March 1, 2022 • 11 minute read • ![]()
Introducing Software-Defined Assets



- Name
- Sandy Ryza
- Handle
- @s_ryz
This post introduces software-defined assets, a new, declarative approach to managing data and orchestrating its maintenance. It has four sections:
- Declarative approaches in data management
- Introducing the software-defined asset
- Orchestration: managing change in assets
- Software-defined assets and the Modern Data Stack
Declarative approaches in data management
Over the past two decades, the way we build software has changed. Frontend engineering has moved from jQuery, an imperative library that makes it easy to manipulate webpages, to React, which allows writing JavaScript that declares the components you want on the screen. The DevOps community has embraced Infrastructure as Code — it’s moved from imperative shell scripts that spin servers up and down to frameworks like Terraform, which allow you to simply declare the servers you want to exist.
Declarative approaches are appealing because they make systems dramatically more debuggable, comprehensible, and automate-able. They do this by making intentions explicit and by offering a principled way of managing change. By explicitly defining what the world should look like — e.g. by specifying the set of servers that should exist — it becomes easy to discover when it does not look like that, reason about why, and reconcile.
While the way we build software in many critical domains has transitioned to a declarative model, visit a data platform, even at a technologically sophisticated organization, and you’ll find that imperative programming is still alive and kicking. Scripts and scheduled jobs overwrite tables with reckless abandon, leaving a trail of confusion in their wake. Discovering how a table or ML model is generated requires a heroic act of code-spelunking. Deploying changes to data feels dangerous and irreversible. Debugging requires untangling a complicated history of state mutations. Backfills are error-prone and chaotic. It's hard to distinguish trustworthy, maintained data from one-off artifacts that went stale months ago.
While the way we build software in many critical domains has transitioned to a declarative model, visit a data platform, even at a technologically sophisticated organization, and you’ll find that imperative programming is still alive and kicking.
Declarative approaches have started to surface in some of the tools and practices identified with the Modern Data Stack. dbt enables declaring tables using pure SQL transformations. Maxime Beauchemin’s Functional Data Engineering advocates for a declarative approach, and bespoke tools inside many organizations have adopted its recommendations. But, so far, these approaches are siloed. Python and other non-SQL programming languages have largely been left behind, and, when data or execution dependencies span different technologies, developers are again stuck using imperative programming to coordinate them.
What would it look like to transition data platforms to a declarative model? In DevOps, we care about servers. In frontend engineering, we care about UI components. In data, we care about data assets. A data asset is typically a database table, a machine learning model, or a report — a persistent object that captures some understanding of the world. Creating and maintaining data assets is the reason we go to all the trouble of building data pipelines. Assets are the interfaces between different teams. They’re the objects that we inspect when we want to debug problems. Ultimately, they're the products that we as data practitioners build for the rest of the world.
The world of data needs a new spanning abstraction: the software-defined asset, which is a declaration, in code, of an asset that should exist. Defining assets in software enables a new way of managing data that makes it easier to trust, easier to organize, and easier to change. The seat of the asset definition is the orchestrator: the system you use to manage change should have assets as a primary abstraction, and is in the best position to act as their source of truth. Dagster is an orchestrator built for this declarative, asset-based approach to data management.
The world of data needs a new spanning abstraction: the software-defined asset, which is a declaration, in code, of an asset that should exist.
Introducing the software-defined asset
Declarative data management starts with using code to define the data assets that you want to exist. These asset definitions, version-controlled through git and inspectable via tooling, allow anyone in your organization to understand your canonical set of data assets, allow you to reproduce them at any time, and offer a foundation for asset-based orchestration.

The Dagster asset
Each asset definition has three main parts:
- An asset key, which is a global identifier for the asset.
- An op, which is a function that we invoke to produce the asset.
- A set of upstream asset keys, which reference the inputs to the op, and which are usually asset definitions themselves.
Upstream asset keys
The inclusion of upstream asset keys means that each asset definition knows about its dependencies. This distinguishes them from the task abstractions found in traditional orchestrators, which instead track dependencies inside the DAG or workflow objects that hold the tasks. By tracking dependencies alongside the nodes, instead of expecting them to be captured in a centralized artifact, the asset graph can easily scale to model the hundreds or thousands of assets that show up in even modestly sized organizations.
An asset definition can be invoked by the orchestrator to materialize that asset, i.e. to run the op on the contents of the upstream assets and then persist the results in storage, like a data warehouse, data lake, or ML model store.
Each asset is a decorated function
Here’s a simple asset definition using Dagster’s Python API. It defines an asset called "logins", which is derived from an upstream asset called "website_events". "logins" and "website_events" are both tables.
@asset
def logins(website_events: DataFrame) -> DataFrame:
return website_events[website_events["type"] == "login"]
The asset key is "logins" — taken from the name of the decorated function. The decorated function is the "op" — it’s used to compute the contents of the asset. "website_events" is an upstream asset key, inferred from the name of the argument of the decorated function.
The logins asset is defined as a pure function; Dagster's asset APIs encourage (but don't require) separating business logic from IO. The code that persists it is provided separately and shared across multiple assets.
Dagster allows defining assets in pure Python, as shown above, but it also embraces loading asset definitions from other systems. From Dagster's perspective, dbt models are software-defined assets for the analytics engineer, and Dagster offers utilities for loading dbt projects as sets of software-defined assets. It’s also often useful for a software-defined asset to wrap a computation that occurs on a hosted platform; for example, the definition for one of the base tables in your data warehouse might invoke Fivetran, Airbyte, or Meltano to populate its contents.
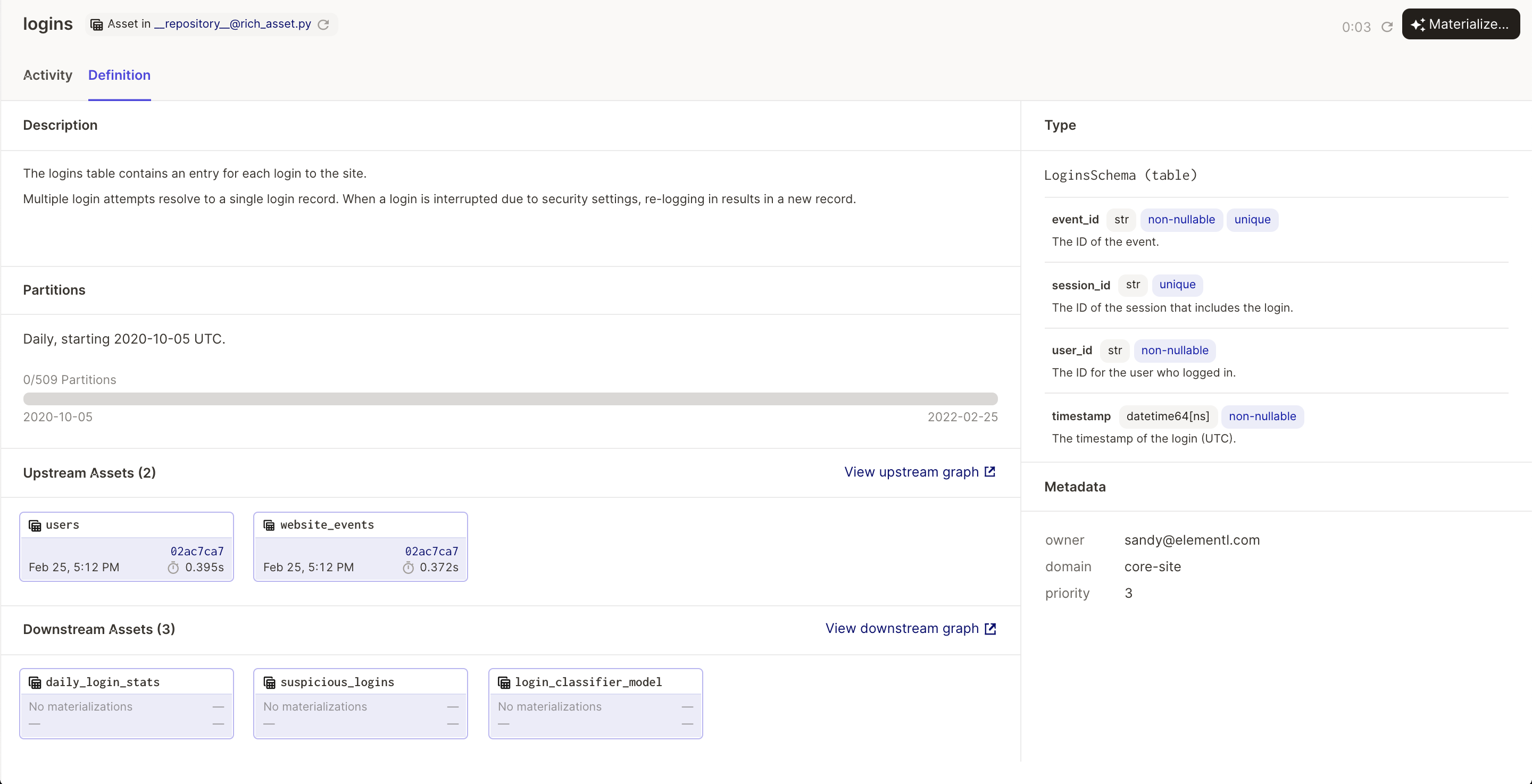
In addition to the main parts described above, a software-defined asset is a natural nexus for metadata that should be versioned with the definition of the data it applies to: schema, ownership, data quality checks, and SLAs. For example, here’s an asset definition with a richer set of metadata:
@asset(
metadata={"owner": "sandy@myfakeemail.com", "domain": "core-site", "priority": 3},
dagster_type=LoginsSchema,
partitions_def=DailyPartitionsDefinition(start_date="2020-10-05"),
compute_kind="pandas",
)
def logins(website_events: DataFrame, users: DataFrame) -> DataFrame:
"""
The logins table contains an entry for each login to the site.
Multiple login attempts resolve to a single login record. When a login is interrupted due to
security settings, re-logging in results in a new record.
"""
...
The "Definition" tab on the Dagster "asset details" page makes it easy for anyone within an organization to get a holistic view of an asset definition, and Dagster’s APIs make it possible for tooling to consume it.

The asset graph
A collection of software-defined assets constitutes an asset graph. Asset graphs are critical tools for understanding and working with data. For a data developer, the asset graph offers a cross-technology way of answering "if I changed asset X, what would the impact be on asset Y?", as well as a basis for discovering the root cause of unexpected results. For a data consumer, the asset graph reveals the lineage of an asset, which gives insight into its contents, whether it’s experiencing problems, and whom to chase down for help.

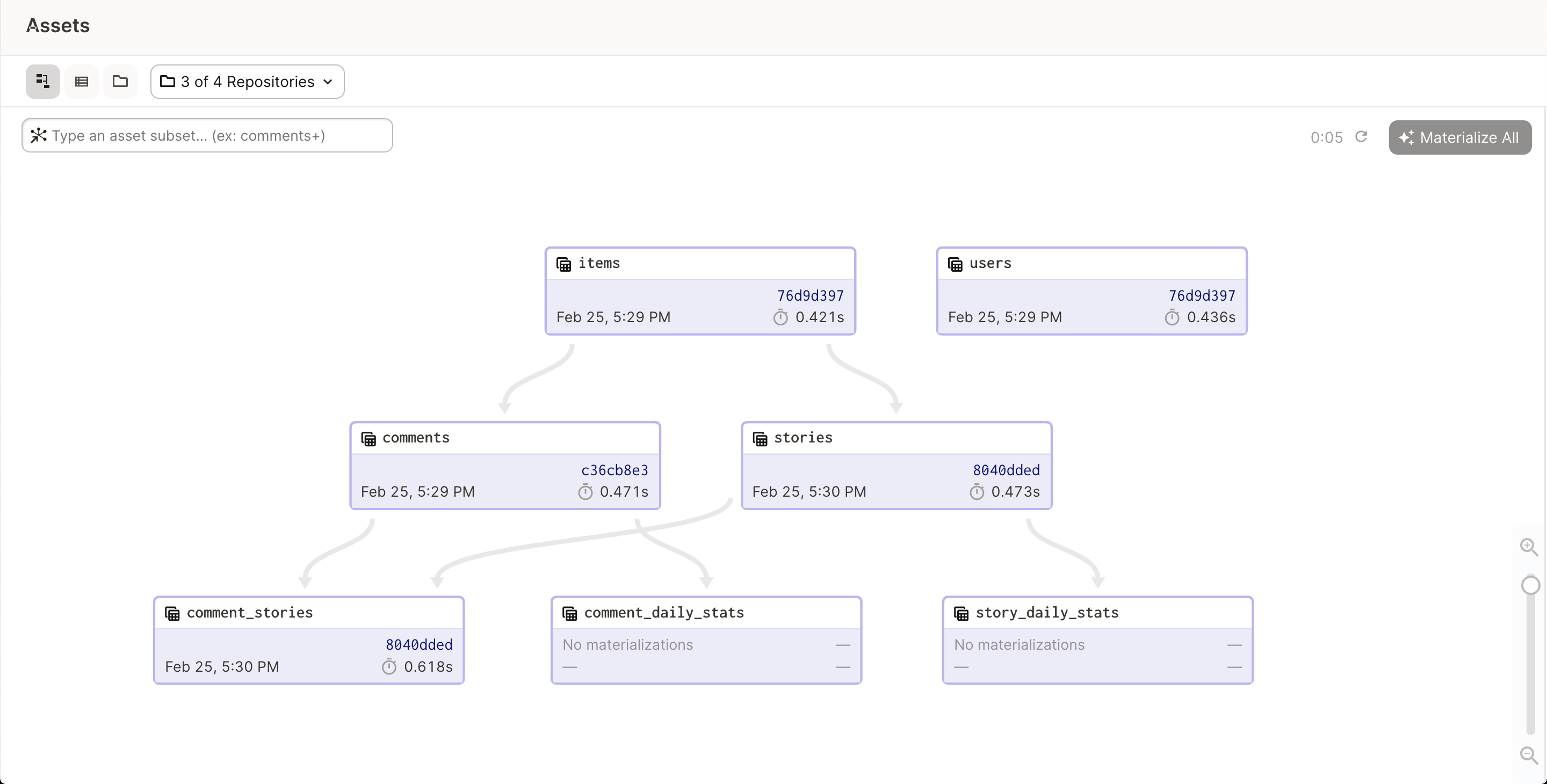
Software-defined assets naturally facilitate a federated model of asset management and observation. Because each asset declares its upstream assets, no single team needs to be responsible for maintaining a monolithic DAG that captures all dependencies. Collected across an organization, the asset graph offers a picture of how data moves across technologies and teams. Here’s an image of an asset sub-graph: just the group of assets that are maintained by a single team. It contains links to assets that the team’s assets depend on, or that are depended on by the team’s assets:

Software-defined asset graphs look similar to the lineage graphs that show up in some data observability tools, but there’s a crucial difference. The software-defined asset graph is an explicit declaration of intention, not just a post-hoc observation of what happened. It expresses what assets the developers expect to exist and how they expect those assets to relate.
The software-defined asset graph is an explicit declaration of intention, not just a post-hoc observation of what happened.
This declarative approach to asset lineage naturally reins in much of the chaos that is rampant in traditional data platforms. Data practitioners regularly refer to their data warehouses and data lakes as cesspools or tangled messes. The software-defined asset graph can be constructed directly from a group of assets defined in code, which means practices for managing and evolving code can be harnessed for managing data.
Orchestration: managing change in assets
When new upstream data arrives, or when we change the code that derives our assets from their upstream dependencies, we need to launch computations to keep our assets up-to-date. Launching these computations at the right times is typically a job for an orchestrator — a system that invokes computations and models the dependencies between them.
Because orchestrators are the source of truth on scheduling, dependencies, and kicking off computations, they hold the key to answering some of the most important questions in data management:
- Is this asset up-to-date?
- What do I need to run to refresh this asset?
- When will this asset be updated next?
- What code and data were used to generate this asset?
- After pushing a change, what assets need to be updated?
But traditional orchestrators are ill-equipped to answer these questions, because "asset" is not a core part of their data model. They can tell you what tasks have completed, what tasks depend on what other tasks, and when tasks are scheduled to run, but they can't tell you what those tasks have to do with what you ultimately care about — the assets that the tasks are reading and writing.
An orchestrator that centers on assets is the ideal system for answering these questions. It eliminates the friction of translating between assets and tasks and can speak authoritatively about how the asset's stakeholders can expect it to be updated. Here's Dagster's asset page, for an asset on a schedule:

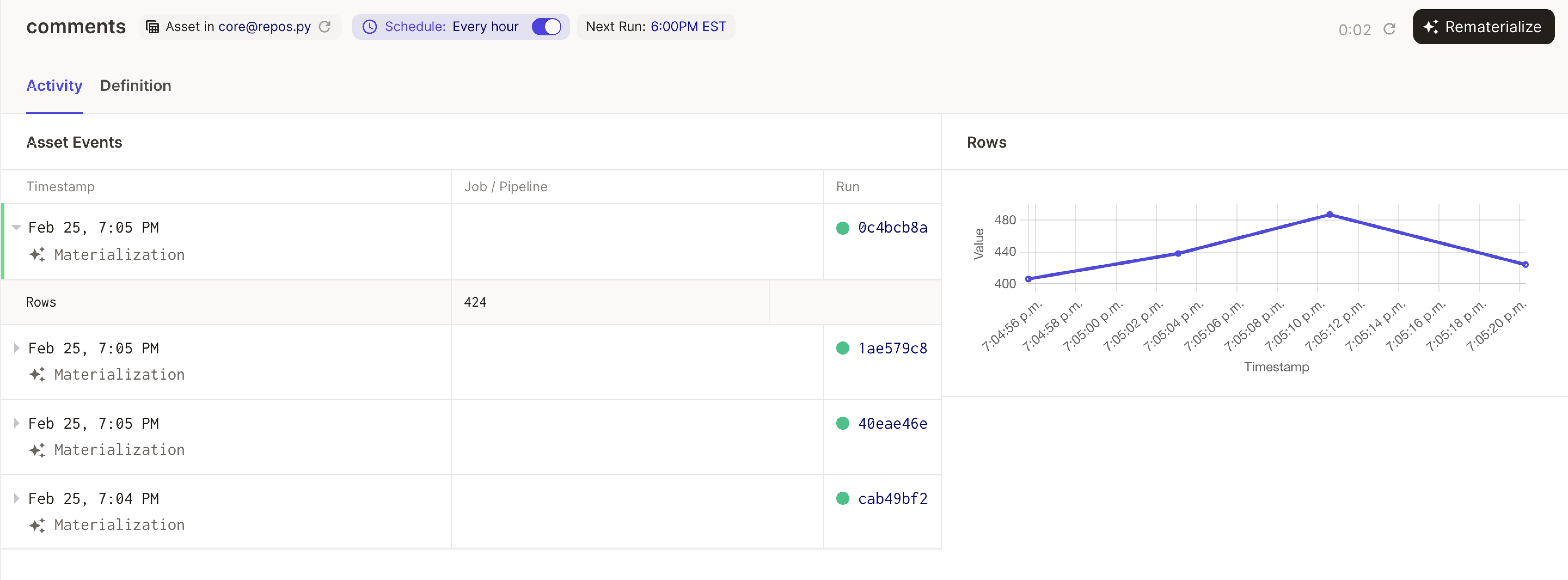
There are a few things to point out here:
- The table of materializations indicates the last time the asset was updated, which helps determine whether it’s out-of-date.
- Because the orchestrator is responsible for scheduling future materializations, it can tell you when the asset is next scheduled for an update.
- If you notice that the asset is out of date and isn’t scheduled for an update soon enough, you can click the "Rematerialize" button to launch a run that refreshes it.
If the asset is partitioned, this is all available at the level of each partition. This metadata and functionality are also available through Dagster’s APIs, which allows it to appear in other systems alongside other metadata about assets that Dagster doesn't have access to.
Orchestration as reconciliation
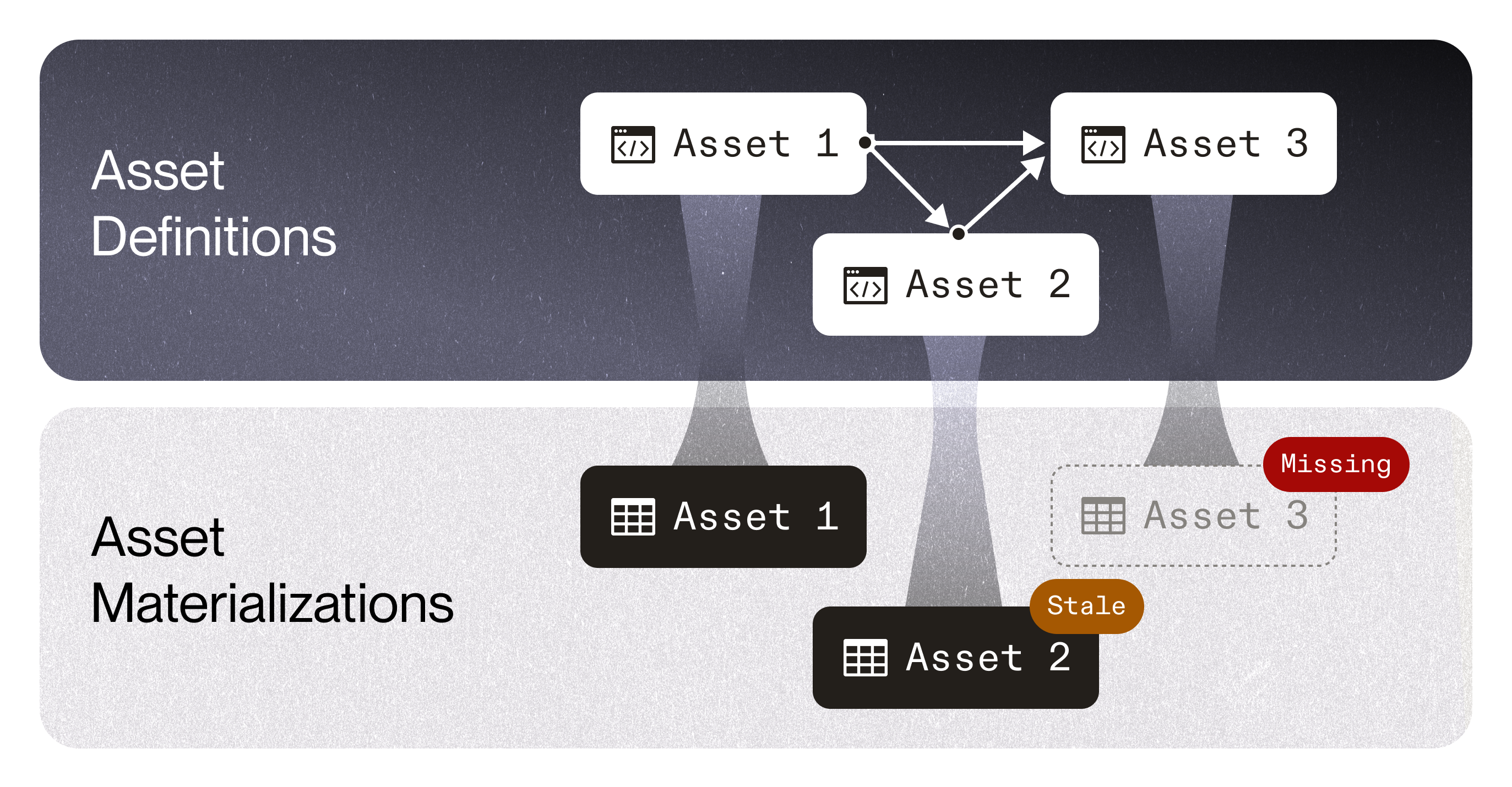
Asset-based orchestration isn’t just about making it easier to translate between assets and computations; it also enables a more principled approach to managing change in those assets, through a process of reconciliation. Reconciliation-based orchestration means observing discrepancies between how the world "is" to how the world "should be", and then, depending on the scheduling policy, launching any computations that are required to make them match. "How the world is" means the most recent materializations of your assets: their physical representations in storage. "How the world should be" means your software-defined assets: their representations in code. Scheduling based on this comparison offers a path to increased confidence that assets are up-to-date, insight into why they’re not up-to-date, and less wasted computation.
Reconciliation-based orchestration is present in the latest version of Dagster, but will see even deeper realization in coming versions.
Definition-materialization discrepancies
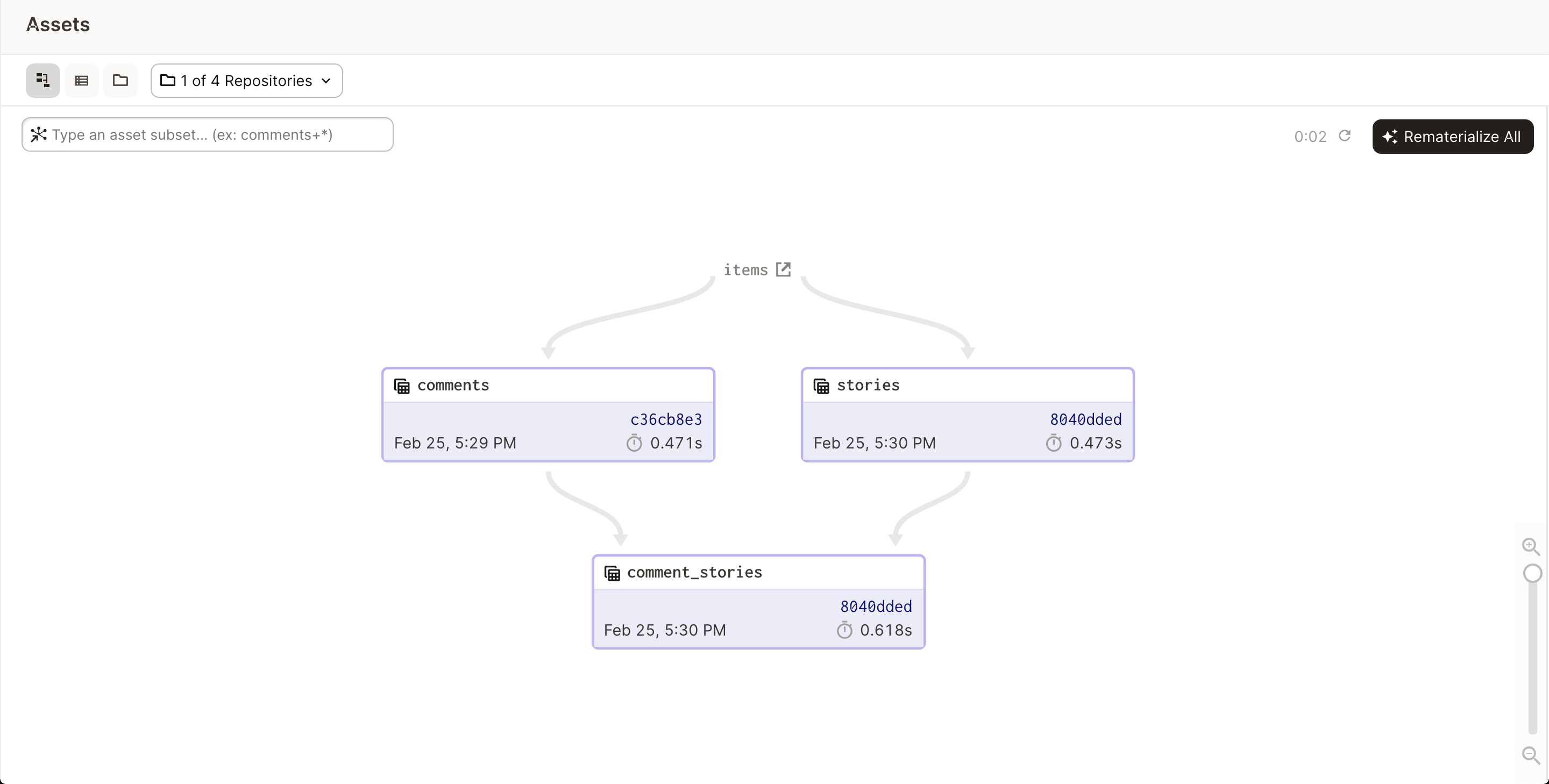
The most basic discrepancy in need of reconciliation is when you have a software-defined asset with no materializations. To make the set of assets in physical storage match the set of assets you’ve declared, you need to materialize the asset. Here's an asset graph with an unmaterialized asset, comment_stories:

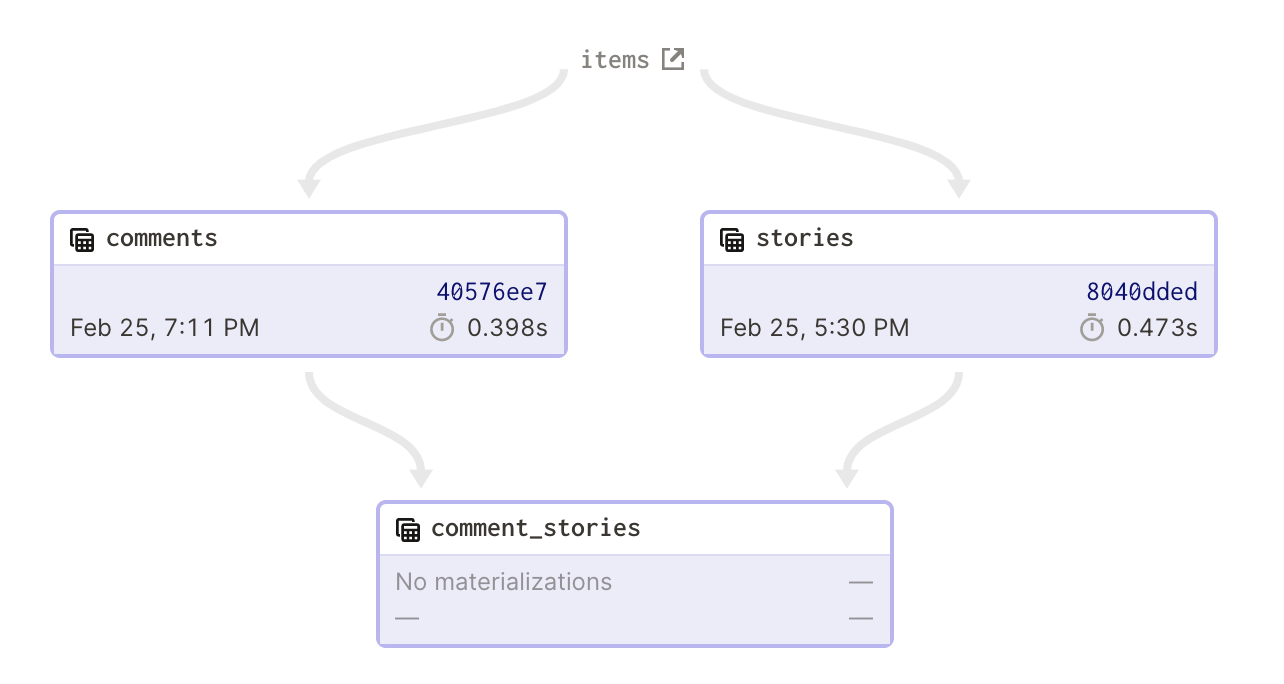
Materializing comment_stories resolves this discrepancy.
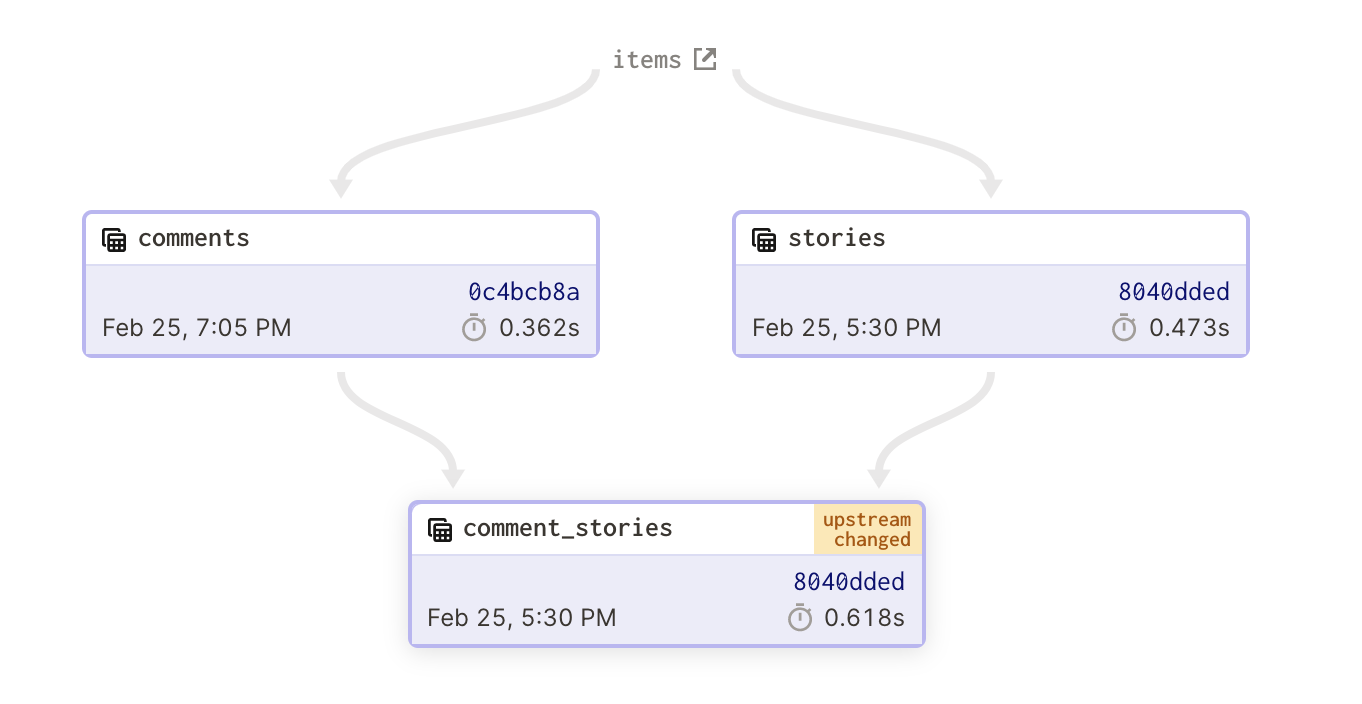
Another discrepancy is when the contents of an asset don’t reflect the contents of the assets it depends on. By default, declaring that an asset depends on an upstream asset means that the contents of the asset should be based on the most recent contents of the upstream asset. If the most recent materialization of the asset occurred earlier than the most recent materialization of the upstream asset, then it’s likely that the asset's concents are stale. Dagster raises the discrepancy with an "upstream changed" indicator:

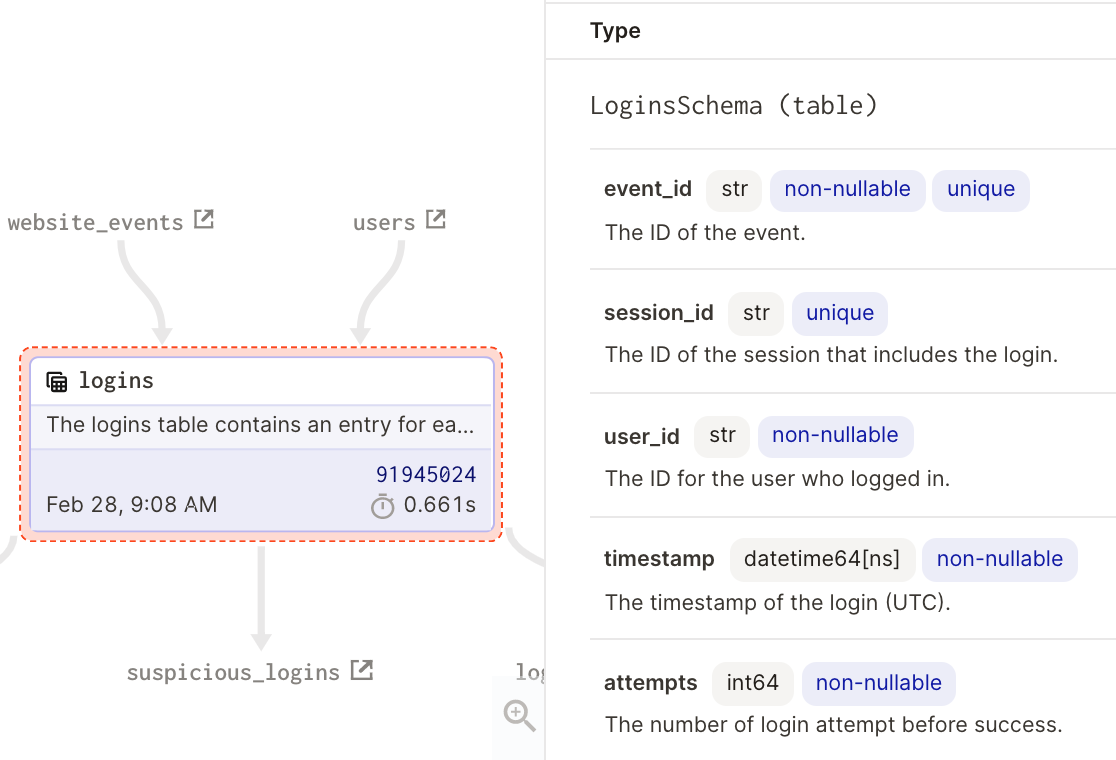
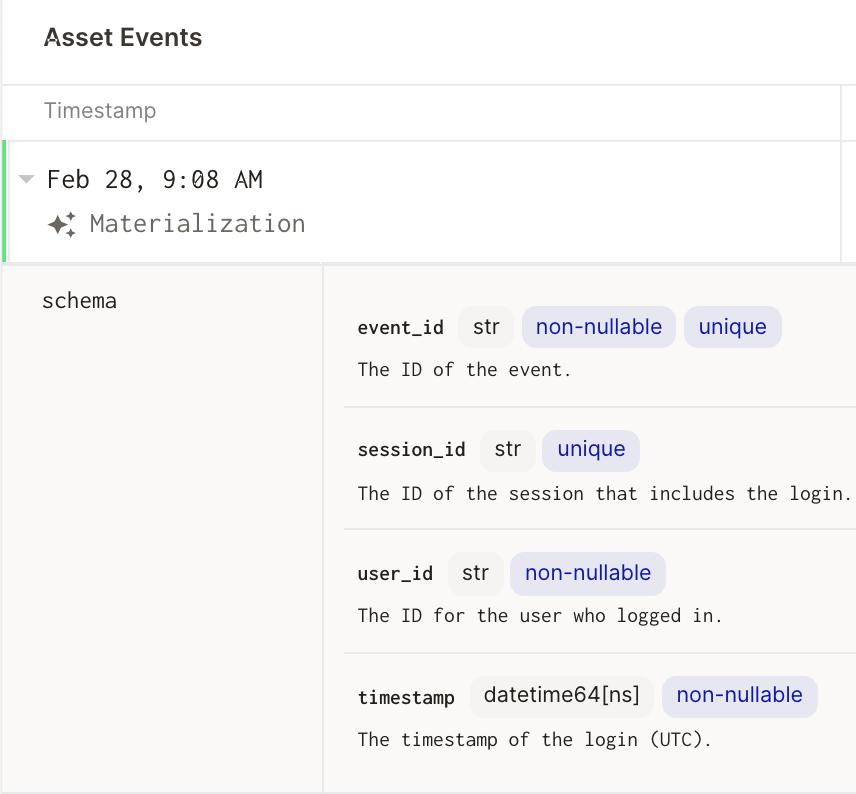
A third discrepancy is when the asset definition’s metadata doesn’t match its materialization’s metadata. Software-defined assets can contain arbitrary metadata that describe their contents, such as the set of columns and column types that the asset is expected to have. For example, imagine that you materialized an asset and then pushed a code change that includes a new column, "attempts", in the asset’s definition. Dagster helps you observe the discrepancy between the set of columns in the asset’s definition and the set of columns in the latest materialization, and thus infer that the asset is out of date.
| Definition | Latest Materialization |
|---|---|


In most situations, the action that the orchestrator should take to reconcile the asset is to launch a run to rematerialize it. However, that's not always the case. For example, in the case of a discrepancy where a materialized asset no longer has a matching definition, the right action will usually be to delete the physical asset. In the future, Dagster will be able to invoke user-supplied code that carries out this deletion.
Where we're heading: reconciliation-based scheduling
An orchestrator’s job is to kick off computations at the right time. What’s the right time? In the world of data assets, the right time typically depends on a two questions:
- Is this asset fully reconciled, as discussed in the section above? I.e. is it up-to-date?
- How out-of-date is it OK for this asset to be?
Traditional orchestrators expect users to specify when computations should run using terms that are fairly distant from those questions: "run this DAG at this interval" or "run this DAG whenever X happens". This imperative approach to orchestration often makes it awkward to express how work should be scheduled. For example, when two different teams depend on the same core asset, or when a daily-partitioned asset depends on an hourly-partitioned asset. This awkwardness often results in wasted computation and poor observability.
While an asset-based orchestrator can still support the above kinds of jobs, it offers an opportunity to instead express how work should be scheduled using the language of asset reconciliation. In coming versions of Dagster, you'll be able to provide scheduling policies that directly address those above questions: you'll be able to specify the conditions under which your asset is considered unreconciled and specify how long it's ok for your asset to remain in an unreconciled state.
At its most eager, this becomes fully "reactive" scheduling — i.e. rematerializing assets immediately after they become unreconciled. It can also accommodate a more lazy model; for example, when SLAs are more relaxed and you want to batch updates to avoid unnecessary computations.
Software-defined assets and the Modern Data Stack
The "Modern Data Stack" refers to a set of tools and practices that, in the past few years, have drastically simplified common patterns for working with data. For example:
- In the past, to build a derived table, you would write an Airflow task that issues a "CREATE TABLE" statement to your database. Nowadays, you’re more likely to define the table directly, as a dbt model.
- In the past, to ingest a table into your data warehouse from your production database, you would write an Airflow task that executes a sync. Nowadays, you’re more likely to define that table directly, using an ingest tool like Fivetran or Airbyte.
Python and other non-SQL programming languages have largely been left behind. As soon as you want to transform data with Pandas or PySpark, write a custom ingest script, or train an ML model, you’re back to writing imperative code in Airflow.
In large part due to its embrace of declarative data management, the Modern Data Stack has brought immense quality-of-life improvements to data practitioners. But these improvements come with some glaring gaps:
- Python and other non-SQL programming languages have largely been left behind. As soon as you want to transform data with Pandas or PySpark, write a custom ingest script, or train an ML model, you’re back to writing imperative code in Airflow.
- As we discussed at length in our "Rebundling the Data Platform" post, segregating ingest, SQL transformation, and ML into different purpose-build tools can mean losing sight of the asset graph that spans all of them. The lack of a shared orchestration layer results in an operationally fragile data platform that fosters a constant state of confusion about what ran, what's supposed to run, and whether things ran in the right order.
An asset-based orchestrator addresses both of these gaps by combining polyglot compute with a declarative, asset-based approach. Dagster makes Python a native citizen of the Modern Data Stack and enables asset graphs to span multiple compute systems, without reverting to a difficult, imperative paradigm.
Loading asset definitions from Modern Data Stack tools
For a video version of this section, watch:
Dagster embraces loading asset definitions from other systems. For example, the load_assets_from_dbt_project utility in the dagster-dbt library makes it simple to load each of the dbt models in a dbt project as a software-defined asset:
dbt_assets = load_assets_from_dbt_project(
project_dir="my/dbt/project/dir/",
)
Similarly, the build_airbyte_assets utility enables building assets out of Airbyte syncs:
airbyte_assets = build_airbyte_assets(
connection_id="my-airbyte-connection-id",
destination_tables=["table1", "table2"],
)
Python assets can depend on dbt (or any other) assets, and vice versa. If you have a dbt model named "daily_usage_stats", defining a Python asset that depends on it looks just like defining a Python asset that depends on another Python asset:
@asset
def predicted_usage(daily_usage_stats: DataFrame) -> DataFrame:
...
Note that similar to dbt, this asset definition only includes business logic, no code for reading or writing data to persistent storage. Dagster offers a way to share the code that performs IO across multiple asset definitions.
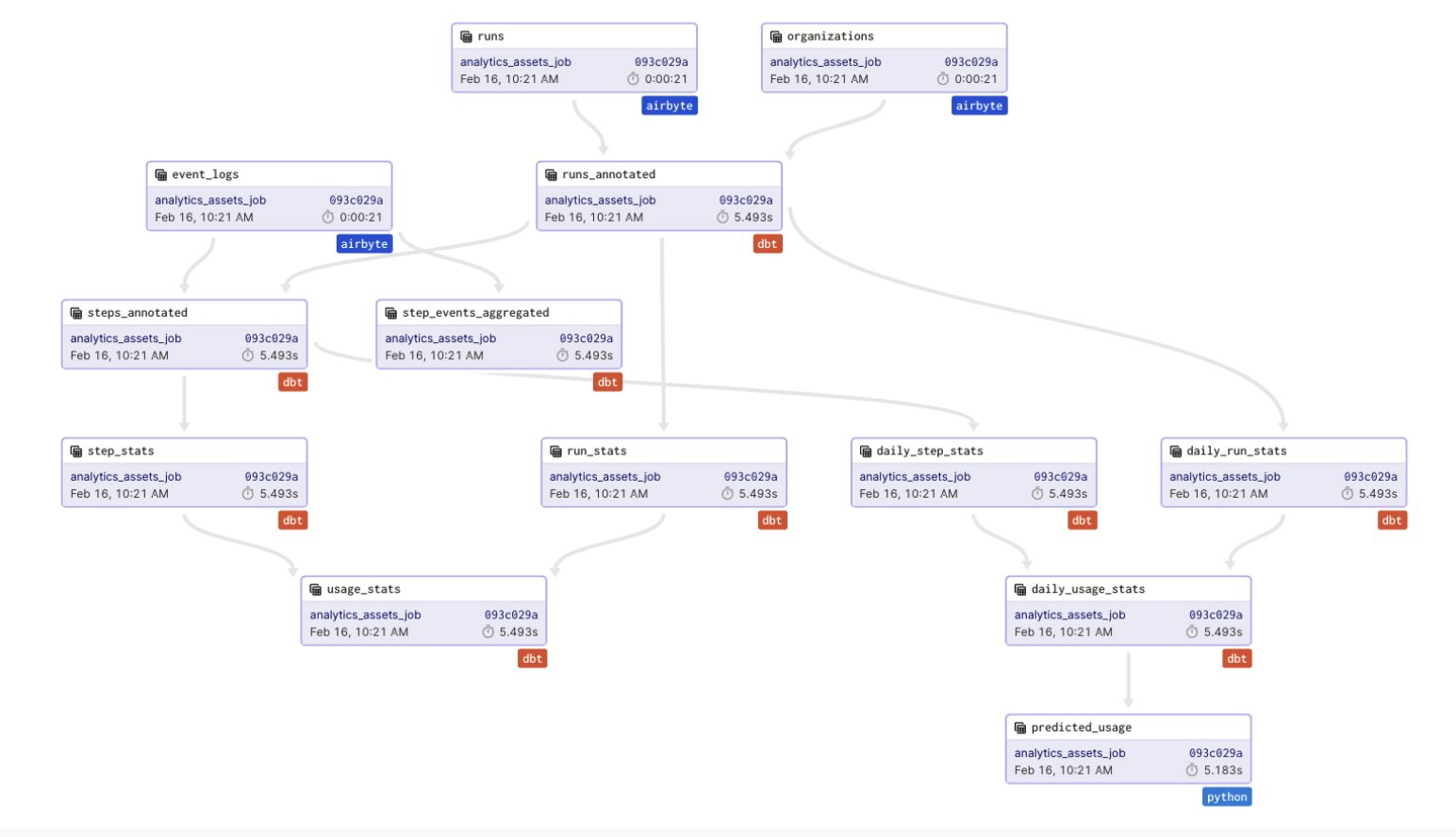
Because the op and asset layers in Dagster are distinct, this does not require that each dbt model or Airbyte sync execute as its own step. Dagster can translate a selection of assets into a single dbt or Airbyte invocation. The asset graph is rich, spanning Python, Airbyte, and dbt:

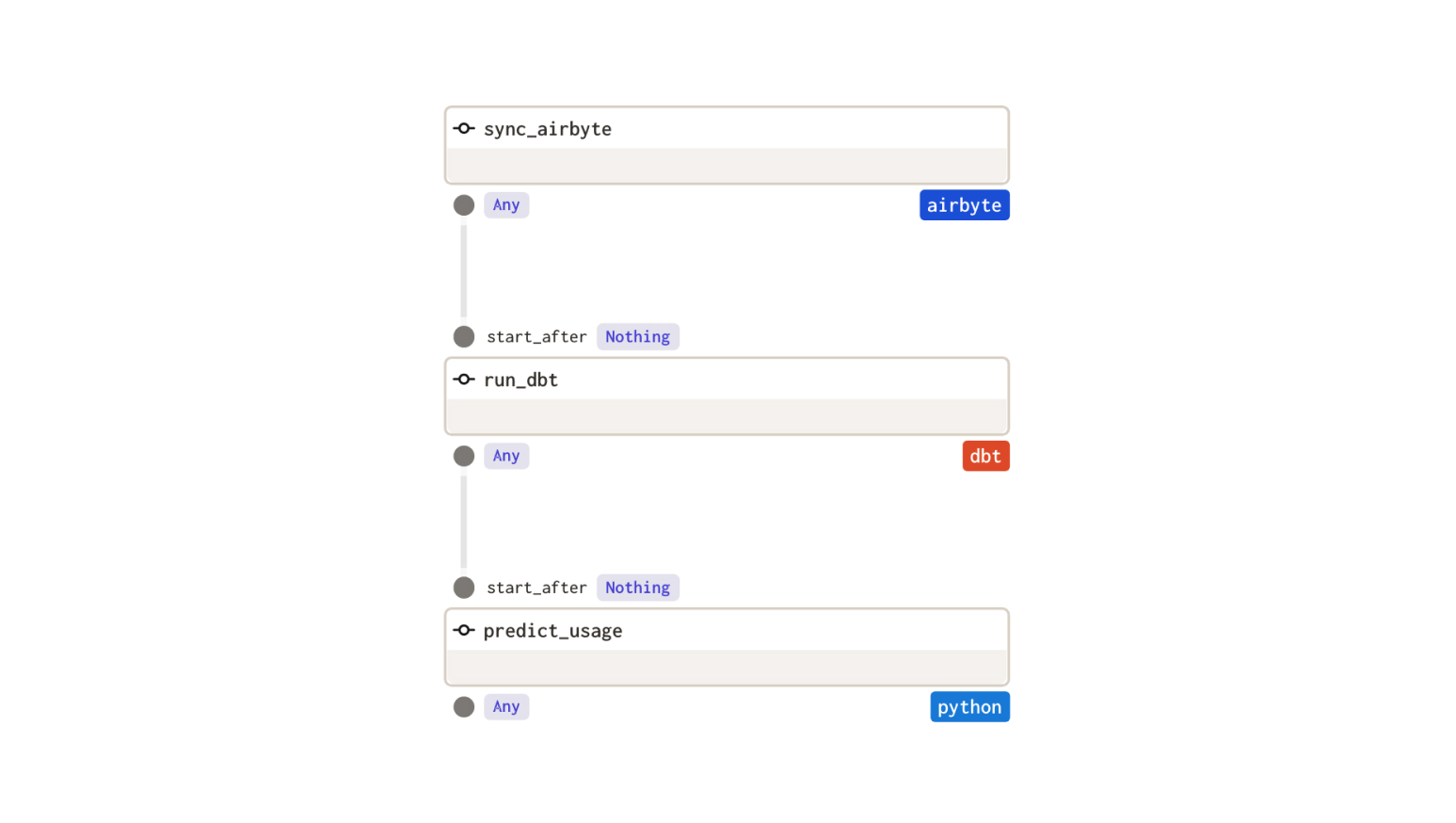
But the op graph is simple:

To boil it all down
In domains with sprawling complexity and ceaseless change, declarative approaches offer drastic benefits. Data and ML is one such domain. However, only small, siloed pockets of it have adopted these approaches and realized these benefits.
In the world of data and ML, the natural declarative unit is the software-defined asset, which combines a description of how to compute an asset with metadata about that asset, including the asset it depends on. Dagster's Python API allows you to define assets, and then Dagster's tooling makes them accessible to anyone within an organization.
A graph of software-defined assets is a powerful tool for data management, lineage, and observability: instead of describing the chaos that exists, it declares the order you want to create.
Instead of describing the chaos that exists, it declares the order you want to create.
Once you've declared this order you want to create, an asset-based orchestrator helps you materialize and maintain it — i.e. ensure that the physical assets in the data warehouse / data lake / object store match the assets that are defined in code. It does this through a process of reconciliation: noticing discrepancies between definition and materializations, and launching computations to resolve them.
The Modern Data Stack has already started to embrace declarative, asset-based principles. Because it defines dependencies and scheduling policies at the asset level instead of at the task level, an asset-based orchestrator is the ideal orchestrator for this stack. Dagster brings in heterogeneous compute and a unified control plane, without requiring practitioners to revert to tasks and imperative programming.
Don't just take our word for it
Dagster's February 2022 release, 0.14.0, includes a full-featured preview of software-defined assets.
- Check out the software-defined assets page in our docs.


We're always happy to hear your feedback, so please reach out to us! If you have any questions, ask them in the Dagster community Slack (join here!) or start a Github discussion. If you run into any bugs, let us know with a Github issue. And if you're interested in working with us, check out our open roles!
Follow us:


10 Reasons Why No-Code Solutions Almost Always Fail


- Name
- TéJaun RiChard
- Handle
- @tejaun

5 Best Practices AI Engineers Should Learn From Data Engineering
- Name
- TéJaun RiChard
- Handle
- @tejaun

The Rise of the Data Platform Engineer

- Name
- Pedram Navid
- Handle
- @pdrmnvd
