underneath that question was a budget concern: platform investment is finite, and orchestration has to compete with many other data priorities.
The answer could not be "because Dagster is better." It had to be: because the current orchestration layer limits how safely and quickly the organization can build on its data.
A scheduler answers when jobs run. An asset-aware orchestrator answers a different set of questions altogether: what data exists, how it got produced, what depends on it, and whether it can be trusted. Those are different categories of questions.
That difference creates a different operating model. Incident response becomes less dependent on tribal knowledge. Re-runs become easier to reason about. Product teams can bring pipelines into a shared platform. Leadership gets a roadmap from L2 to L3 instead of a vague argument about better tooling.
As organizations layer AI and analytics tooling on top of their data platforms, the cost of operating without asset-level freshness, quality, and lineage metadata only grows.
The case for change has to be proportionate to the cost of change. An L2 to L3 migration is real work. The argument for it has to be architectural because the benefits are architectural.
The Internal Case, In Brief
The current platform answers questions about jobs. Stakeholders ask questions about data. That gap is structural.
Closing it requires a platform that models data as a first-class object, makes dependencies explicit, automates based on data state, and treats pipeline changes as reviewable. Dagster is built around those properties.
L2 is valid work. The L2 ceiling is real. The case for crossing it becomes easier to make when the organization can see what the current platform can and cannot represent.
Dagster matters because it moves orchestration from a system engineers interpret to a platform the organization can build on.





.jpg)
.png)



.png)

