


What Are Data Management Tools?
Data management tools are software systems designed to help organizations collect, store, organize, process, and govern data throughout its lifecycle. These tools address various aspects of data operations, from integration and transformation to quality control, cataloging, and security. They enable teams to ensure data consistency, reliability, and accessibility while supporting analytics, reporting, compliance, and other business needs.
Here are the main types of data management tools and examples of popular solutions, reviewed further below:
- Data integration platforms: Dagster, Fivetran, Matillion, Airbyte
- Master data management (MDM) tools: Informatica Multidomain MDM, IBM InfoSphere Master Data Management, Semarchy xDM
- Data warehousing and data lakes: Snowflake, Google BigQuery, Databricks Lakehouse, Azure Synapse Analytics, Amazon Redshift
- Data catalog and discovery tools: Alation Data Catalog, Atlan, AWS Glue Data Catalog
- Data governance and policy platforms: Collibra Data Intelligence Cloud, OneTrust DataGovern, Precisely Data360 Govern
This is part of a series of articles about data quality
Core Functions of Data Management Tools
Data Collection and Integration
Data collection and integration tools aggregate data from various sources, such as internal systems, cloud applications, and external datasets. They enable organizations to unify data formats and protocols, resolving discrepancies and enabling data flow. By automating these processes, businesses reduce manual intervention and ensure data arrives in the required structure for downstream analytics and processing.
The effectiveness of integration depends on the ability to connect diverse endpoints, apply transformation logic, and handle errors efficiently. Modern platforms offer connectors, APIs, and automation to fetch data from databases, SaaS tools, IoT devices, and more. This enables real-time data feeds and up-to-date insights necessary for agile decision-making.
Data Storage and Warehousing
Data storage and warehousing solutions provide scalable repositories for data, supporting both operational and analytical needs. These tools allow companies to store large volumes of historical and transactional data securely, structured in a way that supports efficient querying and reporting. Typical implementations include relational databases, NoSQL stores, and modern cloud-based data warehouses.
Efficient data storage ensures that data is readily accessible and optimizes resource usage and cost. Data warehousing platforms include features like partitioning, indexing, and parallel processing, which significantly improve performance for analytical workloads. The move to the cloud has enabled organizations to leverage on-demand scaling, high availability, and managed infrastructure, reducing the burden on IT teams.
Data Processing and Transformation
Data processing and transformation tools are essential for cleaning, structuring, and enriching raw datasets into usable formats for analytics or operations. These tools handle tasks such as filtering, aggregating, joining, and normalizing data from multiple sources. By automating transformation pipelines, organizations can standardize incoming data, address inconsistencies, and produce consistent outputs for business intelligence or machine learning applications.
Transformation also includes enrichments like geocoding, sentiment scoring, and formatting exchanges that support different business functions. Processing engines work at significant scale, often integrating with tools for orchestration and parallelization, allowing for the rapid completion of complex data workflows. This speeds up the delivery of meaningful, actionable information to stakeholders across the enterprise.
Data Governance and Quality Control
Data governance and quality control are focused on establishing policies, roles, responsibilities, and processes to ensure data meets organizational standards. Tools in this domain help implement frameworks for data stewardship, lineage tracking, and compliance measures. Governance solutions assign ownership, enforce business rules, and document decisions to promote accountability and transparency across teams.
Quality control features include profiling, validation, deduplication, and error correction functions that protect the integrity of company data assets. Automation of these checks allows businesses to quickly surface anomalies, address root causes, and maintain trust in their reporting and analytics.
Metadata and Catalog Management
Metadata and catalog management tools track and organize information about an organization’s data assets, including source, lineage, structure, and usage details. A centralized metadata catalog provides a searchable inventory that boosts data discoverability and reuse. These solutions enable collaboration among analysts and engineers by making it easier to find, assess, and understand datasets.
Automated metadata harvesting and lineage tracking help organizations comply with data privacy regulations and audit requirements. Catalog platforms enable impact analysis, help reduce data duplication, and empower data stewards to manage and curate datasets efficiently. With clear metadata documentation, enterprises improve data literacy and maximize return on their data investments.
Data Security and Compliance
Data security and compliance tools protect sensitive information, control access, and ensure regulatory adherence. These tools manage authentication, encryption, masking, and activity monitoring in line with laws such as GDPR, HIPAA, and CCPA. They enable organizations to define access policies, track usage, and respond to incidents quickly, reducing the risk of data breaches and non-compliance penalties.
Platforms often offer detailed audit logs, automated alerts, and reporting functions to support compliance audits and internal reviews. Security features extend to both data in motion and at rest, ensuring that protections are consistently applied throughout the lifecycle. Security and compliance tooling are essential elements of any modern data management strategy.
Key Categories of Data Management Tools
Data Integration and ETL Platforms
Data integration and ETL (Extract, Transform, Load) platforms enable the collection, blending, and movement of data across various sources and destinations. These systems automate the process of extracting data from disparate repositories, transforming it for consistency and quality, and loading it into data warehouses or lakes.
Modern ETL platforms often incorporate real-time streaming and batch processing, along with connectors for databases, cloud services, and APIs. With built-in error handling, logging, and scheduling, they reduce manual maintenance and improve data reliability. These platforms are essential for organizations pursuing scalable, automated, and solid data architectures.
Master Data Management (MDM)
Master data management (MDM) tools centralize and harmonize critical business information, such as customer, product, or supplier data, across systems. These solutions create a single, authoritative version of the truth (the "golden record"), which improves accuracy and consistency across business processes. By eliminating redundancies and resolving conflicts, MDM systems support reliable decision-making and consistent reporting.
An MDM platform typically supports data stewardship, governance, and workflow automation to manage updates, syndication, and data quality rules. Linking records across applications prevents fragmentation, while advanced matching and merging algorithms help maintain accurate master records.
Data Warehousing and Data Lakes
Data warehousing solutions store structured data in a format optimized for query performance and business intelligence. Data lakes, on the other hand, ingest raw, semi-structured, or unstructured data at scale, retaining its native format for flexibility. Both environments are often connected, enabling organizations to separate storage from compute and access data for different use cases.
Cloud-native data platforms make it easier to deploy, scale, and secure warehouses or lakes without heavy infrastructure investments. They support features such as automatic scaling, multi-tenancy, and integration with analytics engines. Using both data warehouses and lakes enables organizations to address a wide spectrum of data needs, from real-time analytics to archival storage.
Data Catalog and Discovery Tools
Data catalog and discovery tools help organizations inventory, describe, and locate their data assets. These tools provide search, tagging, and lineage tracking to make datasets more transparent and accessible. By indexing data across warehouses, lakes, and business applications, catalog tools simplify self-service data discovery for analysts, data scientists, and business users.
Advanced catalogs offer collaborative features such as metadata enrichment, usage analytics, and rating systems. They improve data governance by documenting data ownership, usage patterns, and compliance status. Effective cataloging reduces data duplication, enforces standards, and ensures that teams spend less time searching for data and more time using it.
Data Governance and Policy Platforms
Data governance and policy platforms centralize the administration of data policies, standards, and compliance activities. These tools support the definition, enforcement, and auditing of data-related rules and responsibilities across organizational units. Key features include data stewardship workflows, policy distribution, and regulatory tracking.
Automated rule engines, workflow management, and reporting modules help ensure that governance policies are consistently applied. Policy platforms often integrate with other data management solutions for holistic oversight, supporting efforts to comply with privacy laws and internal data standards.
Notable Data Management Tools
Data Integration Platforms
1. Dagster
.png)
Dagster is an open-source data orchestration platform designed to help teams build, test, and operate reliable data pipelines. Rather than focusing solely on data movement, Dagster emphasizes pipeline correctness, observability, and maintainability across the entire data lifecycle. It is commonly used to orchestrate ETL/ELT jobs, machine learning workflows, and analytics pipelines that span multiple tools and systems.
Key features of Dagster:
- Software-defined assets: Treats datasets as first-class objects, making dependencies, freshness, and lineage explicit
- Strong typing and validation: Built-in checks ensure data quality and correctness at each pipeline step
- Powerful orchestration engine: Coordinates batch, event-driven, and scheduled workflows across diverse systems
- Observability and debugging: Rich UI for monitoring runs, inspecting metadata, and diagnosing failures
- Flexible deployment options: Supports local development, containerized environments, and cloud-native deployments via Dagster Cloud
Extensive integrations: Works seamlessly with tools like dbt, Snowflake, BigQuery, Spark, Kubernetes, and more
%20(1).webp)
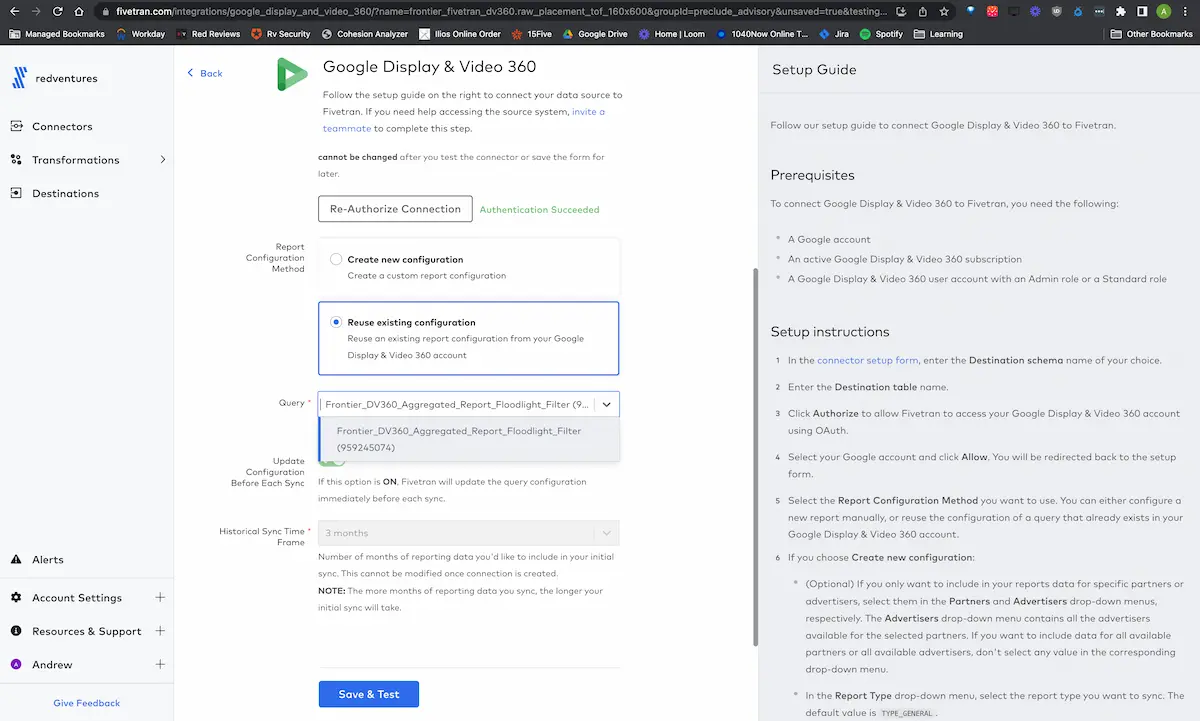
2. Fivetran
Fivetran is a managed data integration platform that automates the movement of data from a wide range of sources to cloud destinations. It supports over 700 connectors, allowing organizations to ingest data from SaaS applications, databases, ERPs, and files without building or maintaining pipelines manually.
Key features include:
- Connector library: Supports over 700 pre-built connectors for applications, databases, file systems, and more
- Automated schema handling: Detects and manages schema changes with minimal disruption to pipelines
- Flexible deployment options: Enables deployment in cloud, on-premise, or hybrid environments
- Built-in transformations: Prepares data for analytics using configurable, in-warehouse transformation models
Security and compliance: Adheres to standards like SOC 2, HIPAA, GDPR, and PCI DSS, with enterprise-grade controls
3. Matillion
Matillion is a cloud-native ETL/ELT platform that simplifies the process of extracting, transforming, and loading data into modern cloud data warehouses. It offers a visual development environment with low-code tools, making it accessible for data teams to build, schedule, and monitor data pipelines. Matillion integrates tightly with cloud services and supports real-time and batch data workflows.
Key features include:
- Pre-built connectors for cloud apps, databases, and file systems
- Visual pipeline builder with low-code interface
- Cloud-native architecture optimized for Snowflake, BigQuery, Redshift, and others
- ELT support with SQL pushdown for efficient processing
- Job scheduling, logging, and orchestration capabilities
.webp)
4. Airbyte

Airbyte is an open-source data integration platform focused on ELT processes. It enables users to move data from hundreds of sources to data warehouses or lakes with minimal setup. Airbyte emphasizes connector extensibility, allowing users to build custom connectors. With flexible deployment options, it supports open-source and enterprise-grade use cases.
Key features include:
- Over 600 pre-built connectors for sources and destinations
- Open-source core with active community support
- Cloud, on-premise, and hybrid deployment models
- Support for real-time and batch data ingestion
- Custom connector development with minimal code
.webp)
Master Data Management (MDM)
5. Informatica Multidomain MDM
.webp)
Informatica Multidomain MDM provides a unified platform to manage master data across domains such as customers, products, and suppliers. It helps organizations maintain accurate, consistent, and complete master records through matching, merging, and governance workflows. Its cloud-native design and AI automation improve productivity and ensure data quality at scale.
Key features include:
- Multi-domain master data support
- Matching, merging, and conflict resolution to create golden records
- Cloud-native architecture with microservices support
- Integrated data quality, validation, and enrichment tools
- AI-driven automation for stewardship and onboarding
6. IBM InfoSphere Master Data Management

IBM InfoSphere MDM is an enterprise-grade solution for managing master data across critical domains. It provides real-time access to trusted data and supports operational and analytical needs through matching, stewardship, and governance features. The platform is suitable for hybrid deployments and integrates with existing enterprise systems.
Key features include:
- Centralized master data for customer, product, account, and more
- Advanced matching and consolidation algorithms
- Stewardship dashboards, alerts, and audit logs
- Support for cloud, on-premise, and hybrid environments
- Integration with enterprise applications and services
7. Semarchy xDM
Semarchy xDM is a unified platform for master data, reference data, and application data management. It offers an agile, model-driven approach that allows rapid development and deployment of data hubs. With built-in data quality, governance, and accessible interfaces, Semarchy xDM supports IT and business users in managing data assets.
Key features include:
- Multi-domain MDM, RDM, and ADM in a single platform
- Built-in data quality tools: matching, deduplication, validation
- Visual application builder for fast deployment
- Role-based security and granular access control
- Agile data modeling and quick configuration
Data Warehousing and Data Lakes
8. Snowflake
Snowflake is a fully managed cloud data warehousing platform built for high performance, scalability, and simplicity. It separates compute and storage so users can scale resources independently, and supports structured and semi-structured data for analytics across large volumes.
Key features include:
- Independent scaling of compute and storage for flexibility
- Support for structured, semi-structured (e.g., JSON, Parquet) and variant data types
- Zero-management infrastructure (no servers to provision)
- Multi-cluster concurrency to avoid resource contention
- Shared data marketplace and data-sharing capabilities across accounts
9. Google BigQuery

Google BigQuery is a serverless, fully managed enterprise data warehouse that runs at petabyte scale, enabling organizations to analyze massive datasets without having to manage infrastructure. The platform integrates with machine-learning and BI tools, supports streaming and batch ingestion, and offers flexible pricing models.
Key features include:
- Serverless architecture with no infrastructure to manage
- Scalable to petabyte-level datasets and high query concurrency
- Support for both batch and streaming ingestion
- Native integration with Google Cloud AI/ML services and geospatial analytics
- Flexible pricing (on-demand or flat-rate)
10. Databricks Lakehouse Platform
The Databricks Lakehouse Platform combines the best of data lakes and data warehouses into a unified architecture, enabling storage, processing, analytics and machine-learning workloads on one platform. It provides an open, scalable environment that removes silos and supports modern data-driven workflows.
Key features include:
- Unified lakehouse architecture supporting raw data, analytics and AI workflows
- Open standards and broad ecosystem compatibility
- Single platform for ETL/ELT, streaming, BI, data science and ML
- Central governance with unified metadata, access controls and cataloging
- Scalability and flexibility to handle both structured and unstructured data
11. Azure Synapse Analytics
.webp)
Azure Synapse Analytics is an analytics service that brings together big data and data warehousing in a unified environment. It enables organizations to analyze data from operational stores, data lakes, and enterprise warehouses using a common workspace.
Key features include:
- Unified analytics workspace: Combines data integration, warehousing, and big data analytics in one environment
- Support for multiple data sources: Access and analyze data across data lakes, operational stores, and warehouse systems
- Integrated security and compliance: Built-in protections aligned with over 100 global compliance standards
- Flexible pricing model: Consumption-based pricing supports cost optimization and scalability
Migration readiness: Tools and documentation for migrating to Microsoft Fabric from dedicated Synapse pools
.avif)
12. Amazon Redshift
.webp)
Amazon Redshift is a cloud-based data warehouse to deliver SQL-based analytics across data lakes and structured data stores. With support for serverless deployment and zero-ETL integrations, it enables near real-time insights without managing infrastructure.
Key features include:
- Serverless and provisioned deployment: Choose between managed infrastructure or serverless execution for flexible scaling
- Zero-ETL integrations: Ingests data from sources like streaming platforms and operational databases in near real-time
- Lakehouse compatibility: Unified analytics across Redshift warehouses, Amazon S3, and federated sources
- SQL-based machine learning: Native integration with Amazon SageMaker and support for AI/ML workflows
Optimized price-performance: High throughput and cost efficiency for enterprise-scale analytics
Data Catalog and Discovery Tools
13. Alation Data Catalog
Alation Data Catalog is a metadata management and data-discovery tool that helps organizations find, understand, and govern their data assets. It provides searchable metadata, collaborative documentation, lineage tracking, and connectors to many data sources.
Key features include:
- Centralized searchable catalog of data assets across warehouses, lakes, BI tools
- Metadata harvesting, tagging and enrichment to improve discoverability
- Usage analytics, lineage and overview of who’s using what data and how
- Collaboration features (annotations, comments) for data stewards and analysts
- Integration with a range of data sources via open connector framework
.webp)
14. Atlan
.webp)
Atlan is a metadata management and data collaboration platform that unifies discovery, governance, and automation across modern data stacks. It provides a metadata layer that integrates with various tools and systems, enabling users to explore column-level lineage, define data products, and apply governance policies in context.
Key features include:
- Active metadata platform: Captures and activates metadata across the data stack for discovery and governance
- Column-level lineage and automation: Tracks data flow and automates workflows for consistency and control
- No-code connectors: Integrates with tools like Snowflake, Databricks, dbt, Tableau, and more
- Collaboration and data products: Enables teams to define and manage data products and governance policies together
AI readiness and context-aware interfaces: Supports AI agents and semantic layers to bring business context into analytics
.webp)
15. AWS Glue Data Catalog
.webp)
AWS Glue Data Catalog is a managed metadata repository service within the AWS ecosystem. It stores table definitions, schemas, partitions and other control information, enabling users to discover and query data assets, manage schema evolution, and support ETL workflows.
Key features include:
- Automatic schema discovery via crawlers for varied data sources
- Central metadata repository for varied AWS services (S3, Redshift, Athena, EMR)
- Schema versioning, tracking, and evolution over time
- Integration with ETL jobs managing data preparation and transformation
- Metadata accessible for lineage, governance and performance optimization
Data Governance and Policy Platforms
16. Collibra Data Intelligence Cloud
.webp)
Collibra Data Intelligence Cloud is a unified platform for data governance, quality, cataloging, and lineage. It helps organizations build trust in their data by providing consistent governance frameworks, policy enforcement, and data stewardship workflows. The platform enables business and technical users to collaborate on data definitions, compliance, and data lifecycle management across distributed environments.
Key features include:
- Centralized data catalog, governance, and lineage in one platform
- Pre-built workflows for stewardship, policy approvals, and issue resolution
- Business glossary and metadata management for shared understanding
- Role-based access and data usage tracking for compliance
- Cloud-native architecture with scalable microservices design
17. OneTrust DataGovern
OneTrust DataGovern focuses on data governance and privacy management by enabling organizations to classify, control, and monitor their data usage. It automates the enforcement of policies and integrates with consent and privacy frameworks, helping ensure regulatory compliance. With visibility into data flows and access rights, it supports ethical and secure data practices.
Key features include:
- Automated data classification aligned to business and compliance frameworks
- Policy management and enforcement for data usage and sharing
- Integration with consent and privacy tools for regulatory alignment
- Data lifecycle tracking from ingestion to deletion
- Dashboards for data discovery, access control, and usage analytics
18. Precisely Data360 Govern
Precisely Data360 Govern is a governance solution for managing metadata, data lineage, and business context across enterprise data assets. It supports collaboration between data stewards and business users through visual workflows, impact analysis, and issue tracking. The platform improves data trust by linking technical metadata to business meaning.
Key features include:
- Metadata harvesting and automated cataloging
- Business glossary and definitions tied to data assets
- Lineage visualizations and impact analysis for audit readiness
- Governance workflows for issue resolution and stewardship
- Data quality scoring and annotation tools
Conclusion
Effective data management tools are essential for ensuring data integrity, usability, and security across the enterprise. As organizations face increasing data volume, variety, and velocity, these tools provide the infrastructure to collect, process, store, govern, and protect information at scale. By investing in the right mix of data management capabilities, businesses can improve operational efficiency, support informed decision-making, meet compliance requirements, and unlock the full value of their data assets.






.jpg)
.png)



.png)

