





Leverage the power of LLMs while keeping the costs in check using the Dagster OpenAI integration.
Hi. Now that LLMs are becoming more mature and accessible, many organizations are looking to integrate them into common business practices such as technical support bots, online real-time help, and other knowledge-base-related tasks.
While the premise of LLMs is remarkable, and the use cases are many, the cost of operating such processes is also becoming apparent.
In the following piece, we share an approach to leveraging the power of LLMs while keeping the costs in check, by building an AI pipeline on top of Dagster’s new OpenAI integration.
We hope this tutorial will inspire you to build novel AI-powered processes without breaking the bank.
Just over a year ago, we shared our initial steps in creating a support bot, utilizing Dagster, GPT-3, and LangChain. Today, as Large Language Models (LLMs) are emerging and evolving a lot more, we’re entering the next chapter in our adventure, incorporating the latest updates from GPT-4 and Dagster, particularly the new dagster-openai integration.
If you'd prefer to follow along with the project, you can do so via our GitHub repo here.
Recap of Initial Setup
Our journey began with leveraging Dagster to streamline the fetching and indexing of GitHub documentation, thereby enabling our support bot to respond to user queries with precision.
Prerequisites
This is not a beginner’s tutorial and we will assume you are familiar with Python, working with command line, and have a basic familiarity with Dagster.
To run, you need:
- Python 3 installed locally
- An OpenAI api key
- a number of Python dependencies that can be installed as follows:
Our initial setup started with extracting raw documents from GitHub repositories:
@asset
def source_docs():
return list(get_github_docs("dagster-io", "dagster"))Then, chunk these documents and their embeddings into a Faiss index:
Finally, we used a vector space search engine with LangChain to improve the support bot’s efficiency:
This infrastructure laid the groundwork for a robust Q&A mechanism. It leverages the power of OpenAI's models to interpret user questions based on our documentation, alongside crafting cost-effective prompts with LangChain.
New Challenges with AI Pipelines
With the growth of our system and the introduction of new models and AI capabilities, gaining a deeper understanding of our pipelines became crucial, especially in terms of optimizing our use of OpenAI services. We aimed to develop more cost-effective strategies, with a focus on:
- Enhanced Visibility into OpenAI Usage: Understanding the cost implications of running our support bot and other AI-driven features was our primary concern. The task of monitoring usage across different models and APIs, while developing complex AI pipelines, highlighted the need for a more efficient tracking system. We sought a solution that would allow us to manage our OpenAI interactions with greater ease and precision.
- Cost Control: As we leveraged LLM for more complex tasks such as generating completions and embeddings, concerns about escalating costs arose. A mechanism to effectively control and predict costs became essential.
So, we want a straightforward way to compare OpenAI models based on the actual data, enabling us to make informed decisions that optimize both performance and cost-efficiency.
Introducing the dagster-openai Integration
In our journey to refine AI pipelines, we're excited to share that we've made our work with OpenAI APIs available to the broader community through an open-source dagster-openai integration. Paired with Dagster's software-defined assets, this integration not only facilitates seamless interactions with OpenAI APIs but also enhances transparency by automatically logging OpenAI usage metadata within asset metadata. For detailed insights, explore our guide on leveraging Dagster with OpenAI.
This integration's standout feature is its capacity to amplify visibility into OpenAI API utilization through Dagster Insights. By systematically logging usage metadata, we're now equipped to conduct a more granular analysis of our OpenAI model engagement. This not only aids in cost optimization but also empowers us to make more data-informed decisions when evaluating and comparing models.
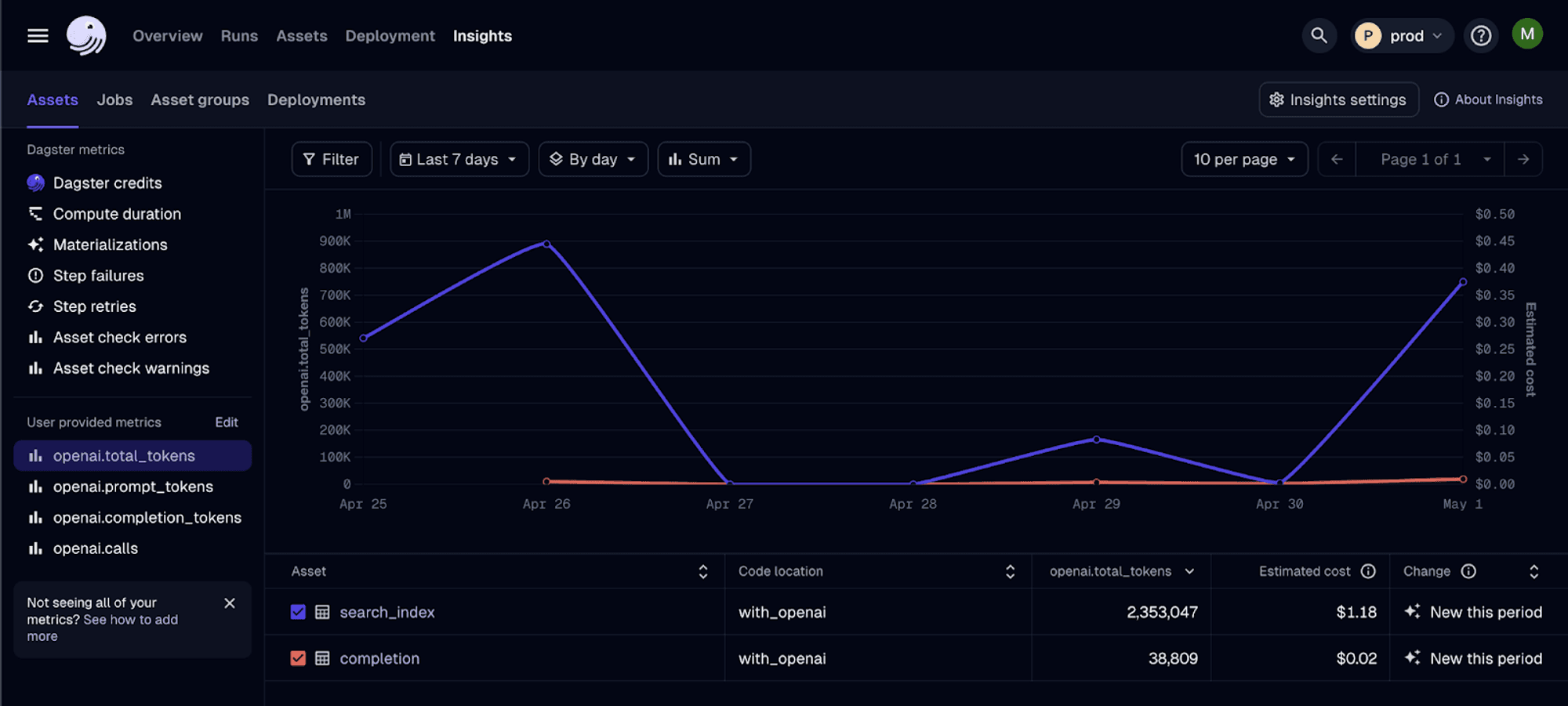
The integration also introduces a method named with_usage_metadata designed for logging usage data from any OpenAI endpoint. We'll dive into the specifics shortly.
Refining Our Approach with the New Integration
Refining our approach with the new integration allowed us to enhance our project's performance and cost-efficiency significantly:
- Visibility and Control: Leveraging the integration, we monitored our OpenAI usage within the Dagster ecosystem, gaining detailed insights and alerting into our operational practices.
- Efficient Performance Comparison: By utilizing the logged metadata, we efficiently compared model performances, which facilitated our decision-making process.
Let’s update what we originally have! As mentioned above in the initial setup, we’ve got:
With the new integration, it only needed a few lines of code changes:
Instead of directly calling the API, we would use the client from our OpenAI resource, which automatically records API usage data into our asset catalog.
In addition, we labeled “compute kind” more descriptively. This small yet impactful tag improves the readability of our asset graph and makes it easier to understand the context of our computations involved in each asset at a glance:
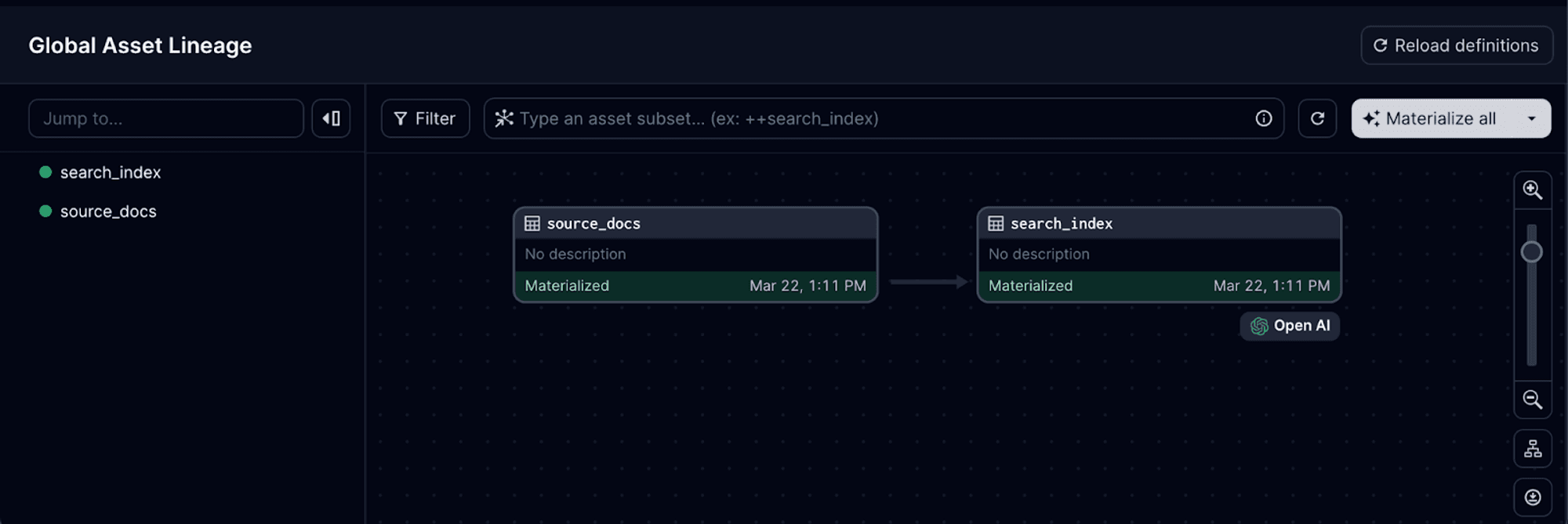
Now let’s run this asset.
We get instant metadata added to asset materialization:
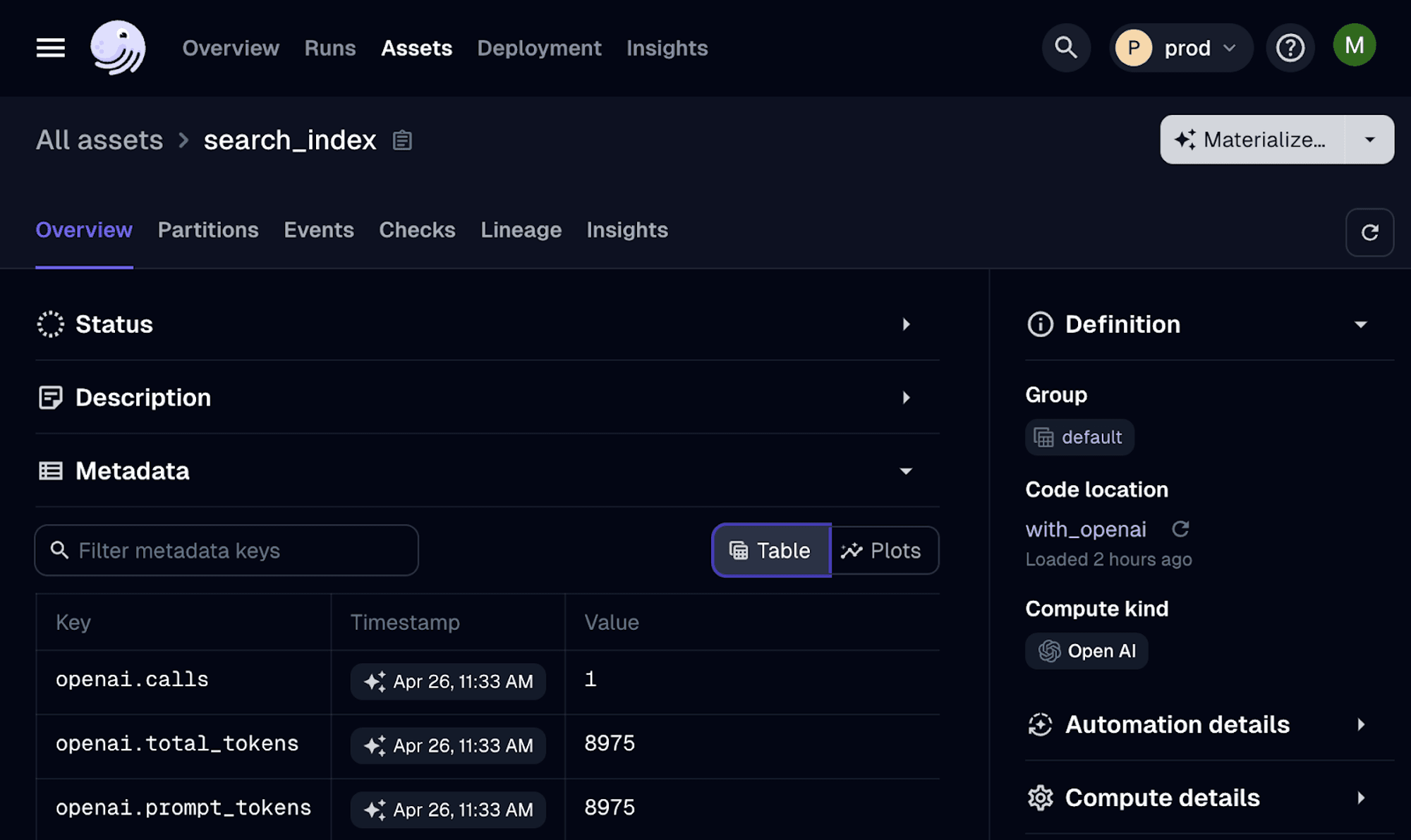
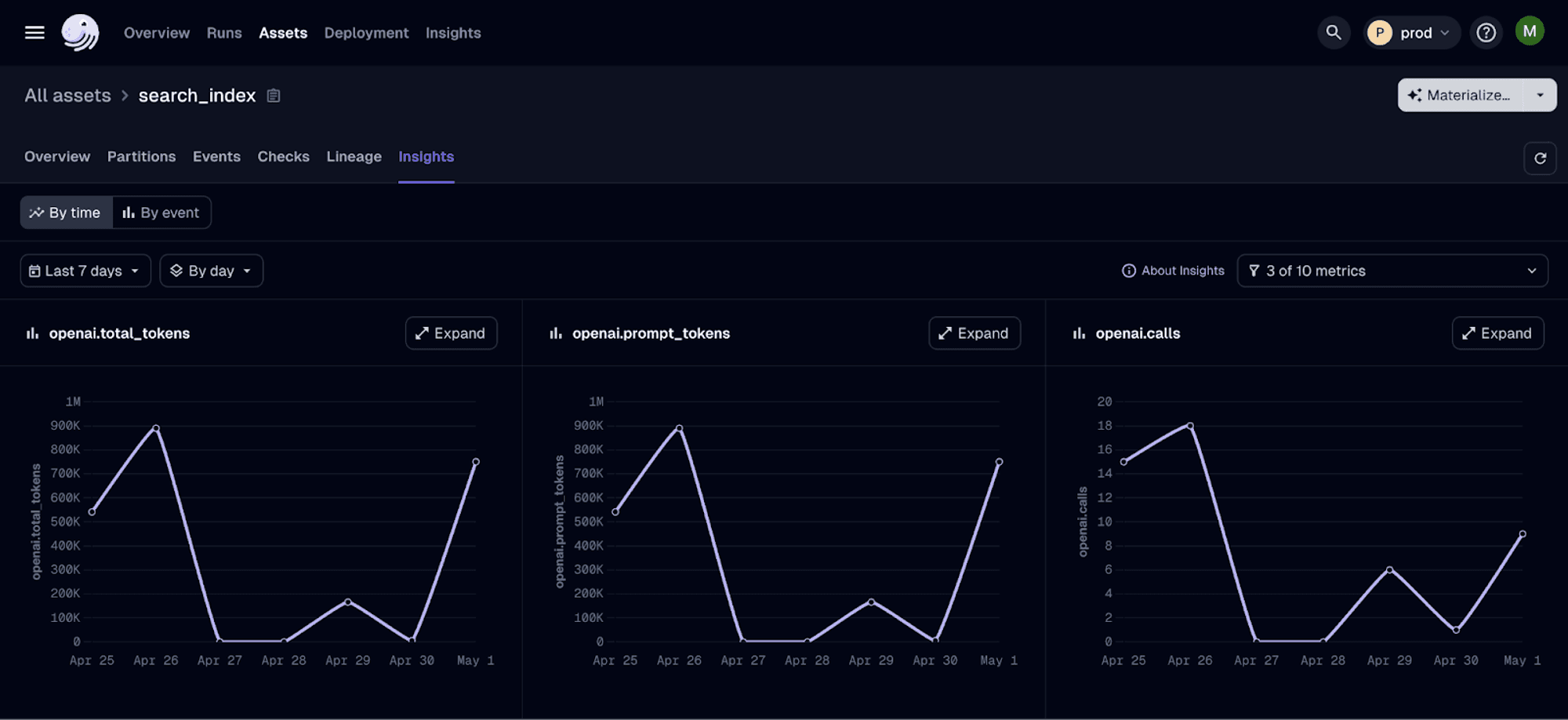
And… even better, when running this pipeline with Dagster+, we get nice aggregated charts:
Then, moving onto print_answer. First, let’s update our print answer function to a completion asset, using OpenAIResource, together with LangChain:
Now, you can see all the steps show up in the asset graph:
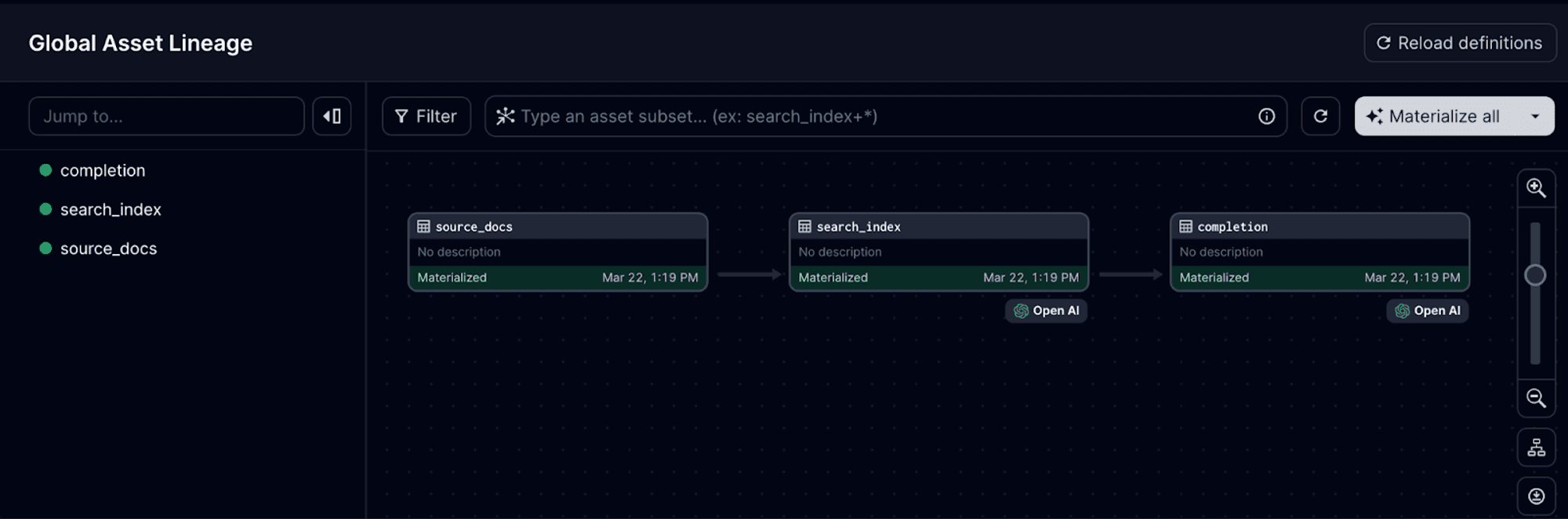
With just a few code modifications, we've enabled a pipeline that automatically logs usage to our asset metadata. This establishes a solid foundation for tracking and optimizing our support bot’s cost and performance over time.
Let’s try with the simple question “What is Dagster?”:
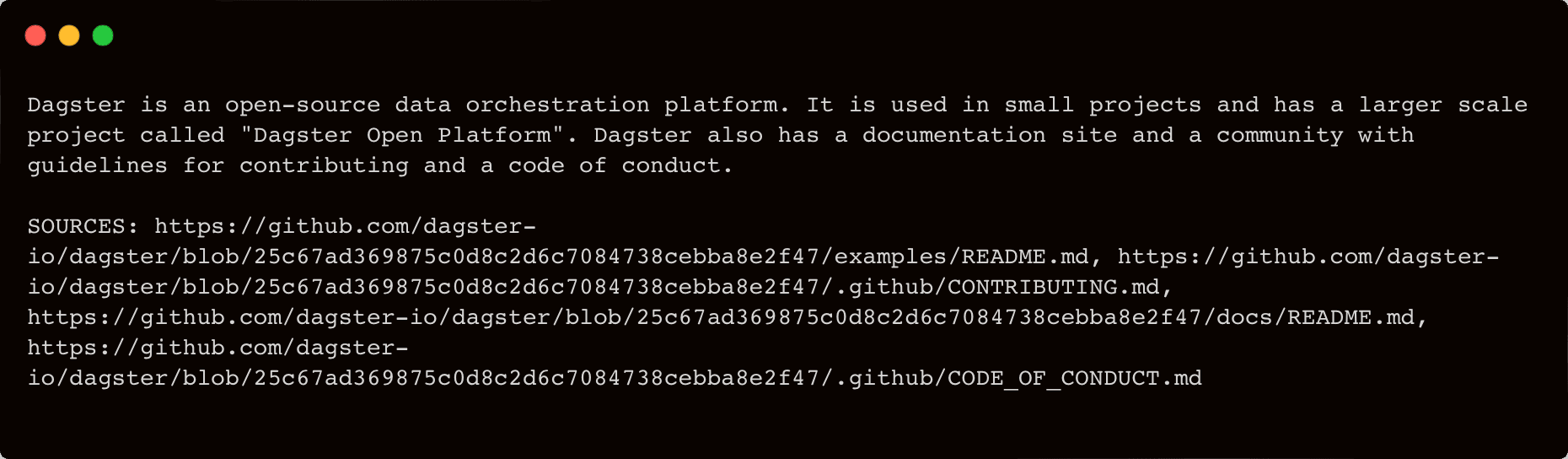
It’s working just as before but with more insights into the usage.
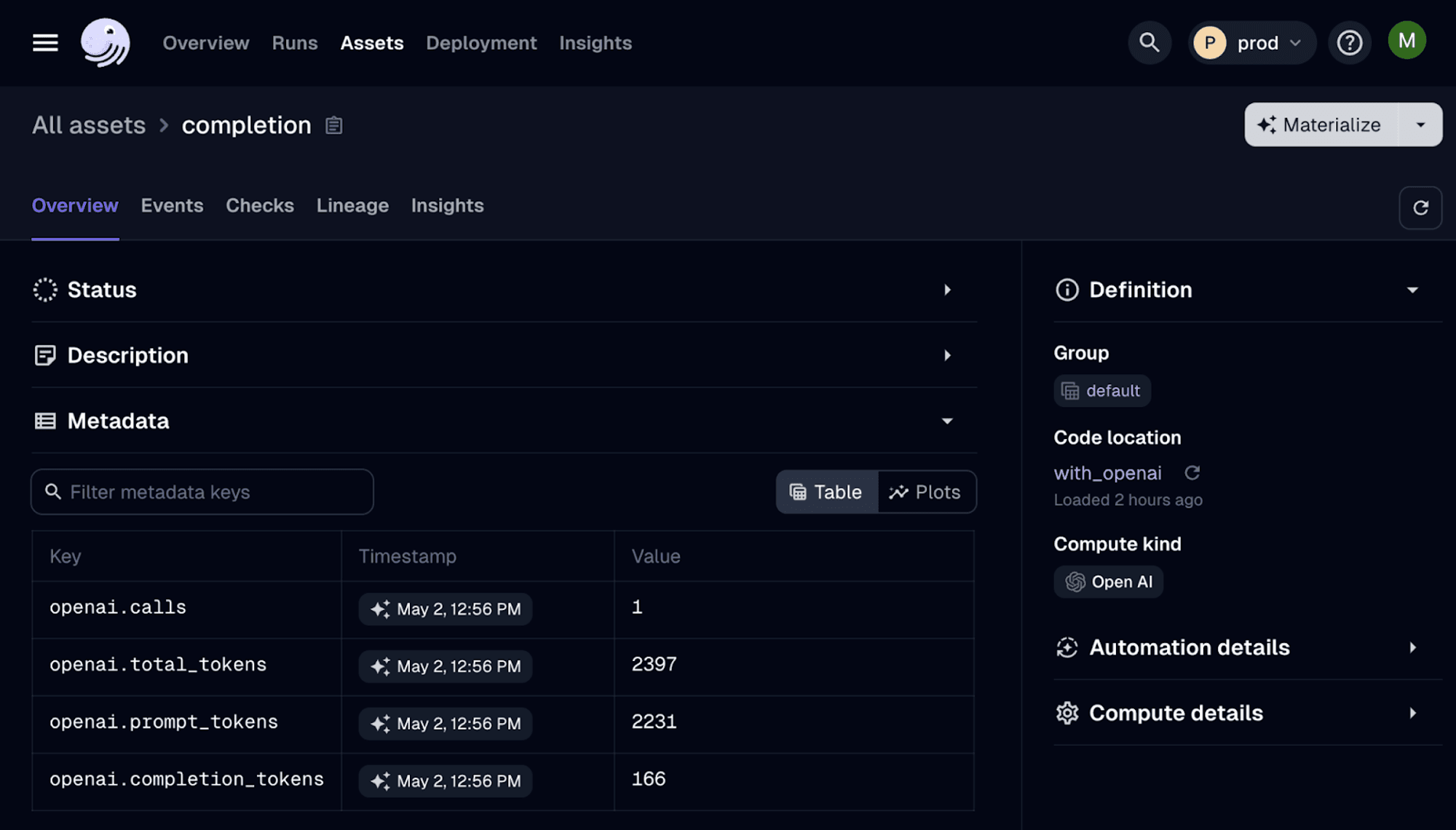
Now, onto the fun parts.
Addressing Complex Queries with Enhanced Documentation
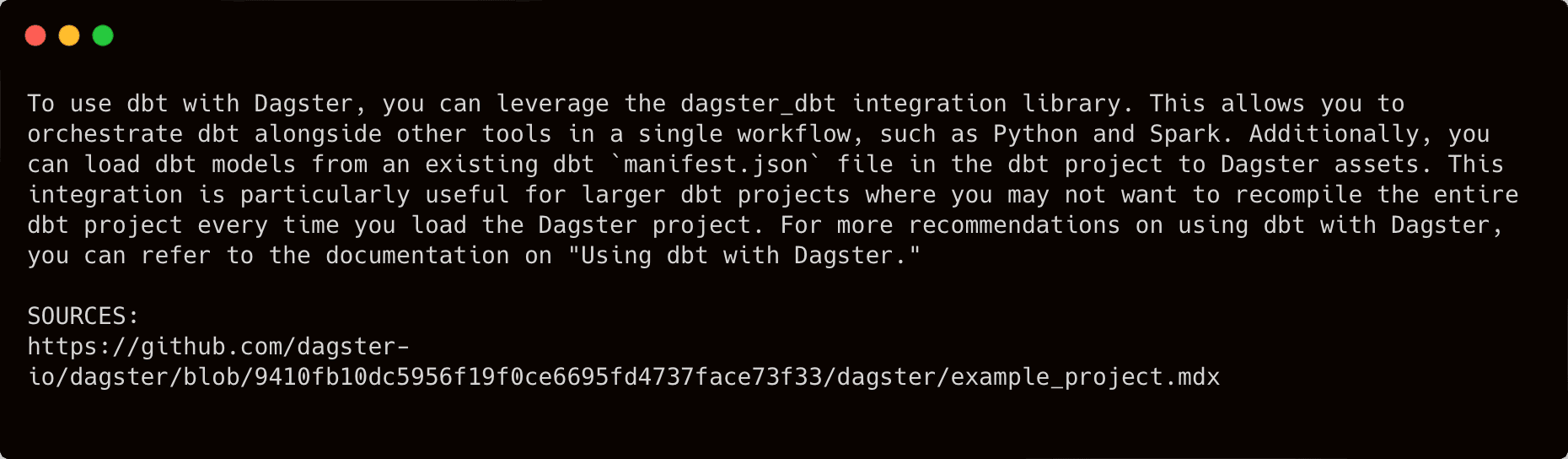
Currently, our naive support bot gives a pretty generic answer when for a specific question like “How can I use dbt with Dagster?”:

To enhance responses to complex queries like that, we can incorporate a wider range of documentation. For example, for specific topics such as the dagster-dbt integration, we could look up the relevant guides, API docs, and GitHub discussions.
To do so, we need to modify our code to fetch documents from various sources.
Then, we can update the asset to fetch the source docs:
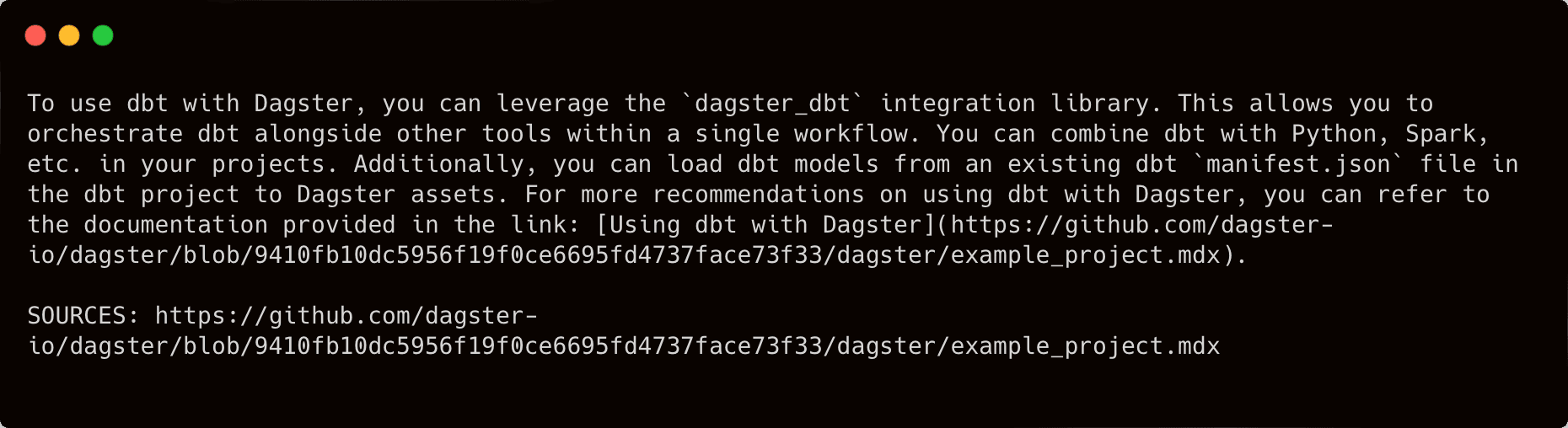
Now, let’s try it again with “How can I use dbt with Dagster?”:
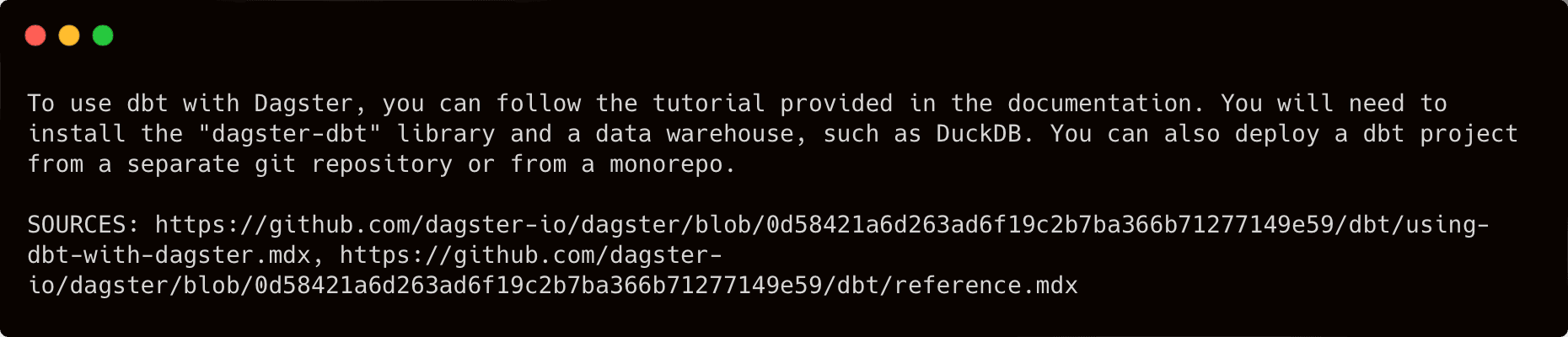
OK, this response is now looking much more relevant than before.
Optimizing Performance and Costs
However, as we expand our sources for the pipeline, cost could become concerning.
The good news is that we get all the usage data automatically logged in our pipeline. Let’s take a quick look:

Ok, the cost is growing a bit. Let’s dive in!
Seeing a cost increase prompts us to optimize. We’re certain that some documentation segments are updated less frequently than others, so we can update the embeddings and indexes only as needed for different document sections.
Dagster's native partitioning feature enables us to organize source docs by category efficiently. Here’s how we can adjust our setup:
We start by defining a StaticPartitionsDefinition. Let’s assign each documentation category as a separate partition:
Then, we partition our assets:
@asset(compute_kind="GitHub", partitions_def=docs_partitions_def)
def source_docs(context: AssetExecutionContext):
return list(get_github_docs("dagster-io", "dagster", context.partition_key))
@asset(compute_kind="OpenAI", partitions_def=docs_partitions_def)
def search_index(context: AssetExecutionContext, openai: OpenAIResource, source_docs):
source_chunks = []
splitter = CharacterTextSplitter(separator=" ", chunk_size=1024, chunk_overlap=0)
for source in source_docs:
context.log.info(source)
for chunk in splitter.split_text(source.page_content):
source_chunks.append(Document(page_content=chunk, metadata=source.metadata))
with openai.get_client(context) as client:
search_index = FAISS.from_documents(
source_chunks, OpenAIEmbeddings(client=client.embeddings)
)
return search_index.serialize_to_bytes()Although our completion asset is not partitioned, it depends on the newly partitioned search_index asset. Using a partition mapping will allow the completion asset to depend on all partitions of search_index:
Now, we can see in our asset graph that our source_docs and search_index assets have 2 partitions each:
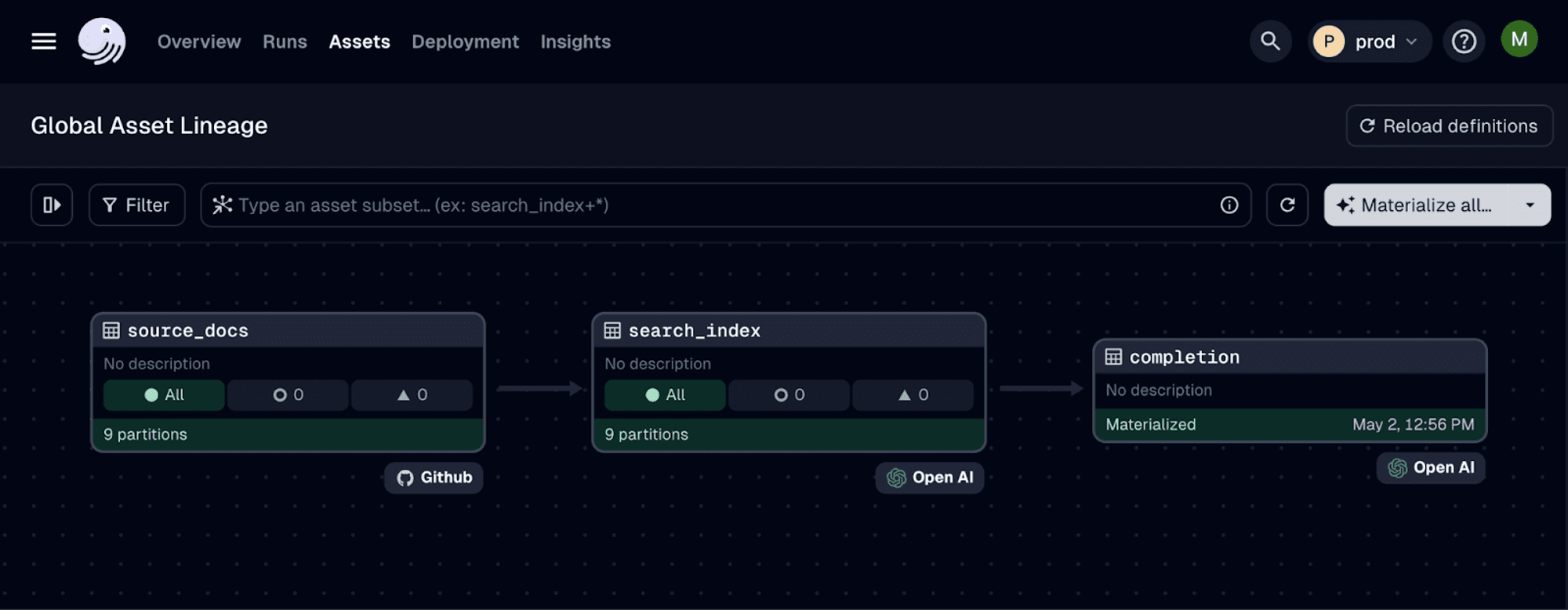
You can now refresh the partitions that you need, and only when you need them!
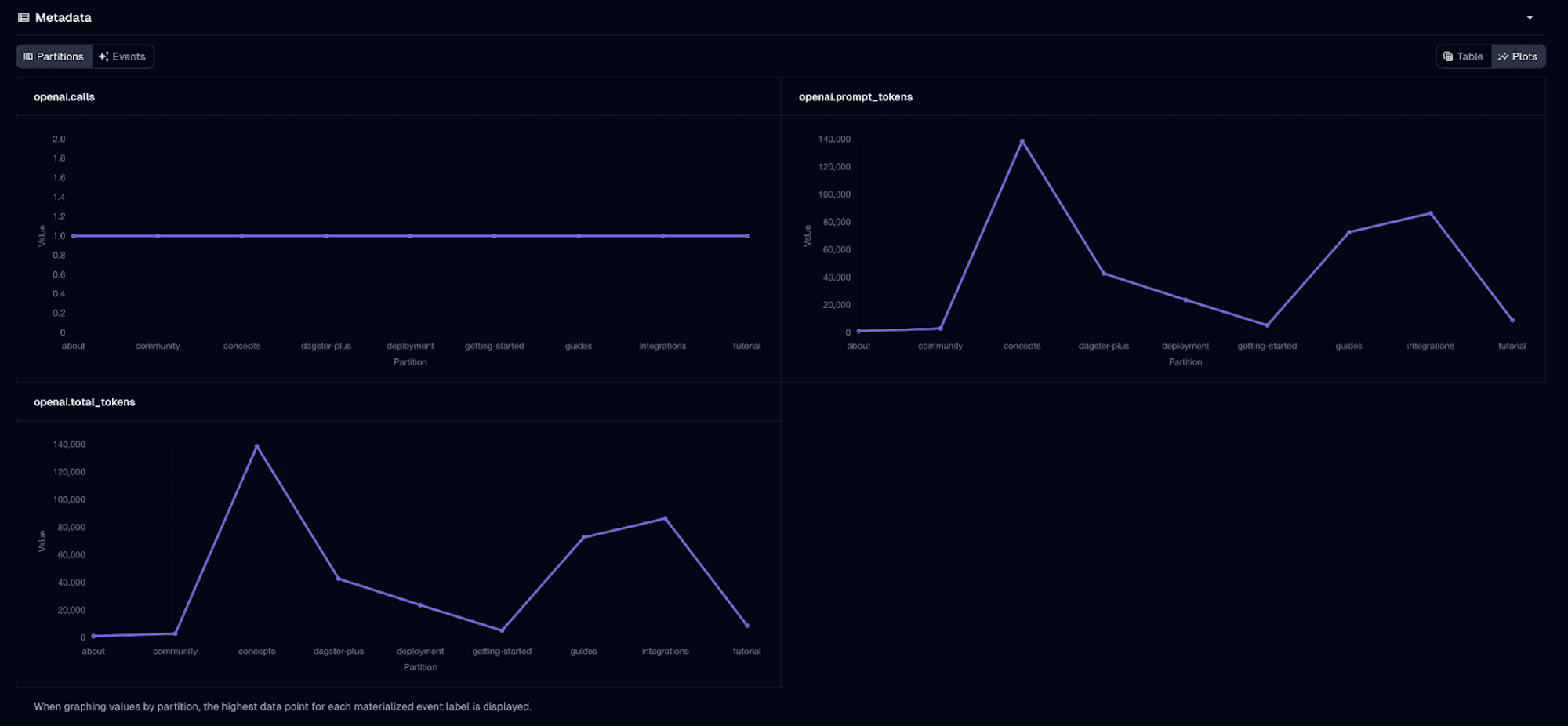
By using partitions, we can now selectively update our embeddings and search index only when actual changes occur. This approach minimizes unnecessary computations, and effectively reduces costs.
Leveraging Different OpenAI Models with LangChain
OK, now let’s explore different models to optimize our responses for higher ROI.
We can parameterize our pipeline to select the best OpenAI model based on the query. Here’s how do it:
First, we can define configurations to allow specifying the OpenAI model and the question it should address:
Then, let's incorporate this config to the completion asset.
Note: to apply different models dynamically, we use LangChain’s Expression Language (LCEL) to facilitate a declarative composition of chains.
This is a declarative way to truly compose chains - and get streaming, batch, and async support out of the box. You can use all the same existing LangChain constructs to create them.
So now, our full code looks like:
Then, we can manually launch a run using the launchpad:

To the question “How can I use dbt with Dagster?”, we get this answer:
So far, our pipeline has been kicked off manually.
As a production pipeline, we want to automate the responses for new queries without manual intervention.
For the purpose of the demo we store incoming questions in a JSON format within a designated folder.
Here’s how we can set up a sensor in Dagster to automatically materialize answers when a new question comes in:
Note: This setup is primarily designed to be digestible for demo purposes. In a practical scenario, it'd be more efficient to aggregate queries in a queue or database and batch them into single runs, rather than initiating a run for each question.

The sensor detects our question file and launches a run to materialize our completion asset. We get the answer:
Future Directions: Advancing AI Pipeline Efficiency and Effectiveness
In this post, we've laid the groundwork for optimizing AI, emphasizing cost management and enhanced developer productivity.
Key takeaways include:
- The rollout of our new dagster-openai integration which enables seamless interaction with OpenAI APIs and out-of-the-box usage tracking.
- Leveraging LangChain to dynamically declare different models
- Utilizing features of a modern orchestrator (Dagster) to improve developer productivity such as Insights, metadata tracking.
Looking ahead, we plan to further leverage Dagster and OpenAI's capabilities for model performance comparison and overall productivity enhancement. This includes but not limited to:
- Expanding the use of Dagster Cloud’s Insights to monitor crucial metrics more comprehensively.
- Leveraging Dagster’s data catalog for better management as we embark more sources, such as integrating Slack history to improve the response quality.
- Ensuring data freshness and reliability to uphold the quality of our support bot infrastructure, which involves dealing with bad or fake sources.





.jpg)
.png)



.png)

